2025.01.14
使ってみたら意外と便利なEMR Studio notebook ~notebookでデータを加工しAthenaで見る~
はじめに
こんにちは。グループ研究開発本部、AI研究開発室のY.Tです。
今日はEMR Studioでnotebook環境を使ってみたら、なかなか使いやすかった話をしようと思います。
notebookはとにかく便利でつい使ってしまうもの。jupyter notebook上でpandasなどでデータを加工していた人は、かなり扱いやすいのではないでしょうか?
今回はサンプルとして、movielensのcsvデータを、athenaのテーブルにして簡単な集計をかけられるようにするまでの流れをnotebook環境でやっていきたいと思います。
環境の作成
まずはStudioを作成しましょう。
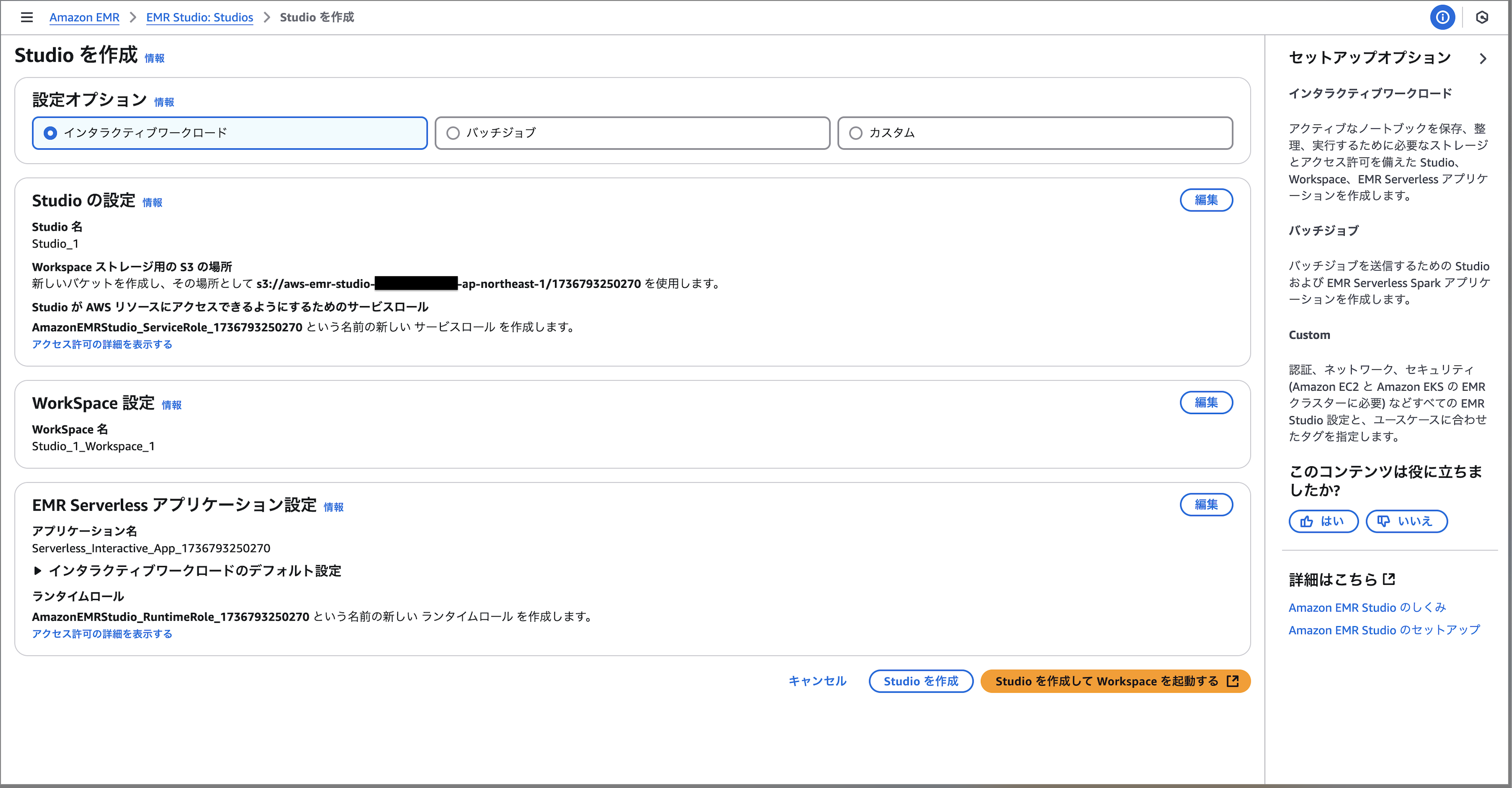
自分で色々作っても良いですが、インタラクティブワークロードのデフォルト設定のままでOKです。作成を選択後に立ち上がるまで少し時間がかかります。
URLからStudioにアクセスし、Workspaceを開きましょう。Workspaceのリンクから開けます。
見慣れたいつものUIです。とても簡単!
豊富なExampleが並びます。今回は触れませんが、とりあえず試すのにはこれを動かすのが良さそう。
notebook環境の起動
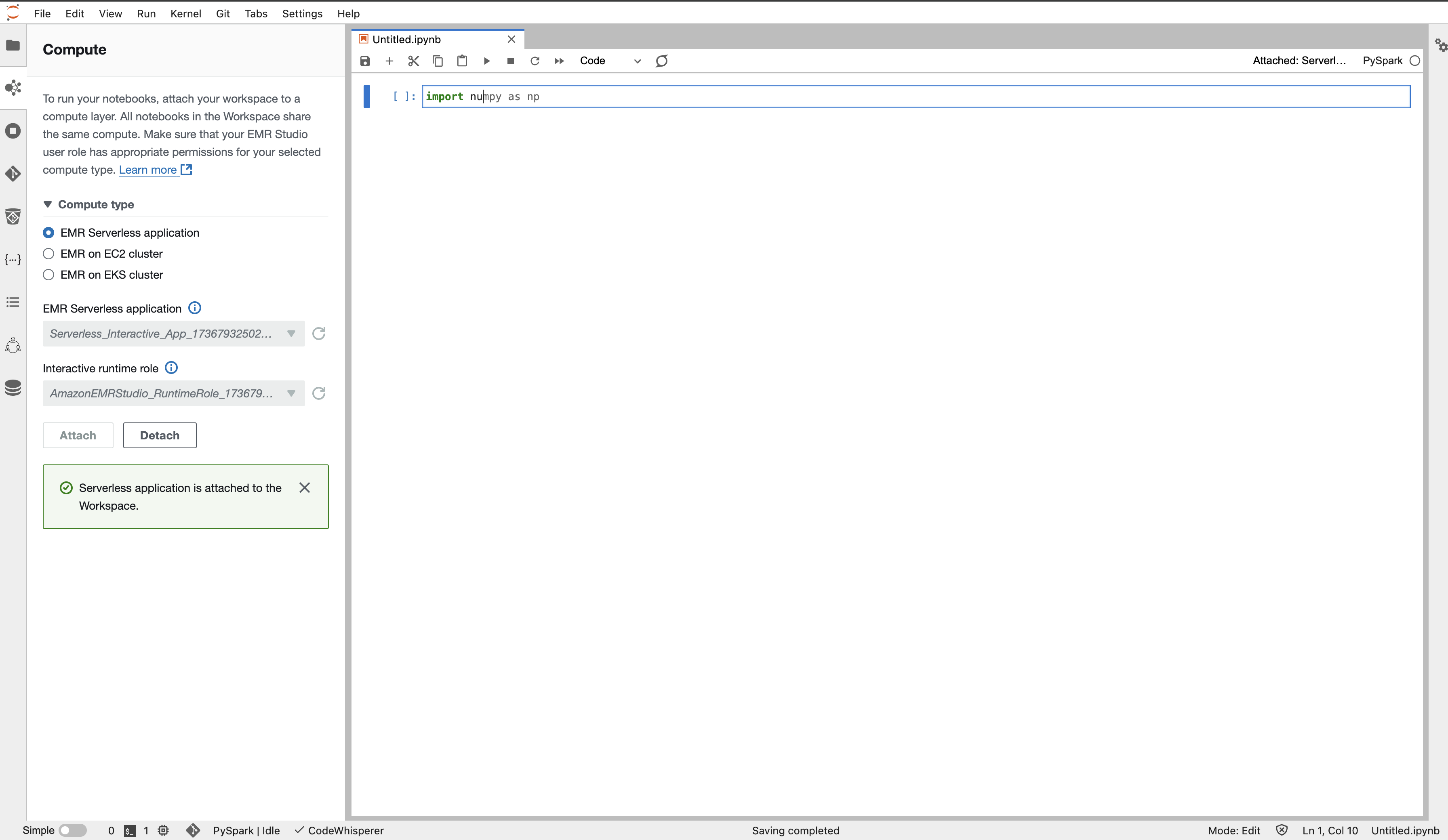
LancherからPySparkのnotebookを選択して、notebookを作成します。
賢いSuggestが出てきましたね。
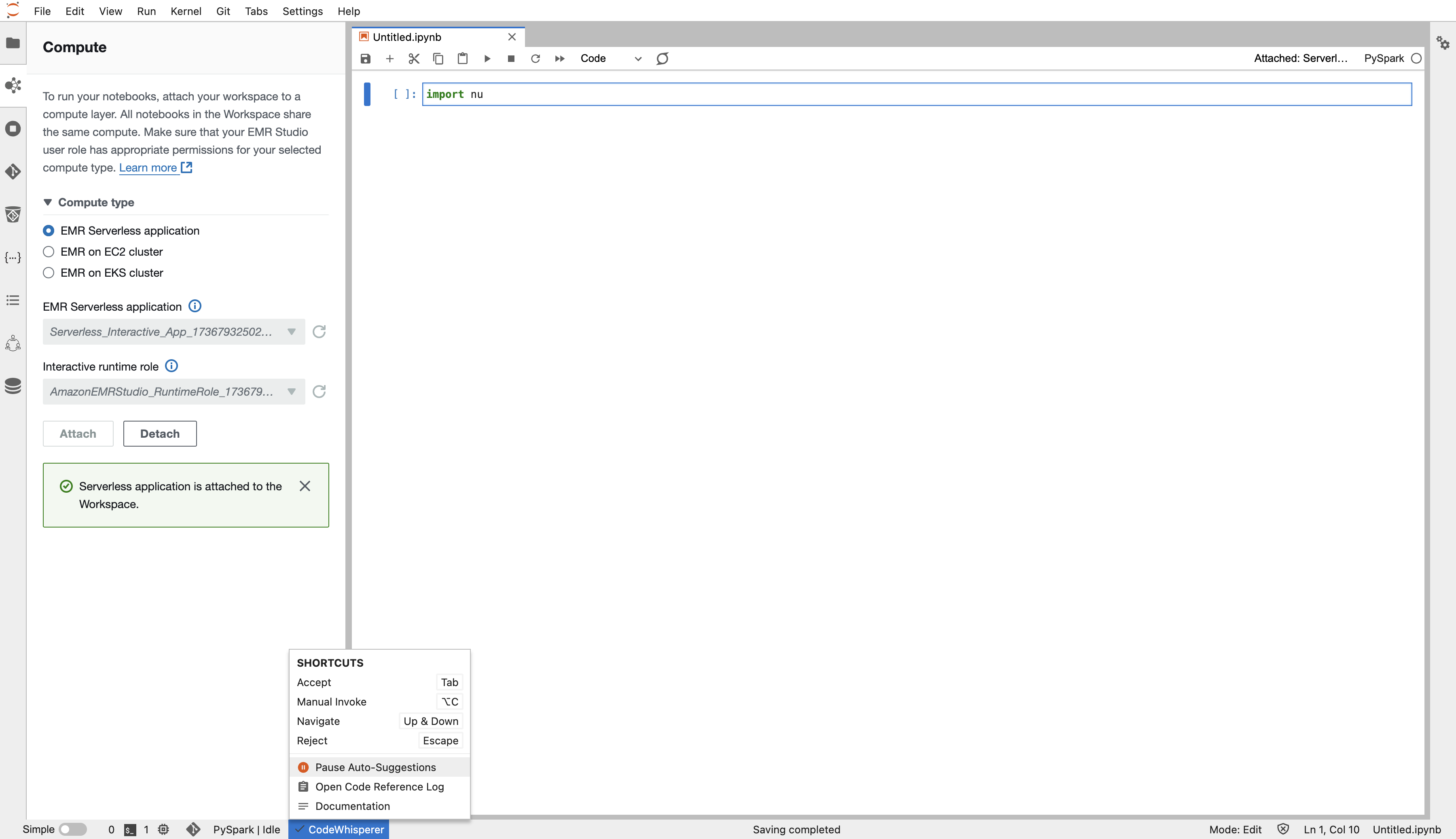
CodeWisperが最初から入っています!不要であればoffにしましょう。
Applicationの設定
立ち上がったApplicationはEMR StudioのApplicationから確認可能です。
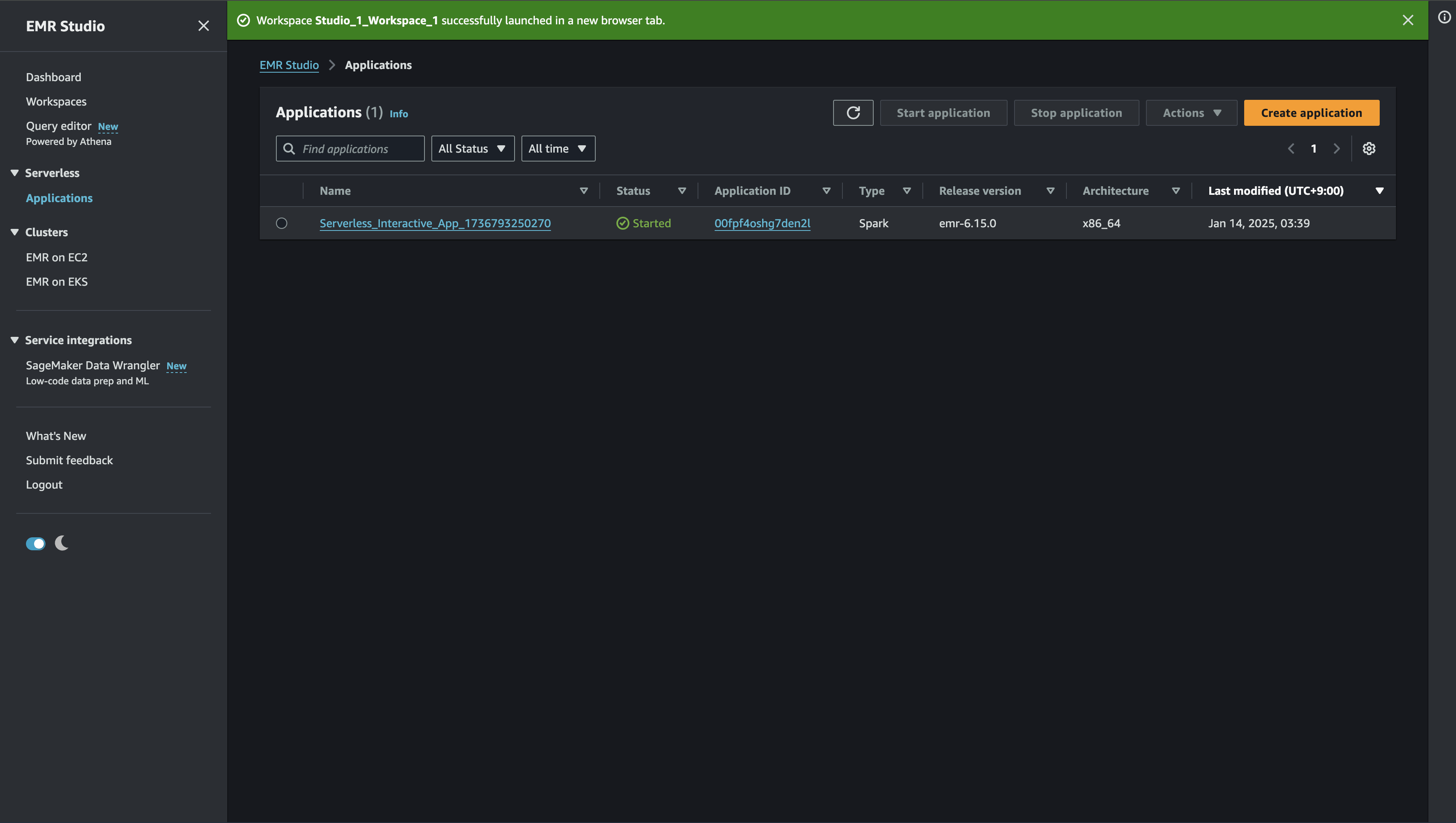
Applicationの設定から、クラスタのサイズやキャパシティ、その他の設定を変えることが可能です。今の設定を確認するため、Acction -> Editと進み画面を開きます。
あら、デフォルトだと、バージョンが6.15でx86で動いていますね。バージョンを最新に、アーキテクチャをARMに変えてみましょう。
特にアーキテクチャは大事です。なぜってARMの方が安いから!!
サンプル程度のコードにバージョン依存もアーキテクチャ依存もないですからね。
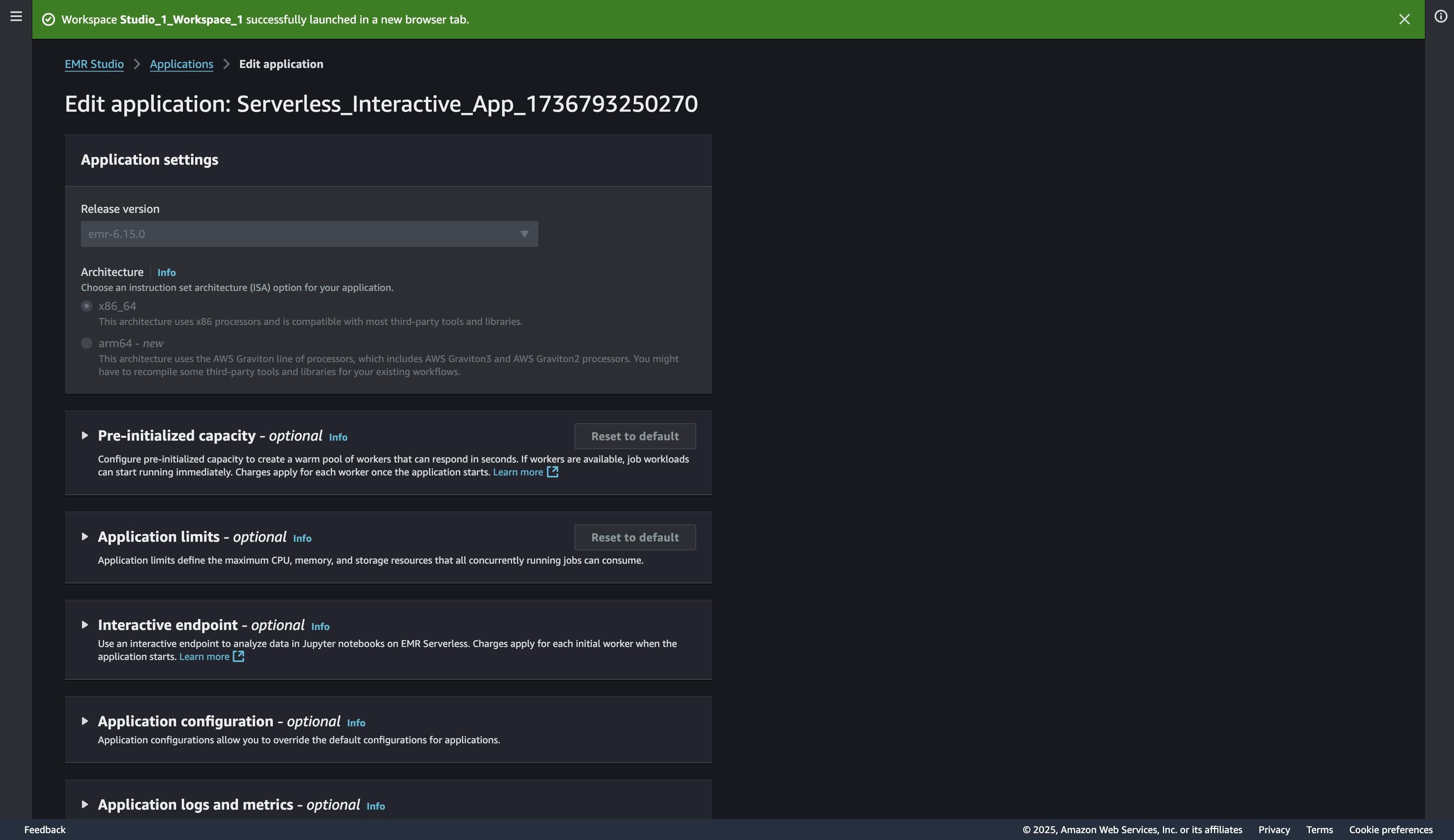
まだApplicationが動いており変えたい設定がグレーアウトして変更できないので、まずはApplicationを止めます。(少し時間がかかります。)
Applicationを止めなくても設定を変えられる項目はありますが、反映タイミングに困惑するので、とりあえず止めてから変えた方がわかりやすくていいです。
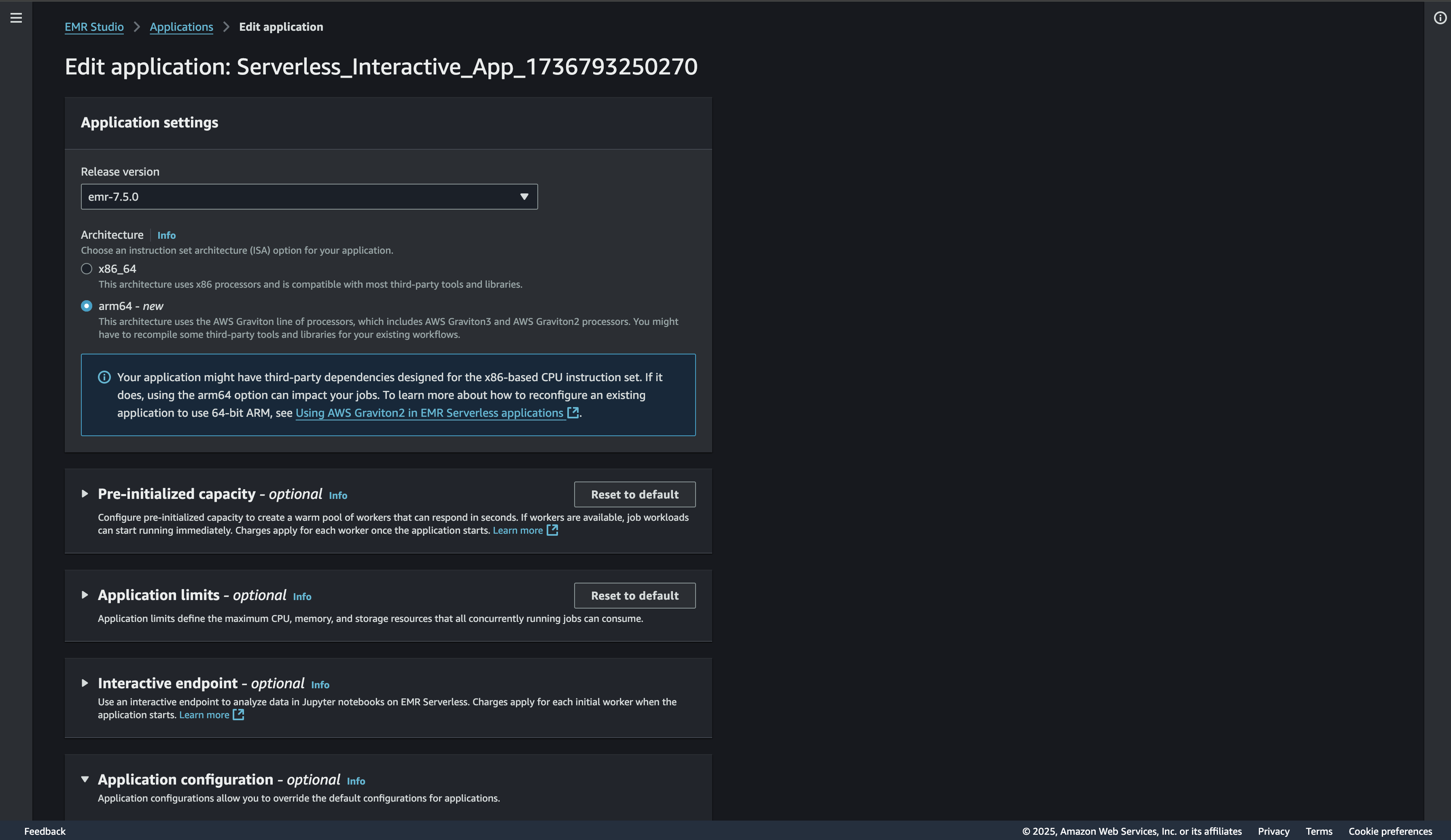
設定を変更してsaveし終わったら、改めてAttachします。
configはnotebook側で入れることもできます。例えば、driverとexecutorのサイズはこのように。
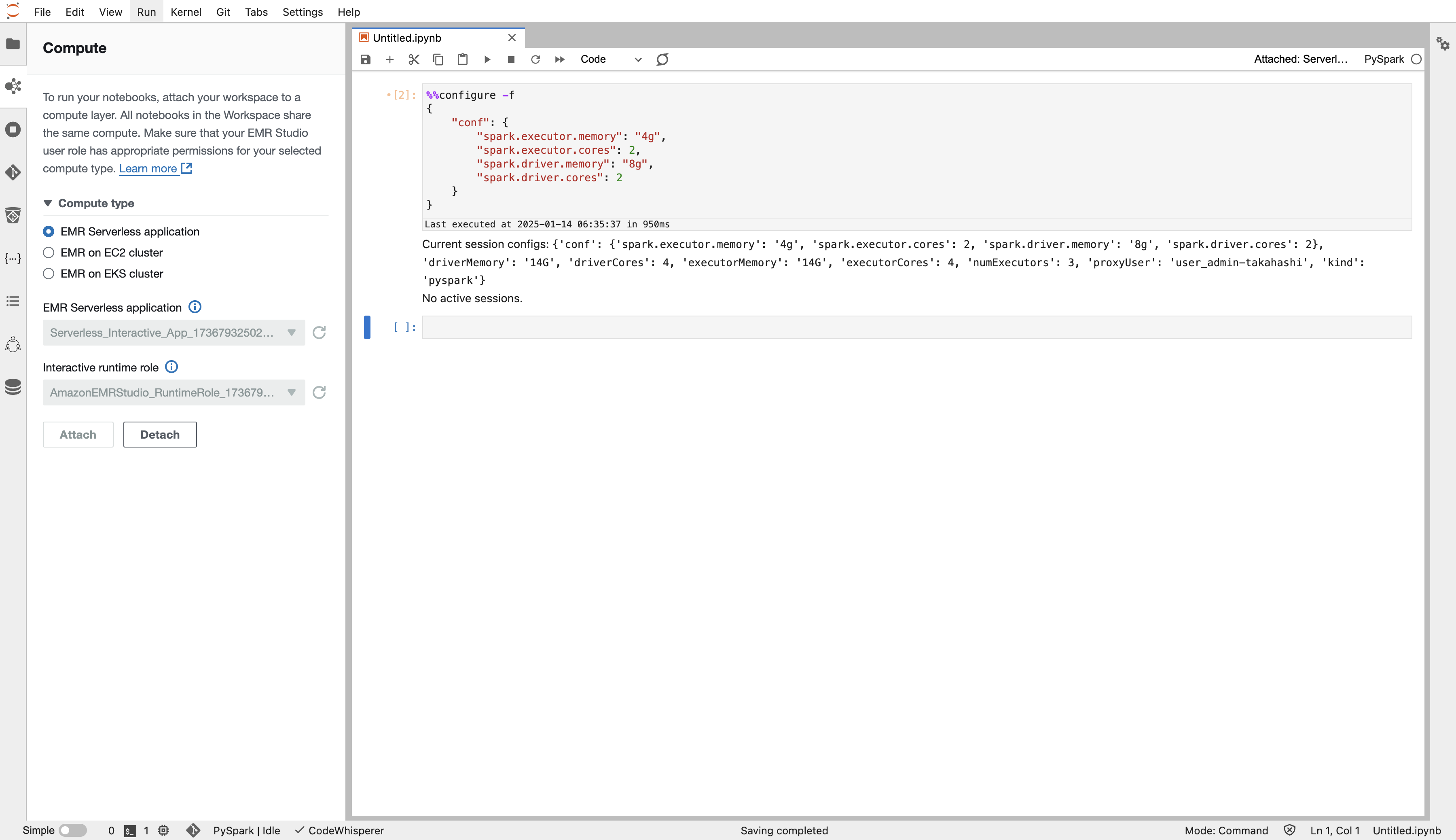
自作のライブラリをimportしたいときに、コードをs3に配置して以下のように書くなどしてしまうと楽かもしれません。
%%configure -f
{
"conf": {
"spark.executor.memory": "4g",
"spark.executor.cores": 2,
"spark.driver.memory": "8g",
"spark.driver.cores": 2
},
"pyFiles": [
"s3:///util.pyfiles.zip"
],
"Files": [
"s3:///params.json"
]
}
コードの実行
実際にimportでも処理を実行すると、spark sessionが作成されます。
その時のcellの出力のリンクからspark web UIにアクセスできます。処理の流れを確認したいときは便利です。
ちなみに、sparkの処理中にローカルで扱いたいファイルは、ジョブ起動時にconfigに指定して、driverとexecutorに送信する必要があります。
notebookでは、s3などに置いておいてboto3などでダウンロードするスクリプトをspark session中に実行してしまうという方法もあります。
movielensより、Movielens 32Mのmovies.csvをparseする簡単なコードを実行してみます。
from pyspark.sql.functions import col, split, regexp_extract
file_name = "movies.csv"
csv_file_path = f"s3://{bucket_name}/{object_path}/{file_name}"
df = spark.read.option("header", "true").csv(csv_file_path)
df = df.withColumn("genres", split(df["genres"], "\\|"))
df = df.withColumn("year", regexp_extract(df["title"], r"\((\d{4})\)", 1))
df = df.withColumn("title", regexp_extract(df["title"], r"^(.*)\s\(\d{4}\)$", 1))
df = df.withColumn("year", col("year").cast("int")) \
.withColumn("movieId", col("movieId").cast("int"))
df.show()
# Parquet形式でS3にパーティションを切って書き出し
parquet_output_path = f"s3://{bucket_name}/datamart/movies/"
df.write.mode("overwrite").partitionBy("year").parquet(parquet_output_path)
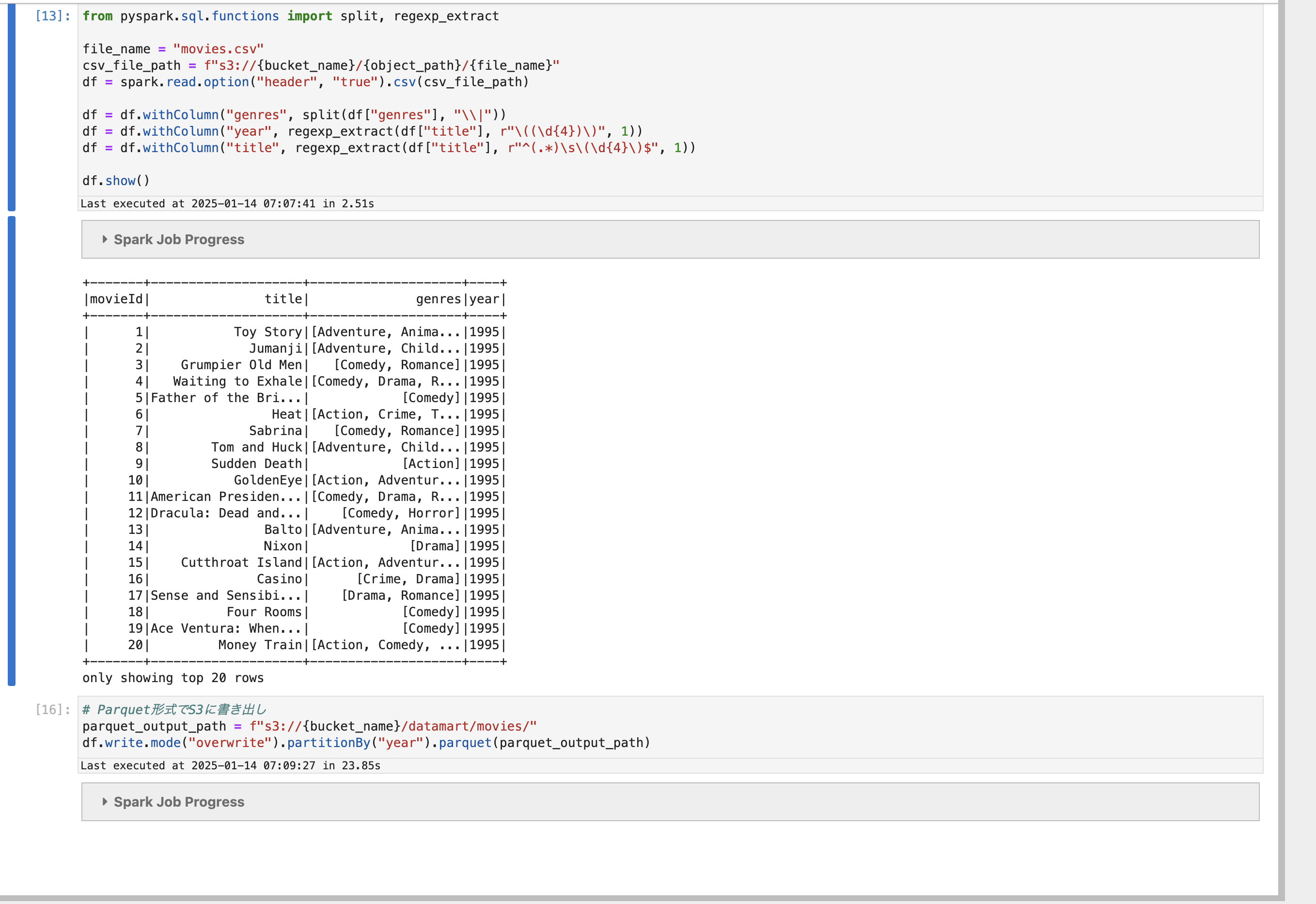
今回はデータサイズが巨大ではないので特に何もしていませんが、巨大なデータを大量のSpark Executorで処理する場合、非常に多くの小さなファイルが書き込まれる場合があります。
後述のAthenaのクエリ性能やコストに悪影響を与える場合があるので、repartitionなどの処理を追加し書き込みファイル数を減らす工夫をしましょう。
Athenaのテーブルにしよう
簡単な集計ぐらいはクエリエディタのSQLを書いた方が楽。皆さんもそう思いませんか?
Athenaでデータを見れるようにしましょう。
Glue ETL Jobを使うとか結構いろいろなやり方があるのですが、結局は今からやるようにDDLをAthenaから流してテーブルを作成し、データの実体は別で作ってテーブルに書き込むというのが一番わかりやすいように思います。
csvから直で読み込むような方法もありますが、個人的にはあまりお勧めしません。自分でもやってみましたが、型を想定通りに読み込むのに苦労したり、どうやっても日付型が思うようにいかなかったりで苦労しました。
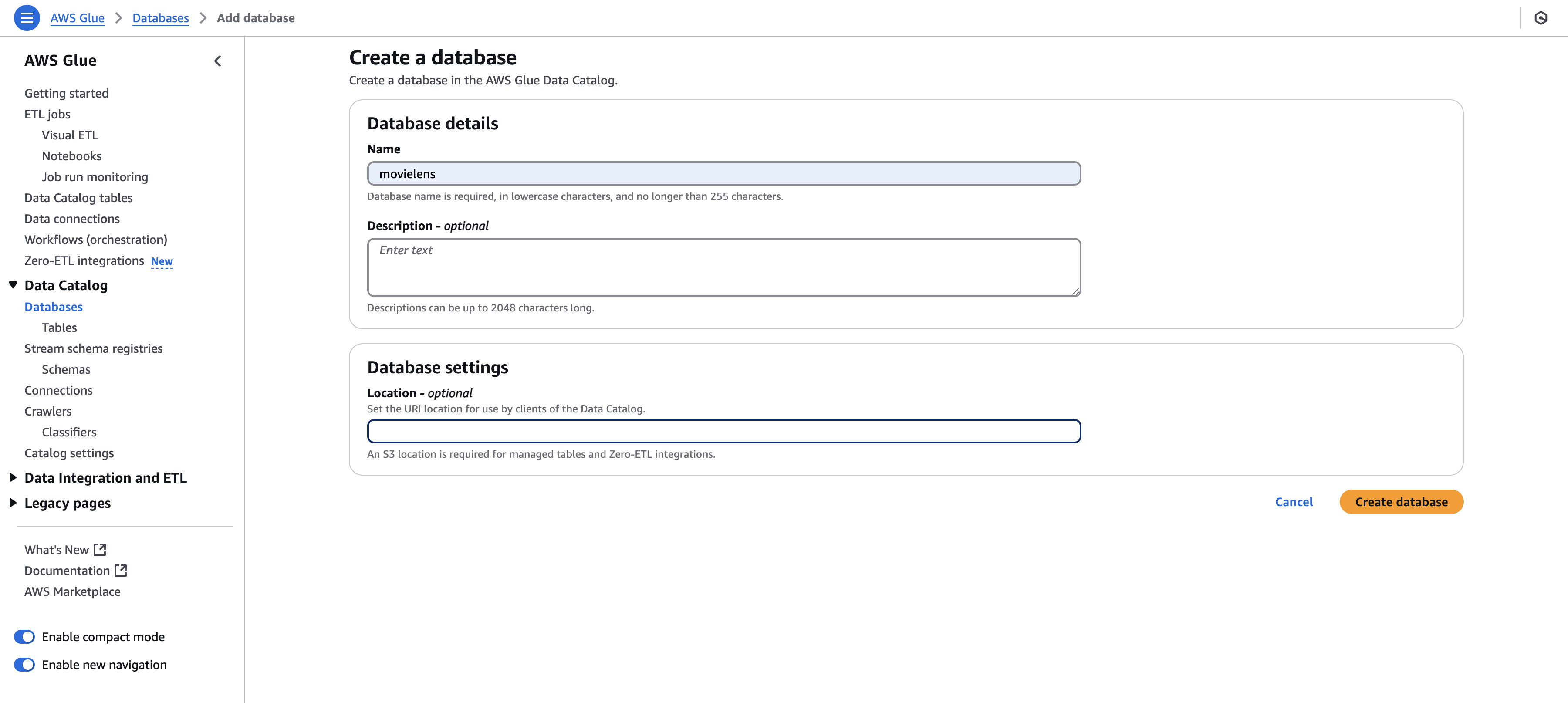
最初に、databaseを作っておきます。データベースのスキーマのようなものです。defaultでも良いですが一応作ります。
DDLを実行してテーブルを作りましょう。
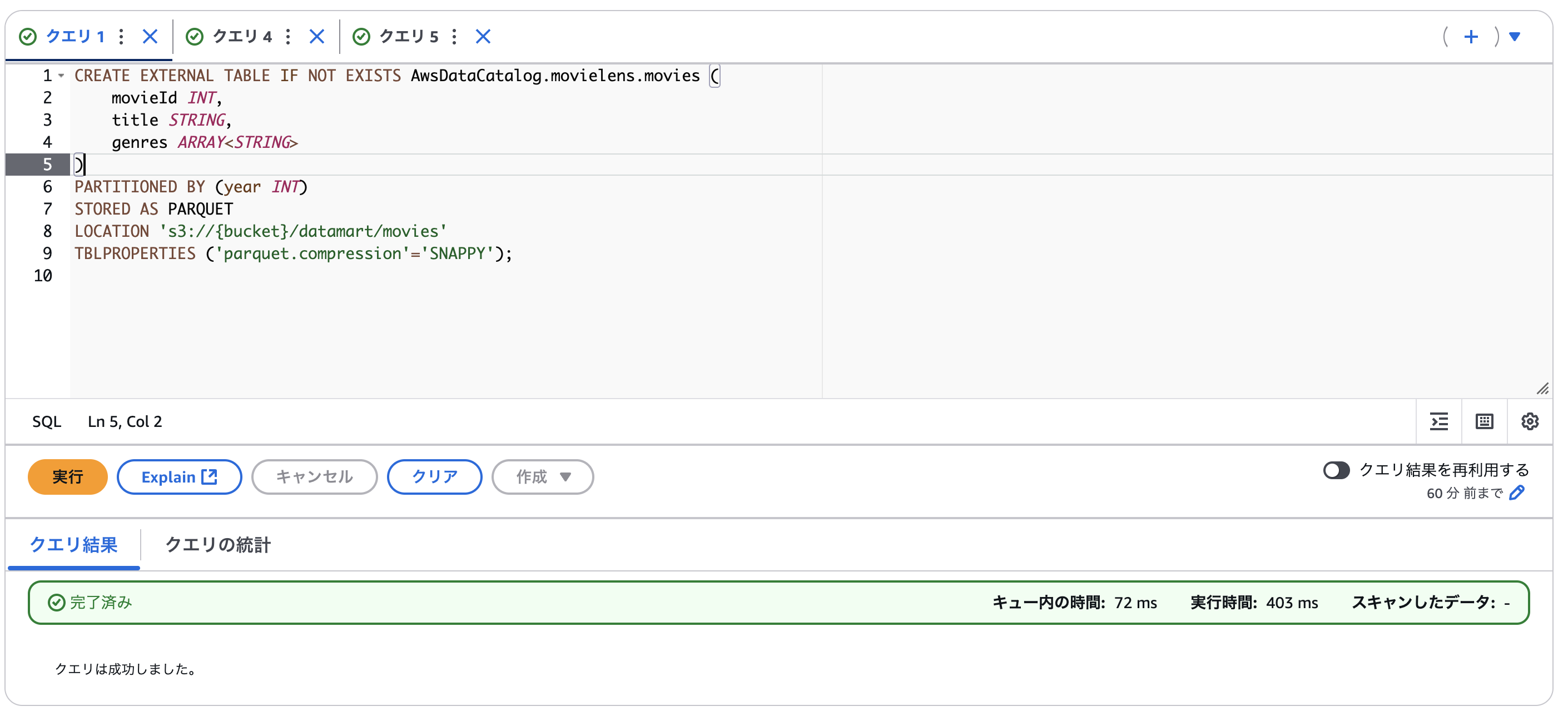
CREATE EXTERNAL TABLE IF NOT EXISTS AwsDataCatalog.movielens.movies (
movieId INT,
title STRING,
genres ARRAY
)
PARTITIONED BY (year INT)
STORED AS PARQUET
LOCATION 's3://{bucket}/datamart/movies'
TBLPROPERTIES ('parquet.compression'='SNAPPY');
今回はs3ロケーションに直接parquetファイルを配置したため、テーブルを作成した後にパーティションを読み込む必要があります。
MSCK REPAIR TABLE `movies`;
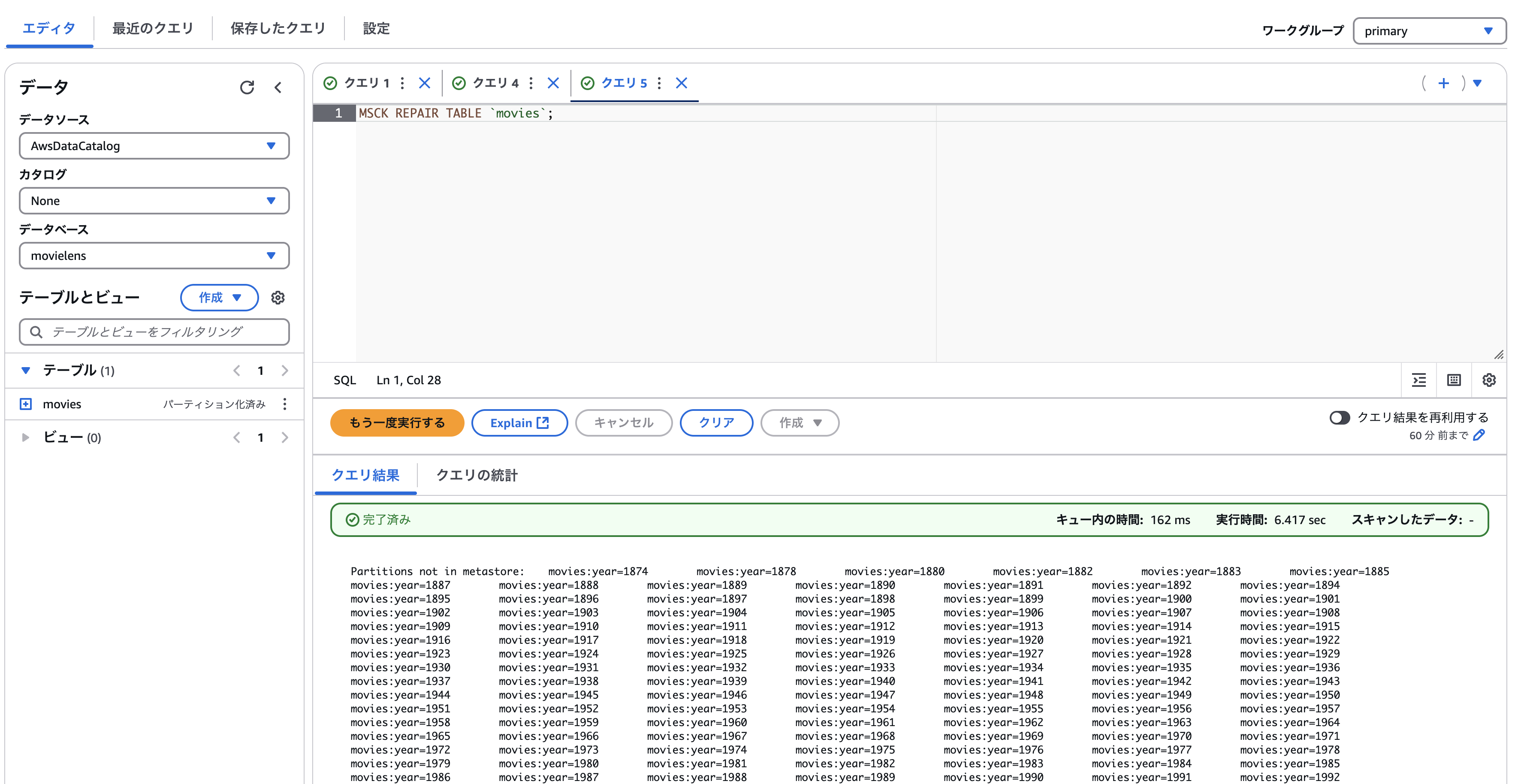
できました。
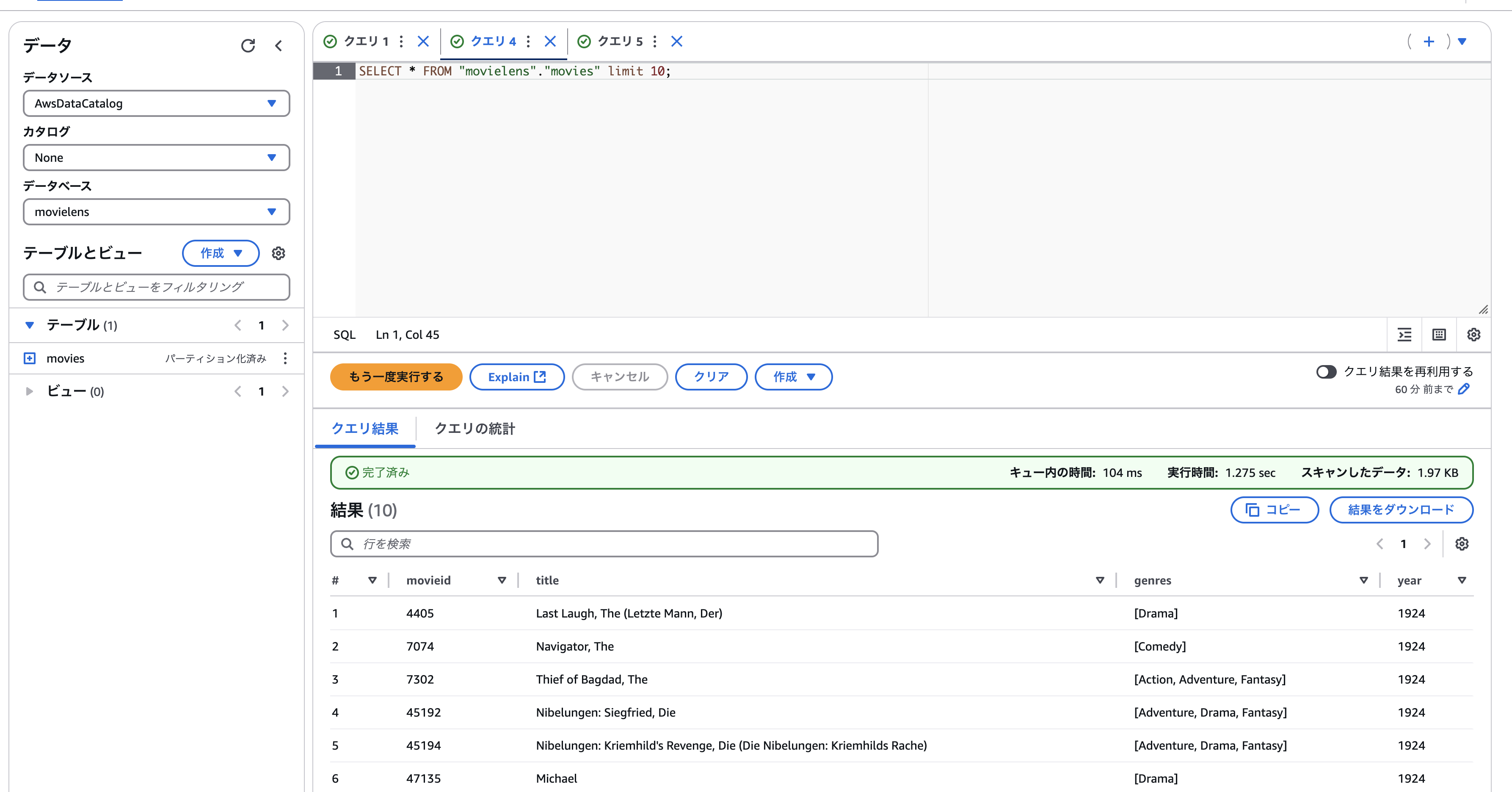
あとは煮るなり焼くなり好きに分析しましょう。例えばジャンルごとのカウントなど。
まとめ
movielensのcsvデータを、Athenaのテーブルにして簡単な集計をかけられるようにするまでの流れを一通り説明しました。
今回はビッグデータというほどのサイズのデータを扱いませんでしたが、かなり大きなデータを扱う時にはおすすめです。
データの実体は高圧縮されてs3上に置かれているだけのようなものなので、大きなデータを置いておいても意外と安いです。
Sparkはワークロードによるのでなんとも言えませんが、サーバーレスに動くので使った分だけ。Athenaもスキャン自体は1TBをスキャンして5USDぐらいです。
気楽に試せるコスト感ではあると思うので、興味があればぜひ!
参考
宣伝
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD