2019.12.24
自然言語処理の技術紹介:危険すぎる(GPT-2)モデルと関連する技術を試してみた話(簡単な翻訳、ニュースの内容とFX動きの予測)
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
そろそろ今年(2019年)も終わるということで、今年、盛り上がっていた人工知能(AI)の一部の関連技術をふりかえってみました。自分の勝手な印象ですが、今年の気になった技術だと、自然言語処理といったAIの一つです。特に、びっくり技術ニュースといえば、危険すぎると言われた自動文章作成モデルGPT-2だろうなと思いました。ということで、今回のブログでは、GPT-2についての勉強と簡単な実装を共有させて頂きたいと思います。
遡ってみると、2019年2月に、OpenAIといった有名な人工知能(AI)を研究する非営利団体がテキスト生成などの大規模な自然言語モデル(GPT-2)を発表しました。しかし、当時、発表したモデルは一部分しか公開されず、段階的な公開という方針でした。理由はモデルの精度が高すぎて、フェイクニュースなどオンラインでなりすましの危険があったからです。その時から、私は少し気になっていました。そして、いつか完全モデルが出てきたら勉強してみようと思っていました。11月に、ようやく完成モデルが公開されました。そこで、このGPT-2モデルはなにがすごいのか、なぜ危険だと言われたのか、ブログで一緒に見て行こうと考えています。
では、このブログの構成は、以下のとおりです。
① 自然言語処理とは?
② AttentionとTransformer
③ Zero-shot learning
④ GPT-2モデル
⑤ 実装
⑥ まとめと考察
まず、本格的に技術の話に入る前に、そもそも「① 自然言語処理とは?」を簡単に復習させて頂きます。それから、GPT-2モデルを理解するため、主な基本的技術「②AttentionとTransformerと③Zero-shot learning」を説明します。これらの技術を理解した上で、「④GPT-2モデル」をお話させて頂きます。最後に、「⑤実装」でtransformerでの簡単な翻訳とGPT-2モデルでのテキスト分類(ニュースの内容とFXの動きの予測)を共有します。説明が少し長いですが、好きなセクションを楽しく付き合って頂ければ幸いです。
① 自然言語処理とは?
自然言語(Natural Language or Ordinary Language)は人間がお互いにコミュニケーションを行うために自然に発生した言語です。日本人だと日本語、私みたいな外国人だと母国語(たまに日本語?)のような感じです。その日常的に使っている自然言語をコンピュータに理解と処理させる一連の技術が自然言語処理(Natural Language Processing; NLP)です。コンピュータが言語を処理できたら、翻訳、テキスト分類、文法訂正、感情分析、などに適応することも可能です。
実はよりよく言語を処理するため、技術的なアイデアとしては昔(1900年代)から、研究者が言語を単語に分割し、確率論的や統計学的な手法で単語を理解した上で、翻訳、感情解析、コンテンツの分類を研究したりしていました。それに、2000年代からは、コンピュータの性能と共に、自然言語処理の技術進歩が急速に発展しています。統計的な手法から、ニューラルネットワーク(特に、ディープラーニング)という技術に少しずつ移動しています。一般的な代表といえば、RNN(Recurrent Neural Network)、LSTM(Long-short term memory)といったディープラーニング技術です。それらの関連技術がますます発展し、2017年にTransformer(Self-attention)技術が発表され、大きな進歩に貢献していると言われています。Transformerの技術はState of the art (機械翻訳の現王者;SOTA)になり、その後のSOTA(googleが提案したBERTモデル、 OpenAIが提案した危険と言われたGPT-2モデル、など)もほぼTransformerの構造を利用したものです。
それでは、Transformerはなにがいいのか、次のセクションで説明したいと思います。
② AttentionとTransformer
上記に述べたように、このセクションは自然言語処理に貢献しているTransformer技術について書かせて頂きたいと思います。ちなみに、これから説明するTransformerは大きなロボットが出ていた映画のTransformerではないです(笑)。
Transformerを理解するために、まず、Attentionを理解することが必要です。私にとって、技術論文の参考以外だと、この記事の可視化説明とこの本の詳細説明がわかりやすかったので、興味がある方のご参考になればと思います。
Attention
(ここでは、機内でのお願いとご注意の「Attention、please」の話ではなく、自然言語処理の技術の話です。笑)
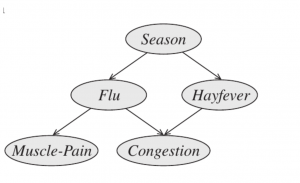
自然言語は時系列データのようなものです。沢山の単語が系列(順番、sequence)で繋いで、文章を作成します。機械が言語を翻訳するための有名な技術の一つはsequence-to-sequence(Seq2Seq)モデルです。文章を単語に分けて、単語を一つずつ訳していきます。例えば、下記の図のように、日本語「タイへ行きタイ」から英語「I want to go to Thailand」に翻訳しようとしたら、まず、入力(input)日本語文章を単語「タイ、へ、行き、たい」に分けます。単語一つずつをモデルに入れます。モデルが日本語の単語をencode(データを他の形式へ変換する機能)し、ベクトル(長さと向きの情報を持つ数字)に変換します。それから、ベクトルを英語の単語にdecode(他の形式へ変換したデータを元に戻す機能)し、モデルから英語の単語を出力します。
Encoderモジュールもdecoderモジュールも中身は時系列データを扱うのが得意なRNN (Recurrent Neural Networks)です。単語一つは一つの数字ベクトルとして、設定します。系列でRNN encoderに入力していきます。例えば、ステップ①、単語#1を入れると、hidden state#1が出力されます。ステップ②、単語#2とhidden state#1がhidden state#2を出力します。繰返し、最後のhidden stateがdecoderの入力になります。
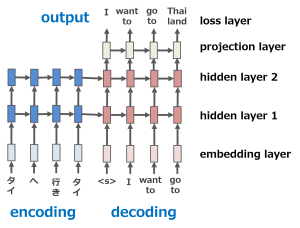
簡単な文章だと、sequence-to-sequenceモデルで高精度に翻訳できますが、文章が長くなると難しくなります。この手法では、文章を入力するときに、encoderの長さが固定されます。そうすると、とても長い文章だと、短い文章と同じベクトルの長さに変換しなければならないです。長い文章を固定長のベクトルに入れすぎると、情報が溢れすぎて、encodingするとき大事な情報が消させる可能性があります。
主な二つの改善ポイントはencoderとdecoderの改善です。
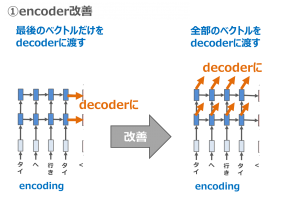
一つ目、encoderの改善です。Seq2Seqモデルは文章をencoderで変換するときに、隠れ状態ベクトル(hidden states)を通して、最後のベクトルだけをdecoderに渡します。Attentionは全部のhidden statesの情報をdecoderに渡します。そうすると、大事な情報を消さず、全部の情報をencodeすることが可能になります。
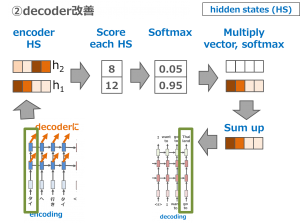
Transformer
(繰返しになりますが、Transformerロボットの話ではなく、自然言語処理の技術の話です。笑)
Transformerは2017年に Attention is all you needという論文で提案されました。一言で言うと、transformerの重要技術はself-attentionです。上記に説明したように、Seq2SeqやattentionのencoderとdecoderはRNNを利用します。しかし、RNNは時系列データを扱うのが得意ですが、データを順番で入力します。大量のデータになると、計算時間がかかってしまいます。スピードを改善するため、transformerはRNNの代わりに、attentionを利用し、self-attentionが提案されました。なぜ、self-attentionなのか、理由が主に3つあります。一つ目、一つの層の計算の複雑さを減らすことです。二つ目、並列の計算を可能にすることです。三つ目、長さの依存の必要性をなくすことです。
それでは、Self-attentionの構想に対応するため、transformerの大事な2つのポイントを見て行きたいと思います。
① 沢山のencoderとdecoderを重ねた構造を利用します。こうすると、複雑なタスクに対応することが可能になります。
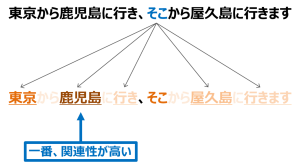
一言で言うと、self-attentionは系列(順番、sequence)の表現を計算するために、単一の系列の異なる位置の関連性を付けるメカニズムです。「東京から鹿児島に行き、そこから屋久島に行きます」の文を読むときに、人だと、「そこ」は「鹿児島」を指していることが簡単に推定できますが、機械だと簡単には、わかりません。Self-attentionは機械に文章の関係性を理解させるための手法です。例えば、単語「そこ」の意味を示したいときに、他の位置にある単語を参考にしながら判断します。そこで、Self-attentionを使うことで、単語の関係性を推定することが可能になります。ちなみに、Tensor2Tensorの可視化がわかりやすいので、ご参考になればと思います。
A) 三つのベクトル(Queries, Keys, Values)を作成します。
B) scoreを計算します。
C) scoreを8で割ります。
D) softmaxを計算します。
E) softmax × valuesを計算します。
F) sumします。
最後に出て来た値は単語の関係性になります。

Transformerは計算量も抑え、並列計算もできるため、大きいモデルで大量のデータを扱うことも可能になります。そこで、Transformerがベース技術になりました。BERTやGPT-2などもTransformerを利用しています。
③ Zero-shot learning
Zero-shot learningは機械が見たことがないものを予測するための機械学習の技術の一つです。 例えば、馬を見たことがある子供がはじめて縞馬を見たときでも、白と黒のストライプを持つ馬だろうと想像できます。しかし、機械では馬の写真と名前だけを学習したため、見たことがないシマウマを認識することはできません。それは、人間が既存の知識をベース化し、見たことがあるものと始めて見たものの関連性を繋ぐ能力があるからです。機械に学習したことがないものとあるものの関連性を繋げる能力を高めるため、機械に推論の力を付けることが必要です。そのための技術の一つはzero-shot learningです。
下記の図を参考にしながら、説明させて頂きます。例えば、犬、馬、車の絵を学習するときに、一般的な機械学習は犬、馬、車、をラベルし、学習します。Zero-shot learningはさらに犬、馬、車(用語はインスタンスと言います)の見える視覚クラスを分類します。そうすると、見たことがない猫が犬や馬のクラスに近いということを予想することが可能になってきます。つまり、人間のように、見たことがなくても、見たことがあるものの関連性を推論することができます。
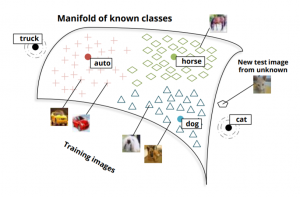
 stanfordの論文より転載
stanfordの論文より転載さらに、最近の技術だと、学習したことがなくても、他のところで学習したものがあれば、それと関連性を繋ぐことも可能です。そうすると、別のところから、猫のベクトル空間の情報があれば、未知の猫写真がその猫のクラスに近いとわかれば、その写真は猫ですと推論することも可能です。そこで、大規模なモデルで学習したことがなくても、対応することが可能になります。
また、簡単に数式的な説明や実装例は他の方のブログがまとめてありますので、そちらの方も参考になるかと思います。それから、以前、私もzero-shot learningを適応できるメタ学習(Meta-Learning)について書かせて頂きましたので、ご参考になるかと思います。
④ GPT-2モデル
基本的な技術の長い説明でしたが、いよいよ、本題です。GPT-2モデルの紹介です。
自分なりに勉強したところ、一言で簡単にGPT-2といえば、「transformer + zero-shot learning + big data」だと思います。


上記にtransformerを説明するため、簡単にattentionとself-attentionを紹介しましたが、実は細かく説明すると、attentionは様々な形があります。transformerはRNNの代わりに、attentionを入れたことはself-attentionという言葉は使われています。しかし、実は、大規模なデータを対応するため、self-attentionを繰返し計算するのが必要です。そこで、アルゴリズムの最後に一つステップが追加されます。正確に、一つステップが追加されたself-attentionはmulti-head attentionと言います。この二つ単語(self-attentionとmulti-head attention)のアルゴリズムは少し違いますが、たまり混ぜて使われている気がします。また、multi-head attention(self-attention)と似ていますが、注目している単語以降は計算に参考をしないようにしたアルゴリズムはmasked multi-head attention (masked self-attention) です。masked multi-head attention (masked self-attention) は今まで見ていた単語だけを使って、確率的に次の単語を予測していくアルゴリズムです、masked multi-head attentionを使うことで、次の単語の予測も可能になり、自動文章生成などにも繋がります。
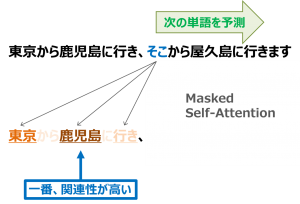
transformerのencoderはmulti-head attentionを使い、decoderはmulti-head attentionとmasked multi-head attentionを使います。GPT-2は沢山のmasked multi-head attentionが入ったdecoderを利用していることで、次の単語の予測するのは強いです。
おまけ:GPT-2とBERTの違い
自然言語処理の有名な学習済みモデルといえば、OpenAIのGPT-2モデルより、GoogleのBERTモデルを答える方が多いのではないかと思います。ですので、GPT-2とBERTはなにが違うのか、少しだけおまけに書かせて頂きます。
簡単に説明すると、GPT-2もBERTもTransformerの技術を適応していますが、GPT-2はdecoder部分、BERTはencoder部分を重ねた構造です。
BERTはencoder (multi-head attention)を利用するため、空白に単語を埋めるのが得意です。逆に、GPT-2はdecoder(masked multi-head attention)を利用するため、次の単語を予測するのが得意です。かつ、GPT-2が機械が学習したことがないものを予測したいので、zero-shot learningを加えられました。
また、様々な学習済みモデルの記事の参考で、GPT-2とBERTの比較や自然言語の転移学習です。
⑤ 実装
それでは、いよいよ、実装です。今回、やってみたいことは二つあります。
一つ目は、Seq2SeqとTransformerで簡単に英語を日本語に訳してみることです。
二つ目は、GPT-2モデルでニュースの内容を分析し、FXの動きを測ってみることです。
すべての実装はgithubに入れておきましたので、興味がある方はご参考になればと思います。
実装環境
GMO GPUクラウドを利用させて頂きました。主な実装はpython, tensorflow, kerasです。
マシン: GPUクラウドbyGMO マシンスペック GPU : NVIDIA® Tesla® V100 SXM2-16GB 開発環境: Docker tensorflow/tensorflow:latest-gpu-py3-jupyter 言語環境: Python 3.5 主なライブラリ tensorflow-1.14.0 keras-2.2.5
実験①:簡単に英語を日本語に訳してみた
日本語と英語のデータ準備
日本語と英語データは manythingsサイト からダウンロードし、使わせて頂きました。また、「② AttentionとTransformer」のセクションで説明したSeq2Seqの文章の長さ限界と、AttentionとTransformerの改善を実験するため、使われたデータは短い5,000文と長い5,000文で合計10,000文でした。
実装の流れ
Seq2SeqとTransformerの実装の流れは主なところはほぼ似ています。まず、文章のデータを単語に処理します。それから、英語と日本語はそれぞれ、encoder_inputとdecoder_inputとして、処理します。最後に、それらのinputをモデルに入れて学習します。詳細はjupyter notebookに参考して頂ければと思います。Seq2Seqでの翻訳はここ、Transformerでの翻訳はここです。
学習結果
今回の学習結果は下記になります。青い線はTrainingデータの結果、オレンジ線はValidationデータの結果です。図を見てみると、Training accuracyは学習回数(Epochs)と共に、増やしていったため、モデルがちゃんと学習していたことが確認できました。しかし、Validation Accuracyは思ったよりあまり上がってくれなくて、Validation Lossも上がっていたので、モデルは少しoverfittingに見えます。一つ考えられる理由はデータ量だと思います。Validationのとき、出た単語はTrainセットがなくて、機械が始めた見た単語だったりしたら、関連性を繋ぐことができなかった可能性があります。今度、またの機会があれば、検証するため、TransformerとZero-shot Learningの組み合わせ実験をやってみたら、どうかなあと思ったりしています。
翻訳した例
学習したモデルはどういう感じなのかをイメージを掴むため、例文を試してみました。
Seq2Seqでの翻訳結果
Seq2Seqでの翻訳結果は下記になります。もっと、試してみたい方はJupyter notebookを遊んでみてください。自分は始めて自然言語処理を勉強したので、よければ、感想やコメントがあれば嬉しいです。
Transformerでの翻訳結果
Transformerでの翻訳結果は下記になります。データセットはSeq2Seqと同じです。
実験②:GPT-2でニュースの内容とFXの動きを測ってみた
それでは、最後のセクションはGPT-2の実験です。GPT-2モデルでニュースの内容を分析し、FXの動きを測ってみることです。実装コードはgithubにありますので、ご参考になればと思います。
FXとは?
今回の実験を理解するため、「FXとは?」の知識が少し必要ですので、簡単に復習させて下さい。FX(Foreign exchange,外国為替証拠金取引)は他の国の通貨を売ったり買ったり(取引)して、売買時の価格差による利益を狙うことです。例えば、今日は、1ドルは100円とします。私は100円を1ドルに投資して、ドルを買います。もし、明日は円が安くなって、1ドルが120円になり、そのときに投資した1ドルを売れば、20円の利益が出ます。

仮説
この実験の仮説はびっくりニュースが出たら、FXは沢山動くだとうと思います。いい例ではないですが、例えば、bankrupt(破産)のような否定的な印象が沢山出てたら、FXのトレンドが下がって行くし、hope(希望)のようなポジティブな印象が沢山出てたら、FXのトレンドが上がっていくだろうと仮説にします。この仮説は本当かどうかを検証するため、過去のニュースで出た単語を処理し、FXの変動に影響する単語を分類します。分類はやり方は色々な機械学習の手法がありますが、今回はせっかくGPT-2を勉強したので、GPT-2を使ってみます。
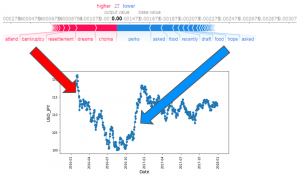
データ
FXデータは forextester から、2016/1ー2018/6のUSDJPYデータをダウンロードしました。データは一日一点で、毎日10:00時データを抽出します。ニュースデータは kaggle news-category dataset から、ダウンロードしました。ニュースのデータは41種類がありますが、FXに関係ありそうな3つのカテゴリー(CRIME, BUSINESS, IMPACT)に絞ります。学習したデータセットは下記な感じです。FXが上がった日はsign=1、下がった日はsign=2、変らない日はsign=0にしました。また、一日にはニュースが何件がありますが、全部の件数を学習します。
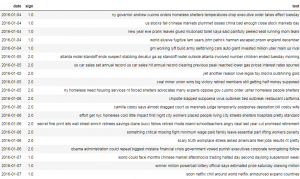
モデル
GPT-2モデルを使わせて頂きましたが、一つだけを注意していただきたいです。GPT-2モデルのoutputは2 None dimensionsがありますが、今回はテキスト分類のため、outputは1 None dimensionに減らしました。残りは基本的に転移学習で学習済みGPT-2モデルを再利用という感じでした。
GPT-2モデル設定
import os
from keras_gpt_2 import load_trained_model_from_checkpoint, get_bpe_from_files, generate
# Set up filename and path for loading trained model
model_folder = 'gpt-2/models/1558M' # 117M, 345M, 774M, 1558M
config_path = os.path.join(model_folder, 'hparams.json')
checkpoint_path = os.path.join(model_folder, 'model.ckpt')
encoder_path = os.path.join(model_folder, 'encoder.json')
vocab_path = os.path.join(model_folder, 'vocab.bpe')
print('Load model from checkpoint...')
# Get pretrained model for transfer learning
pretrained_model = load_trained_model_from_checkpoint(config_path, checkpoint_path)
bpe = get_bpe_from_files(encoder_path, vocab_path)
GPT-2のdimension調整
from keras.models import Sequential
from keras import optimizers, losses
from keras import layers
from keras.layers import LSTM, Embedding
import keras.backend as K
# Create the model
model = Sequential()
# Add the pretrained model
model.add(gpt2_model)
# Add new layers
model.add(layers.Lambda(lambda x: K.mean(x, axis=1)))
model.add(layers.Dense(y_train_ohe.shape[1], activation='relu'))
# Compile model
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# Show model summary
model.summary()
学習結果
学習結果は下記になります。Training Accuracyは上がっていく傾向が見られましたが、不安定に見えます。かつ、Validation Accuracyはなかなか上がってくれませんでした。もしかして、Trainingの期間に出たニュースはValidationの期間が出ていなくて、別の単語が出てきた可能性があります。
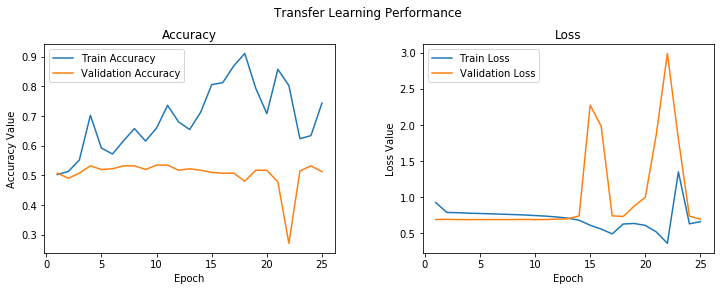
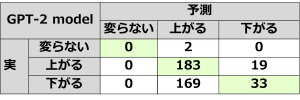
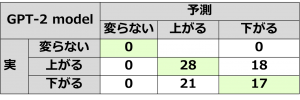
個人的には、正直、今回の実験仮説ではまだGPT-2の全性能を発揮することができていません。機会があれば、また様々なアイデアで改善してみたいのです。
⑥ まとめと考察
今回は自然言語処理技術について、基本的な知識から簡単な実装までを紹介しました。Transformerといった有名なアルゴリズムに触れつつ、危険と言われた最新の自然言語処理モデルGPT-2も試してみました。期待通り、学習済みモデルの適応性は簡単でした。また、精度について、FX予測は足りませんが、それなりに悪くないと思います。
また、実はGPT-2リリースしてから、たった1ヶ月ですが、最近はまた他のモデルがどんどん出てきています。自分の、のんびり遊びながらたまに少し勉強のスピードだと、自然言語処理分野の発展を追いかけられないと感じています。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD