2022.04.08
深層学習以外、確率グラフィカルモデルの紹介
こんにちは。次世代システム研究室のA.Z.です。
今回のブログでは少しい前の機械学習の分野ではやったモデルフレームワーク、グラフィカルモデルと直近のトレンドについて紹介いたします。
グラフィカルモデルとは
グラフィカルモデル(Probabilistic Graphical Model)とはグラフ理論と統計理論の組わせたモデルであり、該当ドメインの中にあるすべてのフィーチャ(確率変数)の関係性がグラフの構造として表現されるモデルです。各フィーチャ(確率変数)はノードとして表して、変数と変数の関連性はエッジで表現されます。
グラフィカルモデルのコンセプトは理論上でBayes理論に基づいて構成されます。その結果、変数と変数の間の関連性やグラフ構想などを構成するときに、ドメイン知識もモデルに簡単に組み込みできるので、柔軟性がかなり高い。また、Neural Networkの場合は、異なるユースケースに異なるモデルアーキテクチャ利用されていますが、グラフィカルモデルの場合は、同じフレームワークで、どんな問題でも利用できるという特徴です。
一方、グラフィカルモデルも様々な欠点があります。大きな欠点はスケールしにくいとデータの準備または処理の工数がかかります。利用している確率変数の数が増えると、グラフの構造の複雑さや推論(inference)する時間がものすごく上がります。また、学習するときに、異常値(outlier)にはとても敏感なので、変数が増えれば、データの前処理の工数が増えます。
上記の欠点にも関わらず、ロバストさ、モデルの透明性さなどの観点からすると、かなり良いので、ミッションクリティカルの分野(医療検査、金融など)には幅広く使われています。
グラフィカルモデルの種類について
利用するグラフタイプ(有向・無向)によって、グラフィカルモデルの種類は2つの種類に分かれています。
有向グラフ形式(bayesian Network)
変数の関連性が有向グラフで表現される場合は、bayesian networkと呼ばれます。
有向グラフでは、各変数の親に対して、条件付き確率と表しています。
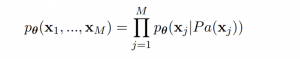
P_a(x_j)とは構成グラフにある、親ノードを表しています。例えば、以下のBayesian Networkの場合は、同時確率分布の定義は以下になります。
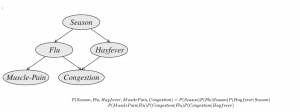
無向グラフ形式(Markov random fields)
変数の関連性が無向グラフで表現される場合は、Markov Random Fields(MRF)と呼ばれます。無向グラフなので、変数と変数の間の関連性は条件付きの確率でできないため、代わりに変数と変数関連性は相関スコアーを計算するための関数に代用されます。MRFの同時確率分布の定義は以下です。
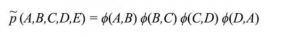
Φは相関スコアーを計算するための関数。例えばRestricted Boltzman Machine(RBM)の場合は、こちらの関数はenergy関数になります。
グラフィカルモデルの利用について
グラフィカルモデルを利用するときに、基本的に、必要なステップは以下です。

普通の機械学習モデル(Random Forest, Neural Networkなど)の利用するときに比べて、Model Buildingの部分がことなります。具体的に、各ステップで何を行っているか簡単に説明します。
Model Building
こちらのステップはグラフィカルモデルを利用するときのみ特集なステップです。一般的な機械学習モデル(random forest, neural networkなど)が、モデルのアーキテクチャがもう決まって、こちらステップが不要です。一方、グラフィカルモデルの場合は、どのようなモデル(グラフ)構造になるか、各ユースケースが違います。各変数の依存関係の定義がこちらのステップで定義する必要です。
構造の定義方法自体基本的に手動か自動で行っています。各変数の依存関係やドメイン知識がはっきりしていれば、ドメインエキスパートがこちらの構造を作成します。一方、変数の数が多くまたは依存関係はあまりはっきりしていない場合は、データから学習し、モデル構造が自動的に作成されるケースもあります。
グラフ構造を自動的に学習するためのアルゴリズムは一つの例としてHill-Climbing optimizationという手法です。(今回の紹介は省略)
Learning
こちらのステップは基本的に一般的な機械学習モデルと同じで、モデルのパラメータを学習行います。一般的に、Maximum Likelihood Estimation (MLE)またはBayesian Parameter Estimation
Inference
こちらのステップは基本的に一般的な機械学習モデルと同じで、モデルのパラメータを学習行います。一般的に、Sampling手法(Markov Chain Monte Carlo(MCMC))と近似手法(Variational Inference)がよく使われています。こちらのステップでは、partial情報から、推論したい変数を推論を行います。
直近のグラフィカルモデルモデルのトレンドと深層学習との関連性
グラフィカルモデルは2010までは、機械学習の分野の中に、かなり、人気でした。当時グラフィカルモデルの代表的なモデルはLDA(Latent Dirichlet Allocation)とRestricted Boltzman Machine(RBM)です。LDAとRBMについて、当サイトにある過去のブログで紹介されましたので、ぜひご参考ください。
約2012年以降(alexnetのbreakthrough)以降、Deep Learningの手法のほうが、人気が集まって、グラフィカルモデルの人気度が低下したように見えています。おそらく最近機械学習触っている方があまりグラフィカルモデルの話題が出てこないと思います。こちらのフレームワークが古いではと思われるかもしれませんが、実はグラフィカルモデルのコンセプトは今の深層学習にも利用されています。
グラフィカルモデルのフレームワークの柔軟性やロバストな特徴のおかげで、深層学習分野の中でも、グラフィカルモデルのフレームワークの応用も出てきます。一番重要な手法はvariational auto encoderです。次は簡単にvariational auto encoderについて紹介します。
Variational Auto Encoderとは
Variational Auto Encoderに入る前に、まずAuto Encoderについて簡単に説明します。
Auto Encoderは一つニューラルネットワークモデルの種類であり、データ次元を空間Aから空間Bにmappingするためのモデルです。こちらの空間マッピングの処理はembeddingとよく言われています。具体的に、inputデータからニューラルネットワークのencoderにデータ流して、その後、encodedしたをdecoderに流して、inputデータを再現(reconstruction)します。最後に、inputとreconstructionの誤差をloss関数として、最小化されます。具体的に、以下の図になります。
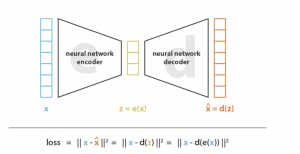
引用:https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Auto Encoder自体は、mappingという役割が果たすことができますが、データ生成の役割に利用するのはできません。そこで、 Auto Encoderをベースにデータ生成の機能ついているのはvariational auto encoderになります。
Auto EncoderとVariational Auto Encoderの違いは基本的に以下の図になります。

引用: https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
一言いうと、Auto Encoderが学習するときに、マッピング方法を学習します。一方、Variational Auto Encoderは学習するときに、マッピングの分布を学習し、分布がさいあれば、分布から、データが生成できます。
マッピングの分布の学習について、簡単に説明します。例えば、データ(x)がある潜在的変数zから生成されますP(x|z)。そうなると、xの生成プロセスは以下のグラフィカルモデルのように表現できます
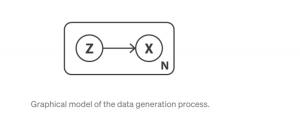
引用:https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
- まず、zをP(z)からsampling
- x をzからsampling P(x|z)
最終的に、観測できるxから潜在変数のzの確率P(z|x)を認めたいため、最終的な式は以下になります。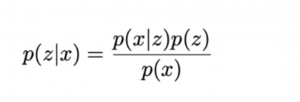
上記から、P(z)とP(x|z)はGaussian分布を想定しそれぞれP(z)とP(x|z) はN(0,I)とN(μ,δ)という分布のパラメータになります。P(z)とP(x|z)がさいわかれば、P(z|x)が計算できますが、正確な計算を難しく、近似的に、variational inferenceでP(z|x)を計算されます。variational inferenceを利用しているため、variational auto encoderの名前がつけられています。最終的に、学習時のフローとLoss関数定義は以下の図になります。
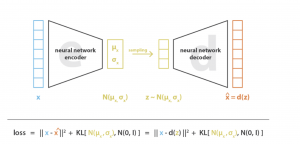
引用:https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Loss関数で分布の距離(Kullback Leibner)の部分がありますが、こちらはできるだけP(x|z)とP(z)の分布が近づくように最適です。目的はできるだけinput(x)と潜在変数(z)と近づくためです。
上記の方法では、一つのニューラルネットワークにグラフィカルモデルの応用方法または例が参考にできると思います。今後、こちらのベースに、様々な場面で、グラフィカルモデル+ニューラルネットワークの組み合わせモデルも応用できるてきます。
具体的に、ソースコードの実装などの場合は、以下のtensorflowの例に参考できます。
https://www.tensorflow.org/tutorials/generative/cvae
今後の様相される展開
直近では、Deep Learningの分野がかなり発展して、様々な新しいbreakthroughがでていました。例えば、transformerという構造が出てから、ほとんどSOTA(State Of The Art)モデルはtransformerベースに構成されてます。一番有名なのは、自然言語処理の分野の中で、BERT、GPTなどが様々な自然言語処理のタスクに応用されます。しかし、こちらのモデルは深層学習モデルの欠点、ブラックボックスの特徴がまだ残っています。モデルの中に、どのような学習されるかなぜ結果がこうなっているかなかなか説明ができない問題があります。またドメイン知識や世の中のルール(common-sense)などのモデルに導入するのはまだ様々な課題残っていると思います。直近、AI neurosymbolic(Neural Networkとsymbolic reasoningの統合モデル)の分野に注目高まっています。こちらの分野で、今後グラフィカルモデルの活発化する可能性があると思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットフォームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方にはぜひ 募集職種一覧からご応募をお願いします。
参考:
https://jonathan-hui.medium.com/machine-learning-graphical-model-b68b0c27a749
https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Kevin, Murphy. “Machine Learning: A Probabilistic Perspective.” Adaptive Computation and Machine Learning series
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





