2025.01.14
Self RAGを簡単に作ろう ~ DifyとAWS Bedrock Prompt Flowの比較 ~
導入
こんにちは。グループ研究開発本部 次世代システム研究室のH.Oです。今回もAIアプリケーション開発の話題をお届けしたいと思います。前回のブログでは、検索精度が大きく向上するAdvanced RAGの手法の一つ、Self RAGをLangGraphを使って実装する方法を取り上げました。LangGraphは非常に便利なライブラリですが、実際にAdvanced RAGをアプリケーションとしてデプロイし、運用するまでには多くの工数がかかったことも否めません。今回は簡単にSelf RAGのアプリケーションを実装・デプロイする方法として、DifyとAWS Bedrock Prompt Flowを用いた実装を試し、双方の特徴やメリット・デメリットを比較しました。
目次
結論ファースト
|
|
メリット |
デメリット |
|---|---|---|
|
Dify |
|
|
|
AWS Bedrock Prompt Flow |
|
|
おさらい
まず本題に入る前に、実装しようとしているSelf RAGとはどのようなものだったかおさらいします。詳しくは前回の記事をご覧ください。Self RAGとは、プロンプトに特定ドメインの知識や最新の知識を検索・取得してきたものを混ぜてLLMに送信することで、回答精度を向上させるRAGに、さらなる工夫を加えることで回答精度をより向上させることのできるソリューションです。具体的には、プロンプトの入力 → 関係する知識情報の検索 → LLMに投げてresponseを受け取る、といったRAGの基本的な流れの中に、
- 検索した知識情報の関連度を評価し、関連が薄いと判断した際にはプロンプトをもう一度作り直す。
- LLMが生成した応答が、検索した知識情報に基づいているか評価する
- LLMが生成した応答が、元の質問に対する回答として適切かを評価する
という三つの評価を追加しています。各々の判定は回答生成とは別個に、LLMに対してシステムプロンプトと、質問文、知識情報を渡すことによって実現しています。
前回の記事ではこのフローをLangGraph、LangServeを使ってコーディングベースで実装し、デプロイする方法について扱いました。一旦LangGraphでSelf RAGを実装し、応答の精度が向上したことは確認できましたが、以下の課題が浮かび上がりました。
課題
- LangGraphアプリケーションはコーディング量が多く、複雑なアプリケーションになればなるほど実装工数が嵩むこと。
→LangGraphで開発するようなAIエージェントは業務の観点からは本筋というよりもサブの位置付けであることの方が多いのではないか、と考えると実装工数が嵩むことは主たるプロジェクトの開発業務を圧迫する可能性が高くなります。 - LangChainエコシステムでは、LangChainアプリケーションをデプロイして本番で運用することを想定したプラットフォームである、LangGraph Cloudが開発中であるが、これがまだ実用に供さないレベルなので、AWS Lambdaにアプリケーションとしてデプロイする方法をとった。開発と運用のプラットフォームが分離しているためできることなら統一したい。
上記の課題を解決する方法として今回検証したのが、DifyとAWS Bedrock Prompt Flowです。
実装するSelf RAGの概要
今回も前回同様、Indexとして、天秤AI mediaで公開されているこちらの記事を使いました。
質問は「ChatGPTの企業・自治体の活用事例を天秤AI mediaの記事を参考にして教えてください」というものです。
期待する回答
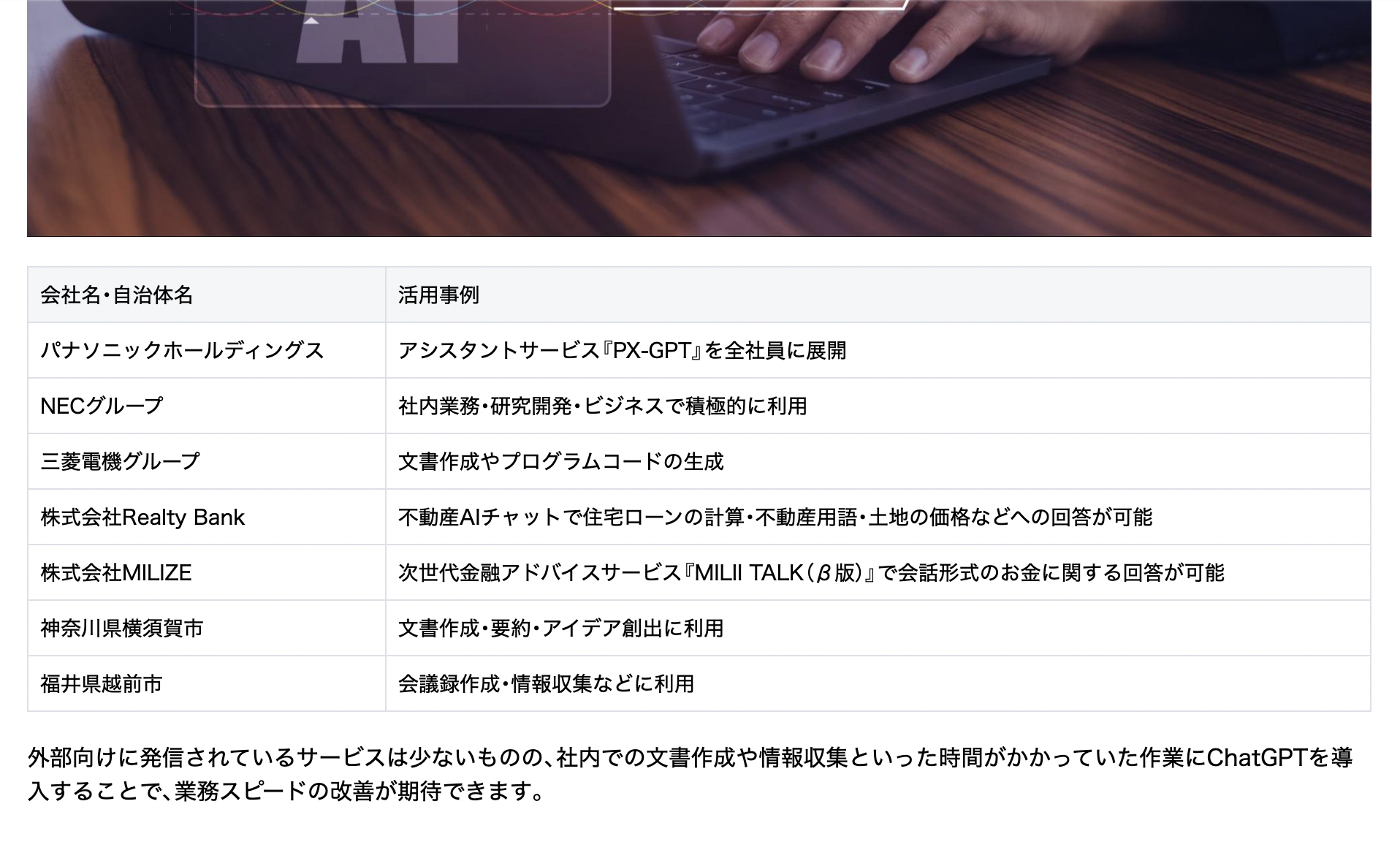
記事には、企業・自治体の活用事例が、具体的な団体名とともに、表形式で書かれています。固有名詞レベルで具体的な回答が得られることをゴールとすることで、回答精度の向上がわかりやすく評価できると考えました。
Dify
Difyとは、大規模言語モデルを用いて、AI機能を持つアプリをノーコードで開発できるツールです。 特定のタスクや目的を達成するために動作するAIエージェントや、複雑な処理を行うAIモデルなど「LangChain」などのライブラリを用いてプログラミングをするよりも簡単に開発できます。
こちらが作成したSelf RAGのフローです。
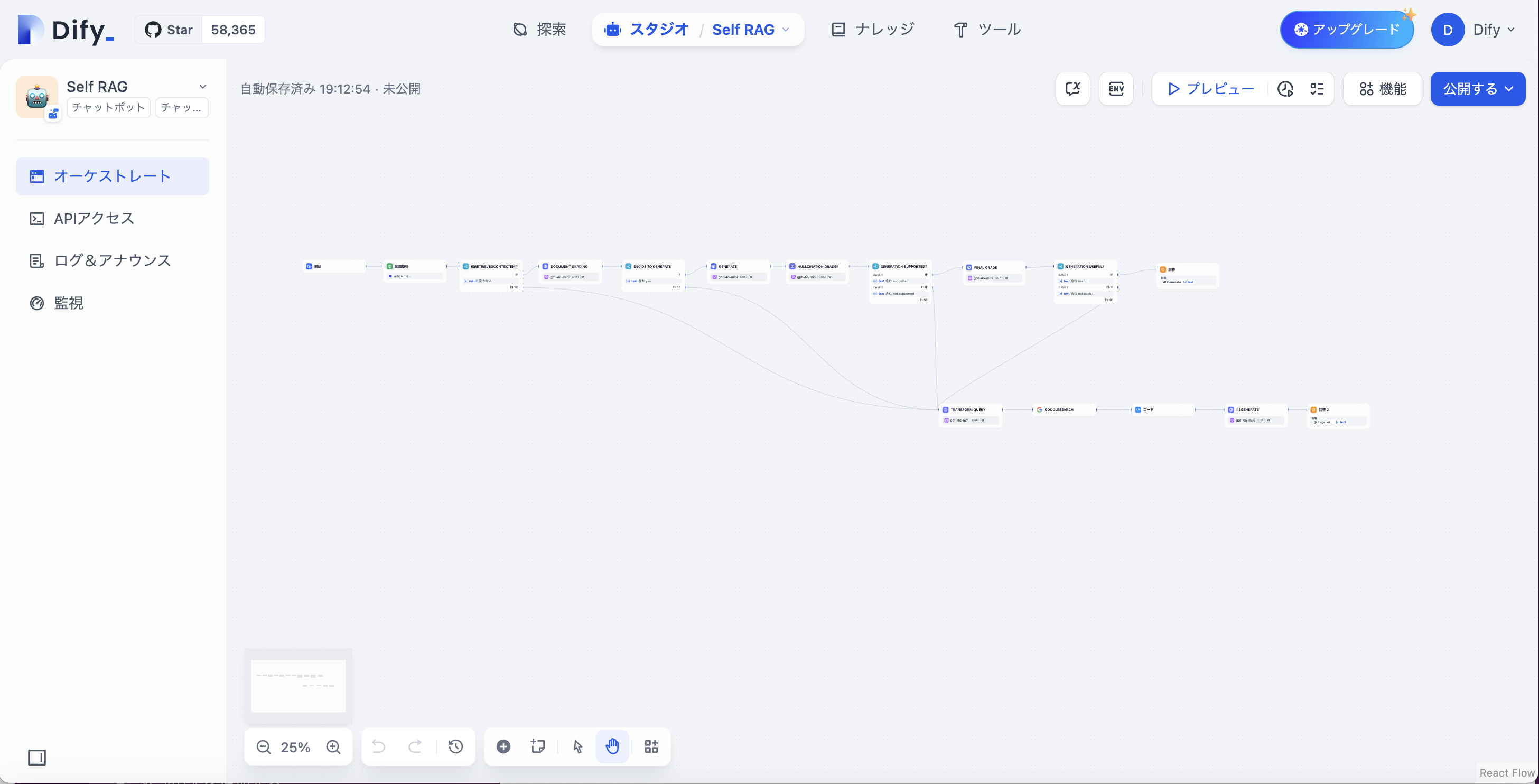
実装上の注意点として、ループ処理を作ることができないという仕様があります。
ノーコードツールのため、エンジニアでない人が使うことを想定し、無限ループを実装してしまうことを未然に防ぐためと推測されますが、ループ状にNodeを繋げることができなかったため、代替機能として、各判定でNoが返された時、Web検索APIであるGoogle Searchを使ってコンテクストを補うことによって回答を生成するというフローに変えました。
これはWeb検索でコンテクストfetchを補完するCRAGのアイデアを取り入れたものになります。
この点を除いて、実装したフローや、内部で用いているプロンプトは前回のものと全く同じです。
それでは実際にプロンプトを入れましょう。
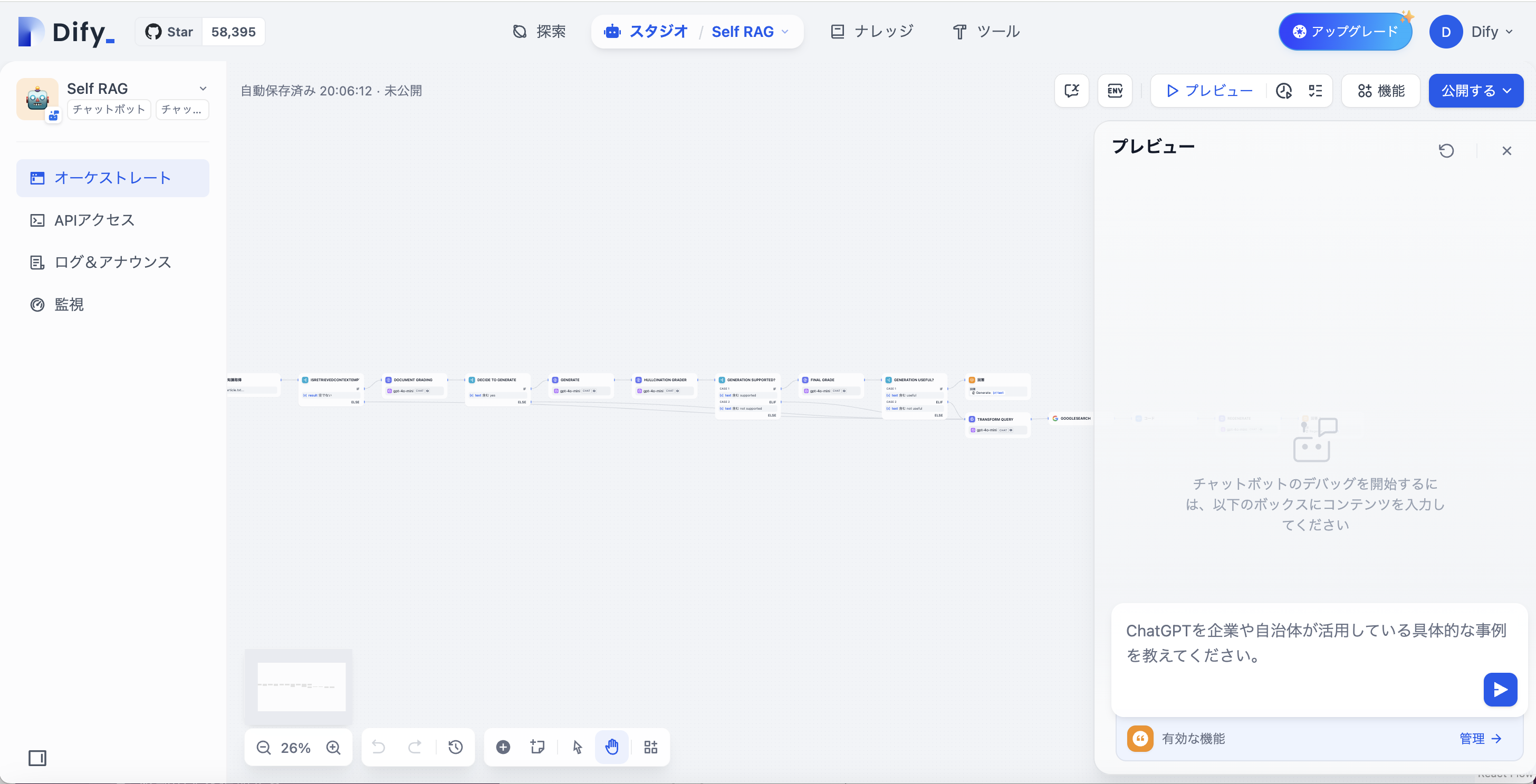
この場合、質問に関連する知識情報があるか、という判定がYesとなるため、上のSelf RAGのフローに進みます。
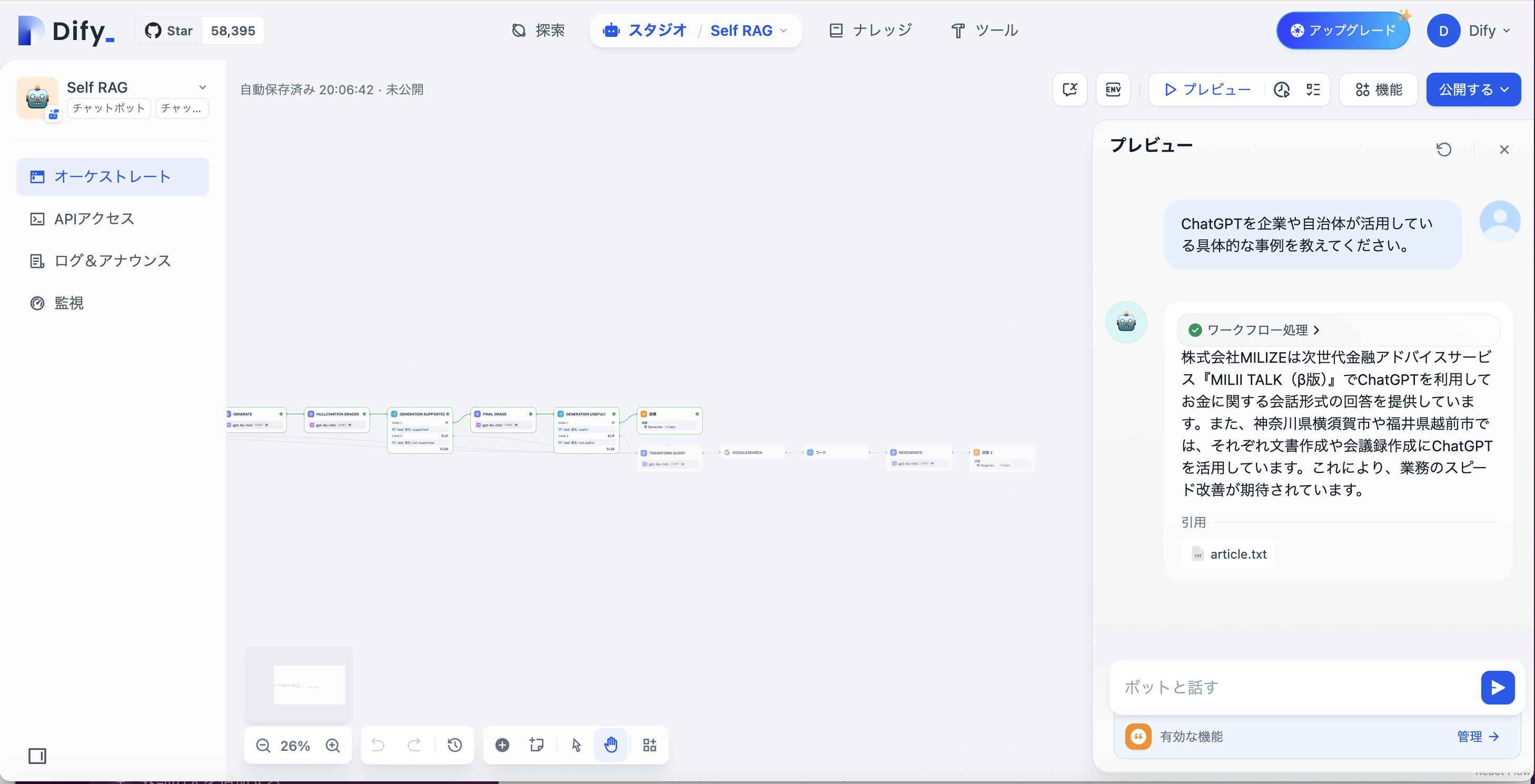
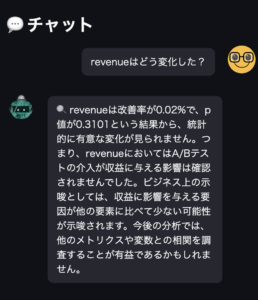
Self RAGの返した応答
「株式会社MILZEは次世代金融アドバイスサービス『MILII TALK(β版)』でChatGPTを利用してお金に関する会話形式の回答を提供しています。また、神奈川県横須賀市や福井県越前市では、それぞれ文書作成や会議録作成にChatGPTを活用しています。これにより、業務のスピード改善が期待されています」
これは記事の内容を適合するものであり、Self RAGに期待する精度の応答だといえます。
それでは、次に質問に関連する知識情報がない場合(今回の場合は知識情報に関係ない質問を投げたとき)どのような応答が返ってくるかみてみましょう。
プロンプトはChatGPT -> Geminiに変えてみます。
今回は質問に関連する知識情報があるか、という判定がNoとなるため、下のWeb検索(CRAG)のフローに進みます。
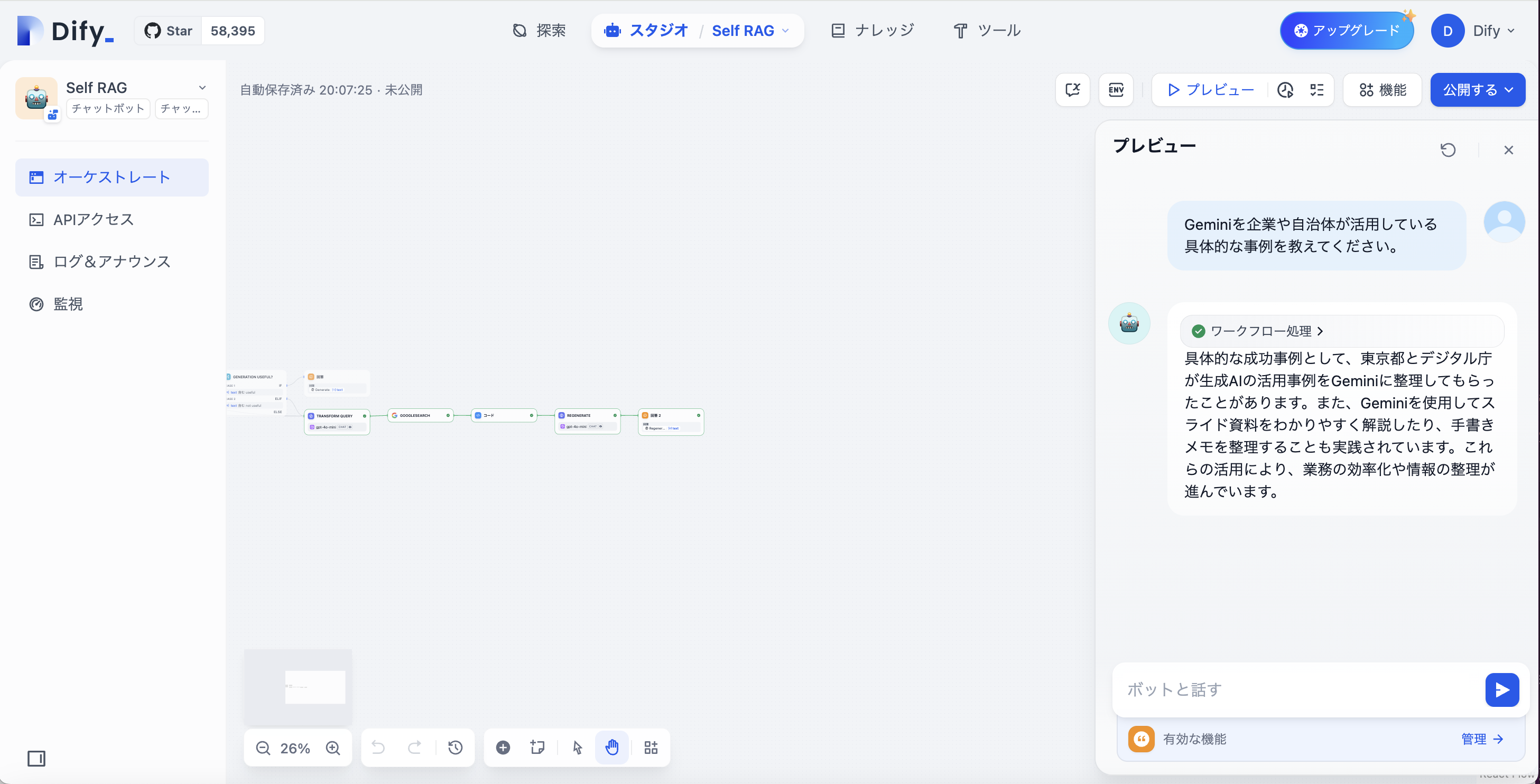
Self RAGの返す応答
「具体的な成功事例として、東京都とデジタル庁が生成AIの活用事例をGeminiに整理してもらったことがあります。また、Geminiを使用してスライド資料をわかりやすく解説したり、手書きメモを整理することも実践されています。これらの活用により、業務の効率化や情報の整理が進んでいます。」
具体性という意味では期待する内容の回答ではありませんが、通常のRAGレベルの回答が返ってきています(前回の記事の通常のRAGのデモを参照)
どちらも処理速度は4~5秒ほどかかりました。実行中、処理が成功したNodeが緑色に縁取られるUI上の工夫がありますが、処理速度が早いとは言えません。
AWS Bedrock Prompt Flow
Amazon Bedrock Prompt Flowsは、AWSが提供するLLM(Large Language Model)ベースのサーバーレスワークフローサービスで、生成AIワークフローを、GUIで構築することができる機能です。大規模な言語モデルを利用したアプリケーションの開発と運用。サーバーレスで動作するため、インフラストラクチャの管理が不要で、スケーラビリティも自動的に行われます。
また、Amazon S3やLambdaなどとの連携を通じて、さまざまなタイプのデータ・処理と結合してシステムを構築することが可能です。
Nodeは、LLMへの問い合わせを行うPrompt、outputの値によって条件分岐を行うCondition、知識情報の検索機能を提供するナレッジベース、Lambdaを使用しています。
Lambdaは知識情報が有用でなかった場合にWeb検索で保管し、再度LLMに送信する処理までをまとめて、実装しています。
import json
import os
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from langchain_community.utilities import SerpAPIWrapper
from langchain.agents import create_openai_functions_agent
from langchain_core.tools import Tool
os.environ['SERPAPI_API_KEY']
os.environ['OPENAI_API_KEY']
def lambda_handler(event, context):
# 入力を読み込む
resource = event.get("node",{}).get("inputs",[])
question = resource.get("question", "")
# Google検索を実行してコンテキストを作成
llm = OpenAI(model="gpt-4o-mini", temperature=0)
# LLM用プロンプトテンプレート
initial_prompt = PromptTemplate(
input_variables=["question"],
template="""
You a question re-writer that converts an input question to a better version that is optimized
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning.
Here is the initial question: {question}
Formulate an imporved question.
"""
)
initial_chain = initial_prompt | llm
search = SerpAPIWrapper()
# エージェントの作成
serpApiTool = Tool(
name="serpapi",
func=search.run,
)
agent = create_openai_functions_agent(
llm=llm,
tools=[serpApiTool],
verbose=True
)
final_chain = final_prompt | llm
final_prompt = PromptTemplate(
input_variables=["original_answer", "search_results"],
template=(
"""
human
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
)
)
# Step 1: 初期回答を取得
renewed_question = initial_chain.run({"question": question})
# Step 2: Google検索を実行
search_results = agent.run(renewed_question)
# Step 3: 検索結果を元に再度LLMを呼び出し
final_answer = final_chain.run({"original_answer": renewed_question, "search_results": search_results})
if not search_results:
return {
"statusCode": 404,
"body": json.dumps({"message": "No results found"})
}
return final_answer
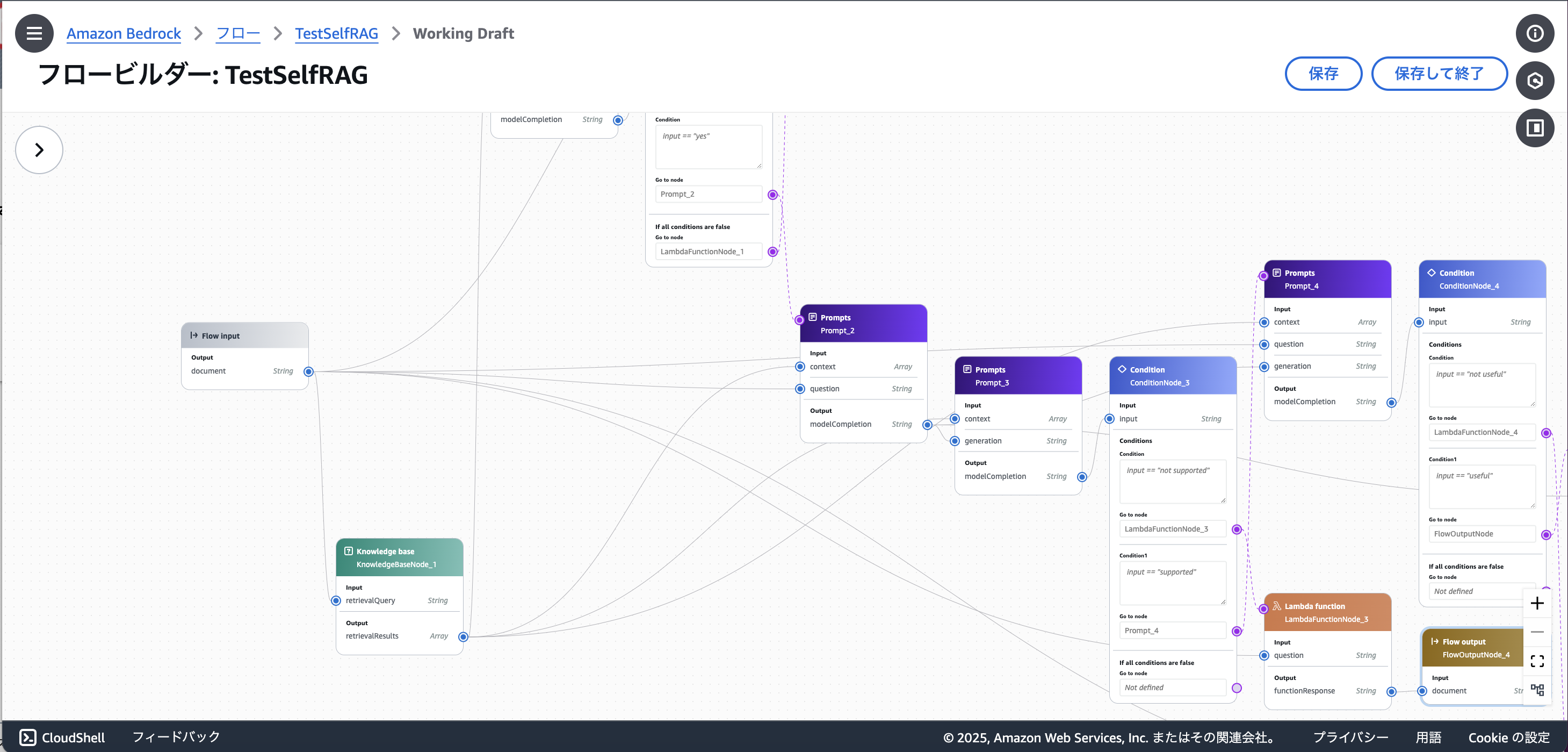
まず、構築したSelf RAGのフローがこちらです。(画面に対してフローの図が大きく、縮小機能が限定的だったため、分割しての掲載となります)
- 知識情報の検索結果が質問に関連したものでなかった場合、Web検索を行って回答生成するフロー
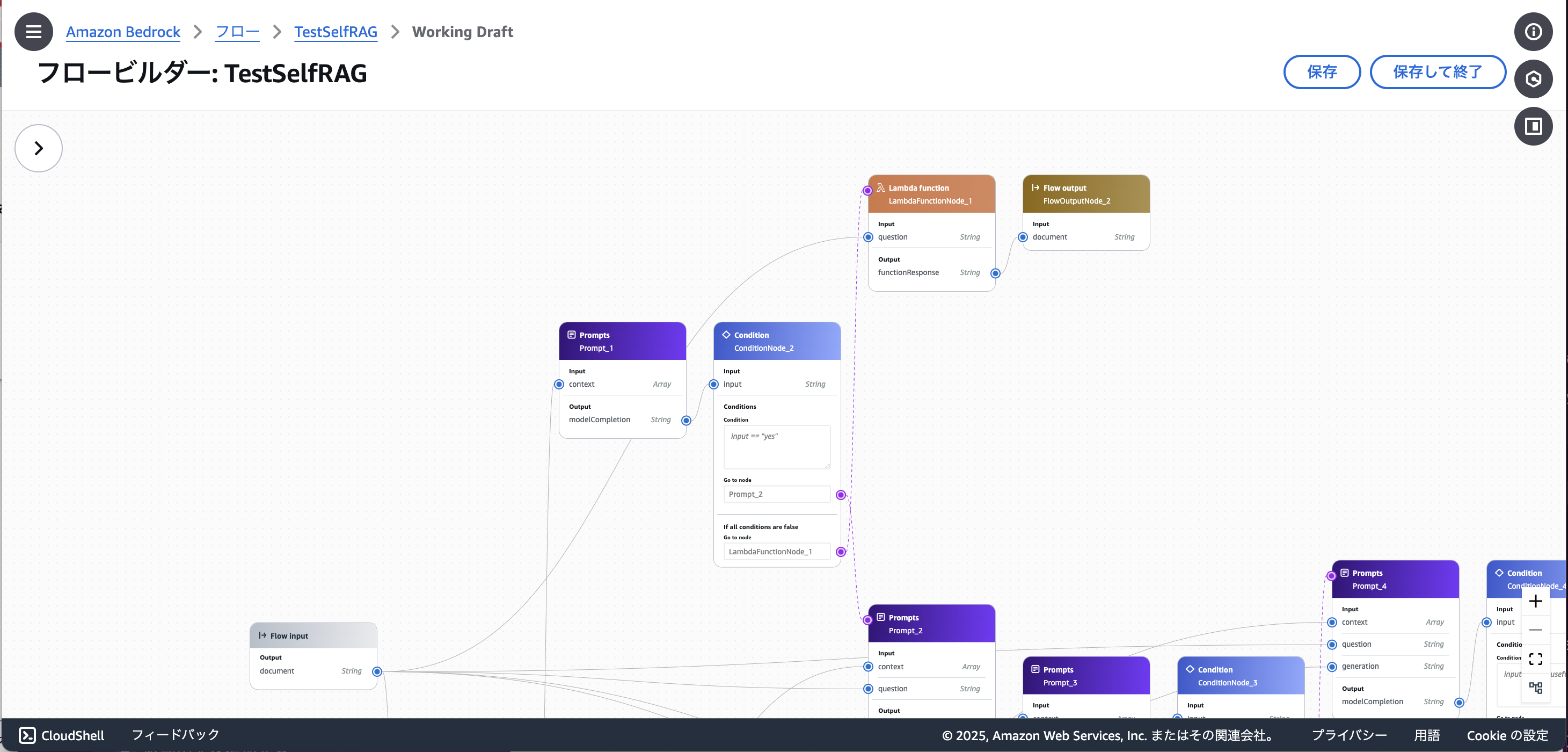
2. 入力されたプロンプトに対して関連する知識情報を検索・取得するナレッジベース
3. ナレッジベースから適切にfetchできた場合に実行されるSelf RAGのフロー
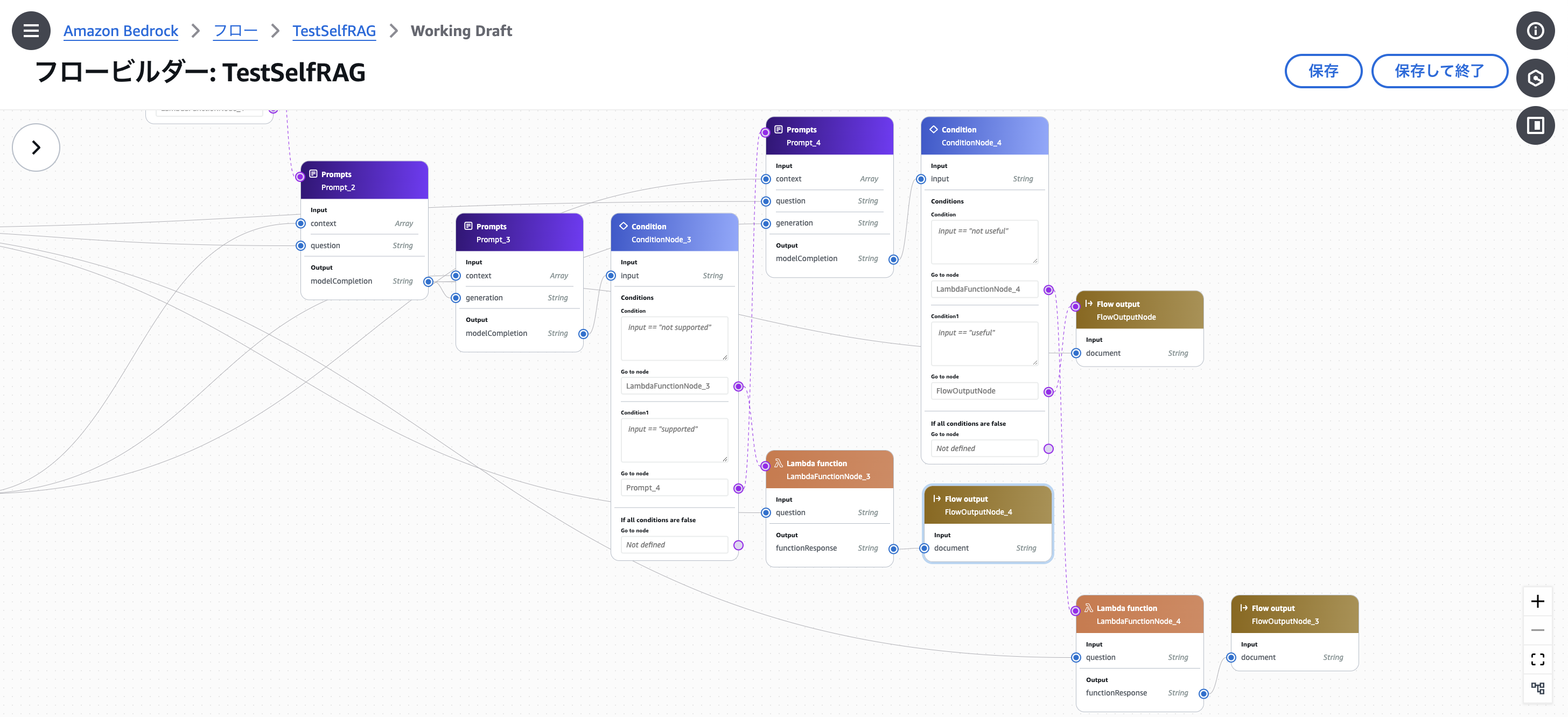
続いて実装に際して何点か注意するべき点がありましたので紹介します。
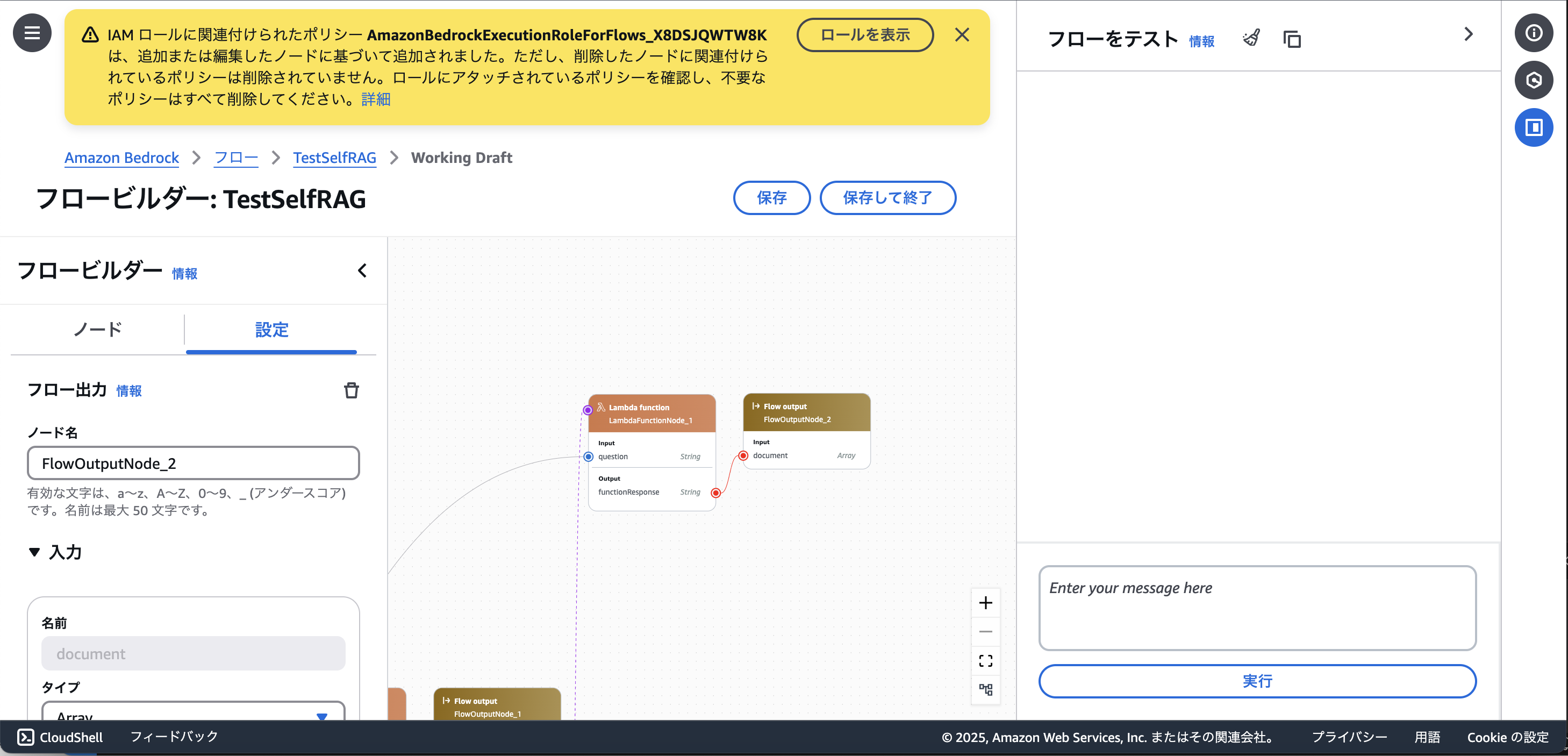
<注意点1> 全てのNodeを正しく設定しないと保存ができない。
保存しようとしてエラーが出た場合。この場合エラーを解消しない限り作成途中のフローを保存できません。

権限設定に不備がある場合はアラーが出ます。しかし、ここで「ロールを表示」をクリックしてしまうと作成したフローのデータが飛んでしまうので要注意です。
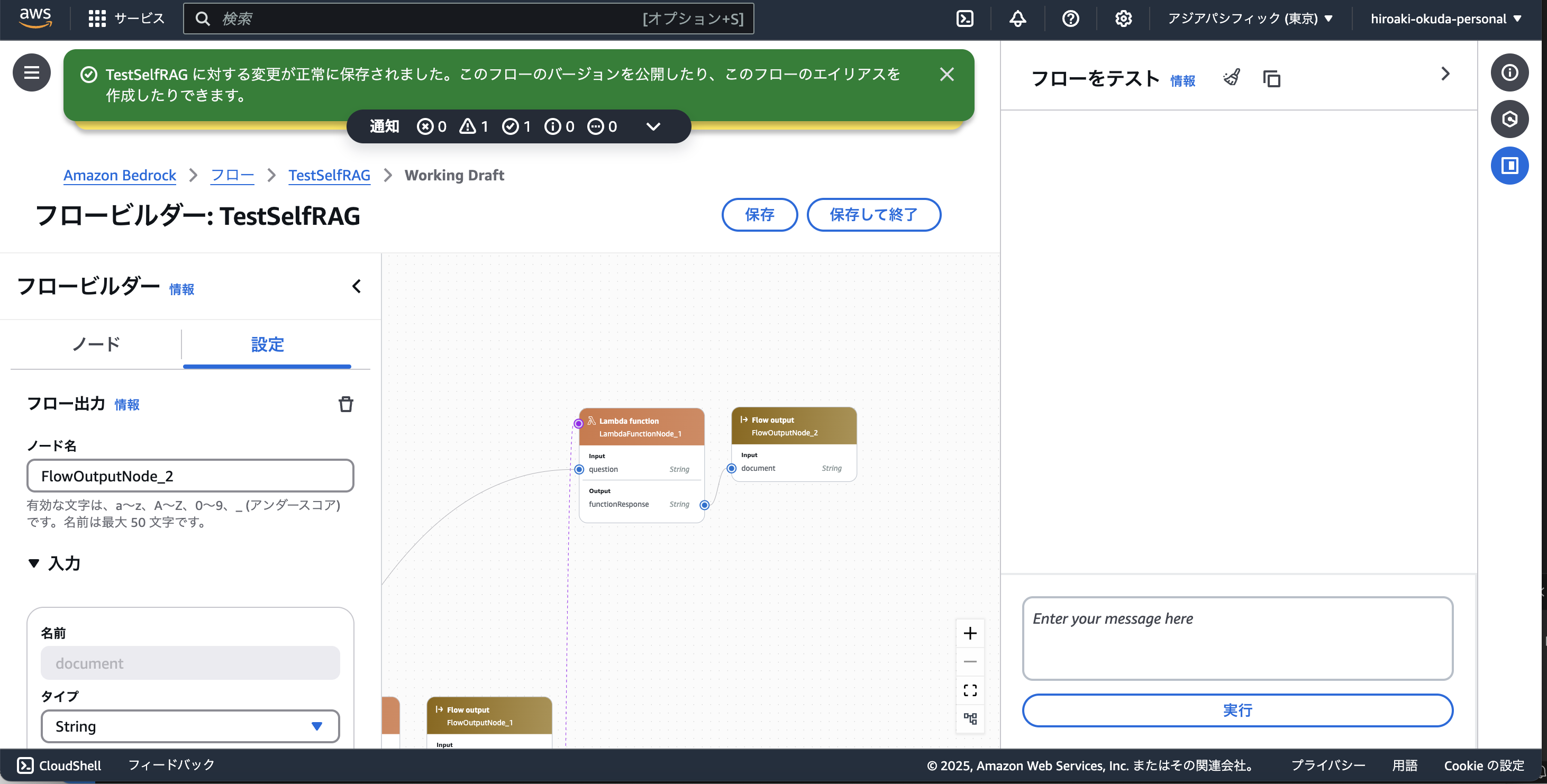
保存に成功した場合
<注意点2>
Difyのように、一つのノードに対して複数のノードから線を繋ぐことができないです。
Difyでは、各Conditionにおいて条件を満たさなかった場合、全てWeb検索による補完をさせたかったので、Google Searchを使用するフローに全てのケースを繋いでいます。一方で、AWS Bedrock Prompt Flowではこの繋げ方ができないです。そのため、
「Queryを作り直し -> Google Searchで検索 -> LLMで再度contextとqueryを送信して応答を返却させる」
という一連の処理をLambdaで実装し、「Lambda -> Flow Output」のノードを各分岐に繋ぐという方法をとっています。
<注意点3>
PromptノードのInputに対しては、自由に引数を設定することができるが、引数はpromptを入力する欄に実際にpromptを入力していき、引数としたい変数を{{hogehoge}}のように入れると、引数の項目が出現するようになっており、わかりにくいです。
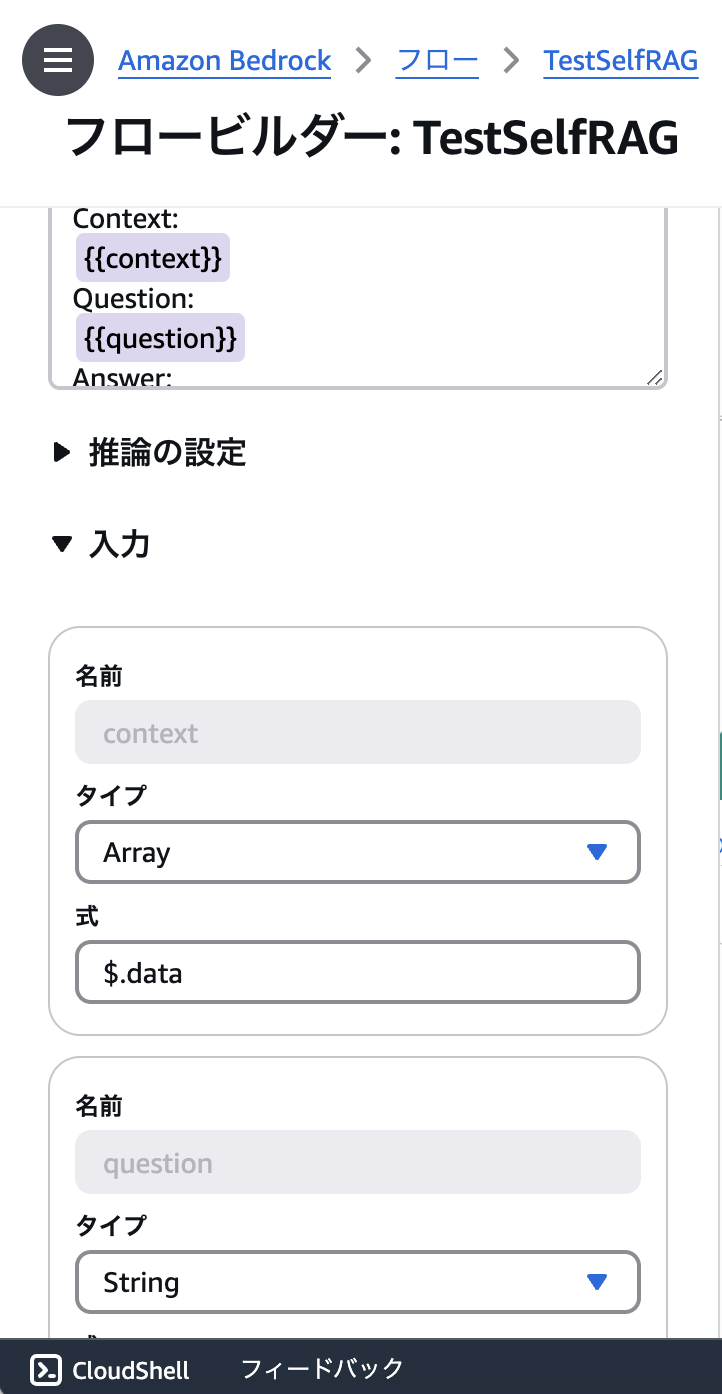
<注意点4>
Promptノード等で使用できるAIモデルはAWS Bedrockで使えるものに限られます。
これはAWS Bedrock内の機能なので当然ですが、AWS Bedrockで使えるモデルだけが使えるため、OpenAIやGeminiを使用することができないです。もし、使用したい場合はLambdaの中でOpenAI APIやVertex AIを呼び出す処理を実装し、Nodeとして繋げることになります。しかし、もしこの方法を取るのであれば、アプリケーション開発とほぼ同じことになり、元々の、コーディング工数を減らすという趣旨に反するとも考えられます。
このようにいくつか使いづらさを感じる点がありましたが、フローの実行時間が2秒程度であり、Difyに対して処理速度の速さは優っていました。
まとめ
DifyでSelf RAGを作成する場合は、各判定でnoが出た際にプロンプトをLLMに書き直させて再度元のフローに戻す、というループ処理を実装できない。そのため、Google Searchのコンポーネントを追加することで、判定でnoが出た時はGoogle検索で知識情報を補う方針をとることで、実装ができた。実行時間が5秒ほどかかるという欠点があるが、回答の精度は良く、実用的です。
AWS Bedrock Prompt Flow でSelf RAGを作成する場合、非常に制約が大きく実装が困難でした。また、フローのビジュアル・挙動などが直感的でない場合が多く、各コンポーネントを正しく連結しない限り、作成したフローが保存できず画面遷移をしてしまうとデータが飛ぶということがあったため、使い勝手がDifyに比べて良くなかったことは否めません。一方で、Lambdaやナレッジベース、S3との連携によって扱えるデータソースの選択肢、処理の拡張が可能であること、実行速度が速く、1秒少しで応答が返ったという点が強みでした。今後の機能の充実次第ではより高度で柔軟なAIアプリケーションの実装が可能なのはこちら側だと考えられます。
最後に
グループ研究開発本部 次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネット上の高度なアプリケーション開発を行うエンジニア・アーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD