2019.10.15
FX予測においてON-LSTMとGANはLSTMに勝てるのか?
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
久しぶりに、 次世代システム研究室の発表会を担当させて頂きました。そのような経緯で、これまでブログで「日常の遊び×技術」を取り上げてばかりだった私は、今回、もう少し真面目に「金融×最先端技術」というネタを書かせていただきます。
今回、主に紹介したい技術は Ordered-Neuron(ON)です。 Ordered-Neuron(ON)はICLR2019の論文賞を受賞しました。論文の内容は自然言語の技術的な課題を解決するため、LSTM (Long short-term memory)を改善しました。LSTMは自然言語だけではなく、時系列データ予測にもよく使われているため、この論文の手法はFXデータのような時系列データにも適用できるのではないかと考えました。ということで、最新のON-LSTM関連の技術を金融データに試すことにしました。
では、このブログの構成は、以下のとおりです。
① ON-LSTM (Ordered-Neurons Long Short-Term Memory)
② GANとON-LSTM
③ FX予測実験
④ まとめと考察
参考:発表スライド
ちなみに、全体的に、今回のブログ内容は大きなテーマになり、いつもより少し濃いので、他のデータサイエンティスト方との分担で書くことになりました。FX、時系列データ解析、LSTMの詳細説明はそちらを参考にして頂ければと思います。丁寧に説明して頂いている真面目なデータサイエンティストのブログですので、ご確認いただければと思います。
① ON-LSTM (Ordered-Neurons Long Short-Term Memory)
さて、ON-LSTMはなに? なにを改善したのか?を見て行きたいと思います。
Ordered-Neurons(ON)は自然言語についての技術的な課題を改善するために提案された手法です。このアイデアは今年(2019年)の主要機械学習カンファレンスICLRのベスト論文賞(best paper award)を受賞しました。受賞したアイデアはなにか面白いのかを簡単にまとめさせて頂きます。
自然言語(特に、文章の構成)を解析するときに、様々な考え方がありますが、この論文によると、自然言語では単純な系列ではなく、階層構造(constituency tree)のような形(a)で考えているようです。この階層構造を導入し、階層の情報をうまく引き出し、効率的に学習することができたら、よりよい解析精度が期待できます。その階層の情報を引き出す技術の一つはLSTM (Long short-term memory)です。

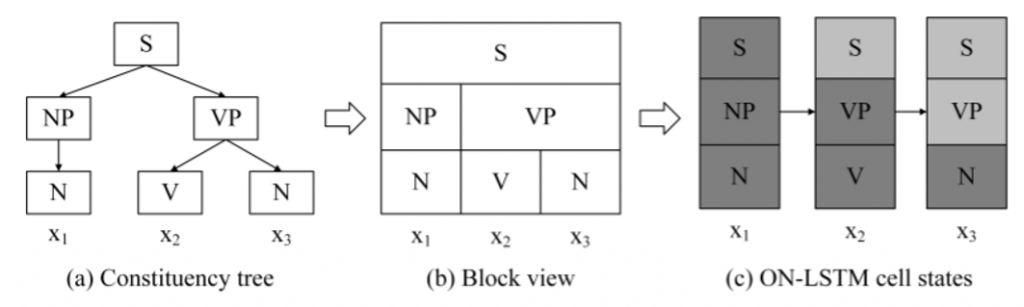

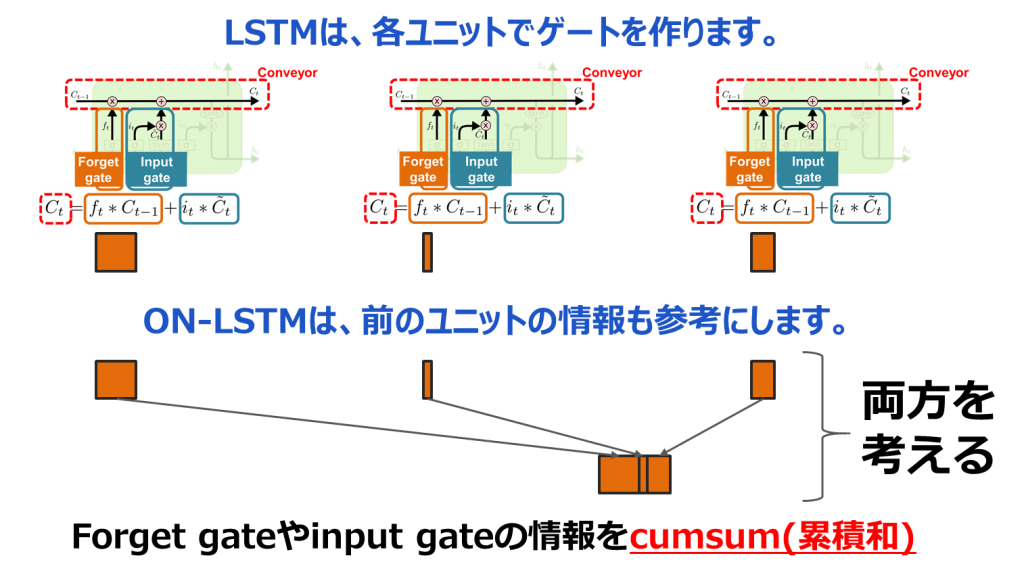
二つ目、structured gating mechanismはforget gateやinput gateの情報をcumsum(累積和)するという提案です。普通のLSTMは各ユニットでゲートを作ります。例えば、最初のLSTMユニットのゲートは前のデータを忘れたほうがいいよということになると、forget gateの重みは大きくなり、次のゲートは前の情報を忘れないほうがいいということになると、forget gateの重みが小さくなります。その各ユニットのパラメータが独立しています。ON-LSTMは前の忘れる情報も参考にするため、cumsum(累積和)を使います。こうすることで、各ゲートの情報を引き続くことが可能になります。
式を書くと下記の感じになります。
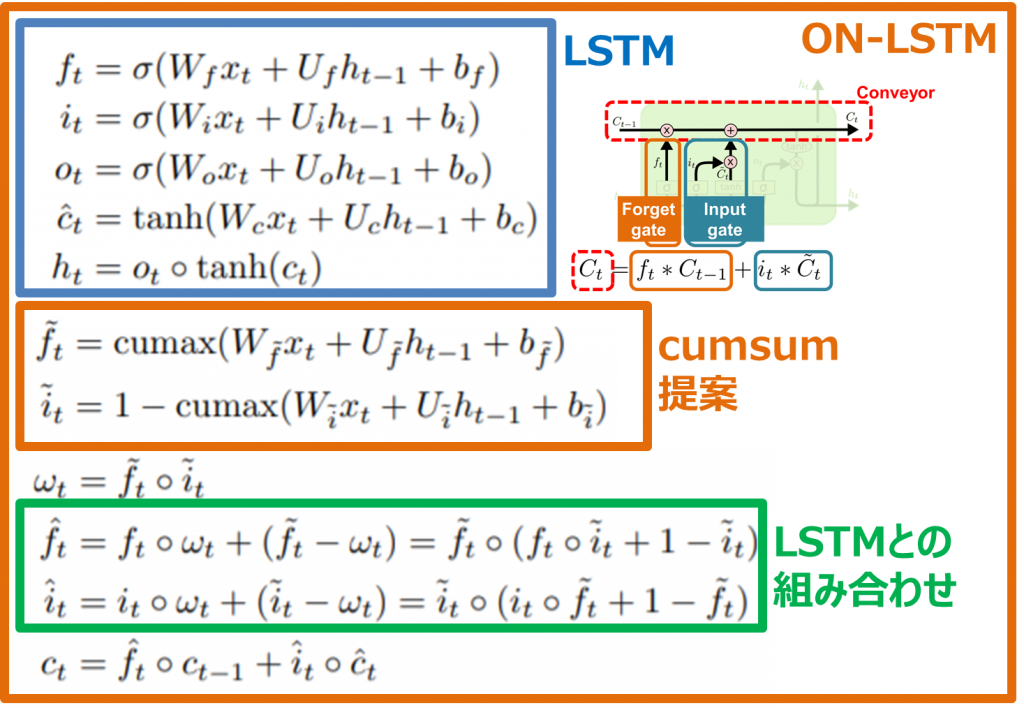
これらの提案を行うことで、ニューロンセルが結果、忘れるべきや書き込むべきの領域を検討することが可能になります。この論文では、自然言語についての技術改善を証明しましたが、今回のブログではOrdered Neuron論文の手法で自然言語の代わりに、時系列データ(FXのデータ)に適用してみることにしました。具体的な実装や結果はセクション「③ FX予測実験」で検討させて頂きます。
② GANとON-LSTM
GAN (Generative Adversarial Network; 敵対的生成ネットワーク) は2014年にIan J. Goodfellowらが発表したニューラルネットワークのフレームワークです。このフレームワークでは競合する2つのニューラルネットワークが実装されます。web検索すれば、GANの記事はたくさんありますので、ここでは簡単なシナリオを使って復習させて頂きます。まず悪い人がいます。悪い人はgenerator生成器として、偽の絵を作ります。そのとき、警察はdiscriminator識別器として、偽の絵と本物の絵を判定します。悪い人は警察が判定できないくらい、頑張って偽ものの絵を作っていきます。警察が判定できなくなるまで、悪い人が偽絵を作成する例です。機械が完璧な絵を作りたく、頑張って学習精度を上げていく感じです。
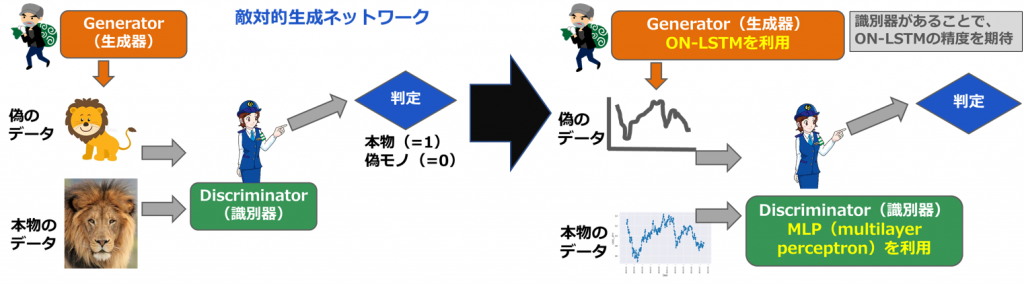
今回の実験では、ON-LSTMが作った偽のFXデータが、もっと本物のFXデータに真似られたら、いいなあと考えました。そこで、ON-LSTMが悪い人generatorの役目で、警察discriminatorが判定できないくらい、FXデータを予測できるなのかということで、ON-LSTMとGANを組み合わせてみます。そこで、ON-LSTMが悪い人の役目で本物と似たようなFXデータを予測してみたいと思います。そこで、GeneratorにON-LSTMを利用します。データは絵ではなく、FX為替レートデータに書き換えます。
lossの式を書くと、下記になります。悪い人(generator, G)と警察(discriminator, D)がゼロサムゲームの行う感じです。理想では、Gが本物のデータと偽データは同じように作成していくので、loss関数を最小化していきます。そのときに、Dが判定できなくなっていくので、loss関数が少し高くなっていきます。

実装や結果は次のセクション「③ FX予測実験」になります。
③ FX予測実験
このセクションでは「① ON-LSTM (Ordered-Neurons Long Short-Term Memory)」と「② GANとON-LSTM」で説明した手法の実装です。最新の技術ON-LSTMと試してみたいアイデアGAN+ON-LSTMの比較対象としてLSTMを利用しました。
実装環境
GMO GPUクラウドを利用させて頂きました。主な実装はpython, tensorflow, kerasです。
マシン: GMOクラウドbyGMO マシンスペック GPU : NVIDIA® Tesla® V100 SXM2-16GB 開発環境: Docker tensorflow/tensorflow:latest-gpu-py3-jupyter 言語環境: Python 3.5 主なライブラリ tensorflow-1.14.0 keras-2.2.5 keras_ordered_neurons-0.8.0 (https://github.com/CyberZHG/keras-ordered-neurons)
FXデータ
FXデータは forextester から、2018/1ー2019/8のデータをダウンロードしました。生データは一分間隔ですが、今回は一日一取引の実験をしてみたいので、一日一点データを引き出しました。また、データを分け、2018年データは学習用、2019年データは評価用とテスト用です。データ処理の詳細はgithubを参考にして下さい。
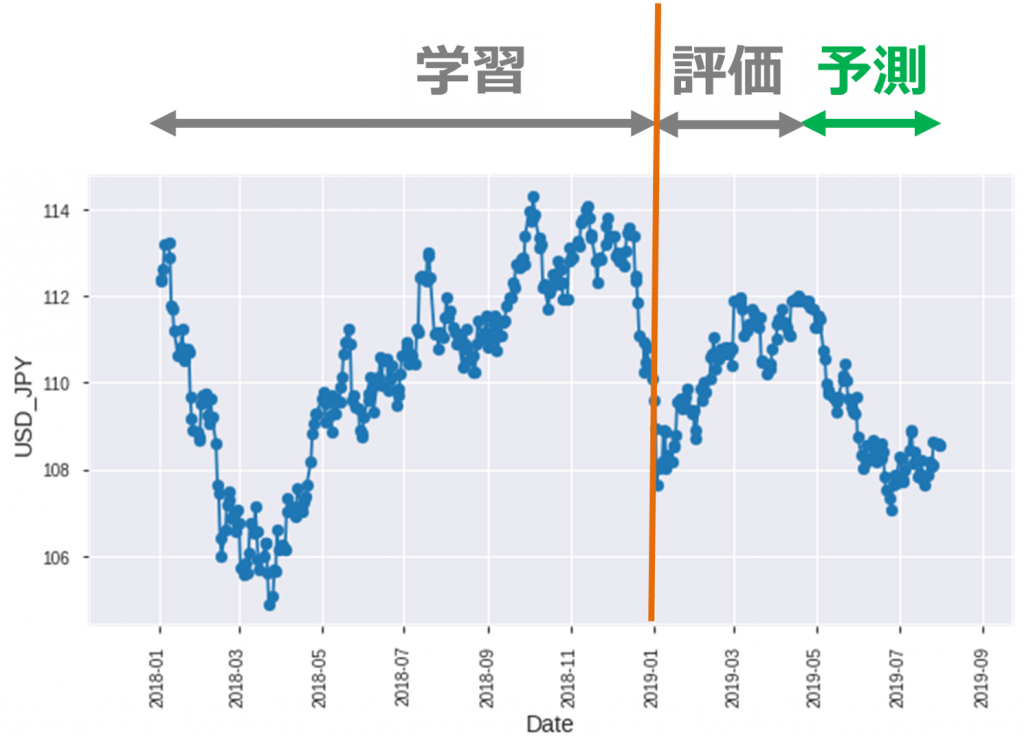
今回の売り買いルール(デイトレード)
データを使って売り買いしてみたいので、今回の売り買いルールを作りたいと思います。まず、学習データセットの中をいくつかに分けます。一つの小さいセットをLSTM batchと言います。LSTM batchは 60日データがあり、それを使って、1日データを予測するという感じです。一日の slide windowで学習し、学習モデルを作成します。それから、学習モデルを使って、レートを予測します。予測結果によって、当日に売るか買うかを決めます。買ったら、必ず翌日に売ります。
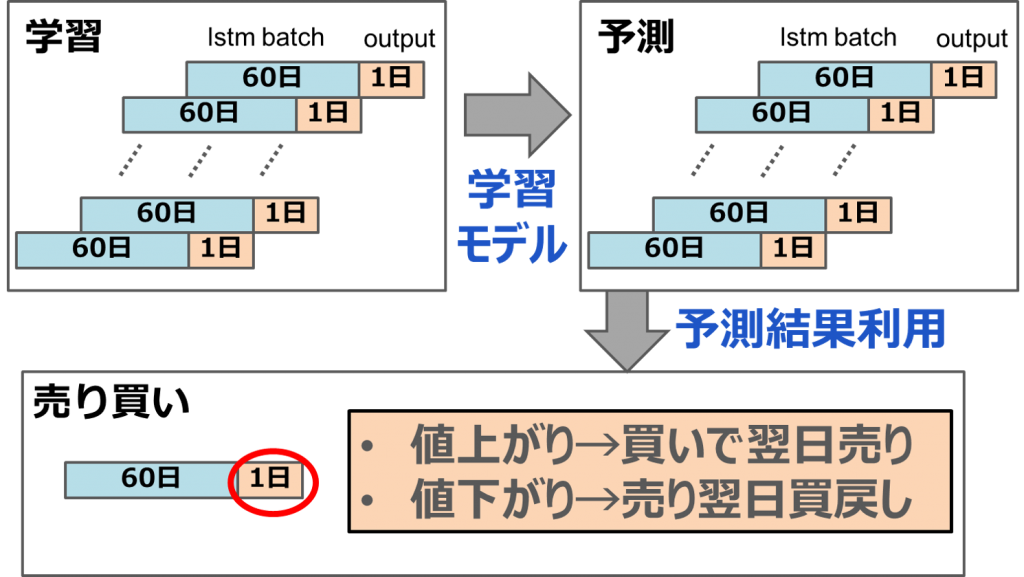
実装
実装:ON-LSTM
ON-LSTMネットワーク構造は下記のような感じになります。ポイントは chunk sizeの設定です。ゲートの情報をどれくらい引き続きたい「セクション①で説明したcumsum(累積和)の期間」というパラメータです。
from __future__ import unicode_literals
def create_on_lstm_model():
on_lstm_model = Sequential()
on_lstm_model.add(ONLSTM(units=500, chunk_size=5, return_sequences=True,
input_shape=(train_features.shape[1], train_features.shape[2])))
on_lstm_model.add(Dropout(0.01))
on_lstm_model.add(ONLSTM(units=500, chunk_size=5, return_sequences=True))
on_lstm_model.add(Dropout(0.01))
on_lstm_model.add(ONLSTM(units=500, chunk_size=5, return_sequences=True))
on_lstm_model.add(Dropout(0.01))
on_lstm_model.add(ONLSTM(units=500, chunk_size=5))
on_lstm_model.add(Dropout(0.01))
on_lstm_model.add(Dense(units = 1))
on_lstm_model.compile(optimizer = 'RMSprop',
loss = 'mean_squared_error', metrics=['accuracy'])
return on_lstm_model
実装:GAN+ON-LSTM
上記に説明したように、GANのフレームワークは2つの競争者(generatorとdiscriminator)がいます。GeneratorはON-LSTMを使い、discriminatorは下記の簡単なMLP(Multi-Layer Perceptron)構造を使います。
from __future__ import unicode_literals
def create_discriminator():
discriminator=Sequential()
discriminator.add(Dense(units=512,input_dim=1))
discriminator.add(LeakyReLU(alpha=0.1))
discriminator.add(Dense(256))
discriminator.add(LeakyReLU(alpha=0.1))
discriminator.add(Dense(128))
discriminator.add(LeakyReLU(alpha=0.1))
discriminator.add(Dense(units=1, activation='sigmoid'))
discriminator.compile(loss='binary_crossentropy', optimizer='RMSprop')
return discriminator
また、generatorとdiscriminatorを結合するキーパーソンはGANです。
from __future__ import unicode_literals
def create_gan(discriminator, generator, generator_type="lstm"):
discriminator.trainable=False
if generator_type=="mlp":
gan_input = Input(shape=(num_features,))
else:
gan_input = Input(shape=(lstm_batch_size, num_features))
print (gan_input.shape)
x = generator(gan_input)
gan_output= discriminator(x)
gan = Model(inputs=gan_input, outputs=gan_output)
opt = Adam(lr=0.0002, beta_1=0.5)
gan.compile(loss='mean_squared_error', optimizer=opt)
return gan
実装コードの詳細はgithubを参考にして下さい。
結果と考察
いよいよ、結果です。LSTMとON-LSTMとGAN+ON-LSTMを比較してみました。
学習
学習は 200 epochs(学習回数)を行いました。青いのは実データ、赤は予測データになります。ビデオを見て頂くと、学習回数を増やすと、予測データは実データに近くなっていくことが見えます。
LSTM
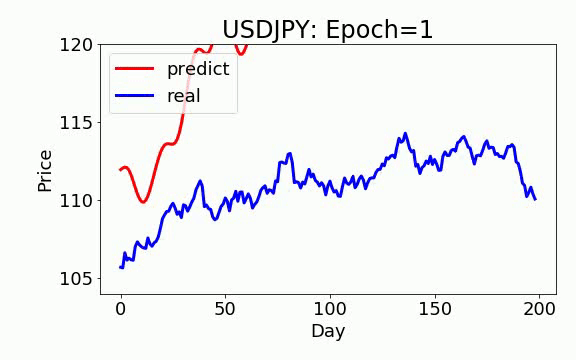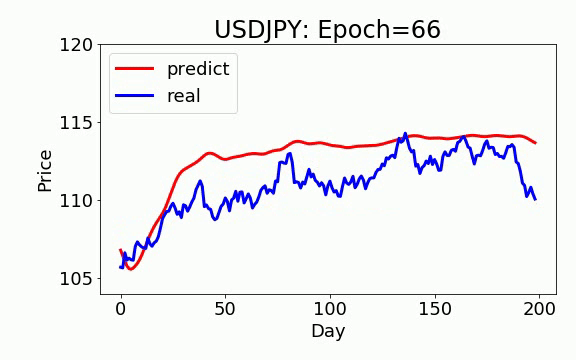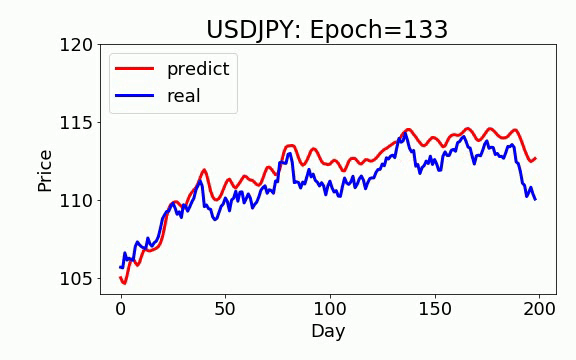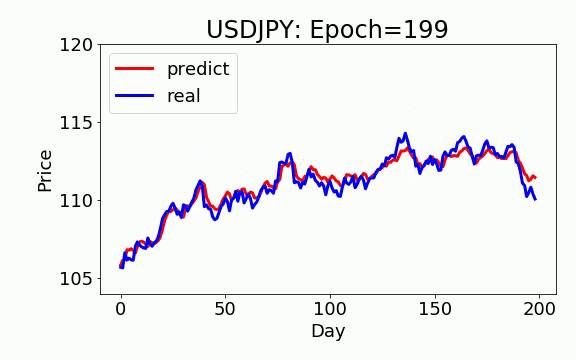
ON-LSTM
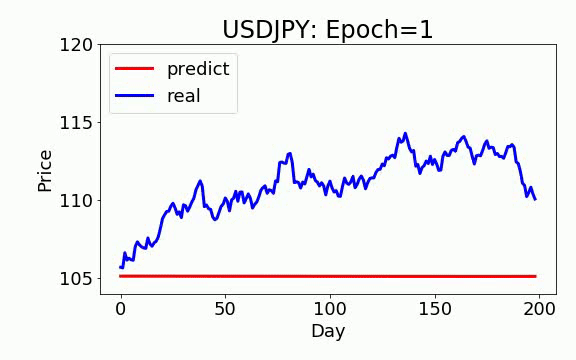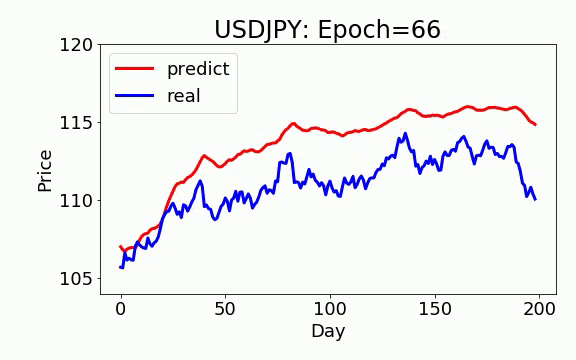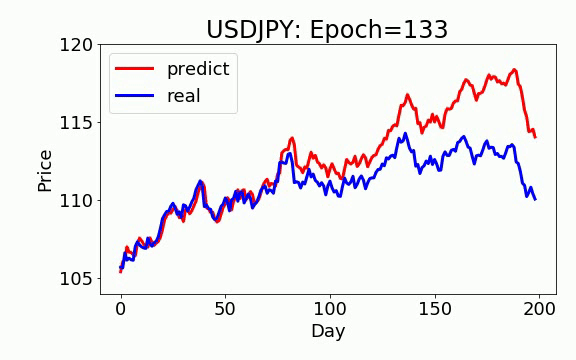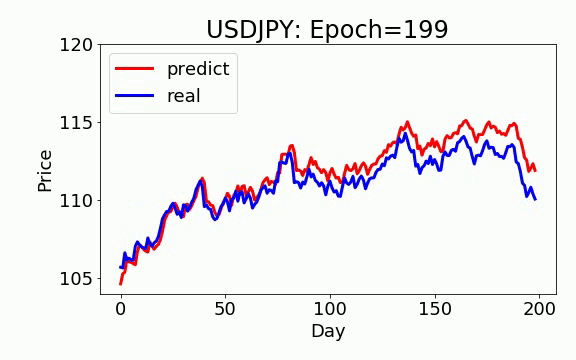
GAN+ON-LSTM
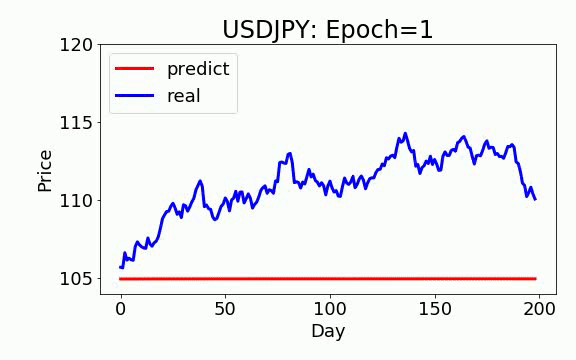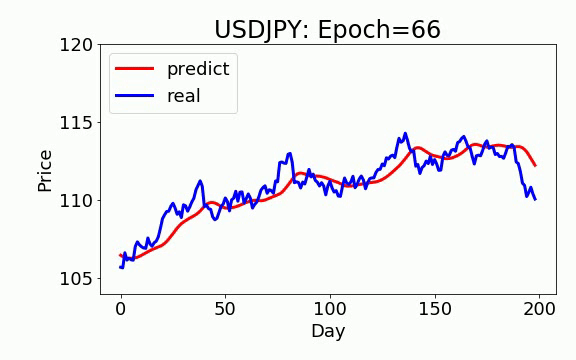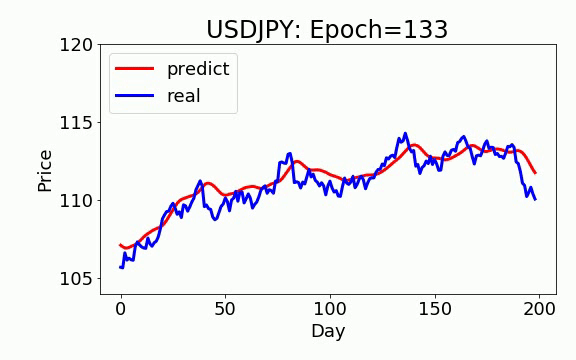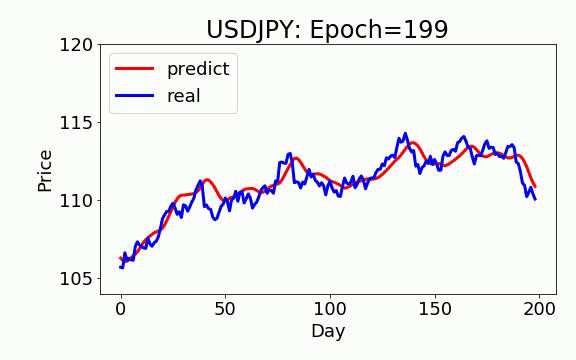
テスト
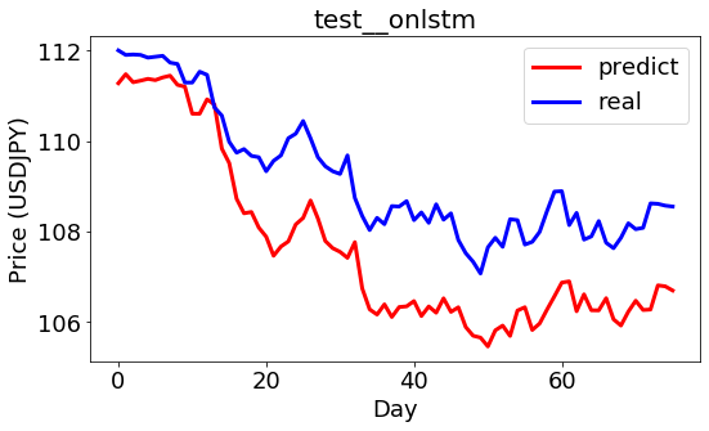
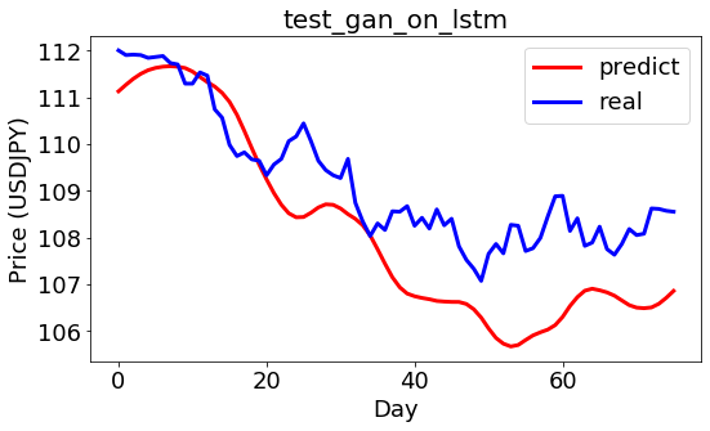
学習モデルを使って予測してみました。予測と実のデータのプライスは少し差がありますが、動きが似ていることが見えます。
LSTM
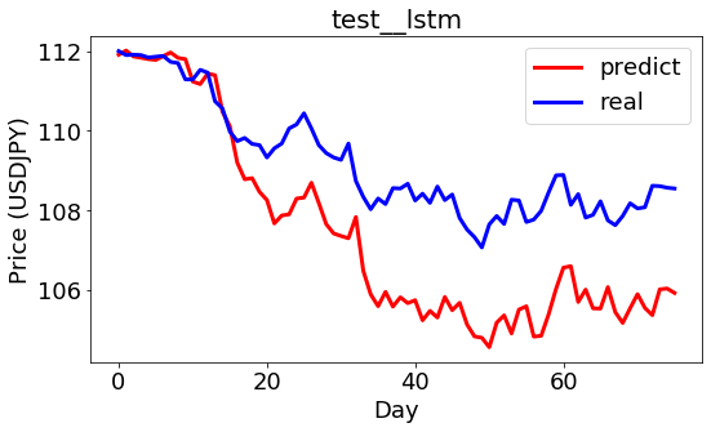
ON-LSTM
GAN+ON-LSTM
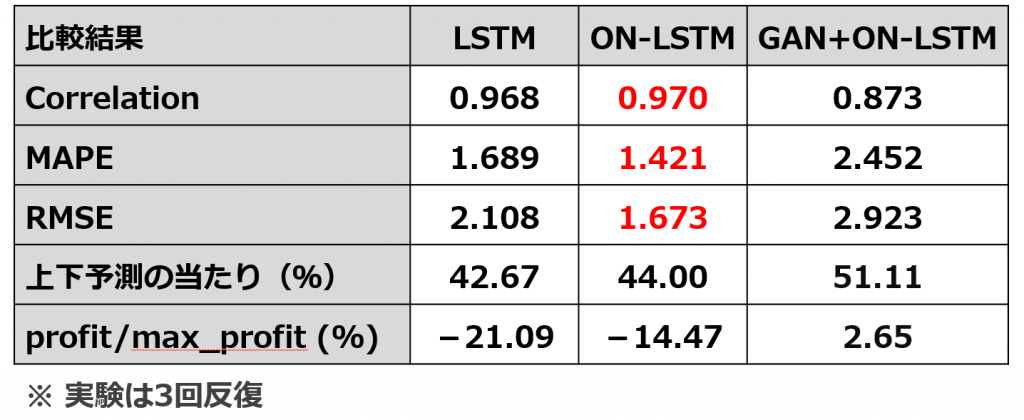
比較(performance、FX売り買い)
上記は学習とテストの結果の定性的なイメージを見せましたが、定量的な結果は下記になります。相関係数(Correlation)と二乗平均平方根誤差(RMSE)を出してみると、ON-LSTMの結果が一番よかったことが見られます。ちなみに、Correlation値が1に近くなると、相関が強いという意味で、RMSEという誤差の指標が0に近くになると、誤差が小さいという見方です。
また、売り買いのperformanceを判断するため、上下予測の当たり(%)とprofit/max_profit(%)も計算してみました。LSTMもON-LSTMも上下予測の当たりは50%以下ですし、profit/max_profitは赤字になりました。GAN+ON-LSTMは少し儲かると見えますが、Correlation値も低かったし、たまたまな結果と考えられます。儲かるまでにはどんな手法でもまだ不十分という結果でした。
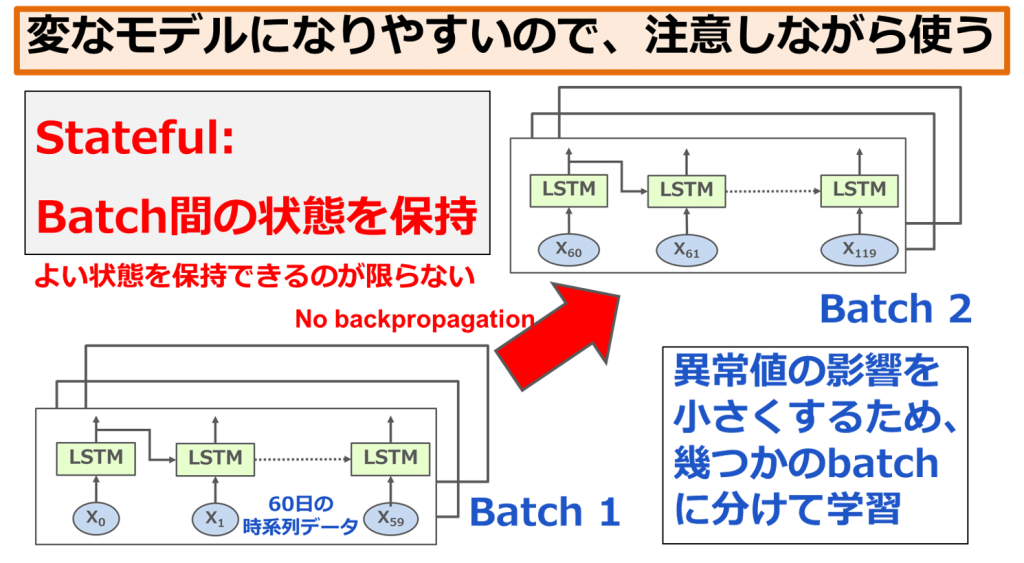
戦略変更(機能追加)
上記の結果を改善したいので、様々な実装機能を使ってみました。今回、紹介したい実装機能はstatefulです。下記の図のように、普通は学習するときに、異常値の影響を小さくするため、幾つかのbatchに分けて学習します。こうすると、batchとbatchの間の状態は保持されていないです。statefulはbatch間の状態を保持する機能ですが、いつもよい状態を保持できるとは限らないです。個人的にはstateを使うと変なモデルになりやすくなる可能性があると思います。悪い方に学習させないように、使うときには注意が必要だと思います。
興味がある方はPhilippeさんのブログとgovind.techのブログがおすすめです。
結果、少し、改善が見られ、微妙な黒字を出すことができました。他の期間にもテストしてみたら、似たような微妙黒字が安定です。しかし、どれでもまだ不十分でした。

実装ポイント
- 実装
- データ
- 量:トレンドの変化が含まれるものを選定
- 質:実際のプライスではなく、変動のフラグ値など
- チューニング
- 学習期間:定期的にSliding Windowで学習
- ハイパーパラメーター:KerasClassifier, GridSearchCVが便利
- ON-LSTM精度:chunk_sizeが結構効く
- GAN不安定:一先ずlearning rateを下げる
- 注意:データ漏れ、dropoutの情報漏れ、LSTMのshuffleとstateful
- データ
- (機械学習が詳しい方に)実は
- 今回はデイリーデータ(結構荒い)を使ったけれど、精度のため、細かいデータに使う価値はある
- ARIMAモデル(自己回帰移動平均モデル)も比較してみたが、ON-LSTMとの比較結果は少しよかった程度(たまに負けることもあり)
- WGAN(GANの改善版)も試してみたが、精度がまだ不十分だった
⑤ まとめと考察
今回、ON-LSTMとGAN+ON-LSTMを紹介し、FX予測と売り買いを実装しました。デイトレードにはまだ不十分な精度ですが、自分なりに最新の技術を学ぶことができたと思います。
- 今回、技術勉強と考え、プライス予測しようとしていましたが、やはりプライス予測より間接的な特徴の方が期待できそうです。今後、機会があれば、様々な特徴を試してみたいです。
- ON-LSTMは思ったとおりLSTMの改善です。ただ、実はいつもではなく、チューニングに依存しています。
- GAN+ON-LSTMは期待ほどではなかったです。しかし、GANの不安定問題を解決し、もう少しチューニングすれば、個人的にはまだ期待できそうです。
- 実装の再現性について、たまにCPUもGPUも不安定です。この件はまだ改善余地があるのではないかと思います。
ちなみに、発表のとき、「自分だったら、これを使って取引してみたいですか?」という質問を聞かれました。「自分だったら、まだ使わう自信がないですね」って即答してしまいました。なぜなら、たしか、テスト結果では、50%超えるところまでにできましたが、実際に取引して、最初の方でガンガン負けてしまったら、資金がなくなって、50%超えるまでの投資ができないです。倒産してしまう可能性があります。
参考:発表スライド
発表スライドとブログの被っていない内容があるため、両方とも共有させて頂きます。「近日公開予定」
最後に
次世代システム研究室の発表会は、半年ごとで行っております。興味がありましたら、今度、遊びに来て下さい。様々な分野のエンジニアやデータサイエンティストがお話をさせて頂きます。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD