2021.04.08
PDCAがうまく回らないデータサイエンティストを救いたい
~因果推論とビジネス~
こんにちは。次世代システム研究室のY. O.です。
突然ですが、筆者が所属している次世代システム研究室のミッションを、HPから引用します。
次世代システム研究室とは、GMOインターネットグループの事業領域で力を入れているスタートアップやグループ横断のプロジェクトにおいて、技術支援・開発・解析などを行い、ビジネスの成功を支援する部署です。
最新のテクノロジーを研究開発し、いち早くビジネスに投入することで、お客様の発展と成功に貢献することを主要なミッションとしています。
このミッションのもと、筆者は、スマホアプリを運営するグループ会社のメンバーと共に、日々アプリユーザーのための改善施策を実行しています。
そこで今回は、アプリユーザー体験改善 = ビジネスの成功 をデータサイエンティストの立場から実現するために実際に導入している因果推論について、解説していきたいと思います。
0. TL;DR
- データサイエンティストはPDCAサイクルのP・Cに参画してビジネスの成功をサポートして欲しい!
- 手軽に導入できる因果推論手法としてRCT・DID・傾向スコアを紹介!
1. 因果推論とビジネス
因果推論はビジネスのPDCAを支える重要な武器
PDCAサイクルを回してサービスを改善しよう!というのはどのビジネス現場でも語られていることだと思います。そして近年、「データを収集し効果を計測しやすくなってきた。PDCAのC(=Check)をより正確に行おう!」という文脈や、「AI・機械学習を勉強・活用していくうちに、因果推論というのも有名学会で取り扱われているのがわかってきた。これはぜひ自分たちのビジネスにも適用したい!」という文脈などで因果推論がビジネス現場にも登場してきているように感じます。
どのような文脈にせよ「バイアスを排除し見せかけの効果に騙されないで評価する」というコンセプトである因果推論は、ビジネス現場のPDCAサイクルをより定量化できる武器であることは間違いなく、PDCAサイクルを回しても改善を感じられないという場面を減らすことができます。
いくつかの文献によると、この因果推論は計量経済学に区分されるようなのですが、ビジネス現場(少なくともアプリ開発の現場)では計量経済学者よりもデータサイエンティストというポジション方が有名で、データサイエンティストがこの責務を担当することになります。
そのデータサイエンティストとして筆者が主張したいのは「データサイエンティストとしてPDCAサイクルのP・Cに参画する」ことです。これは実際に筆者の現場では実践されていることで、PとCにどのように関わればいいのか・ポイントは何かについて記載します。
[P] Pの時点で始まっている
え、Checkする手法が因果推論なのでは?という疑問をもたれる方もいらっしゃると思いますが、PDCA順の時間軸でサイクルが回っているとすると、データサイエンティストはPlanの段階から参画が必要です。Pの段階で行っておくことは、Cでの因果推論を成功させるための下準備になります。この下準備ができていないと、「効果が出るように複数手法の検証を行う」といった本末転倒なCを実施してしまったり、「そもそも効果測定が不可能に近い状態でCの相談を受ける」といった負け戦に挑むことになってしまいます。
(ここで断っておきたいのは、データサイエンティストはCを成功させるためにPとCを行うだけが責務ではないということです。例えば、D・Aにおける機械学習を用いた開発を行ったり、P・Cにおいても探索的な分析を行ったりします。今回はデータサイエンティストが行う検証的分析の一つである因果推論をビジネスに導入するとしたら、というスコープで書かせていただいています)
[P] どの指標で測定するのか
ビジネスサイドのメンバーと一緒に検証時の指標設定を行います。Planしている施策が何をどうする施策なのかを念頭に、「遅行指標ではないか」「実施施策から遠すぎない指標か」「データを取得し算出できる指標か」を確認します。遅行指標の例としては、MAUといった計算式上のウィンドウの影響で過去成分も含まれてしまうものや、行動変容から発現するまでの(観測できない)潜伏期間があるものなどが挙げられます。また、実施施策から遠すぎる指標の例としては、開発メンバーのデスク整理整頓施策の評価指標として100社を超えるグループの連結売上高を設定するような例があります。この例は極端かもしれませんが、施策から遠い指標にすればするほど効果が測定しづらくなるため、近い指標をPで設定していれば効果が確認できた可能性があるのに「施策に効果は見られなかった」とCの段階で判断してしまう可能性を生んでしまいます。
[P] どの手法で測定するのか
Pの段階で効果計測手法を決定します。本記事ではRCT・DID・傾向スコアを紹介します。
[P] どれだけの期間の実験が必要か
測定手法がなんであろうと、測定した効果にはどれくらいの幅があるのか、区間推定が必要になります。区間推定には、どれだけのデータを集められているか(サンプルサイズが十分か)が関係してきます。ユーザー数やユーザーの利用頻度などを考慮し、先に設定した指標をある区間の範囲で測定するためにはどれだけの期間実験をしなければならないのかを決定します。
例えば、新規ユーザーの〇〇を指標としたのであれば、Dailyのダウンロード数を元に、1%の区間幅で効果を測定したい場合は実験日数が△△日だ、と判断します。
[P] 過去の類似施策ではどれほどの効果があったか
あまり言われないことかもしれませんが、過去の類似施策における改善幅の研究も大切です。施策を打つ以上リソースが消費されているので、過去との比較で最低ラインの見極めを予めしておきたいです。また、改善施策がどのようなものであれ、介入をスタートすること自体に効果がある場合もあるため、ベースラインの把握という意味でも過去の類似施策を研究します。(介入をスタートすること自体に効果がある場合、とは、例えば、アプリの新バージョンリリースをした場合、新バージョンでの改善によりユーザーの利用頻度が向上したという側面だけでなく、そもそも新バージョンのリリース通知によりユーザーの注目を集めたことで利用頻度が向上しただけ、という側面も含まれます。)
[C] 効果検証においてバイアスを取り除くスキル
まさに因果推論のスキルです。先ほど因果推論のコンセプトは「バイアスを排除し見せかけの効果に騙されないで評価する」ことだと述べましたが、このバイアスをいかに除去できるかをスキルと呼んでいます。また、ここでのスキルの引き出しが多いほど、スムーズにPlanできるという側面もあります。
[C] スピードも大切
Cの必要以上な厳密性・学術的考察に興味があるのはデータサイエンティストであるあなたと統計に興味がある一部のビジネスメンバーです。大半のメンバーはすぐに結果が出ると思っていますし、後続のActionをすぐにでも行いたいと思っています。
Pの段階でなるべく測定スキームを構築しておく(コードを書いておく)ことや、頻繁に行う分析であればツール化してしまってビジネスメンバーでも実行できるようにしてしまうことが、因果推論そのもののスキル以外としては非常に重要です。
2. 因果推論 ~手法と実験結果~
RCT(ランダム化比較試験:Randomized Controlled Trial)
いわゆるABテストはRCTに分類されます。「完全ランダムに介入を割り当てている(と仮定できる)」状況において、介入群(A)と非介入群(B)それぞれにおける指標を比較するのがRCTです。
全ての状況においてRCTができれば良いのですが、デメリットとして、コストがかかる・倫理的にNGな場面がある・etc.とよく言われています。その他には、どのユーザーがA/Bなのかがわからないというケースがあります。アプリアップデートを段階リリースする際、App Store/Google Play Consoleの機能を使ってA/Bの割合を指定することができますが、結局アップデートを実施したユーザー(=介入が完了したユーザー)しか把握できず、どのユーザーにアップデート通知が行ったのか(=介入がスタートしたのか)を把握できないという場面がありました。
また、RCTしている風で実はできていないという場面もあります。パッと思いついた例を挙げると、「ユーザーIDが100万番までをA・それ以降をBとしてランダムに割り振り〜」や「完全ランダムにクーポンを配信し、クーポン利用したユーザーをA・利用しなかったユーザーをBとし〜」といったものです。
1つ目の例は、「大概ユーザーIDは登録の時系列順になっているためA群は昔からの愛用ユーザー、B群はどちらかというと新規ユーザー、というバイアスがA群B群間に生まれている」ためRCTの仮定を満たしているとは言い難く、2つ目の例は、「介入をランダムに割り当てているのはクーポンを配信した群とクーポンを配信していない群であり、クーポンを利用したかどうかで群を分けてしまうことにより余計なバイアスが含まれてしまう」ためRCTの仮定を満たしているとは言い難いです。
では、実際に導入しているRCTの一部を紹介します。
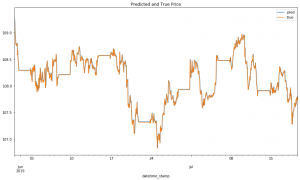
Google Play Consoleでは、ストアの掲載情報(スクショや説明文)についてABテストを実施する機能を提供しています。下図はその機能を利用したABテストの管理画面の結果になります。現状版では現在のバージョン(Current Version)に対して、その他の3パターン(1・2・3)を用意してテストすることができます。
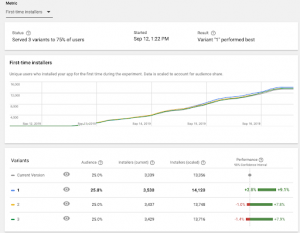
Google Play ConsoleのABテスト機能(外部サイトより引用)
ここで1・2・3について評価結果のレンジが画像右下部分に赤と緑で表示されていますが、みなさんはどのように解釈するでしょうか。この画像だと1のレンジが有意そうなので1を採用するかと思いますが、全てのパターンで2や3のようにプラスにもマイナスにもレンジが振れている場合はどうするでしょうか。このようなケースのとき、少しでも良い方を採用したいビジネスメンバーとしてはレンジの中央がプラスになっている2や3は採用対象になると思います。そのような時は、あらかじめPlanの段階でどのような基準で効果検証をしようとしていたかに照らし合わせて判断するように促すのがデータサイエンティストの役割です。
筆者の現場では、3枠目には必ずCurrent Versionと全く同じストア掲載情報を、1・2と全く同じサンプルサイズにして指定するように決めています。これにより、全く同じ掲載情報なのに(推定効果は0であるはずなのに)効果に幅が生じるのを目の当たりにすることで、推定効果には区間があることを納得しやすくなります。
DID(差の差法:Difference in Differences)
介入群と非介入群について時系列的な並行性があるという仮定(並行トレンド仮定)により群間のバイアスを考慮する(打ち消す)ことで、介入後にその並行性が崩れた分を効果の量とする手法がDIDです。簡単な例を2つ用意しました。下図1つ目では介入群が介入後で②の分だけ指標がプラスになっていることがわかります。この時、①の値を効果だと考えてしまうと、実際の効果を課題に見積もってしまうことになります。下図2つ目も基本構造は同じで、①ではなく②を効果として採用してください。ただし下図2つ目を掲載したのには理由があります。それは①を効果として採用すると一見プラス効果があるように見える場合でも、実は(②では)マイナス効果があるケースがあるということです。
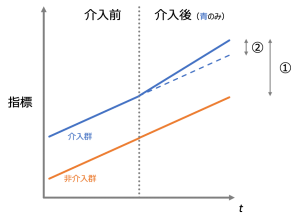
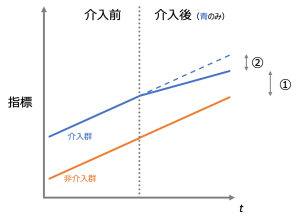
DIDでは②を効果として推定する
傾向スコア
各サンプルについて介入の対象となりそうな傾向をスコア化し、そのスコアを利用して介入群・非介入群の介入効果以外のバイアスを考慮する(打ち消す)方法が傾向スコアを用いた手法になります。(筆者はkaggleで統計・機械学習に興味を持ち始めたという背景があり、傾向スコアのアイデアを初めて学んだとき、「Adversarial Validationと似た考えだなぁ」と理解した記憶があります。)
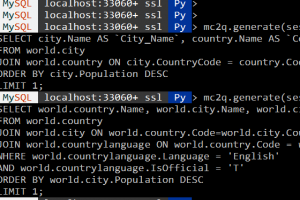
まずは傾向スコアの算出方法です。ここでは、介入群となるか否かの2値判別モデルを作成することになります。出力が確率値になるロジスティック回帰を用いても、流行りのGBDTでモデリングしても良いようです(図)。また、出力値についても確率値ではなく、出力順をランキング化した値をスコアとして利用する方法もあるようです。
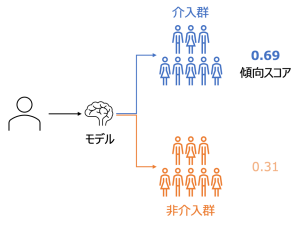
CREATE MODEL
`[[project_name.]dataset_name.]model_name`
OPTIONS(
MODEL_TYPE='BOOSTED_TREE_CLASSIFIER'
,MIN_REL_PROGRESS = 0.01
,BOOSTER_TYPE = 'GBTREE'
,NUM_PARALLEL_TREE = 1
,MAX_ITERATIONS = 50
,TREE_METHOD = 'HIST'
,EARLY_STOP = TRUE
,SUBSAMPLE = 0.85
,DATA_SPLIT_METHOD = 'CUSTOM'
,DATA_SPLIT_COL = 'valid'
,INPUT_LABEL_COLS = ['target'])
AS
SELECT
* EXCEPT (ユーザーID)
,CASE WHEN MOD(ユーザーID, 10) IN (8,9) THEN TRUE ELSE FALSE END AS valid
FROM ユーザー特徴量
INNER JOIN 介入有無の正解データ USING (ユーザーID)
傾向スコアを計算するモデルをBigQuery MLで作成するクエリ
CREATE TABLE
`[[project_name.]dataset_name.]table_name`
AS
SELECT
ユーザーID
,predicted_target_probs[OFFSET(0)].prob AS prob
FROM ML.PREDICT(
MODEL `[[project_name.]dataset_name.]model_name`,
TABLE ユーザー特徴量)
作成したモデルで傾向スコアを予測するクエリ
続いて、傾向スコアを利用して介入群・非介入群の介入効果以外のバイアスを考慮する(打ち消す)方法について2種類紹介します。
1つ目はIPW(Inverse Probability Weighting)です。全ユーザーに介入したとき、しなかった時の接続体験の期待値をそれぞれ![]() 、
、![]() と表現すれば、
と表現すれば、![]() が求めたい値となり、
が求めたい値となり、![]() については次式で推定します。
については次式で推定します。
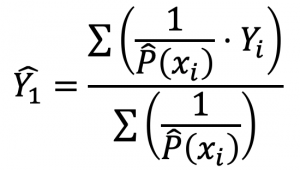
![]() の推定量
の推定量
式の分母分子に![]() という傾向スコアの逆数が登場しています。ユーザーの特徴から高い確率で介入群と推定される場合には
という傾向スコアの逆数が登場しています。ユーザーの特徴から高い確率で介入群と推定される場合には![]() で表現されるサンプルの重みが小さくなり、逆に介入群とはならなさそうだと推定されたのに実際には介入が起こった場合、このサンプルには大きな重み付けがされます。
で表現されるサンプルの重みが小さくなり、逆に介入群とはならなさそうだと推定されたのに実際には介入が起こった場合、このサンプルには大きな重み付けがされます。
2つ目は傾向スコアマッチングです。下図のように、介入群の傾向スコアに似たユーザーを非介入群から探してきてペアを作成することでバイアスを取り除き、その差をペアの数だけ計算することで効果を推定します。
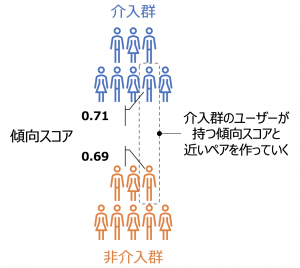
傾向スコアマッチングの概要
1の時に介入有を表す確率変数![]() を導入すると、このようにペアを作って推定した効果は下式のようになります。先ほどのIPWでは全ユーザーに関しての効果を推定していましたが、傾向スコアマッチングでは介入群(
を導入すると、このようにペアを作って推定した効果は下式のようになります。先ほどのIPWでは全ユーザーに関しての効果を推定していましたが、傾向スコアマッチングでは介入群(![]() )についての効果を推定しています。
)についての効果を推定しています。
![]()
傾向スコアマッチングで推定する効果
3. 最後に
技術ブログらしからぬ文章多めの記事となりました。紹介している手法自体は様々な文献で取り上げられていますので厳密な部分はそちらに譲りますが、本記事の特に前半部分が、タイトル通り、PDCAがうまく回らないデータサイエンティストのお役に立てていたら嬉しく思います。
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD