2020.03.31
深層強化学習はFXマーケットのアルファを見つけるか
こんにちは。次世代システム研究室のL.G.W.です。
近年は、Alpha-Goような強化学習の応用例が世の人々に驚かせました。最強の人類智能(囲碁プロ)を勝てば、このようなモデルを活用して、金融取引においても最強のTraderを超えるような利益を取れるか?
今回は最新の深層強化学習モデルーACER(Actor-Critic with Experience Reply)を利用して、FX取引をやってみた結果を報告いたします。
モデル紹介
強化学習
Source: Berkeley大学のDeep Reinforcement Learningコース
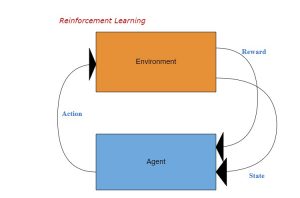
強化学習とは、Agentが状態sの下で、あるPolicyに基づいて動作aを起こして環境が次の状態に遷移し、Agentが報酬rを獲得するプロセスの中で、どうやってトータル報酬を最大化するための学習である。
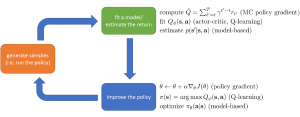
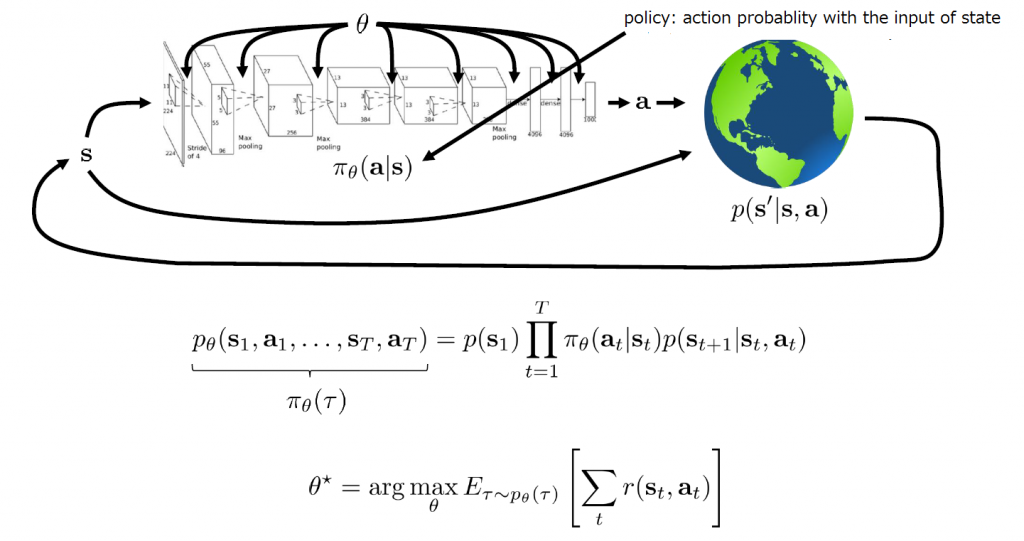
深層強化学習は上図に示したように、Policy πを深層ニュラルネットワークで表現し、一連の動作(Episode)の合計報酬の期待値を最大化するため、そのPolicy NetworkのParameter θをデータから学習していくこと。状態の遷移はMarkov Chainを仮定すると、このプロセスの発生確率は上記のp_θ(τ)のように計算できる。
強化学習の目的は報酬最大化というシンプルなものが、これを達成するため、沢山のアルゴリズムが提案されている。主には下記の3種類に分けられる:
- Value Function
代表的なモデルはQ-Learning: この状態sで動作aを起こした時の期待報酬をニューラルネットワークで近似する - Policy Gradient
代表的なモデルはREINFORCE:Loss関数を報酬から導き、更に報酬もPolicyに依存するので、LossはPolicyの関数になる。そのLossの微分はPolicy Gradientになること。 - Actor-Critic
代表的なモデルはA2C:Valueを近似するNetwork(Critic)とPolicyを表現するNetwork(Critic)、二つを同時に構築し、学習していくこと
通常はPolicy Gradientの学習が効率的に悪い、Value FunctionのFittingが収束しにくいなので、Actor-Criticはより人気が集まっている。実は、上記の3種類と違って、Model-base RLも沢山存在する。Model-baseとは、状態遷移プロセスをモデルで表現し、明確なPolicyがいらないこと。Alpha-goやロボット行動計画の場合、状態遷移が確率的でないので、この手法を用いている。
ACERモデル
今回研究しているモデルは、ACER(Actor-Critic with Experience Reply)というもので、ICLR 2017で発表したActor-Critic系のモデル。ACERモデルはA2Cをベースにして、複数な研究成果を融合した最新モデルである。具体的には、下記のような特徴を取り込んである。
- Experience Replay
強化学習はPolicyによりサンプルを生成し、さらにサンプルからPolicyを更新するという反復プロセスである。理屈的には、サンプルが使い捨てになり、効率てきではない。これを改善するため、最近は経験再生法(Experience Reply)を用いるOff Policy学習がよく用いられる。経験再生法は、過去学習したサンプルをバッファに格納し、このバッファからサンプル(複数なので、Mini-batchになる)を作り、現在のPolicyを更新する(=Policy Gradientを計算する)。ただし、現在のPolicyと過去Policy(平均)の比率を重みとしてPolicy Gradientに掛ける。 - Retrace – Q Function Estimation
強化学習にもう一つ問題は、状態のValueを精確に評価すること。Valueは報酬の関数だが、報酬はこの時点で確定するものもあれば、未来(n-Step後)しか分からないものがある。さらに、ある状態の報酬は次の状態とPolicyにより、変動が大きい(分散が大きい)。その問題を改善するため、Retraceという手法が提案された。未来の複数Stepの報酬も考慮され、さらにPolicyに使われたValue関数と現状態の価値を推定するValue関数は、分離され、それぞれ学習する。 - Importance Weight Truncation
ACERのPolicy Gradientは、過去バッファのサンプルを利用する時、重みの掛け算を使ったが、この掛け算はとんでもない大きい数値になる恐れがある。この場合は、当然切り捨てればよいが、Biasを生じるかもしれない。ACERは、このBiasを補正できるように工夫した。 - Trust Region Policy Optimization
強化学習(Policy Gradient)によくある問題は、Policyの更新がPolicy Gradientの不確実性(報酬の不確実性)により大変不安定で、時々が大きく変動する。過去のサンプルを再利用しているので、Policyがいきなり過去のものと大きくずれると、そもそも過去サンプル(当時のPolicyに基づき、評価された報酬)が信頼できなくなる。それを防ぐため、現在Policyと過去Policy(平均)の距離(KL-Divergence)をある閾値以下のように、現在Policyを調整する。 - Duel Network
Double Q-learningにも使われた技術と同様に、Value Networkは二つに分けて、一つ(Policy Value Network)がPolicyに利用され動作をきめる;もう一つ(Target Network)が状態のValue評価に使う。n-step後は、二つのValue Networkを統一する(Target NetworkをPolicyのValue Networkに上書き)。この方法は、CriticとActorが同一関数(Value Function)に依存する不都合を緩和することができる。(Critic=裁判、Actor=選手と例えば、裁判と選手が同じ人に依存されると、不都合が生じるだろう)
実験結果
今回の実験ではACERモデルがStable-baselinesに実装されたものを流用することします。FX-Marketデータがここにある2019年のUSDJPYの分足を利用し、Open/High/Low/CloseをFeatureとしてInputする。
取引の結果は下記のように可視化し、確認できる。一段目はPriceとBuy/Sellであり、二段目はポジションの変化、三段目はBuy/Sellの数量の時系列、四段目はネット評価損益(初期資金が1万円)である。
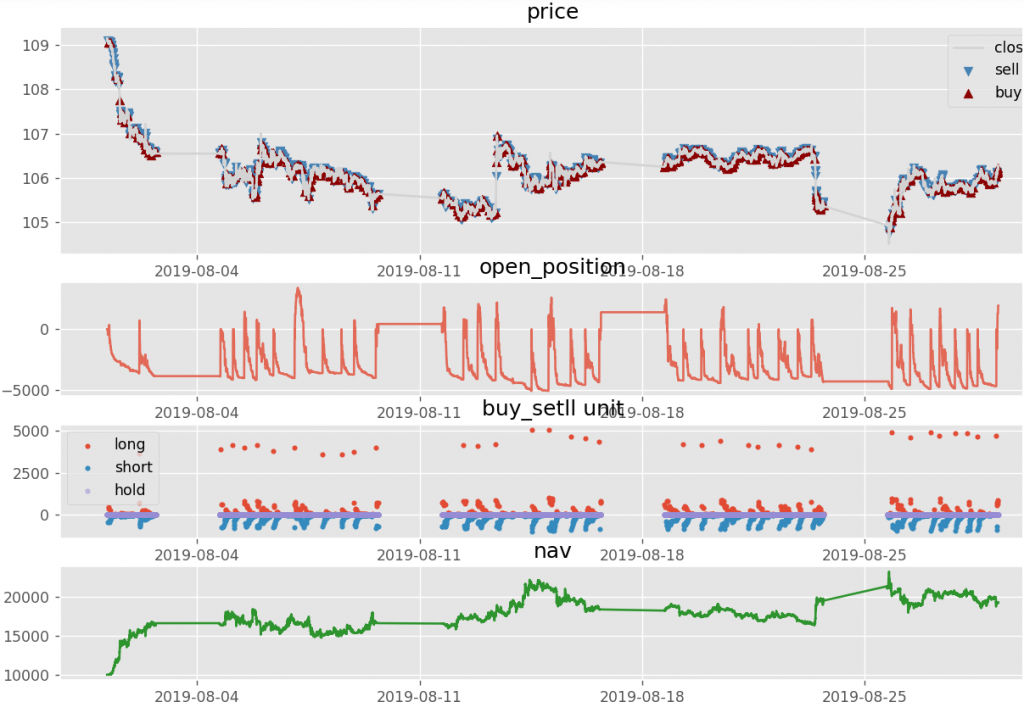
お試しの結果
モデルはBlack boxで、本当にワークしているか確認するため、まずはリアルのFXデータではなく、Sine関数(+Gaussian Noise)で生成したパターンあるものをやってみた。結果は、1万円の初期資金から、1ヶ月に1500回の買売で数百万円まで儲かった。
だが、リアルのデータを投入すると、10回を実行し(同じ期間でも結果が変わる)、-50%~+40%の間に収益率が変動し、あまり儲かる気配がない。
そして、わざわざデータをリークし(つまり、次のTickのデータをFeatureに入れる)、新しく学習したモデルは儲かる確率が上がった(とはいえ、毎回勝ちではない)。
要するに、学習能力があるが、Inputに有益な情報がないと、儲かる可能性がない。
取引回数が多くて、超短期売買の傾向があるので、Spreadを0.3 Pipsから1.0 Pipsに上げたら、売買スタイルが変わるだろう。実際は、1500回の売買から10回まで極端に減らした。多分、売買のコスト(Spread)が高ければ売買回数が控えることを学習し得たと思われる。
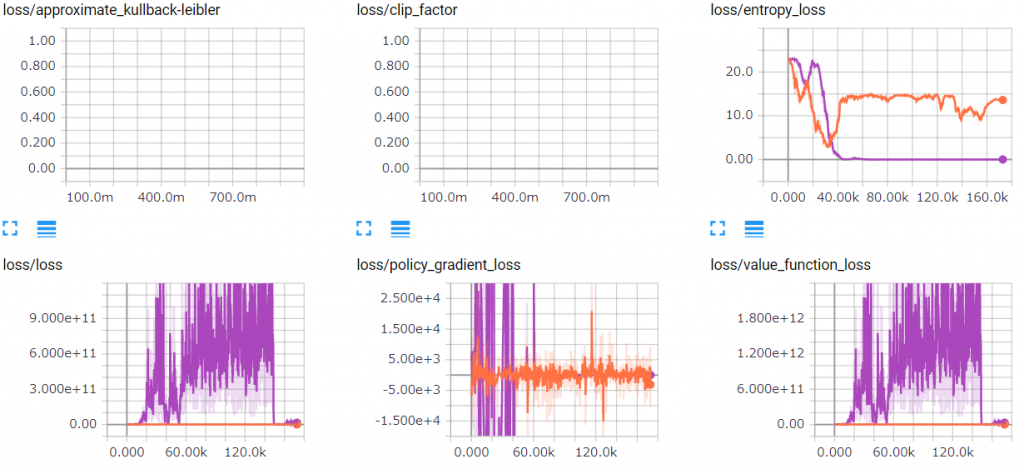
学習プロセスの可視化
強化学習は不安定性の問題が抱えて、それはどうなっているか、まず学習プロセスを可視化できるTensorboardを利用し、チェックしましょう。下図は、同じ条件で2回実行した学習Lossの時系列である。青い線のentropy_lossは40K Step頃から既に変更なし、つまり、学習ができなくなっている(Learning Rateの調整で変わるかも)、一方でLoss自体は下がる傾向が見えなくて、上下振幅している。オレンジ線のentropy_lossはずっと高いままで、Loss自体はなぜか青い(実行)より随分小さいが、下がる傾向が見えない。これは学習が不安定し、収束しなかった証拠だ。
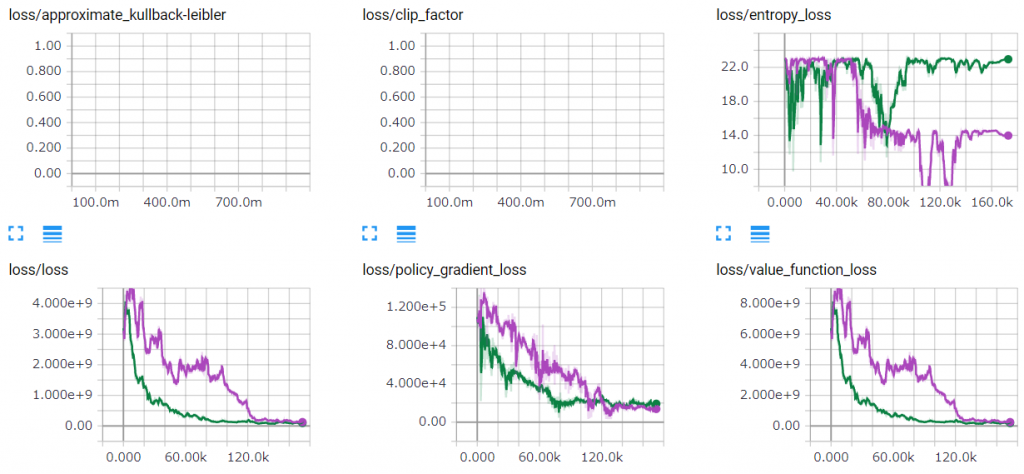
一方、実験で遣った二つケース:A)Sine関数の擬似データ、B)次Tickをリークしたリアルデータ、は収益結果から見ると旨くできているから、学習プロセスはどうなっているか。下図のように、青線(Aの実行)のEntropy Lossが段々下がって、低いレベルに留まった(一時的に下がって上がってのような不安定性も見える)。さらに、Loss自体(Policy Gradient LossとValue Function Lossも含め)は綺麗に下がって、収束したように見える。緑線(Bの実行)のEntropy Lossが高いままが、Loss自体は同様に徐徐に下がって収束した。
ディスカッション
強化学習とFX取引の相性
強化学習モデルは状態空間、動作空間、報酬、Policyにより構成されるもので、FX取引を容易にモデリングできる。状態空間はMarketや自己ポジションなどを定義できる。動作空間はBuy/Sell/Holdのような離散動作でもよい、Buy/Sellの数量を定義してもよい。報酬も確定収益やネット評価損益を定義できる。Policyはつまり状態を見て売買するStrategyである。このように、強化学習モデルにびったり当て嵌まるが、要のところは状態遷移の確率がMarketの現在状態から次の状態への確率になるので、そもそも容易に学習できないはず。つまり、Efficient Marketなら、未来のMarketを予測できないことだから。ただし、上記の実験で示したように、もしSineデータような明確なパターン又は未来の状態を潜む情報が入れれば、強化学習モデルが必ず見つけてくれそう。
また、強化学習が最適化の動作(売買)を見つけられるとはいえ、学習プロセスが極めて不安定なので、報酬関数やLearning RateなどのHyper Parameterのチューニングも大事である。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD