2018.10.11
AIが達人技を体得する技術「敵対的逆強化学習」の紹介
イントロダクション
みなさま、こんにちは(or こんばんは)。
次世代システム研究室のY.Tです。
最近は、急に夏から秋にシフトチェンジして温度変化がダイナミックになっていますが、みなさまはお体に気をつけてお過ごしでしょうか?
私の方は、温かいお風呂とビタミンCのこまめな摂取でなんとか季節の境目を乗り切ろうと奮闘中です。
さて今回は、「敵対的逆強化学習」をテーマとした内容をお届けします。
このブログをご覧になる皆様であれば、「強化学習」というキーワードをすでにご存知かもしれません。
今回取り上げるのは、逆強化学習のアルゴリズムの一つで、達人の手本を見様見真似で模倣するというものです。
どのあたりが「強化学習」の逆なのか、「敵対的」とはどういう忌みなのか、順を追ってご説明したいと思います。
世界チャンピオンを越えるAIを作り上げた強化学習。だが・・・
みなさんは「Alpha碁」というAIをご存知でしょうか?
Googleに買収された深層学習のスタートアップ企業「Deep Mind」社が開発したAIが、囲碁の世界チャンピオンのイ・セドル9段を4勝1敗で撃破したという鮮烈なニュースを覚えているでしょうか。

DeepMind社は、ディープラーニングを基礎とした強化学習、深層強化学習を用いてAIを開発し、膨大な訓練を実施して囲碁の世界チャンピオンに勝利することに成功しました。
見事に世界チャンピオンに打ち勝ったAIですが、その学習に要した計算コストは非常に大きなものでした。
- Google Cloud Platform で、
- CPU1200個、GPU180個を使って、
- 1ヶ月以上計算時間!
おいそれとマネが出来ない敷居の高さです。
普及するのは難しい水準の計算量です。
世の中に普及する上では、このハードルは支障となりかねません。
もっと低コストで、いろいろな人間の達人の技を模倣できるAIが開発できるとなると、普及にとって大きなプラスになるのですが、そんなテクノロジーがあるのか・・・
そこで登場するのが「逆強化学習」というテクノロジーなのです。
今回ご紹介するのは、「逆強化学習」の中でも新しく、深層学習を取り込んだ「敵対的逆強化学習」です。
敵対的逆強化学習とは
敵対的逆強化学習とは、達人(エキスパート)の行動を見て模倣する技術「逆強化学習」が、深層学習テクノロジー「GAN(※)」を取り入れたものです。
※Generative Adversarial Networks:生成的対立ネットワーク
達人のお手本ありき、というところがこれまでの強化学習とは大きく異なっています。
強化学習の課題
まず第一に、「Alpha碁」の例でも分かるように、探索する範囲が広大になると、計算コストが爆発的に膨れ上がることが課題です。
また、報酬が得点のように明確に定義できれば良いのですが、一つの数値で単純に評価がしにくいテーマの場合、報酬を定義することが困難となる可能性があります。
報酬が定義できないと、強化学習を始めることができないため、そのテーマを見送るか強化学習以外のアプローチを取らざるを得なくなります。
これらの強化学習の課題に対する解決方法として提案されたのが「逆強化学習」です。
逆強化学習とは
すでに述べたように、達人の手本を見て、模倣するというのが逆強化学習の基本的な思想です。
従来の逆強化学習には、代表的なものとして以下のアプローチがあります。
- 線形計画法
- 起こりうる状態を丸暗記して手本の再現を狙う。
- Maximum Entropy法
- 状態ごとの特徴を数値化して、報酬の計算式に入力する。線形計画法より実用性が高い
逆強化学習のデモ
従来の逆強化学習のデモとしては、スタンフォード大学/Andrew Ng 教授のチームによるラジコンヘリコプターのアクロバティックな操作の模倣実験が有名です。
(P. Abbeel, A. Ng: “Apprenticeship Learning via Inverse Reinforcement Learning”, Proceedings of the 21st International Conference on Machine Learning,pp.1–8, 2004.)
かなりアクロバティックな操縦をして、見ている側がハラハラするほどですが、これは逆強化学習したAI(モデル)を用いて自動操縦しているのです。
確かに人間の手本の動作をちゃんと身に着けているのですが、実は従来の逆強化学習にも課題があるのです。
従来の逆強化学習の課題
従来の逆強化学習の課題は、ずばり「複雑な課題は模倣困難」という点に集約されます。
ここで「複雑な課題」とは、観測する状態の情報量が多く、さらに状態の変化のバリエーションが膨大な課題のことを指します。
例えば、自分だけではなく、相手の状態も考慮しなければならない、しかも相手が複数いるという課題(将棋や囲碁、複数の敵キャラと対峙するゲームなど)は、状態が持つ情報量も多く、状態から状態への移り変わりのバリエーションが途方もない組み合わせとなります。
こうした「複雑な課題」になると、従来の逆強化学習の表現能力や学習能力では追いつかないのです。
※一方、ラジコンヘリコプターの操縦など、自分自身の状態だけを観測すれば済む課題は、従来の逆強化学習の表現能力・学習能力でも対応できる可能性が高いのです。
では、どうすべきか?
そこで登場するのが、深層学習を取り入れるというアプローチなのです。
深層学習を逆強化学習に取り入れる
深層学習は、その表現能力・学習能力の高さで、機械学習にブレイクスルーをもたらしました。
従来の逆強化学習の課題を解決するに当たっては、もってこいのテクノロジーです。
敵対的逆強化学習は、深層学習の分野の中でも特に発展が目覚しい「GAN(生成的対立ネットワーク)」のテクノロジーに注目し、GANを取り入れたものなのです。
GANは、判定・評価するネットワーク(Discriminator)と、パターンを生成するネットワーク(Generator)の二つのネットワークが切磋琢磨するネットワークです。
この特徴が、逆強化学習の課題解決に多いに役立ちます。

GANの構造
ここで、鍵を握るGANのネットワーク構造を見てみましょう。
以下の図をご覧ください。
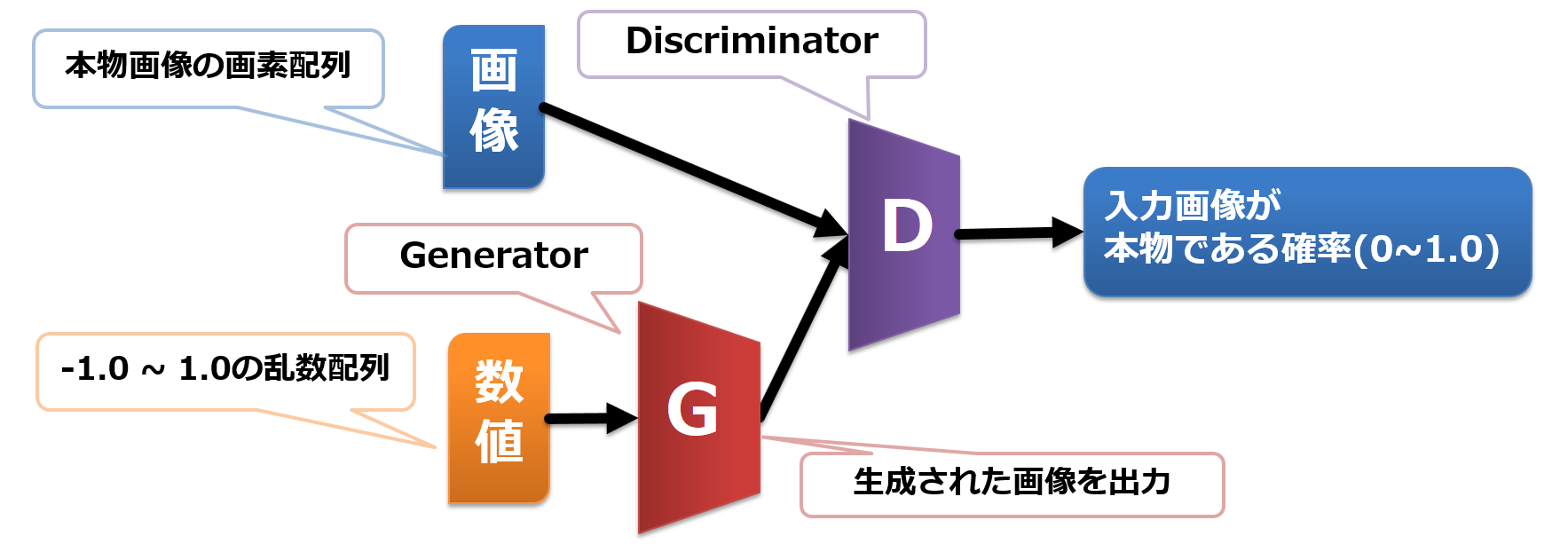
Discriminatorが、入力された画像の真贋を0.0~1.0の数字で出力します。
このDiscriminatorの出力を使って、Generator と Discriminator を競い合わせるように学習させます。
- Generator は、本物と見間違えるような、なるべく精巧な画像を出力するようにネットワークを最適化します。
- 具体的には、Discriminatorの出力が、1.0に近づくようにネットワークの最適化をします。
- Discriminator は、本物は本物、ニセモノはニセモノと見破るようにネットワークを最適化します。
- 具体的には、「本物の画像に対しては1.0を出力する」「ニセモノ(=Generatorが作った画像)に対しては0.0を出力する」という方向にネットワークを最適化します。
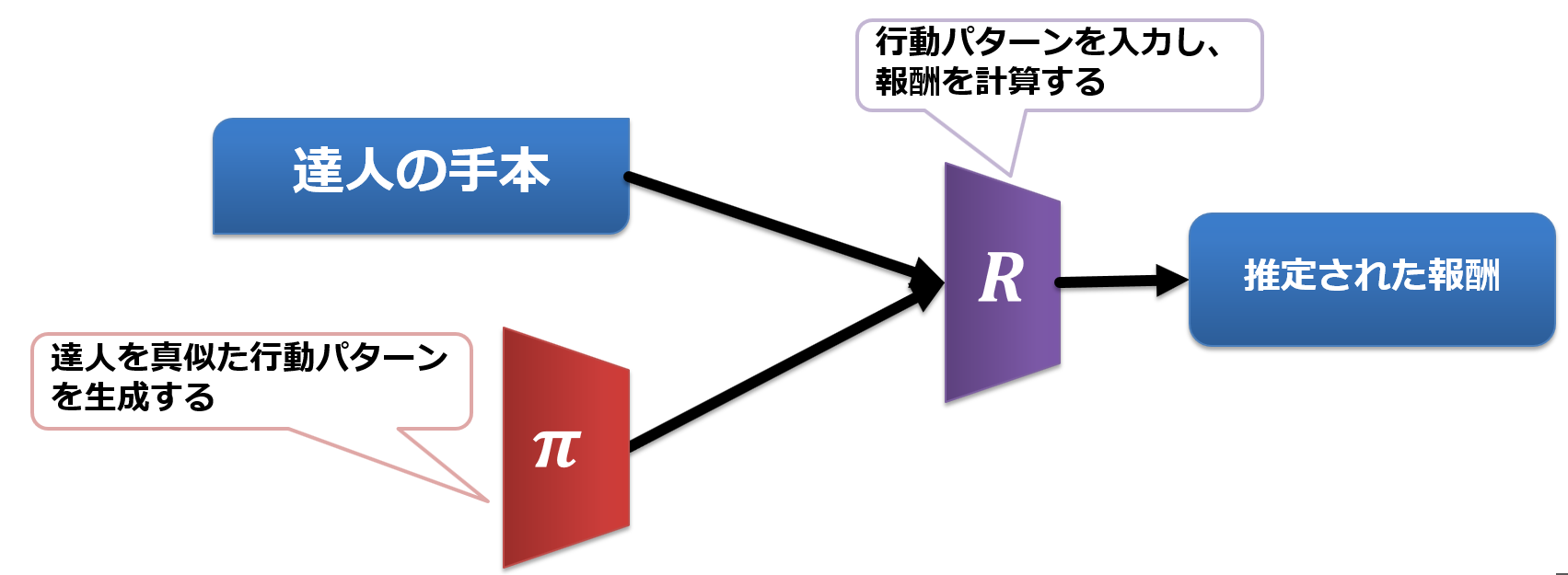
敵対的逆強化学習のネットワーク構造
逆強化学習にGANを取り入れると、このようなネットワーク構造になります。
行動を決定するπネットワークと、行動によって得られる報酬を推定するRネットワークがあるのが分かります。
GANでいうところのGenerator がπネットワーク、DiscriminatorがRネットワークに対応しています。
実験
敵対的逆強化学習の紹介が一段落したので、実験の内容に移りたいと思います。
実験の概要は以下の通りです。
実験概要
- 目標
- 敵対的逆強化学習を用いて、スペースインベーダーゲーム(1978年,Atari2600用)の達人技プレイを模倣する。
- 開発環境
- CPU: Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz x 8
- GPU:NVIDIA GeForce GTX 1070
- Memory:16GB
- OS: Ubuntu 16.04.03
- Python3.5
- 深層学習フレームワーク: Tensorflow , Keras
- 強化学習研究開発フレームワーク「Open AI Gym」
学習データ=達人の手本の準備:フェーズ1
既に述べたように、敵対的逆強化学習はお手本となる達人の動きを必要としています。
そこでまず、人間の手でインベーダーゲームを操作して、達人プレイを目指そうと考えました。
もちろん、エミュレータでただ遊ぶのではなく、各時点における状態・動きを細かくログに記録しなければなりません。
手本となる動きを作成するだけなので、手元のローカルマシンで、ツールを組んでゲームプレイを記録しようとしたのですが、キーボード入力とインベーダーゲームの相性が悪く、OSごとに依存する部分など、原因の追究にスケジュールの多くを費やす恐れがあったので、時間的制約上、このアプローチは断念することにしました。
そのかわり、強化学習を使って、自動的に達人のゲームプレイを作成できないかと作戦を切り替えたのです。
学習データ=達人の手本の準備:フェーズ2
ここでは、深層学習を使った強化学習(Deep Q Network)を使い、達人プレイの実現を目指しました。
レトロゲームの強化学習で既に実績のある手法です。その実績を見込んで、強化学習を数日間続けたのですが、、、
なんと、達人技には程遠い、ポンコツプレイを量産するばかり!
まずは以下のポンコツプレイのサンプルをご覧ください。
このようなポンコツプレイが、夜明けと共にマシンに生成されているのです。
心が折れないまでも、じわじわとヒビが入りそうな気持ちになったのを覚えています。
このままでは、埒が明きません。
一体どうすれば良いでしょうか?
方針転換:独自アルゴリズムでスーパープレイを目指す!
従来の強化学習では、十分な学習を達成するのに、膨大な計算コストが必要になるということを身をもって痛感した私は、泥臭くても良いので、もっと確実な方法を模索していました。
そこで「Infinite Continute Loop = 目標に到達するまで、無限にコンティニュー」という、苦行感は否めないが、より確かな突破力が期待できる方法を考案しました。
そのメカニズムは以下の通りです。
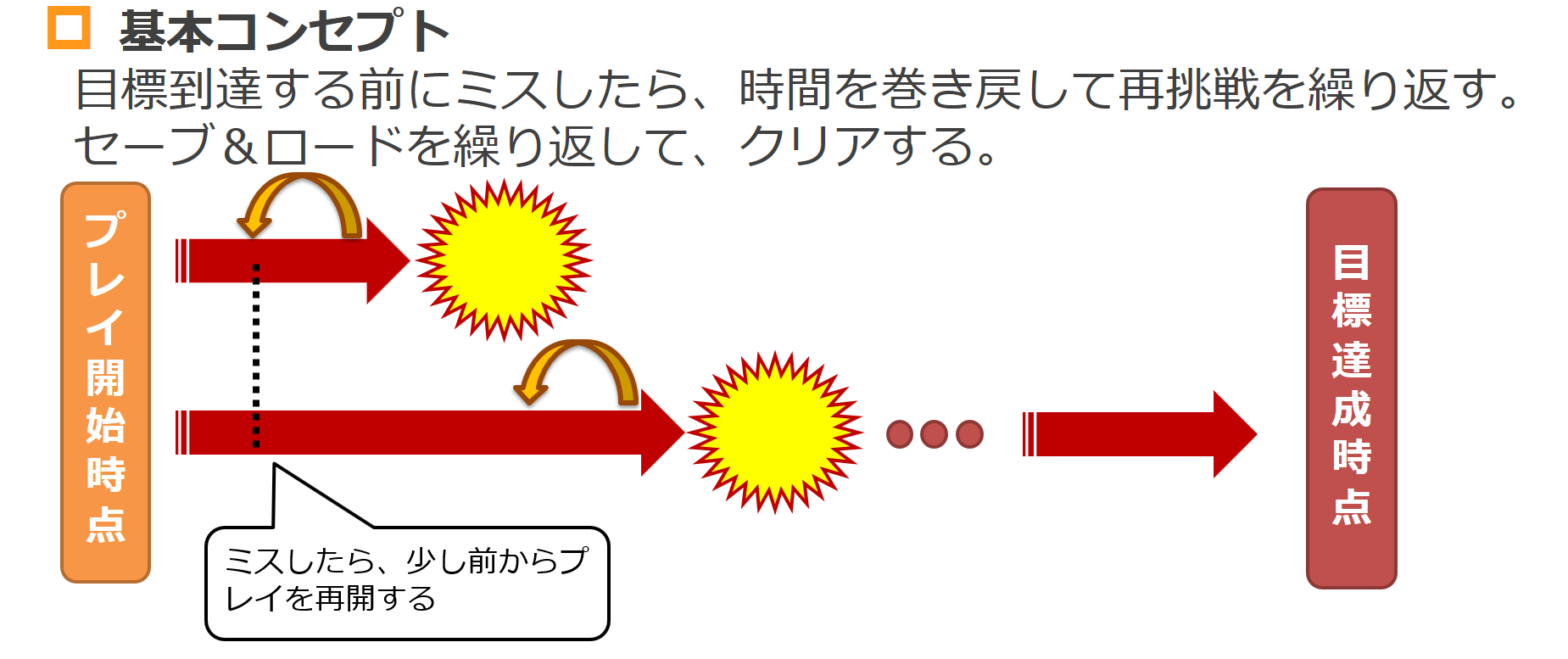
その結果、ついに以下のような高得点を達成できるプレイを量産できるようになりました。
(※ただし、1プレイの生成に1~2時間かかる)
満を持して実験実施!
Infinite Continute Loop アルゴリズムで量産した、達人的なインベーダーゲームのプレイデータを25サンプル準備することができました。
それら25サンプルを使って、敵対的逆強化学習を実施しました。
学習の進行に合わせて、どのように上達してゆくのか?それとも上達しないのか?
それでは見て参りたいと思います。
学習序盤:1時間~4時間後
学習開始から1時間後
以下のようなゲームプレイまでたどり着きました。
学習開始から4時間後
着実に成長が見て取れますね。
そしてついに学習開始から24時間後・・・
ついに2500点に迫るスコアをたたき出すところまで来ました。
達人的なプレイに(少なくとも人間の初心者よりは、ずっとマシなところまで)達することができたように思います。
まとめ
ということで、実験データの準備という、アルゴリズム以外の部分で大きな苦戦を強いられましたが、きちんと実りある実験結果を得ることが出来ました。
- 達人技の模倣は出来たが、スケジュールギリギリまで時間を消費した。計算時間を甘く見ていた。
- 達人の手本データをDQNで生成できなかったときは、本当に焦った。
- GANの利点と同時に課題も取り込んでしまう
- 学習が不安定化することがある。敵対的逆強化学習の実験も、途中で何度かリセットしている。
【重要】最後に
次世代システム研究室では、機械学習や統計処理に関心を持つ開発者、アーキテクト、データサイエンティストを求めています。
自由闊達にのびのびと働きながら学べる環境があります。
コーヒー片手にアカデミックとビジネスの融合したディスカッションをしながら、知的好奇心を満たすことができる環境があなたを待っています。
次世代システム研究室にご興味を持たれたらすぐに 募集職種一覧 からご応募してください。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




