2021.01.12
TFXを用いてend to end の機械学習ワークフロー
こんにちは、次世代システム研究室のA.Zです。
現在、関わっている機械学習プロジェクトは開発開始から4年ぐらいに経ちました。当時サービスを立ち上がったときに、機械学習のツールやフレームワークが今のような充実していませんでした。最初に機械学習サービスを立ち上げたときに、ほとんどSparkとBigqueryをメインで、機械学習ワークフローを作成されました。サービスが規模が大きくなり、かつ様々な機能が追加されたため、全体的なシステムが複雑になり、運用やトラブルシューティングが大変になってきました。
この数年間で、機械学習は研究だけではなく、たくさんの企業が実際のサービスに応用しています。その結果、実サービスに大規模な機械学習システムの運用のベストプラクティスやライブラリも増えています。
特に大手企業のGoogleが自分のサービスでも利用されているend-to-end機械学習ライブラリー(Tensorflow Extended)がオーペンソース化されました。今回はtensorflowベースのend-to-end機械学習ライブラリ、Tensorflow Extended(TFX)について、紹介したいと思います。
はじめに
TFXの話する前に、まず先にプロジェクトの状況とTFXに何を期待しているか簡単に話したいと思います。
当プロジェクトは約2017年に開発始まりました。当時は大規模のデータの機械学習システムを作りたいなら、Sparkが一番使いやすかったと思います。Data自体はgoogle cloud platformのbigqueryに格納されます。
あまりにもbigqueryの性能ががよく、大量なデータが一瞬で処理できるため、データ処理の部分はSQLで書いてしまうことが多いです。
モデルのトレーニング自体は最初にSparkで行いましたが、Deep Learning系のモデルに変更のため、昨年にモデルの部分はtensorflowに移行しました。現在、当プロジェクトはSQL、spark、tensorflow,shell script様々な言語やフレームワークで構成されています。その結果、システム全体が結構複雑になり、なにか問題が発生したら、トラブルシューティングの工数かかるかつ原因特定が困難になってきました。
現在特に気になっている課題や問題
- データ処理や加工はBigquery SQLで行っていることが多く、なにか改修するときに、コードで単体テストできないため、テストの工数が増えます。
- データの処理流れはソースコードしか確認できないため、処理の依存関係の把握は困難。特に新しいメンバーにとって、把握するために時間がかかります。
- モデルトレーニングに利用されているデータの情報に関しては手動でしか確認でき、確認工数がかかります。
- 全体的なモデルトレーニングの効率が悪い。現在、各処理はほとんど直列で実行されていおり、並列化できる部分がまだありますが、Job管理や実行は現在shell scriptで行うため、並列化の仕組みの取り入れるのは工数がかかりま
Tensorflow extendedとは
Tensorflow Extended(TFX)とはGoogleが開発したTensorflowベースend-to-endの機械学習フレームワークです。TFXは大規模な機械学習システムの構築から、本番運用するまで、必要となる機能は一通り揃っています。基本的に、tensorflowを使えば、on-premiseでもクラウドでも、利用できます。特にgoogle cloud platformのサービスを利用すれば、もっと相性が抜群です。
一般的に、機械学習のシステムは以下のようにいイメージになっています。
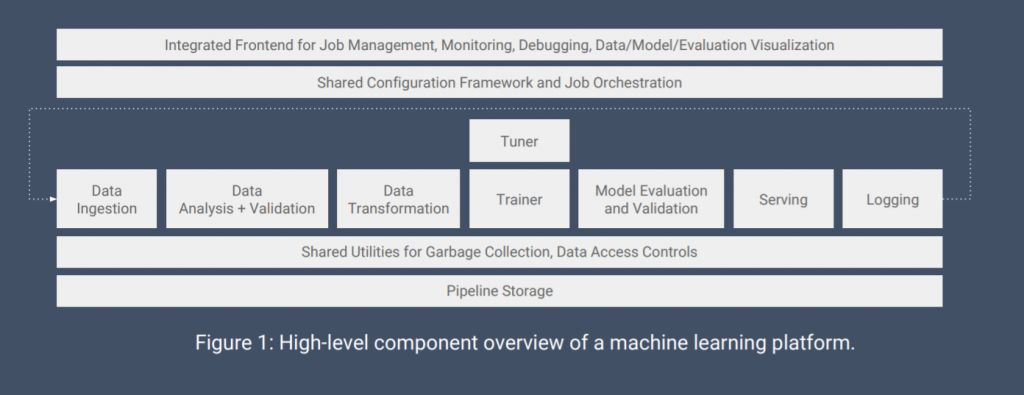
実際にopen-source化されているのは以下の緑の部分ですが、個人的に、ほぼ全プロセスがカバーされていると思います。
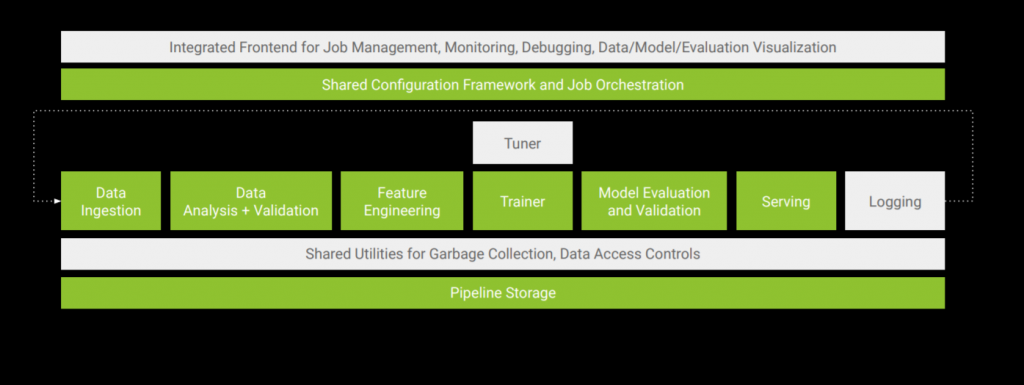
次はTFXの詳細のコンセプトや詳細の機能について、簡単に紹介したいと思います。
TFXのコンセプトと利用している技術について
ML Metadata
プローグラム書くときに、バージョン管理ツール(git,svnなど)が欠かせないになっているように、機械学習のワークフローも全ステップや全実行や実験の履歴の管理が不可欠です。
TFXはML metadataというのは機械学習システムにあるすべての工程の実行情報や依存関係やをトラッキングしたライブラリです。機械学習のシステムに何か問題(データの問題やモデルの問題)が発生したら、こちらのmetadataを利用し、問題の原因特定には役に立ちます。
ML Metadataが保存した情報の格納先はMetadata Storeと読んでいます。ML Metadataが保存して情報は基本的に以下の情報です。
- 各機械学習ワークフローステップや工程でのインプットやアウトプットのmetadata
- 各機械学習ワークフローステップや工程の実行情報
- 各機械学習ワークフローステップや工程の依存関係やパイプライン情報
ML metadataの詳細やアーキテクチャについて、以下のリンクで参考できます。
https://github.com/google/ml-metadata/blob/master/g3doc/get_started.md
大規模データ処理のフレームワーク
大規模のデータ処理がために、TFX はApache Beamという大規模データ処理フレームワークを使っています。
Apache Beamとは大規模なデータ処理を統合化されたプログラミングモデルです。一般的な大規模のデータ処理、バッチ処理やストリーミング処理には同じ定義やインターフェースで対応できます。
Apache Beamはただのプログラミングモデルなので、同じコードや定義が様々なRunner(バックエンド)で実行することができます。例えば、バッチ処理に使いたいときに、Sparkバックエンドを使ったり、ストリーミング処理に使いたいときにFlinkを使ったり、ロジック検証に使いたいときに、ローカルランナーを使ったり、かなり柔軟性が高いフレームワームだと思います。更に、Apache Beamはスケールしやすいのため、機械学習システムのワークフローには適切です
TFX Component
TFXのコンポネントとはTFXのパイプラインやワークーフローの最小の単位です。以下はTFXのコンポネントの構成です
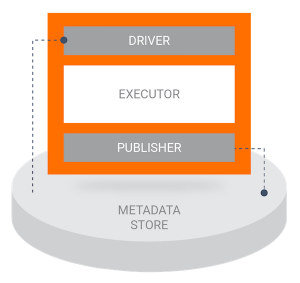
- driver: metadata storeから、データを抽出し、executorに必要なデータや情報をexecutorに渡すため
- executor: componentのメインの処理
- publisher: executorの実行結果や実行情報をmetadata storeに保存するための
コンポネントのexecutorは基本的に
- Apache Beamのプログラム
- tensorflowプログラム
- simple python program
- container(kubeflow)
TFXでは、一番良く使われているコンポネントはデフォールトで用意されています。
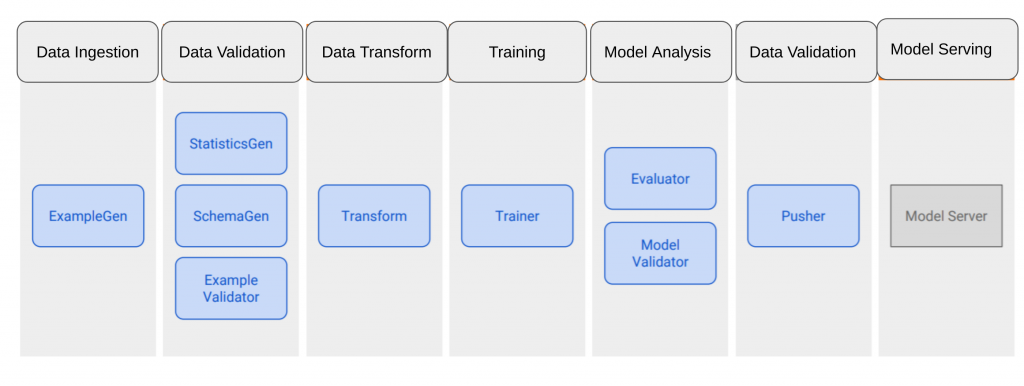
- ExampleGen
一番最初のコンポネントで、パイプラインやワークフローにデータを取り込むためのコンポネント - StatisticsGen
インプットデータの統計情報を計算するためのコンポネント - SchemaGen
統計情報からデータのスキーマやプロパティ(データのレンジ、カテゴリタイプ種類など)作成 - ExampleValidator
インプットデータの異常検知を行うためのコンポネント - Transform
データ前処理のコンポネント - Trainer
モデル学習処理 - Evaluator and Model Validator
モデルの評価を行うためにコンポネント。定義した基準や指標で、学習したモデルの精度のチェックを行い、モデル精度が問題ないかどうか判断 - Pusher
サービング環境にモデルをデプロイ
Orchestrationフレームワーク
TFXで、定義したワークフローやパイプラインをもっと運用や管理や監視を効率化するために、TFXがApache AirflowやKubeflowなど、様々なorchestrationのフレームワークをサポートしています。
TFXでの機械学習パイプラインの例
TFXで一番シンプルなパイプラインはどう作るか簡単に紹介します。
今回作りたいパイプラインのイメージは以下です。
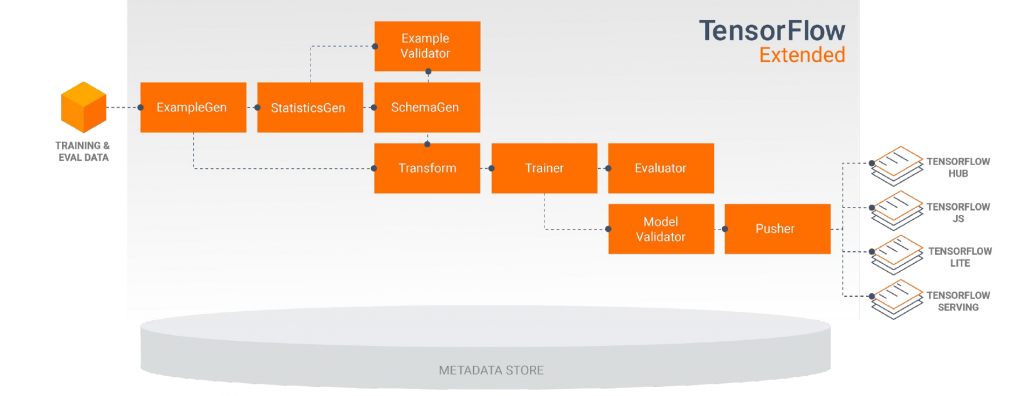
実際にpythonでコード書くのは以下のイメージになります。
def _create_pipeline(pipeline_name: Text, pipeline_root: Text, data_root: Text,
module_file: Text, serving_model_dir: Text,
metadata_path: Text,
beam_pipeline_args: List[Text]) -> pipeline.Pipeline:
# データソースから、パイプラインにデータを取得する
examples = external_input(data_root)
# Brings data into the pipeline or otherwise joins/converts training data.
example_gen = CsvExampleGen(input=examples)
# 統計情報の計算
statistics_gen = StatisticsGen(examples=example_gen.outputs['examples'])
# 統計情報から、 データのスキーマ情報を作成する
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
infer_feature_shape=False)
# データの異常検知を行う
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'])
# データの前処理
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=module_file)
# モデル学習
trainer = Trainer(
module_file=module_file,
transformed_examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=trainer_pb2.TrainArgs(num_steps=10000),
eval_args=trainer_pb2.EvalArgs(num_steps=5000))
# 評価するときに、使っているベースラインモデルを取得する
model_resolver = ResolverNode(
instance_name='latest_blessed_model_resolver',
resolver_class=latest_blessed_model_resolver.LatestBlessedModelResolver,
model=Channel(type=Model),
model_blessing=Channel(type=ModelBlessing))
# モデル評価するときに基準や指標の定義
eval_config = tfma.EvalConfig(
model_specs=[tfma.ModelSpec(signature_name='eval')],
slicing_specs=[
tfma.SlicingSpec(),
tfma.SlicingSpec(feature_keys=['trip_start_hour'])
],
metrics_specs=[
tfma.MetricsSpec(
thresholds={
'accuracy':
tfma.config.MetricThreshold(
value_threshold=tfma.GenericValueThreshold(
lower_bound={'value': 0.6}),
change_threshold=tfma.GenericChangeThreshold(
direction=tfma.MetricDirection.HIGHER_IS_BETTER,
absolute={'value': -1e-10}))
})
])
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
baseline_model=model_resolver.outputs['model'],
# Change threshold will be ignored if there is no baseline (first run).
eval_config=eval_config)
# モデル評価で、問題なかったら、servingのシステムにpush
pusher = Pusher(
model=trainer.outputs['model'],
model_blessing=evaluator.outputs['blessing'],
push_destination=pusher_pb2.PushDestination(
filesystem=pusher_pb2.PushDestination.Filesystem(
base_directory=serving_model_dir)))
return pipeline.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
components=[
example_gen, statistics_gen, schema_gen, example_validator, transform,
trainer, model_resolver, evaluator, pusher
],
enable_cache=True,
metadata_connection_config=metadata.sqlite_metadata_connection_config(
metadata_path),
beam_pipeline_args=beam_pipeline_args)
今回は使っているパイプラインのとソースコードはほぼTFXのサイトにあるサンプルと同じですが、基本的に、こちらのパイプラインは結構使われているため、いろんな場面でも利用できると思います。
また、コードをみると、かなりシンプルでわかり安いと思いますが、実際にカスタムコンポネントを使うときに、コードが複雑になる可能性があります。
まとめ
今回、end-to-end 機械学習フレームワーク、Tensorflow Extendedについて、簡単に紹介いたしました。個人的にTensorflow使うなら、このフレームワークを使ったほうが便利だと思います。実験の段階で、これを使うと、ほぼ改修なしで、本番にそのまま適用できると思います。また、Apache Beamと連携できるため、もしロジックがSQLでよく使うなら、Beamに移行できるところはBeamに移行し、テストの効率がもっと上がると思います。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD