2022.10.07
GCPで実験管理
こんにちは。AI研究開発室のS.Y.です。今回はGCPでのML実験管理を紹介します。
GCPではメタデータストアサービスのVertex ML Metadataと、最近GAになったML Test TrackingサービスのVertexAI Experimentを使って、実験パラメータやリネージの保存・比較を行うことができます。
実験管理
MLプロダクトで実験を行う目的は、様々な特徴量・パラメータ設定の中から、精度やビジネスKPIを最大化するものを選択することです。
ある実験設定による試行は、同時期に実行される試行や、過去の試行と比較されます。
実験の評価を迅速/正確に実施するためには、個々の実験設定とその結果を一元管理し、いつでも比較・参照できるようにする必要があります。ここでは、このように実験に関する情報を一元管理することを実験管理と呼びます。
実験管理に関するツールの形態は、オープンソース/マネージド/クラウドサービスの一部など、多く存在します。
実験管理ツールの主な機能は、実験に関する情報(アーティファクト)を
- 保存する
- 可視化、比較する
- 共有する
の3点だと認識しています。
PoCの段階では、恐らく実験管理に求められるのは保存・比較くらいの機能で十分で、その場合はオープンソースの実験管理ツールをパッと噛ませてPDCAを早く回すことがより重要だと思います。
一方で、本格的に機械学習モデル・パイプラインを運用していくとなると、モデルのパラメータやメトリックス以外の値も保存・比較したり、各イテレーションでの学習状況を可視化したり、過去の実験結果まで遡ってチームで共有したりという需要が出てくるのではないでしょうか。
このような段階では、多くの実験をラクに一元管理できるマネージドやクラウドサービスで提供される実験管理サービスが採用されるでしょう。
特に、今回紹介するVertexAI Experimentのような、クラウドサービスの一部として提供されるツールの場合、コスト(ツール使用自体やアーティファクトのストレージコストなど)は殆どかからない傾向にあるようです。
今後はこういった実験管理サービスがあることも、機械学習プロダクトの構築にクラウドを選択する理由の一つになってくるかもしれません。(まぁ上手くやらないと他の部分で高コストになったりしますが。。)
Vertex ML Metadata
Vertex ML Metadataは、MLシステムについてのメタデータストアです。VertexAI Pipelineで実行される各ステップのリネージや、後述するVertexAI Experimentでアーティファクトが保存されます。1GBあたり$10/月のコストがかかるようですが、メタデータはそれほど膨大にはならないので、ほぼほぼ気になる額になはらないと思います。
アーティファクトと実行をノード、イベントをエッジとするグラフとして保存しているようです。
- アーティファクト: 機械学習ワークフローによって生成、使用される個別のエンティティまたはデータ。例として、入力ファイル、変換されたデータセット、トレーニング済みモデル、トレーニング ログ、デプロイされるモデル エンドポイントなどがあります。
- 実行: 個々の機械学習ワークフロー ステップのレコード。通常はランタイムのパラメータでアノテーションが付けられています。例として、データの取り込み、データの検証、モデルのトレーニング、モデルの評価、モデルのデプロイなどがあります。
- イベント: アーティファクトと実行の関係を記述します。イベントは、アーティファクトと実行を連結することで、ML ワークフローでアーティファクトの出所を特定するのに役立ちます。
下記の図は、機械学習パイプラインをグラフを可視化した例です。
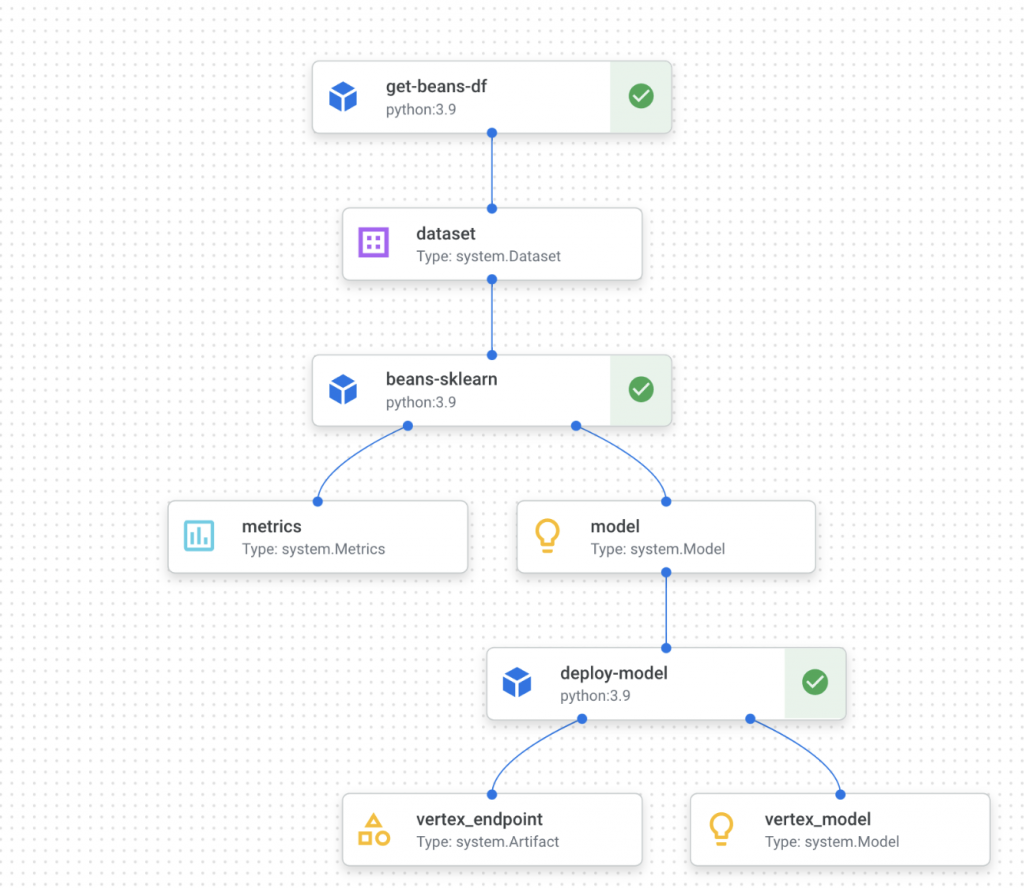
ちなみに手動でのデータ登録や参照はREST APIで可能ですが、こちらはほとんど使わないでしょう。
また、2022年10月17日から、VertexAIで管理されているDatasetとModelについて、自動でVertex ML Metadataで追跡されるようになるようです。
VertexAI Experiment
GCPで最近GAとなった、実験管理サービスのVertexAI Experimentをご紹介します。
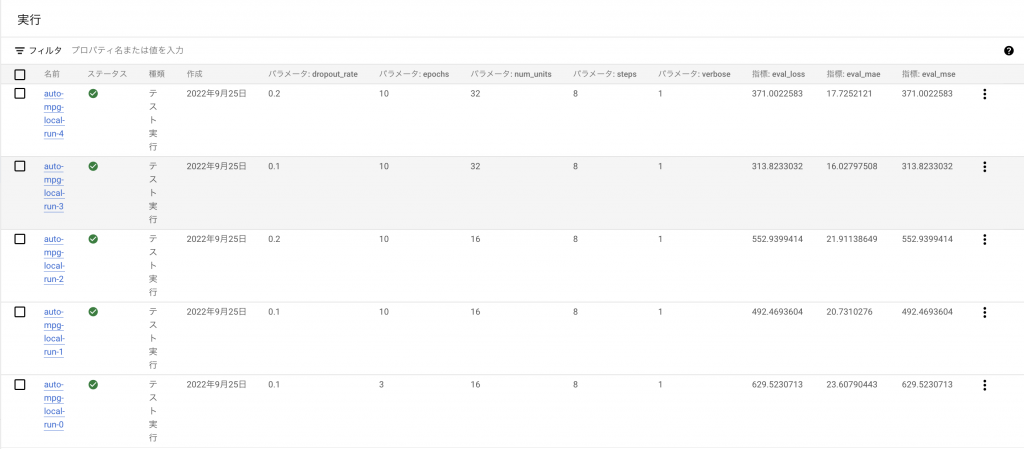
VertexAI Experimentでは、モデルの学習や評価の実行をexperiment runと呼び、同じコンテキストのexperiment runを複数まとめてexperimentという単位で管理します。experiment run毎にparameterやmetricsを保存し、コンソール上で各experiment runの比較ができます。
アーティファクトを保存する機能はpythonのaiplatformパッケージに最初から入っていて、保存したい情報をKey-Value形式にしてlog_*(dict)として呼び出すだけです。MLFlowなどのツールも、基本的にこのようなやり方ですね。
また学習エポック毎のlossなどの時系列情報は、Time Series Metricsという別のメトリクスとして保存します。Time Series Metrics の記録には別途VertexAI TensorBoardのインスタンスの作成が必要です。VertexAI TensorBoardは2022年2月から料金が変更となり、VertexAI Tensorboardを利用したユーザー毎に$300/monthかかります。一度でもインスタンスを作成したりするとその瞬間に$300持っていかれるので、利用の際は十分に気をつけてください(自戒)。
from google.cloud import aiplatform as vertex_ai
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
vertex_ai_tb = vertex_ai.Tensorboard.create()
vertex_ai.init(experiment=EXPERIMENT_NAME, experiment_tensorboard=vertex_ai_tb)
# Define experiment parameters
parameters = [
{"num_units": 16, "dropout_rate": 0.1, "epochs": 3},
{"num_units": 16, "dropout_rate": 0.1, "epochs": 10},
{"num_units": 16, "dropout_rate": 0.2, "epochs": 10},
{"num_units": 32, "dropout_rate": 0.1, "epochs": 10},
{"num_units": 32, "dropout_rate": 0.2, "epochs": 10},
]
# Read data
dataset = read_data(
"http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"
)
# Split data
train_dataset, test_dataset, train_labels, test_labels = train_test_split(dataset)
# Normalize data
normed_train_data, normed_test_data = normalize_dataset(train_dataset, test_dataset)
# Run experiments
for i, params in enumerate(parameters):
# Initialize Vertex AI Experiment run
vertex_ai.start_run(run=f"auto-mpg-local-run-{i}")
# Log training parameters
vertex_ai.log_params(params)
# Build model
model = build_model(
num_units=params["num_units"], dropout_rate=params["dropout_rate"]
)
# Train model
history = train(
model,
normed_train_data,
train_labels,
epochs=params["epochs"],
)
# Log additional parameters
vertex_ai.log_params(history.params)
# Log metrics per epochs
for idx in range(0, history.params["epochs"]):
vertex_ai.log_time_series_metrics(
{
"train_mae": history.history["mae"][idx],
"train_mse": history.history["mse"][idx],
}
)
# Log final metrics
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
vertex_ai.log_metrics({"eval_loss": loss, "eval_mae": mae, "eval_mse": mse})
vertex_ai.end_run()
記録された値は、VertexAIのExperimentタブからexperiment毎に確認できます。time_series_metricsを記録した場合は、TensorBoardインスタンスへのリンクも出現し、そちらで学習の経過を比較することができます。(こちらは1つのグラフに複数experimentの描画ではないので、パッと見の比較は少しやりづらいです)
Pipeline Jobの比較
ここまでVertexAI Experimentを使って、experiment runのparamsやmetricsを保存・比較できることを見てきました。ただVertexAI Experimentの真価は、Vertex Pipelineと組み合わせてPipeline Jobを比較できる点にあると思います。pipelineの実験をpipeline runと呼びます。
vertex_ai.PipelineJob(parameter_values={})に記録したい値を受け渡して、job.submit()の際にexperimentを指定することで、該当experimentにparameter_valuesが記録されます。モデルのハイパーパラメタはもちろん、例えば前処理に関するパラメータなども記録でき、パイプラインを包括的に比較することができます。記録されるmetricsは、pipeline定義のjsonファイルから推察されるようです。
runs = [
{"max_depth": 4, "learning_rate": 0.2, "boost_rounds": 10},
{"max_depth": 5, "learning_rate": 0.3, "boost_rounds": 20},
{"max_depth": 3, "learning_rate": 0.1, "boost_rounds": 30},
{"max_depth": 6, "learning_rate": 0.5, "boost_rounds": 40},
{"max_depth": 5, "learning_rate": 0.4, "boost_rounds": 30},
]
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path=PIPELINE_TEMPLATE_FILE,
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
pipeline runの詳細は、同様にVertexAIのExperimentタブから確認できる他、VertexAI Pipelineの該当pipelineのページからも飛ぶことができます。
まとめ
今回はGCPで機械学習モデルを運用する際に、どのように実験管理をするのが良いかについて書きました。主に検証したVertexAI Experimentは学習コストや料金コストが低く、現在VertexAI上でモデルを運用されている場合や、これから運用する場合は、導入を検討する価値が十分にあると思います。
また、GCPでは直近でVertexAI ExperimentがGAになったり、Vertex ML MetadataがVertexAI上のDatasetやModelを自動で追跡するようになったりと、よりラクで低コストに実験管理ができる環境が揃ってきているように感じます。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD