2022.01.06
教師あり強化学習:模倣学習
模倣学習の基本
ピアジェの認知発達理論によると、人の知能発達第一段階は0~2歳で、主に模倣行動を通して、認知能力を発達する。勿論、人は大人になっても、他人又は専門家の行動を模倣し、色んな技能を獲得する、又は問題を解決する。機械も同じ理屈で知能を発達するのは、正に人工知能の正体だろう。
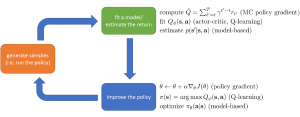
機械学習に定義される模倣学習は、実は、強化学習の一種である。一般的な強化学習では、教師のデータがなくて、ある状態におけ、ある行動を取ると、報酬が分かる。要するに、報酬が明確に定義され、観測できる。模倣学習の場合は、専門家データ(Expert Trajectory)が与えられ、報酬の顕在定義がない。教師あり学習の場合は、サンプル毎にラベルを付けるが、サンプル間の関係が独立として考える。一方、強化学習は、一連のサンプルがMarkov Decision Processに従う前提で、前のサンプルに依存する。その一連のサンプルはTrajectory或いはEpisodeと呼ぶ。模倣学習の専門家データは、リアル人間の専門家が実行動の記録でもあり、情報学習済みのAgentが疑似生成した行動でもある。基本的には、[状態、Next状態、動作、報酬]の配列(Trajectory)のN個分である。専門家データは正解ではなく、ノイズあり、平均的に報酬が高い行動系列である。そうすると、模倣学習の目標は、教師あり学習に似ているように、この専門家の行動に近づくように、モデルのParameterをTrainingする。
模倣学習は主に3種類の手法がある:(1)Behavoir Cloning:専門家データを完全に信用し、専門家の動作を丸ごとコピーするように、行動Policyを構築する。(2)Dataset Aggregation:専門家の行動データと学習した行動ポリシーによる行動データを融合しながら、新しいデータセットの上に、行動ポリシーを更新する。(3)Inverse Reinforcement Learning:専門家のPolicyを学習することではなく、専門家データから報酬関数Reward(State, Action)を推定する。(状態、動作)をインプットすれば、報酬が分かるとすると、行動ポリシーも自然に決められる。
模倣学習の代表的な手法
- 行動クローン:Behavoir Cloning
行動クローンは専門家のデモ(行動履歴)を真似て、行動ポリシーを構築する。教師あり学習と同じように、専門家の行動ポリシーπ*と学習Agentの行動ポリシーπとの距離をコスト関数として定義し、そのコスト関数を最小化するように、πを調整する。もし専門家の行動サンプルが足りなく、デモの状態空間は実の状態空間を完全にカバーしきれない場合、効果が非常に悪い。又、専門家の行動ポリシーは最適ではない(Suboptimal)場合も、効果があまり出ないだろう。
- 専門家データ融合:Dataset Aggregation
行動クローンの欠点を克服するため、専門家のデモデータを参考しながら、学習過程における行動軌跡からポリシーを更新していく。このアプローチの代表的なモデルは、DAggerというもの。このモデルは専門家Policy(π*)と学習中Policy(π)を融合し、新しいPolicy(π’)をRoll outし動作して自己行動軌跡を生成する。更に、専門家に問合せをして得られた行動軌跡と自己行動軌跡をマージし、新しいデータセットを作る。そのデータから学習Policy(π)をRetrainする。上記の過程を繰り返していくが、毎回自己ポリシーをRetrainするので、計算上は非効率的だろう。
- 逆強化学習:Inverse Reinforcement Learning
専門家の行動を取る理由がわからないまま、正に猿真似のようなアプローチであれば、新しい状態では、適切な行動を取れないだろう。逆学習は、専門家の行動理由(この行動をしたら、このような報酬が得られる)を学習しようとする方法である。要するに、報酬関数を推定することになる。典型的なIRLは、Apprenticeship Learningというアプローチ。報酬関数のパラメータはωとし、専門家のポリシーはπ*を定義し、学習ポリシーはπをとする。このアプローチは、ωとπを同時に学習する。学習ポリシーπに対して、ωの報酬関数で評価し、報酬最大化するように、πを更新していくが、一方、専門家ポリシーπ*が得られる報酬は必ずπより、大なりイコールするようにωを制限する。
GAILモデル
今回検証したい逆学習アルゴリズムはGAILというモデルである。GAILはGenerative Adversarial Imitation Learningの略称で、GAN(Generative Adversarial Networks)のコンセプトを融合して考案した逆学習アルゴリズムである。このアルゴリズムの基礎は、下記の式を示したような、Maximum Causal EntropyによるIRL:
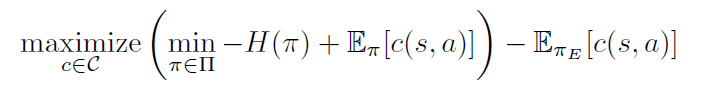
ここに定義したcはコスト関数という意味だが、報酬関数の正反対と考えればよい。πは学習Agentのポリシー、πEは専門家のポリシーである。これはMax-Minの二重最大化問題を捉える。インナーのMinはポリシーπのコスト最小化(つまり報酬最大化)を測りながら、ポリシーπのエントロピーを最大化する。なるべく、ポリシーのランダム性を増やし、専門家のポリシーの丸ごとコピーを避けることで、ポリシーの汎用性を増強する。アウターのMaxは、なるべく、専門家のポリシーから得られる報酬が最大化する(コストの負値を最大化する)ように、コスト関数を学習する。この式から見ると、GANの最適化目的関数に類似していることが分かる。
GAILはこの思想に基づき、下記のアルゴリズムに発展した。学習AgentのPolicy π(パラメータθ)はGANのGeneratorを相当し、Trajectoryのサンプルを生成する。専門家データから学習した評価関数(パラメータω)はGANのDiscriminatorを相当し、Generator πの精度(報酬)を評価する。τiはGeneratorが生成したデータ分布であり、τEは専門家の行動履歴で真のデータ分布と見なす。(1)DωはDiscriminatorのコスト評価関数(報酬関数相当)であり、専門家の行動履歴が最小コストを取れるように、更新されていく。(2)一旦Dωが求められたら、TRPOという通常強化学習モデルを用い、Generatorのポリシー(パラメータθ)を更新していく。上記の(1)と(2)はN回繰り返す。また、ポリシーπの学習には、TRPOに提案されたように、ポリシーパラメータの更新幅(今回は専門家ポリシーとのKL Divergenceで測る)を制限しながら、学習のブレ(報酬の分散)を抑える(GANにも同じ技法を利用した)。

初期実験結果
今回の実験はまたstable-linesを利用してみる。先ずは、Pendulum-v0という振り子ゲームの環境で、専門家データを作る。SACというActor-Criticモデルを用い、十分学習した上に、テストモードで「状態、アクション、報酬」の行動軌跡をレコードする。これは専門家データとして利用するが、もちろん、完璧な専門家ではない。次は、下記の四つケースで、性能(報酬)を比較してみた。四つのケースもランダムで10万回のTimestepを回して平均報酬を評価する。
Case 1:専門家データにてBehavoir Cloningを利用し、SACをPretrainする。
Case2:Case 1の後に、更にSACを学習する。
Case 3:専門家データを利用なしで、直接にSACを学習する。
Case 4:専門家データをGAILモデルにフィードし、学習する。
Case1の平均報酬:-3.505、Case2の平均報酬:-0.710、Case3の平均報酬:-0.696、Case4の平均報酬:-5.948
上記の結果から見ると、Behavoir Cloningはあまり効いていないし、さらに、GAILモデルはBehavoir Cloningより悪い結果が出た。パラメータチューニングも行わずに、シンプルの実験を行っただけなので、結論を付けがたいが、理論上には美しいGAILモデルは、あまりパワーが発揮できなかった。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD