2020.01.10
強化学習のおさらい、DDPGによりFX取引を触ってみる(一)
こんにちは。次世代システム研究室のC.Zです。外国人です。よろしくお願いします。
本文は、DDPGアルゴリズムに辿り着く為、幾つ強化学習の手法を復習してから、DDPGの紹介を次にします。 最後は、DDPGを用いて、FXの取引を少し試してみます。
1、DDPGの前、強化学習のおさらい
理解しやすい為、精密な定義を求めず、基本はシンプルなグラフ+式の形で紹介します。
・Reinforcement Learning(強化学習)
強化学習といえば、以下のようなイメージのグラフが使われていることが多いですね。
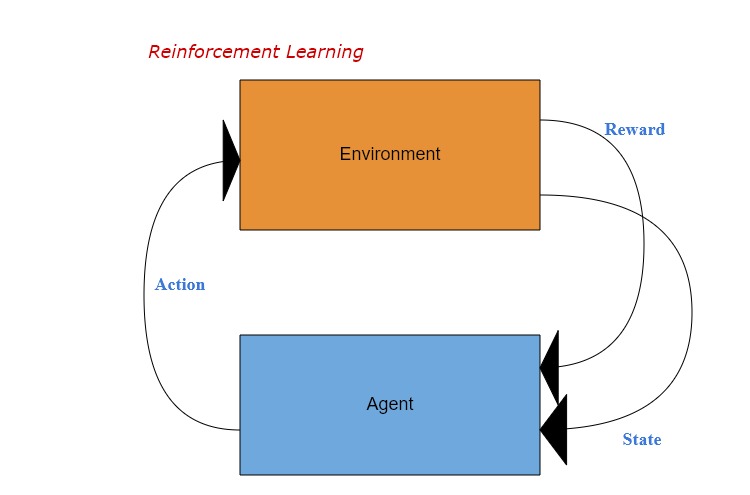
上記グラフを参照するより、最基礎なロジックが自明的なので、本文は略します。 ただし、本文に共通で使われているアルファベット(ギリシア文字)を以下のように定義します。
・s → state
・r → return
・a → action
・![]() → discount factor
→ discount factor
・![]() → policy
→ policy
・![]() → policy parameter
→ policy parameter
尚、利用されているneural network種類の数より、大体以下の3タープに分けられます。
a. Value-based
b. Policy-based
c. Actor-Critic(value-basedとpolicy-basedの組み合わせ)
・Value-based Reinforcement Learning
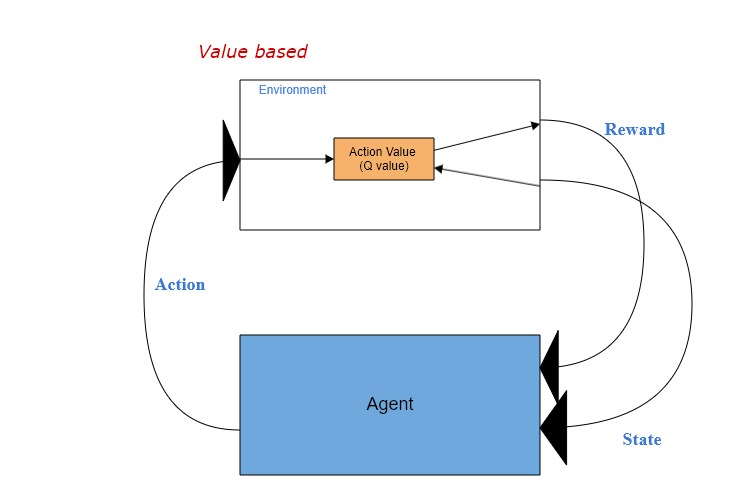
代表的なValue functionとして、Q-learningという手法がこちらで挙げます。 ![]()
金融分野に最も重要なコンセプトの一つ、未来資産の現在価値は![]() ([0,1])*returnより計算されます。
([0,1])*returnより計算されます。
なので、tにおいてのQ値は、stateとactionを条件(input)とし、期間中の累計期待reward(output)です。
・Policy-based Reinforcement Learning
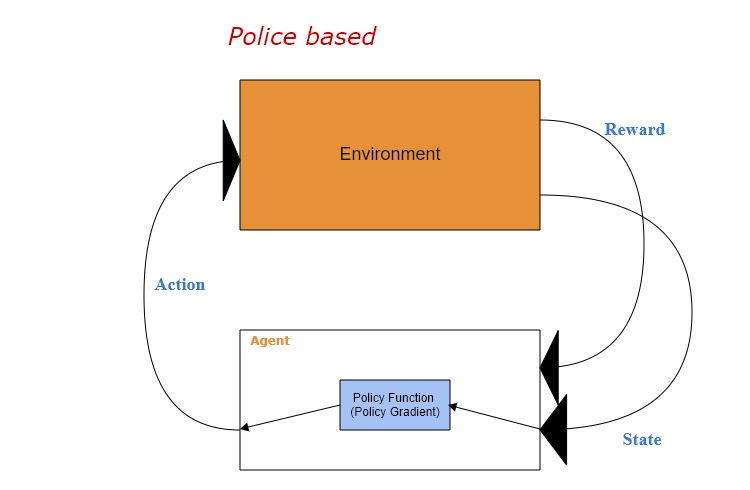
Policy Gradientという代表的なPolicy functionがこちらで挙げます。
Policy functionも収益を最優するための戦略調整であり、一番単純な形で表現すると、以下の式となります。 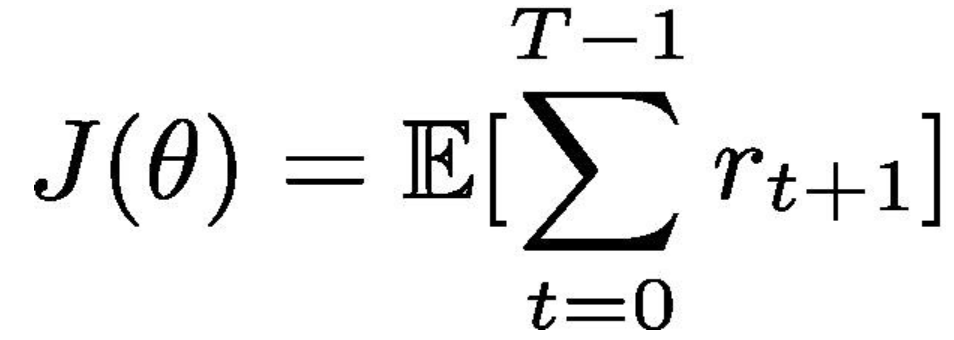
即ち、累計期待returnである![]() を最大化するため、行動戦略parameter
を最大化するため、行動戦略parameter ![]() である を学習より繰り返して調整し、最適の戦略を図ります。
である を学習より繰り返して調整し、最適の戦略を図ります。![]()
右端のpolicy gradientの部分を少し深く入りますと、まずの式を拡張します。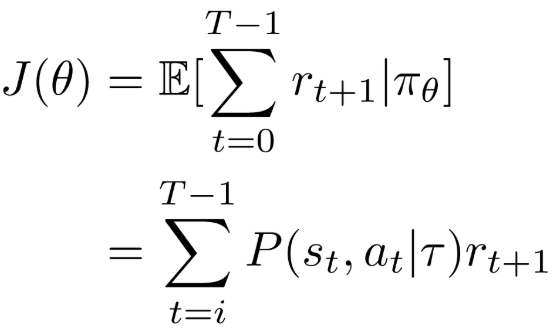
#重要:固定ではなく、確率関数であることを注意してください!
更に、式の左と右をに関して微分とると、最終は以下の式に辿り着きます(詳細は省略)。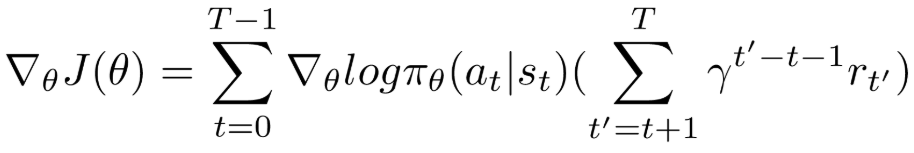
Policy Gradientがようやく分かりました!
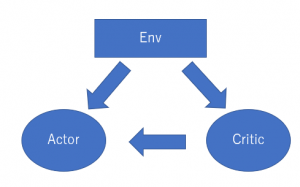
・Actor-Critic (Q Actor-Critic)
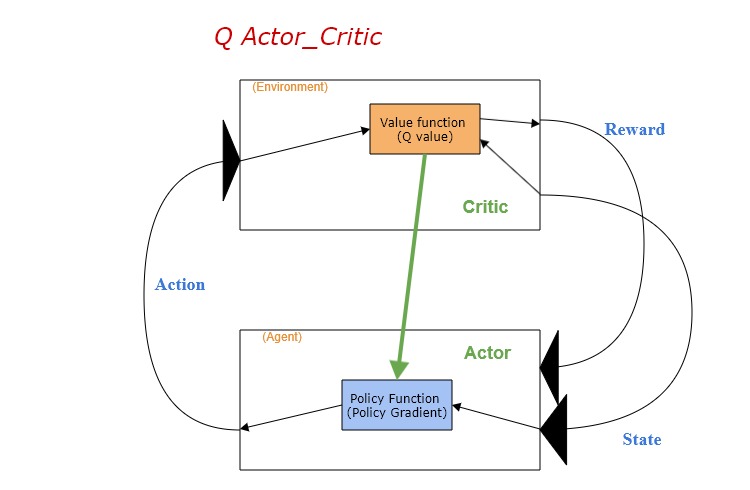
Actor-Criticには二つのneural networkがあります。
・Actor: stateをinput、actionをoutput
・Critic: stateとactionをinput、rewardをoutput
上記のケースでは、criticのrewardはQ valueです。更に、このQ valueを用いてactorのpolicyを更新する(gradient ascent)流れです。
直感的イメージ以外、Actor-Criticのメリットについて、式によりも簡単に説明します。
Policy-basedセクションに紹介したpolicy gradientから見てみましょう。まず、を拡張する際と同じ手法を使うと、gradientの式が以下の形に変換できます。 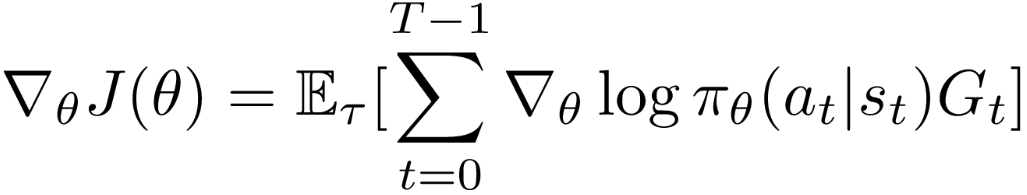
ここでは、![]()
問題はこの式にあります!
policy parameterの更新は、実際はモンテカルロ手法(ランダムでサンプリング)より実施されます。なので、上記式のlog確率と最終の累計rewardが高いボラを生じる可能性があります。
また、rewardが0の際に、機械はactionがいいか悪いかを分別することができないという問題もあります。
以上の懸念点を解決するため、プレーンgradient式に制限項目を導入します。 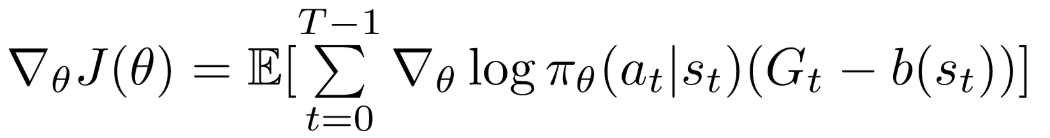
直感的な解説をすると、累計reward減少 → policy parameterが減少と安定 になりますね。
中間の推導は略しますが、以下はQ Actor-Criticの式です。 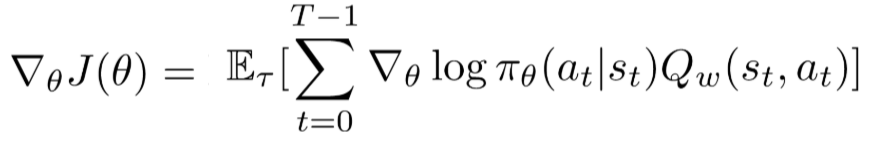
・Advantage Actor-Critic (A2C)
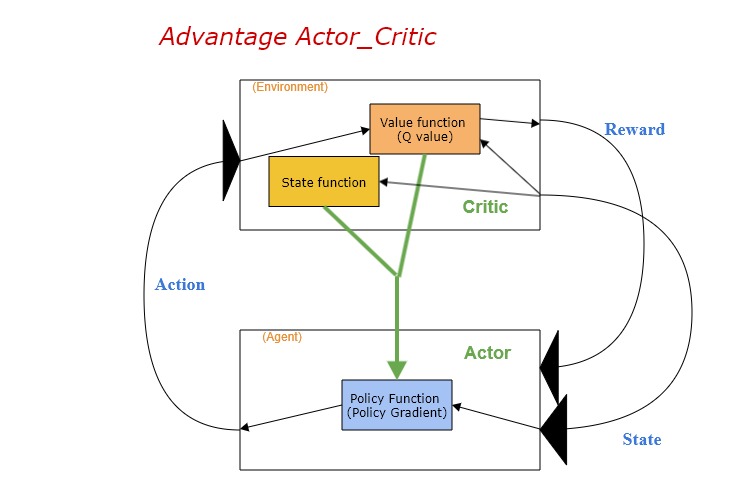
Advantage Actor-Criticは、Q Actor-Criticを加えて、更に一層の制限をかけるアルゴリズム。
ということは、ある特定actionからのQ valueのみで評価することではなく、この特定なactionと一般的なactionの成果比較を評価します。 ![]()
Vはstate functionであり、即ち上で述べた一般的や平均的なrewardです。
但し、Aについて、コンセプト上はvalue functionとstate functionの組み合わせですが、実際はこの二つのneutral networkを使う必要がなく、state functionだけで大丈夫です。(証明略)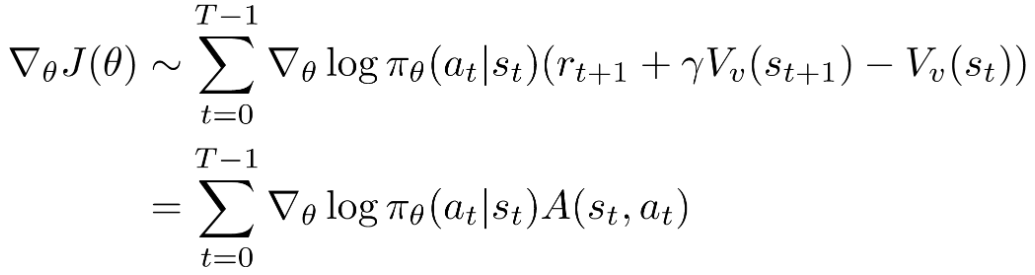
・Asynchronous Advantage Actor-Critic (A3C)
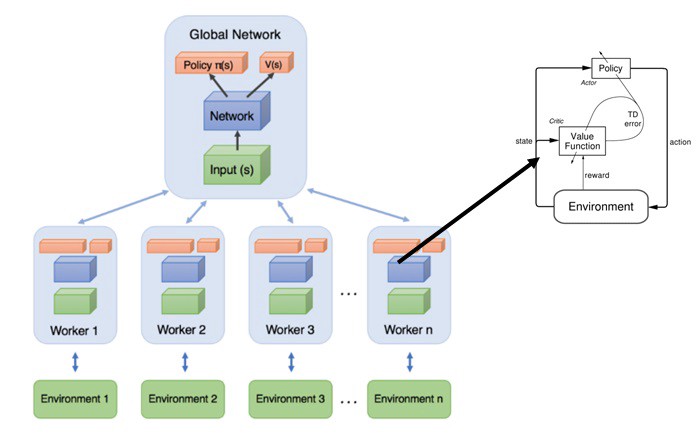
上記グラフで示したように、A3Cは、A2C手法を複数worker同時にそれぞれ独立に処理し、学習結果を一つのglobal networkに持ち込む手法です。
A2Cと比べて、A3Cは理論上の優位性がありそうですあが、近年の研究より、メリットが目立たないみたいですので、処理パフォーマンスを考えると、やはりA2Cのほうがいいですね。
2、Deep Deterministic Policy Gradient (DDPG)
前セッションの幾つアルゴリズムを踏まえ、DDPG手法を紹介します。
まず論文の精密定義を引用します。 
一見みれば、複雑そうですが、段階を分けて順番に説明します。
DDPGはActor-Criticの下に分類されていますので、基本構造についてまず上のAdvantage Actor-Criticの構造図を参照してくだい。
但し、メインな違う点も幾つあります。
・Neutral network
A2C :2つ
a. Q network
b. Stochastic policy network
DDPG:4つ
a. Q network
b. Deterministic policy network
c. Q target network
d. Policy target network
A2CとDDPGのQ networkとpolicy networkはよく似ていますが、区別はActorのoutputです。
・Output of Actor
A2C :stochastic (probability distribution)
DDPG:deterministic (directly)
A2Cのoutputは現在戦略のreward期待値なので、policyの更新には過去経験(バッファに保存された過去の訓練結果)の利用は不可になる。
・Policy Replay Buffer
A2C :使えない
DDPG:使える
毎回の学習にとともに、訓練の経験(action, state, reward)をbufferに保存することができる。
DDPGのoutputがdeterministicのため、Replay Bufferの利用が可能になり、更新policyの分散が抑えられます。
・Target Network
A2C :なし
DDPG:あり
DDPGのtarget networkはただ原始networkのtime-delayedバージョン。
・Q Value
Target network内の計算構造は、実際は原始のnetworkと同じです。ただ、データの安定性を増やす(target networkの目的こそ)ため、原始とtarget valueの差を最小化するように工夫します。
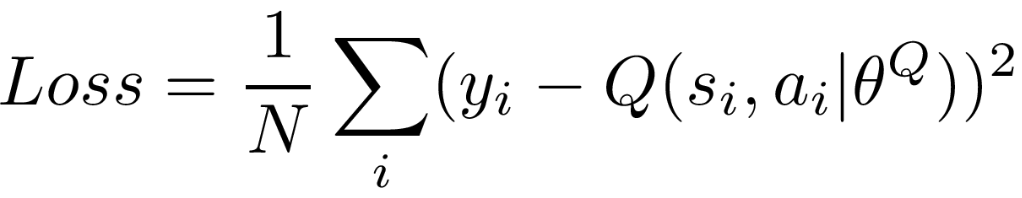
・Policy Gradient
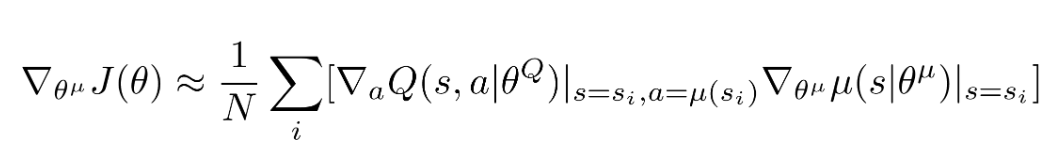
replay bufferが利用されたため、平均値も取りました。
・Target network parameter update
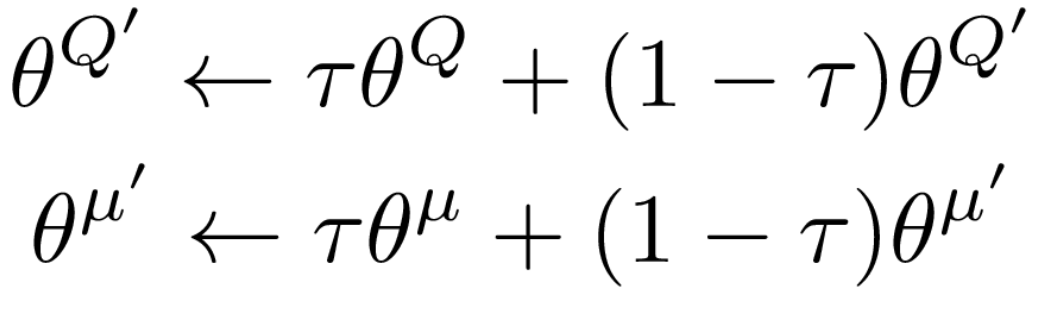
soft更新を利用するので、parameterの安定性が更に向上する。
3、DDPGでFX取引をやってみる(初歩)
今回のブログが、メインはコンセプトの紹介ですので、実践について一番単純な取引条件をベースし、少し触ってみます。
・取引通貨:USD/JPY
https://www.histdata.com/download-free-forex-historical-data/?/metatrader/1-minute-bar-quotes/USDJPY
・フレームワーク: Stable Baseline
https://github.com/hill-a/stable-baselines
・モデル:デフォルト設定
・学習期間:10日
・テスト期間:1日
・取引単位:1000
・一回の最大取引数量:5000(5単位)
・資本金上限なし(自由に取引できる)
・ロスカットなし(リスクコントロールしない)
・決済の損益だけを計算し、保有ポジションの損益計算しない
6回のテストにおいて、予測為替レートは以下のようになります。
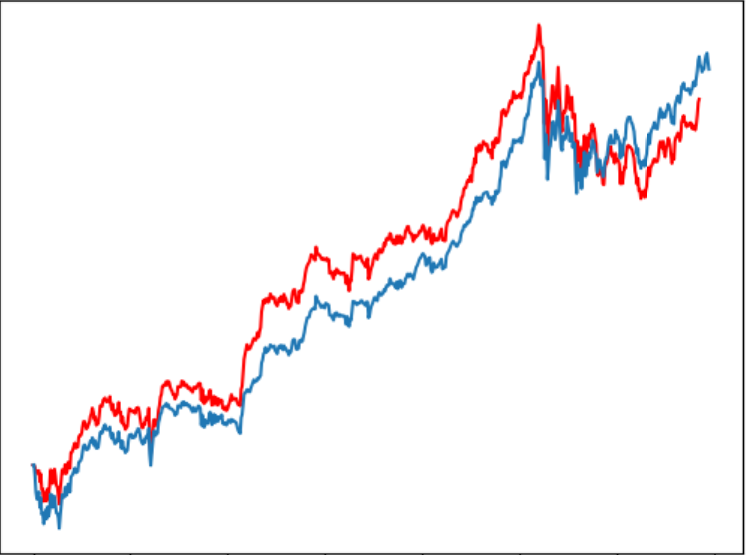
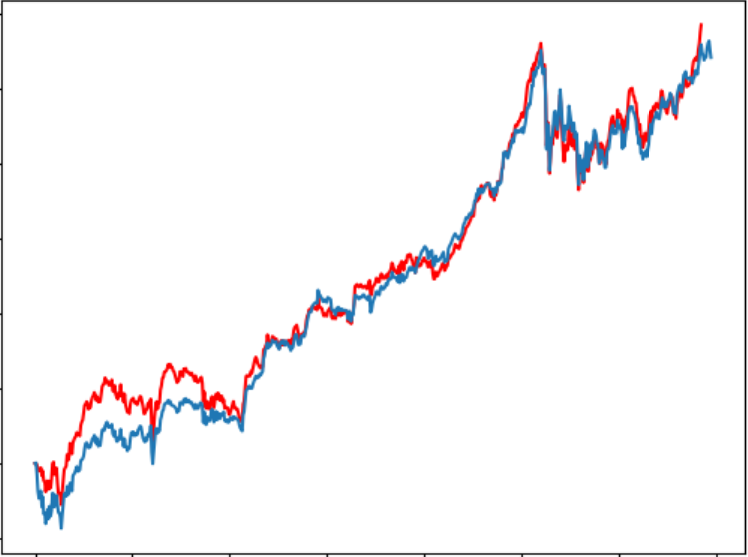
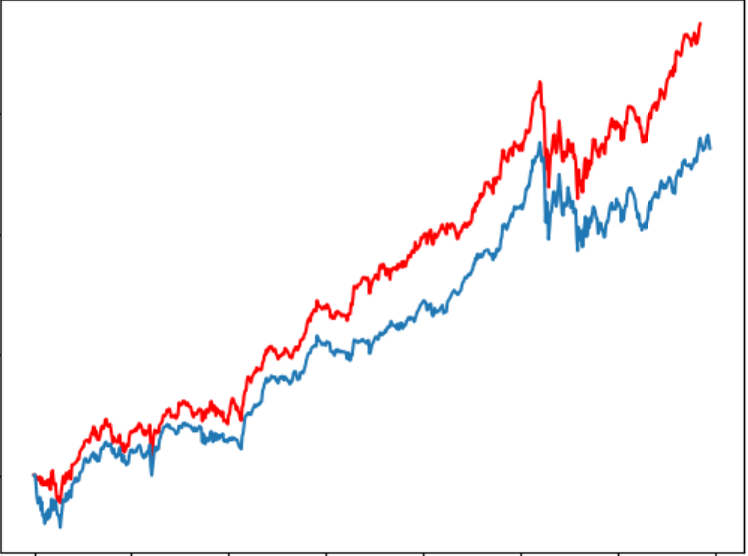
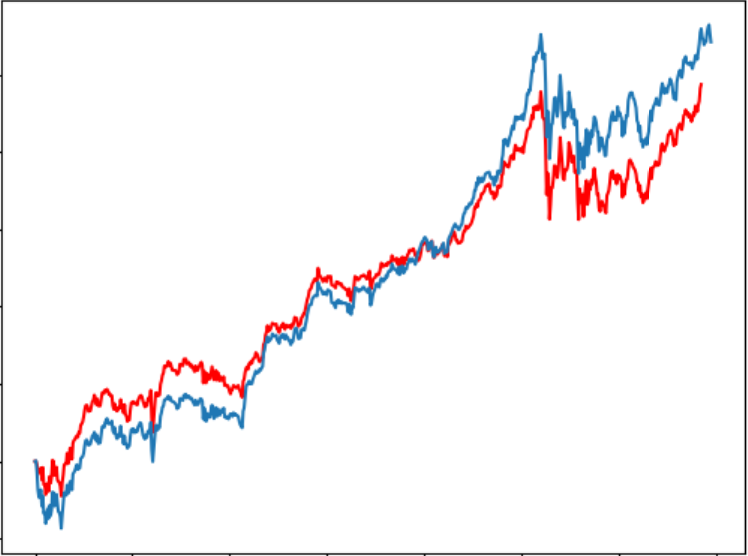
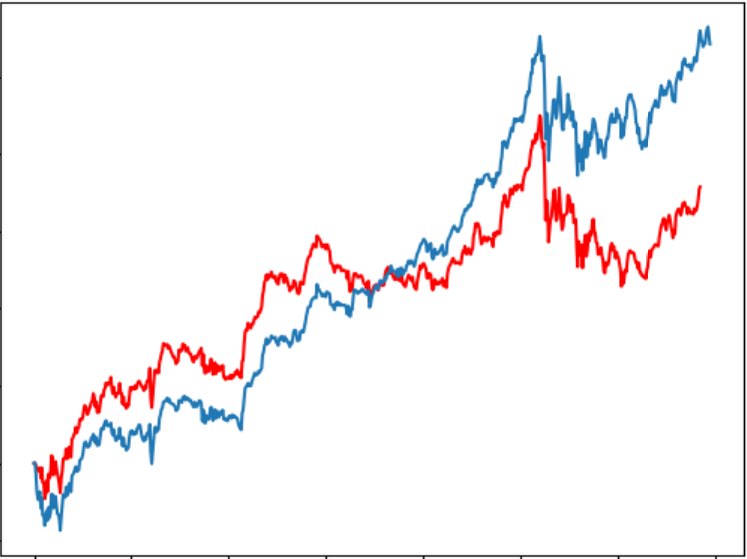
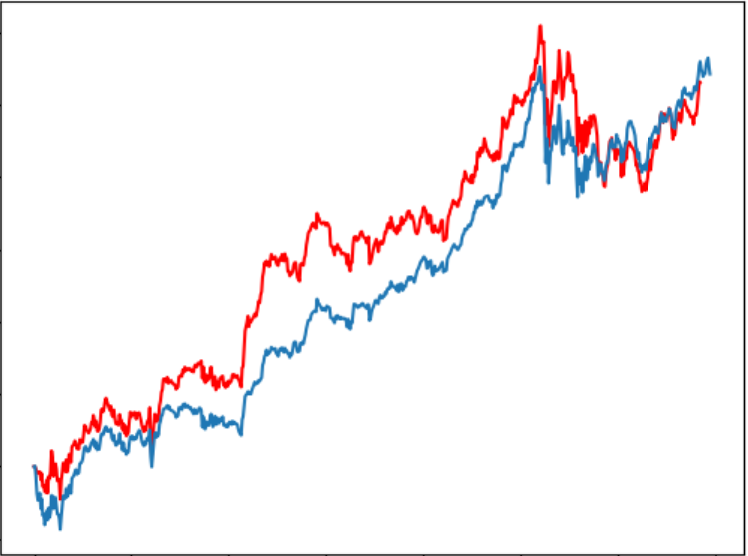
収益はそれぞれ5011、5888、7490、4872、3573、5304となります。
ぎりぎりでしたが、なんと全部プラス!(Lucky!)
しかし、実際は違うテスト期間をやってみると、大損が出た時も結構あります。残念!
次のステップ
次の内容として、
まず、取引条件の設定やアルゴリズムparameterのチューニングにより、DDPGロボ取引を深く検証し、取引詳細などの結果を見せます。
あと、ベイズ統計学の利用やTD3などの拡張手法を紹介し、各手法performanceの比較検証も行います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD