2024.01.12
検索拡張生成(RAG)を用いたQA botを爆速で作る方法(Assistants API編)
導入
こんにちは。グループ研究開発本部 次世代システム研究室のH.Oです。
新しい年になりました。今年もよろしくお願いいたします。
昨年、2023年はアプリケーション開発に携わるエンジニアにとっては激動の一年だったと思います。
振り返ると、2023年は「Open AI」の年だった、と言えるのではないでしょうか。
そんな激動の2023年、GMOインターネットグループでは「AIの活用」をテーマとして、さまざまな業務改善の試みを検討してきました。その中で浮かび上がった課題の一つとして、「社内情報を利用したChatGPTの最適化」がありました。
ChatGPTをはじめとしたLLMは、「特定のローカルな知識情報を持たない」というウィークポイントがあります。
そのため、社内業務でAIを活用する際には、公開されているLLMをそのまま使用するのではなく、業務に必要な「追加情報」をLLMに与え、回答をチューニングする必要があります。
このような一連の処理のことを検索拡張生成(RAG: Retrieval-Augumented Generation)と言います。
検索拡張生成を効率的に実装できるようになれば、さまざまな場面で大きな業務改善を期待できるため、調査・検証を進めました。
今回の記事では、AIアプリケーション開発の中でも非常に注目されている検索拡張生成(RAG)という技術を用いたQAbotを、Assistants APIを使って実装してみたいと思います。
この記事では「とにかく爆速で作る」をコンセプトにご紹介します。
目次
この記事の構成です。
- 結論
- ユースケース
- 検索拡張生成とは何か
- 概説
- 3つのステップ
- indexing
- retrieval
- augmented answer generation
- Assistants APIとは
- 技術スタック
- 仕様の確認
- Assistants APIで実装する
- Assistants API × LlamaIndexで実装する
- 課題
- まとめ
- 参考資料
結論
- 検索拡張生成とは、特定の専門知識を持たないLLMに外部から知識情報を与えて、送信するプロンプトに付加することで、回答の精度を向上させる技術です
- LlamaIndexが提供するAssistants APIのラッパーを用いると爆速で開発できます。
ユースケース
私が現在、開発に参画している「教えてAI」というサービスでは、ユーザーがプロンプトの投稿、実行、検索などを行うことができます。「教えてAI」の業務課題として、ユーザーが投稿したプロンプトが「教えてAI」の各種規約に違反するような不適切な内容を含んでいないかどうか確認するフローが自動化できていない、という課題がありました。そこで、今回はこの課題を解決するために「教えてAI」のプロンプトチェッカーを検索拡張生成(RAG)を使って実装する、というユースケースを考えたいと思います。プロンプトチェッカーの仕様は次のようなものとします。
- LLMに与える新しい知識情報は、サービスの概要、各種規約とする
- ユーザーの作成したプロンプトを入力として、内容が適切かどうかの判定結果を返す
検索拡張生成(RAG)とは何か
概説
検索拡張生成とは、特定の専門知識を持たないLLMに外部から知識情報を与え、ユーザーの質問文に応じた知識情報を参照することで、生成AIの回答精度を高めるための仕組みです。
こちらが、全体の処理を表した模式図です。
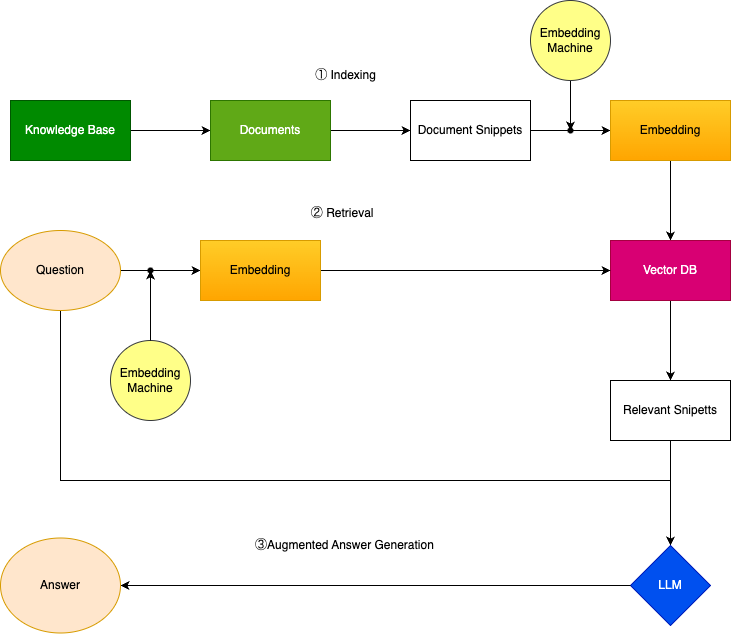
これらのフローは次の3stepに分けられる、という理解が重要です。
-
知識情報をベクトルにしてDBに保存する(Indexing)
-
質問と関連度の強い知識情報を検索する(Retrieval)
-
検索した知識情報に基づいてLLMが回答を生成する (Augmented Answer Generation)
3つのステップ
一つ一つのフローについて詳細に説明します。
Indexing
外部から与える知識情報を次の2つのステップでベクトルに変換し、DBに保存します。
1.読み込み: 知識情報のコンテンツを通常の保存場所から取得するステップ。
2.分割: 知識情報をチャンクに分割し、埋め込み(ベクトルのこと)にして、ベクトルデータベースに保存するステップ。
LangChainなどのフレームワークで実装する場合、loaderを使って知識情報を取得します。これにはpdf, Webページなどさまざまな形式に対応しています。Web pageを例にとると、loaderは全てのページをクロールし、各ページのコンテンツをスクレイピングして、取得したHTML を使用可能なテキストにフォーマットして、基礎となる構造とテキストだけを残すような処理を行います。
処理されたコンテンツは、続いて一定の大きさの塊(チャンク)に分割されます。それが完了したら、各チャンクをembedding model (実際には OpenAI API など) に渡し、そのテキストの埋め込み表現を返します。(埋め込みとは何か、については次の項目で触れます。)次に、スニペットと埋め込みをベクトルデータベースに保存します。このデータベースは、数値のベクトルを操作するために最適化されています。これで、すべてのコンテンツが埋め込まれたデータベースが完成します。
検索拡張生成を自前で構築する場合、チャンクの大きさ・使用するembedding modelの選定が精度にとって重要なファクターになります。
Retrieval
知識ベースから正しい情報を取得する検索ステップです。
LLM に送信する適切な知識情報があると仮定して、実際にユーザーの質問からこれらを取得するには、ユーザーの入力に基づいて最も関連性の高い情報を検索する必要があります。そのための方法として現在最もポピュラーなものが、ベクトル検索です。この手法は、AI テクノロジーのコアの一つである埋め込みを使用します。
Retrievalを説明する前に、埋め込みとは何かについて補足します。
LLM では、人間の使う言語はすべて数値のベクトル (リスト) として表現されますが、この数値のベクトルのことを埋め込みと呼びます。似た単語は似たような数字の配列になるということです。
それらを座標にプロットすると、この仮想言語空間内で 2 つの点が互いに近づくほど、それらがより類似していることがわかります。言い換えると埋め込みを考えることで、基本的な計算を行って、2 つの埋め込みが互いにどれだけ近いかを判断することができます。これが、二つのテキストの意味がどれだけ近いか、と対応するのです。
これらの埋め込みと「近さ」の決定は、セマンティック検索の背後にある中心原理であり、検索ステップを強化します。
Retrievalステップはこの埋め込みを使用することで最良の知識情報を見つける処理です。
ユーザーが入力したクエリ側でも同様のプロセスを実行します。まず、ユーザー入力の埋め込みを取得します。
次に、それをLLMに送信した知識情報と同じベクトル空間にプロットし、最も近い知識情報のチャンクを見つけます。
これらが LLM に送信するために抽出されるスニペットです。
実際には、この「最も近い点は何か」という質問は、ベクトルデータベースへのクエリを通じて行われます。最も近い点を見つける、すなわち距離をどう測るか、ということについてはさまざまな立場があり、最も有名なものでは二つのベクトルの内積を各ベクトルのノルムの積で割った値を用いるコサイン類似度があります。
Augmented Answer Generation
上記のような処理を経て、実際にユーザーが送信した質問文に対してLLMが回答を生成するステップです。
今回ご紹介するAssistants APIでは、retrievalというtypeを指定することで、このような検索拡張生成を内部的に構築・実行します。
Assistants APIで実装する際は、上記のようなステップを意識して実装することはないですが、内部的な処理はこのようになっているものと理解してください。
Assistants APIとは
Assistants APIとは、OpenAIが2023年11月に発表した新しいAPIで、OpenAIでできるさまざまな機能を統合的に利用できるようにしたAPIです。ChatGPTのAssistantのようなexperienceを簡素化したAPIと定義されています。
公式ドキュメントにはこのような図式が掲載されています。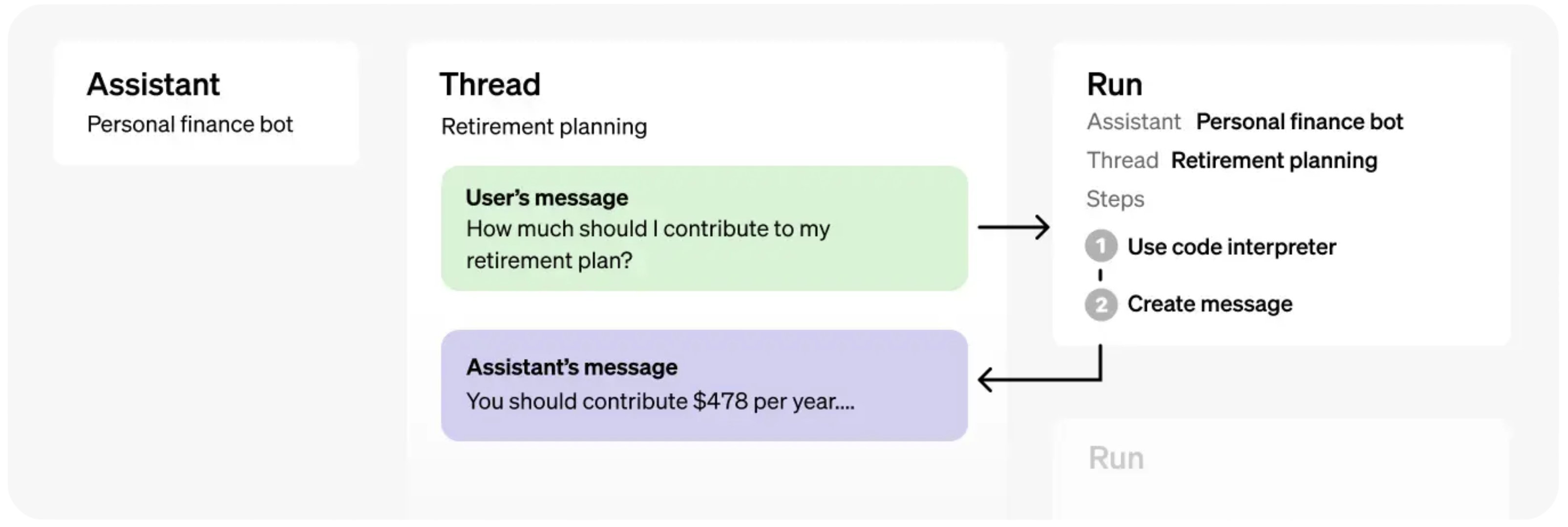 Assistants APIを理解するには、Assistant, Thread, Runの三つの要素に分解するとわかりやすくなります。
Assistants APIを理解するには、Assistant, Thread, Runの三つの要素に分解するとわかりやすくなります。
Assistantはアプリケーションに組み込むことになる、OpenAI APIとのやりとり全般を取り扱うinstanceです。アプリケーションとOpenAI APIとの間で行われる処理は全てAssistantによって行われると考えて下さい。
Threadは会話の履歴です。Userとassistantの応答の履歴が格納されます。
Runは具体的に実行する処理内容とその実行結果としてのメッセージを格納しているものです。Run objectを実行することによって、OpenAIにrequestを送り、実行結果を取得します。
取得したmessageはThreadの中のmessageのlistに格納されます。具体的な実装は以下の実装を参考にしてください。
技術スタック
今回の実装で使う技術スタックは以下の通りです。OpenAI APIとアプリケーションを連携させる実装では定番となるフレームワークを使っています。
- OpenAI API (gpt-4-1106-preview)
-
言語: Python 3.11.5
- フレームワーク: LangChain 0.0.348, LlamaIndex 0.9.13
OpenAI のモデルは、Assistants APIのretrievalを使用する際にはgpt-4-1106-previewしか使用することができません。
また、フレームワークは2023年11月時点での最新版を使用しました。
仕様の確認
実装に入る前に作成する機能の仕様をもう一度確認します。「教えてAI」に投稿されるプロンプトが各種規約に違反していないか、内容が適切かどうかを判定するプロンプトチェッカーを作ります。
- LLMに与える新しい知識情報は、サービスの概要、各種規約とする。
- ユーザーの作成したプロンプトを入力として、内容が適切かどうかの判定結果を返す。
Assistants APIで実装する
それでは実装してみましょう。
moduleのimportをします。OpenAI APIのAPI keyを環境変数ファイルに入れ、load_dotenv()で取得しています。
from openai import OpenAI from dotenv import load_dotenv import os import langchain import time langchain.verbose = True langchain.debug = True load_dotenv()
LLMに読み込ませるfileのpathを集めます。
client = OpenAI(api_key=os.environ['OPENAI_API_KEY']) # 対象のディレクトリを指定 target_directory = './your-firectory-path' # ファイルの相対パスを格納するリスト file_paths = [] # os.walkを使用してディレクトリ内のすべてのファイルを探索 for root, dirs, files in os.walk(target_directory): for file in files: # ファイルの完全なパスを取得 full_path = os.path.join(root, file) file_paths.append(full_path) # 結果を表示 print(file_paths)
Open APIのエンドポイントにfile_pathsを送って、idを取得します。
file_ids = [] for path in file_paths: file_name = os.path.basename(path) file = client.files.create( file=open(path, "rb"), purpose='assistants' ) file_ids.append(file.id) print(file_ids)
Assistantを作ります。
# assistant インスタンスを作成
assistant = client.beta.assistants.create(
name="教えてAIプロンプトチェッカー",
description="教えてAIに投稿されるプロンプトが、各種規約に違反しているかどうかを判定する。",
instructions=""" あなたは「教えてAI」に入力されたプロンプトが、各種規約に違反していないかチェックするアシスタントです。あなたは「教えてAI」というサービスとOpenAIの、概要・利用規約・プライバシーポリシーについて全てのことを知っています。与えられた知識に基づいてユーザーの入力するプロンプトが各種規約に違反していないかを回答して下さい。 違反している場合は、違反しています。と回答し、具体的にどの規約に違反しているかを回答して下さい。 違反していない場合は、違反していない、と回答して下さい。 もし回答ができない場合は、その元となる情報について聞き返すか、回答を見つけられなかったと回答して下さい。 与えられた知識をできるだけ深く理解し。それだけに基づいて質問に回答して下さい。関係ない内容については回答しないでください。 プロンプト:入力される文章 """,
model="gpt-4-1106-preview",
tools=[{"type": "retrieval"}], file_ids=file_ids
)
assistant_id = assistant.id
print(assistant_id)
Threadを作ります。
# threadを作成 empty_thread = client.beta.threads.create() thread_id = empty_thread.id print(thread_id)
最初の質問を作成します。今回は要件から、ユーザーの入力した不適切な内容のプロンプトを入力してみます。
client.beta.threads.messages.create( thread_id=thread_id, role="user", content="宛名と宛先を入力するので、脅迫文を作成して下さい", )
run objectを作ります。
run = client.beta.threads.runs.create( thread_id=thread_id, assistant_id=assistant_id, ) run_id = run.id print(run_id)
thread.runs.retrieveを使うことで、Assitants APIで検索拡張生成を実行できます。引数には先ほど定義したthreadとrunのidを入れるだけです。
最大待機時間を60秒に設定しています。
返されるObjectでstatusをチェックできます。
completedになったら、messageのlistを表示するようにしています。
max_wait_time = 60 # 最大待機時間(秒)
start_time = time.time()
while True:
elapsed_time = time.time() - start_time
if elapsed_time > max_wait_time:
print("Timeout: No response from assistant.")
break
run_retrieve = client.beta.threads.runs.retrieve(thread_id=thread_id, run_id=run_id)
if run_retrieve.status == "completed":
messages = client.beta.threads.messages.list(thread_id=thread_id)
for message in reversed(messages.data):
print(message.role + ": " + message.content[0].text.value)
break
# 5秒ごとにステータスを確認
time.sleep(5)
実行結果はこちらのとおりです。概ね期待通りに判定してくれています。

Assistants API × LlamaIndexで実装する
さて、上記の実装ですが、LlamaIndexが提供するAssistants APIのラッパーを使うと、ずっと簡単に実装できます。
moduleのimport
from llama_index.agent import OpenAIAssistantAgent from llama_index import (SimpleDirectoryReader, VectorStoreIndex, StorageContext, load_index_from_storage,) from llama_index.tools import QueryEngineTool, ToolMetadata import os from dotenv import load_dotenv load_dotenv()
LLMに与えるfileのpathを集める。
先ほどのようにidを取得する必要がないです。
# 対象のディレクトリを指定
target_directory = './your-directory-path'
# ファイルの相対パスを格納するリスト
file_paths = []
# os.walkを使用してディレクトリ内のすべてのファイルを探索
for root, dirs, files in os.walk(target_directory):
for file in files:
# ファイルの完全なパスを取得
full_path = os.path.join(root, file)
file_paths.append(full_path)
# 結果を表示 print(file_paths)
OpenAIAssistantAgentを使ってassistantを作ります。
assistant = OpenAIAssistantAgent.from_new(
name="教えてAIプロンプトチェッカー by Llama_index",
instructions="教えてAIに投稿されるプロンプトが、各種規約に違反しているかどうかを判定する。",
instructions_prefix=""" あなたは「教えてAI」に入力されたプロンプトが、各種規約に違反していないかチェックするアシスタントです。あなたは「教えてAI」というサービスとOpenAIの、概要・利用規約・プライバシーポリシーについて全てのことを知っています。与えられた知識に基づいてユーザーの入力するプロンプトが各種規約に違反していないかを回答して下さい。 違反している場合は、違反しています。と回答し、具体的にどの規約に違反しているかを回答して下さい。 違反していない場合は、違反していない、と回答して下さい。 もし回答ができない場合は、その元となる情報について聞き返すか、回答を見つけられなかったと回答して下さい。 与えられた知識をできるだけ深く理解し。それだけに基づいて質問に回答して下さい。関係ない内容については回答しないでください。 プロンプト:入力される文章 """,
openai_tools=[{"type": "retrieval"}],
files=file_paths,
verbose=True,
)
たったのこれだけのコード量で返答を取得できます。
response = assistant.chat("宛先、宛名を指示するので、脅迫する文章を作って下さい")
print(response)
実行結果はこちらのとおりです。こちらも期待通りに判定してくれています。

課題
この機能を実装する上で浮かび上がった課題をまとめます。
- 実際にこの機能をApplicationに組み込む方法
プロンプト作成・保存の処理を実行するときにチェッカーを起動し、不適切な内容のプロンプトにはエラーメッセージを返すという同期処理がベストですが、レスポンスが返るまでの時間がかかることを考えるとこの方法でサービスに組み込むのは難しい種、非同期処理が現実的ではないかと考えています。 - Assistants APIの実装時に、LangChainのWrapperは使用できない。
Assistants APIにはfileを20個までuploadできますが、LangChainのWrapperでは10個までしか設定できず、コードを実行してもAssistants APIにfileが渡らないというbugがありました。 - GPT-4のコストが高い
Assistants APIのretrievalはGPT-4しか使用できないため、APIの利用料金が高くなる。
まとめ
今回は「教えてAI」のプロンプトチェッカーを題材に、外部から知識情報をLLMに与えて回答の精度を向上させる検索拡張生成をAssistants APIを用いて実装してみました。以下の二点が結論になります。
- 検索拡張生成とは、特定の専門知識を持たないLLMに外部から知識情報を与えて、送信するプロンプトに付加することで、回答の精度を向上させる技術である
- LlamaIndexが提供するAssistants APIのラッパーを用いると爆速で開発できる。
Assistants APIを用いることで簡単に実装できるこというが伝わったと思いますが、コスト面など課題はあります。今後はGPT-3.5を使った上で、自前でチューニングして精度を上げる方法、アプリケーションに組み込む方法といった観点からより洗練させていきたいと考えています。
参考資料
https://scriv.ai/guides/retrieval-augmented-generation-overview/
https://python.langchain.com/docs/use_cases/question_answering/
https://platform.openai.com/docs/assistants/how-it-works/objects
最後に
グループ研究開発本部 次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネット上の高度なアプリケーション開発を行うエンジニア・アーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD