2020.04.01
Zero-shot learningの紹介:見たことがない画像やニュースを予測してみました
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
最近、新型コロナウイルスの感染拡大の影響で外出も自粛モードになっていますが、みなさんお元気ですか。
今年の初ブログという節目に「やったことがないこと、行ったことがないところ」を今年こそ挑戦してみたいと思ったりしませんか。私は植物を見るのが趣味で、行った事がない自然のあるところに行ったり、見た事がない植物の写真を撮ったりして、個人の写真コレクションを増やしていきたいです。最近、携帯の写真検索機能が高まって、たくさん写真を撮っても、見たいときに、単語を入れると、携帯が勝手にアルバムを分類してくれます。例えば、「バラ」を入れると、自分が集めてきたバラの写真が出てきます。最近、新型コロナウィルスであまり外出できないし、リモートワークで目が疲れたときなど、見たい植物の写真を見て楽しんでいます。ところで、残念ながら、私が大好きな「サルスベリ」を入れても画像は出てくれません。毎年、様々なところで沢山「サルスベリ」の写真を撮っているのに、少しイライラします。なぜ、「サルスベリ」が出てくれないだろうかと疑問になりませんか。当たり前の答えですが、機械は「サルスベリ」を知らないのです。
人間は、初めて「サルスベリ」を見たときに、植物名を知らなくても、以前の知識から、「サルスベリ」は植物の一種類だと推定できます。しかし、機械は、学習したことがないものを推定するのには、まだ限界があります。というわけで、今回は機械が学習していないものをなんとかしたいという気持ちで、その周りの技術を調査し、「zero-shot learning」を発見しました。zero-shot learningとは何ですか? なぜ、どうやって、人間のように見たことがないものを推理できるのでしょうか? 今回のブログで、勉強しながら、実装してみようと考えています。
(実は、前回のブログにも少しzero-shot learningという言葉を紹介させて頂きましたが、今回は実際に触って深掘りします。)
さて、このブログの構成は、以下のとおりです。
① Zero-shot learningとは?
② 実装
2.1. 見たことのないカテゴリーの画像を分類してみました
2.2. ニュースの内容とFXの動きを測ってみました
③ まとめと考察
① Zero-shot learningとは?
(少しだけ、前回のブログを繰り返しますが、)
Zero-shot learningは機械が見たことがないものを予測するための機械学習の技術の一つです。 例えば、馬を見たことがある子供がはじめて縞馬を見たときでも、白と黒のストライプを持つ馬だろうと想像できます。しかし、機械では馬の写真と名前だけを学習したため、見たことがないシマウマを認識することはできません。それは、人間が既存の知識をベースに、見たことがあるものと初めて見たものの関連性を繋ぐ能力があるからです。機械に学習したことがないものとあるものの関連性を繋げる能力を高めるため、機械に推論の力を付けることが必要です。そのための技術の一つはzero-shot learningです。
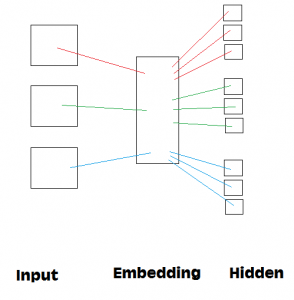
下記の図を参考にしながら、説明させて頂きます。例えば、犬、馬、車の絵を学習するときに、一般的な機械学習は犬、馬、車、のラベルを活用し、学習します。Zero-shot learningはラベルの代わりに、クラスで分類します。具体的には、犬、馬、車のラベルを一つ数字で表すのではなく、いくつかの次元のベクトルを利用します。ベクトル化のおかげで、意味が近い単語を特定することができ、数字的に見たことがない猫が犬や馬のベクトルの方が車のベクトルより近いことを検出できます。人間のように、見たことがなくても、見たことがあるものとの関連性を推論しているようになります。
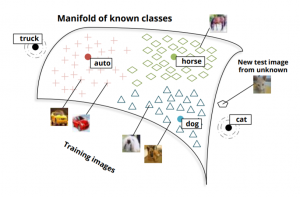
 stanfordの論文より転載
stanfordの論文より転載では、具体的にどんな感じなのか説明させて頂きます。まず、zero-shot learningのコンセプト(考え方)を話してから、実践するための従来の手法を書かせて頂きます。最後は関連論文も少し紹介します。
zero-shot learningのコンセプトと主な手法
一般的に、機械学習はデータを学習(train)し、モデルを作成します。学習済みモデルを使って、様々なことを予測(predict)します。前述したように、機械は学習したことがないものを予測するのは難しいので、zero-shot learningは機械に推論(inference)の力を加えることで対応を試みます。実際の対応は、学習(training)と推論(inference)の 2つのステップから成り立ちます。まず、学習は普通の機械学習と似たような感じで、知られている知識(データ)を学習します。次に、推論は既存知識を利用し、学習していないものを推論します。
Zero-shot learning技術はこの二つプロセスをベースにし、発展しています。主な従来手法は二つあります。①分類と回帰(Classification/regression approach)と、②エネルギー関数(Energy function approach)です。
① 分類と回帰(Classification/regression approach)
まず、機械はどういうふうな学習をするのか、少し復習していきます。普通の学習だと、データ(x)とラベルを使って学習しますが、zero-shot learningはラベルの代わりに、ラベルの単語のベクトルを利用します。このベクトルは既知のclass-category vector(v)とします。学習するときにSVM、neural networksといった手法でv=f(x)を学習していきます。学習が終わったら、学習済みモデルを使って、知られていないものも入っているデータセットのベクトルを予測します。このときに、新しいclass, v*を定義し、新しいデータ、f(x*)をマッピングします。最近傍マッチング(nearest neighbor matching)で、v*とf(x*)を推定します。nearest neighbor matching といったMultidimensional data 解析についての詳細はこのyoutubeを参考にして下さい。
② エネルギー関数(Energy function approach)
この手法は分類と回帰より、複雑になります。学習するときに、エネルギー関数「Ew(x,v) = x’Wv」を利用します。テストのときに、v*における、E(x*,v*)を評価します。
私なりに、テーブルでまとめてみました。ご参考になればと思います。

ちなみに、今回、zero-shot learningをメインに話していますが、実はone-shot、few-shotといった様々なn-shot learningもあります。興味がある方はこのブログを参考して頂ければと思います。
zero-shot learningに関係がある技術
機械学習について有名なAndrew Y. Ng先生のグループがzero-shot learningの改善提案の論文を参照。また、簡単な数式的な説明や実装例は他の方のブログがまとめてありますので、そちらの方も参考になるかと思います。
② 実装
それでは、いよいよ、実装です。今回、やってみたい実験は二つあります。
まず、簡単な勉強用の例として、見たことのないカテゴリーの画像を分類する実験を行います。コーディングしながら、zero-shot learningを理解していくという流れにします。次に、応用例として、前回のブログと似たようなネタで、ニュースの内容とFXの動きを測ってみることに再チャレンジします。
すべての実装はgithubに入れておきましたので、ご参考になればと思います。
実装環境
今回の実装では、(自分の気分転換で)GMO GPUクラウドではなく、 Google Colaboratoryを利用しました。無料版で12h実行時間などの制限はありますが、機械学習モジュールも充実していますのでセットアップが必要なく、GPUやTPUも気軽に楽しめます。
2.1.見たことのないカテゴリー画像を分類してみました
実装の流れは下記の図のように、学習と推論部分が分かれています。
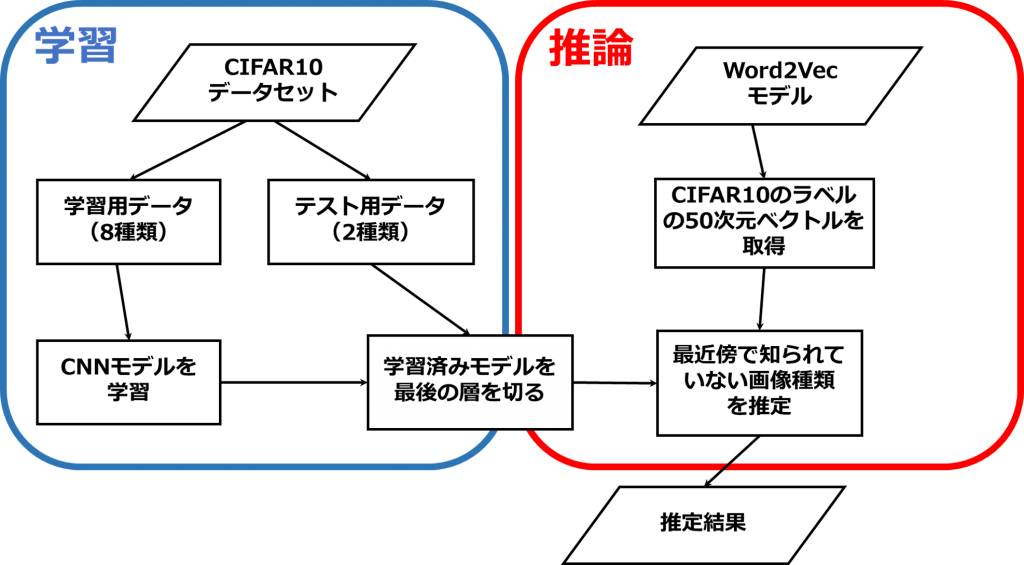
はじめに、学習です。学習データを準備します。データは学習用とテスト用に分けます。テスト用のデータは学習用に入っていないカテゴリー画像が含まれています。学習用のデータをneural networkモデルで学習します。次に、推論です。Word2vecモデルを使って、全てのラベル(class-category vector)を作成します。そのベクトルと学習済みモデルを最近傍で学習したことがないカテゴリー画像を推定します。詳細は下記に説明し、全体の実装はここを参考にして下さい。
データ準備:CIFAR10
Keras(open-source neural network library)のデータセットからCIFAR10(画像分類や物体認識のベンチマークとしてよく使われている)という画像データセットを用いました。CIFAR10は動物や乗物など10種類の画像が含まれています(下記はデータのサンプル)。
from keras.datasets import cifar10 (train_data, train_label), (test_data, test_label) = cifar10.load_data()
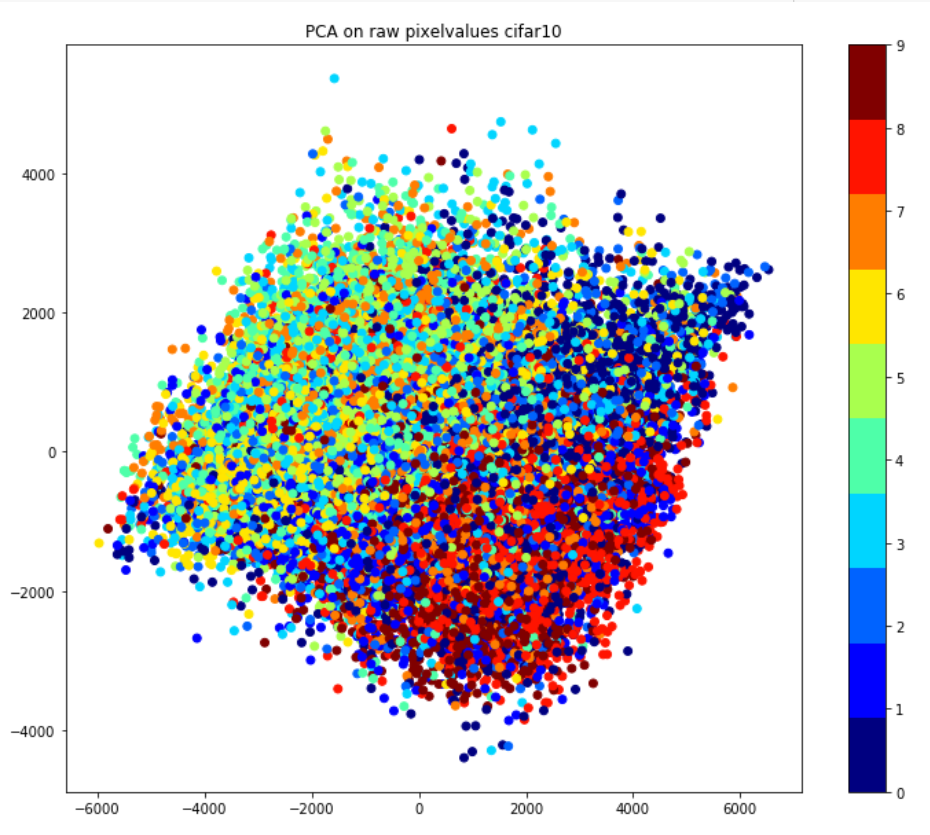
データの雰囲気を捕まえるため、数字に変換された画像データを分類してみました。ここで、やりたいことはこれらの画像をグラフ化したら、各カテゴリーがちゃんと分類できるのかを確認してみたいです。
今回のCIFAR10画像データには4万枚の学習用データがあり、一枚ごとに256通りのピクセル値の数字が3072個(縦32×横32×RGB3)あります。それらの3072ベクトル数字と4万枚のデータの二次元配列を作成します。それから、PCA(Principal Component Analysis、主成分分析) という手法を用いて、それぞれ3027次元の画像データを2次元に圧縮し、プロットしました。計算結果(下記の図)は画像一枚1点で、10カテゴリーを10色で示し、横と縦はPCAの第一主成分と第二主成分の値になります。見てみると、同じカテゴリーの画像は近いところに分類できていることがわかります。
それでは、データを処理していきます。データを学習用とテスト用を8:2で分け、さらに学習用の中の2割を検証用に分けました。全部のデータセット(学習、検証、テスト)にはバラバラで10種類のカテゴリー画像が入っています。また、zero-shot learningを実験するために、知られていないデータが必要ですので、学習用と検証用のデータセットから、「鳥とトラック」を外します。テスト用のデータは「鳥とトラック」を入れたままで使います。
Word2vecモデル準備
Word2vecモデルは gensimというトピック分析や自然言語処理用のライブラリで、学習済みword2vecモデルをダウンロードしました。モデルから、CIFAR10データセットの10個のカテゴリー単語を抽出しました。
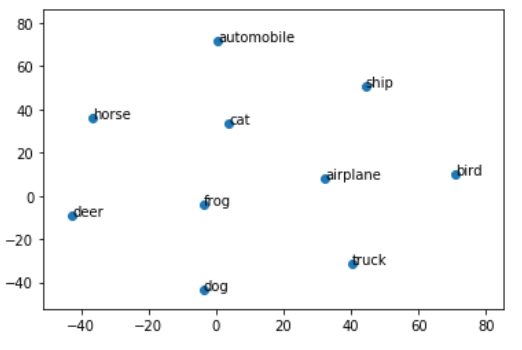
また、単語の雰囲気を捕まえるため、t-SNE(高次元データの可視化に適している次元削減アルゴリズム)を使って可視化してみました。詳細は割愛しますが、上記に説明したPCAと似たような目的で、異なる計算法です。計算結果を見てみると、飛行機(airplane)と鳥(bird)のカテゴリーは近いことが見られるし、四足の哺乳類同士も近いところにいることが見られます。
モデル準備
学習モデルは画像処理でよく使われているConvolution Neural Network(畳み込みニューラルネットワーク、以下CNN)モデルを利用しました。今回のzero-shot learningのため、 Keras Tutorial のモデルを修正しました。
def cnn_model_category_class():
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(50)) # for word class
model.add(Dense(10)) # for cifar10 category class
model.add(Activation('softmax'))
# initiate RMSprop optimizer
opt = keras.optimizers.RMSprop(lr=0.0001, decay=1e-6)
# train the model using RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
return model
画像をモデルに入力し、学習します。入力した画像の数字はいくつかの層を畳み込んで、最後にカテゴリー数字(10カテゴリーで0-9数字に表す)を出力します。こうすると、入力した画像の数字を分類することが可能になります。
今回の実装での注目は最後と最後の一つ前の層です。最後と最後の一つ前の層のベクトルの長さは10と50にしました。実装は10層までのcifar10 categoryモデルと50層までのword classモデルを両方とも試します。
実装:画像分類
ここでは、作成したモデルを利用し、学習します。学習条件はbatch_size = 32、
epochs = 100を設定しました。
image_class_history = image_class_model.fit(x_zsl_train_norm, train_labels_cat,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_zsl_validation_norm, validation_labels_cat),
shuffle=True)
普通の状況だと、categoryモデルを使って学習し、学習が終わると、そのままモデルが使えます。今回はその学習済みモデルに推論力を付けていきます。categoryモデルを最後の層10 classラベルの層を切り捨てて、50dimension層(word vectorと同じ)に、zero-shotモデル(word classモデル)を作成します。学習のときのラベルはword vectorの情報を利用します。同時に、word vectorモデルにk-dimension treeモデルを作ります。それから、モデル予測するときに、zero-shotモデルを利用し、k-dimension treeで学習したことがないラベルでも、word vectorを組み合わせて、小さい情報を推定することが可能になります。
# create KDtree for selected word array vectors = np.asarray(selected_word_array, dtype=np.float) tree = KDTree(vectors)
結果:画像分類
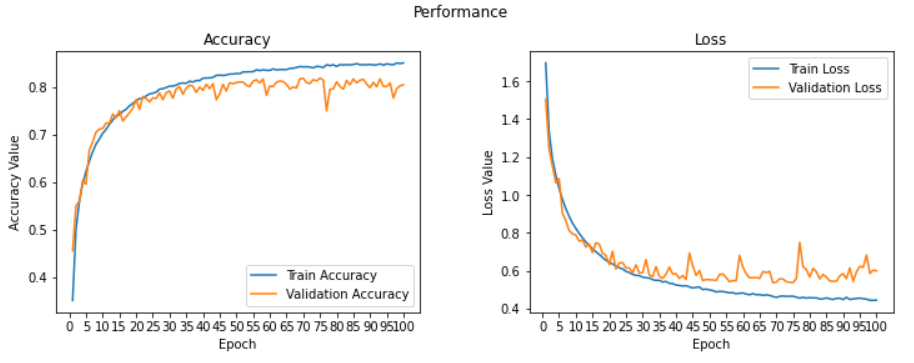
学習結果になります。予想通りにモデルがきちんとラベルがあるデータ(教師があるデータ)を学習しました。学習回数(Epoch)が増えると、学習のaccuracy(正答率)も上がってきて、loss(損失)も下がっていくことが見られました。
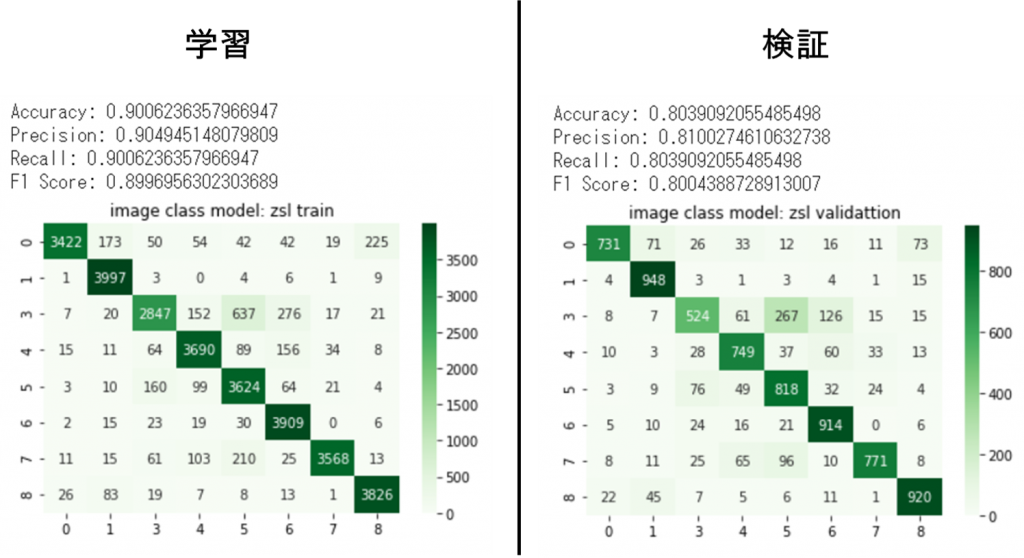
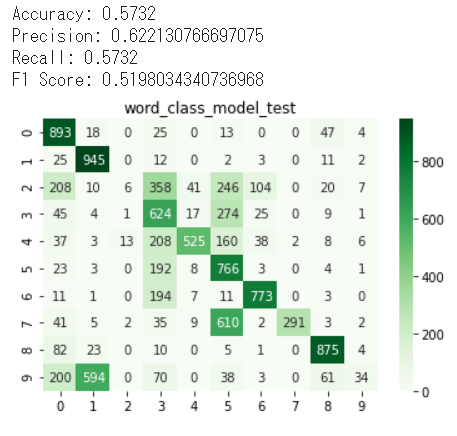
また、Confusion matrix(横は実ラベル、縦はモデル予測)によると、学習のときも検証のときも、実ラベルとモデル予測ラベルがだいたい似ていることが見られます。
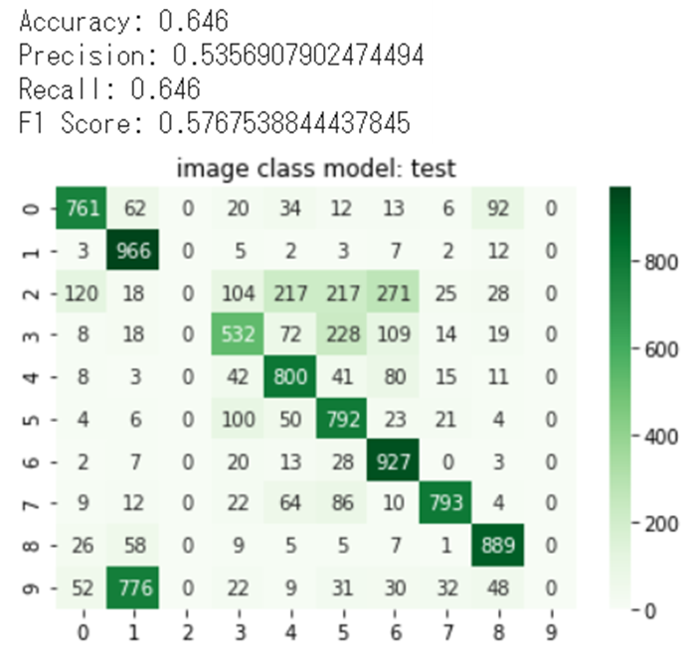
学習モデルを使って、テストデータをやってみるとやはり、学習していなかったラベル(2と9)は予測することが不可能でした。
最後に、zero-shotモデル(word classモデル+k-dimension tree)を作って、同じテストデータを予測してみました。結果を見てみると、学習したことがないラベル2と9を予測することが可能になりました。ただ、学習したことがあるものはテストのデータには精度が少し減ったことが見られました。推定するときに、k-dimension treeで近似するため、学習したことがあるもの間違って推定する画像だと思われます。
2.2. ニュースの内容とFXの動きを測ってみました
「FXとは?」の基本知識と「実験の仮説」は前回のブログの実験②を参考にして下さい。また、今回の実装はここを参考にして下さい。
データ準備:ニュースとFX
FXデータは forextester から、2016/1ー2018/6のデータをダウンロードしました。データは一日一点で、毎日10:00のデータを抽出します。ニュースデータは Kaggle news-category dataset から、ダウンロードしました。ニュースのデータは41種類ありますが、FXに関係ありそうな3つのカテゴリー(CRIME, BUSINESS, IMPACT)に絞ります。学習したデータセットは下記の感じです。FXが上がった日はsign=1、下がった日はsign=2、変らない日はsign=0にしました。また、一日にはニュースが何件かありますが、全部の件数を学習します。また、実験のため、データは3つのセットに分け、学習(train)70%、検証(validation)15%、テスト(test)15%にしました。
モデル:LSTM
LSTMの説明は過去のブログを参考にして下さい。
今回使ったモデルは簡単なモデルになります。
model = Sequential()
model.add(Embedding(max_features, 128))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(2, activation='tanh'))
model.add(Dense(y_train_ohe.shape[1], activation='sigmoid'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
実装と結果:ニュースの内容とFXの動き
実装は画像分類と似たような感じで実装しました。ただ、CNNモデルではなく、LSTMモデルを利用しました。また、k-dimension treeに使う情報は過去のpriceの差の情報でした。
予測した結果の当たり率はZero-shot learningで44%、LSTMで43%でした。
③ まとめと考察
今回はzero-shot learningについての技術を勉強し共有しました。今回の実装は簡単な方法で試してみました。残念ながら、期待通りの改善は簡単な実装だけでは見られませんでした。
しかし、データがないところをなんとかしたい気持ちの時に役に立つ技術だと思います。個人的には期待していきたい技術の一つです。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD