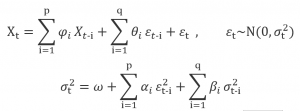FX取引では、マーケットを予測しながら、安く買うか高く売るかという視点でポジションを建てることが、言うまでもなく、とても重要だろう。実は、ポジションの決済タイミングが利益を取るために、同じ重要かより重要とも言える。FXマーケットはトレンド相場があれば、レンジ相場があるが、タイムスパンを変えれば、トレンド相場がレンジ相場に見える(勿論、逆もある)。そうすれば、新規ポジションは、上手く建てても、後は損する可能性がある。新規ポジションが逆に悪いタイミングで建てたとしても、上手い決済タイミングを見つければ、利益を取ることがある。今回のBlogは、深層学習を利用し、マーケットの先予測ではなく、いい決済タイミング(上手く利確か損切り)を学習できるか検証しようと思う。
問題定義
新規注文で売り買いした通貨ペアの持ち高(建玉)をポジションと呼ぶ。決済は、反対売買し、ポジションを手放し、利益または損失を確定させることです。決済しなければ、損益が確定されないままとなりますが、含み損が証拠金の一定割合まで膨らみすぎると、FX業者のシステムに強制的にロスカットされる。
FXの決済は、含み益が出ているときに決済する「利益確定(利確)」と、含み損が出ているときにそれ以上の損失を防ぐために決済する「損切り」に分かれます。又はリスク管理の視点で、リスク量を減らすために、ポジションを減らすこともある。マーケットが常に、下がったり上がったりするので、利確が遅れるか損切りが早かったのは、頻繁に発生する。利益が上手く取れる人は、その利確又は損切りのタイミングを上手に見つけるが、一方、損失の人は、良く損大利小という負けるパータンにはまる。今回の問題は、下の図のように、すでにポジションが持てる前提で、いつにポジションを決済すれば損小利大かということである。
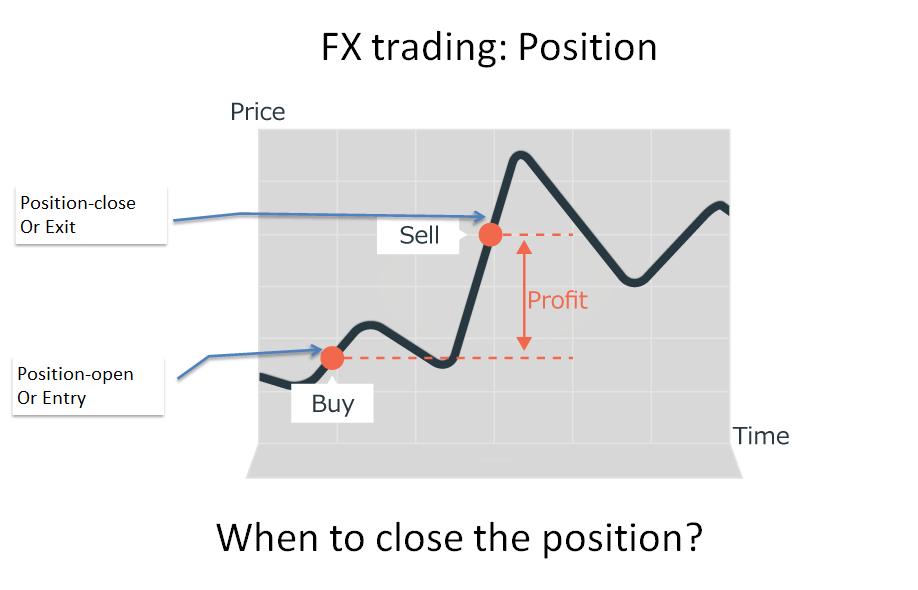
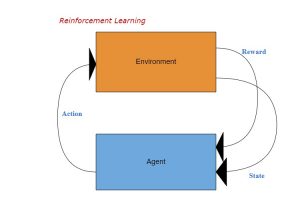
ポジション決済は、予めに利確や損切りの閾値を決めて指値注文又は逆指値注文を出すこともあり、現在のマーケットプライスに追随し相対的な利確・損切りの閾値を設定するトレール注文を出すこともある。勿論、裁量取引で複数の要因を総合判断し、手動で反対売買することもよくあるだろう。今回は、このロジカルをデータから自動学習できる強化学習を応用してみたい。
この問題に対して、強化学習はすごくモデリングしやすい。動作空間:0 (ポジション保有)or 1(ポジション決済)という離散的な空間。状態空間:{ポジション情報(含み損益、売買方向、数量)、Marketプライス(移動平均、ボラ、Max/Min、その他TA指標)}。報酬は、ポジション決済の動作を選んだら、決済損益にすればよいが、ポジション保有の動作を選んだら、含み損益か含み損益の差分か、色んな視点があり、決めにくい。そして、決済ロジカル自体は、正に強化学習の動作ポリシーに相当する。
方法
今回は
TRPO (Trust Region Policy Optimization)という強化学習モデルの勉強も兼ねて、このモデルをメインに検証した。TROPはICML 2015に発表された論文で、後続の有名なPPO(Proximal Policy Optimization)と同じ作者である。TRPOの基本コンセプトは、基本のPolicy Gradientベースの強化学習と同じく、下記の式に示したように、Q関数(s_t, a_t)、V関数(s_t)、そしてAdvantage=Q-Vを定義する。
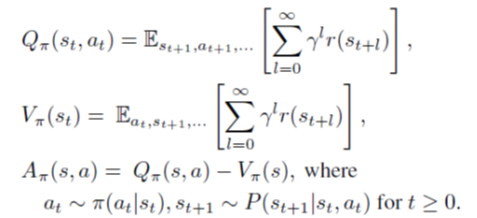
そして、学習の目的関数(L関数、実は期待報酬)は下記の式を定義した。新しいPolicyで動作を決めるが、古いPolicyで学習済みQ/V関数を用い、プレミアム報酬(L関数の第2項)を決める。通常報酬(L関数の第1項)はよく使われる、遅延報酬(動作後の将来報酬)を割引して累積したもの。
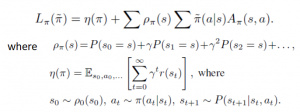
更に、TRPOの一番特別なものは、下記の式に示したように、Policyの更新を暴走しないように制限すること。新しいPolicyのParameterと古いPolicy(既存)のParameterの分布乖離(KL Divergence)をあの閾値以内(Trust Region)に制限する。そして、通常報酬(L関数の第1項)は新しいPolicyのParameterと関係がないので、最適目的関数から外れる。そして、プレミアム報酬のA関数はQとV関数から計算できるし、更に、V関数もQ関数から計算できるから、プレミアム報酬もQ関数の関数に統一できた。

今回の実験ではTRPOモデルが
Stable-baselinesに実装されたものを流用する。FX-Marketデータが
ここにある2019年のUSDJPYの分足を利用している。Hyperparameterなどのチューニングもないので、Validationデータを作らなくて、Train/Testに二つ分け、TrainDataは2019年1月から2019年7月まで、Testデータは2019年8月分になる。InputのFeatureは、Positionの含み損益、PriceのOHLC、Closeプライスの二つ移動平均(7分/14分)及びその差分、プライスの標準偏差、方向の強さを表すTA指標(ADX)、最大・最大値の幅(7分/14分)、そして、プライス系のFeatureなら、-1から1間にスケールを統一するため、OpenPosition時のPriceを引く。さらに、買いと売りの方向も考慮し、売買Sideを掛け合わせる(買うなら1、売るならー1)。ポジション決済(クローズ)の報酬は、決済損益にするが、ポジション保有のアクション報酬は、前回の含み損益との差分に0.5を掛け、更に、-0.002 (-0.2 pips)のペナルティを足す。ポジション保有時間が10分を超える(又は含み損益が-20Pipsに下回る)と、強制クローズにする。
ランダムのタイミングにランダム売買し、ポジションを新規建てる(10000回)。ベースラインは、この新規ポジションを3分後にクローズする。強化学習モデルなら、Trainデータで学習したモデルを用い、Test期間でも、同じように10000回をランダムにポジション建て、ポリシーにより決済を行う。評価の主要指標は平均Return(スプレッドなし)。
結果&考察
モデルの有効性・実装の正確性を確認するため、傾向が明白なToyDataで実験する。ToyDataは、NumpyのSin関数を使い、SinWave+WhiteNoiseで生成される。学習結果は、Baselineの平均Returnより、大幅に超えた。Baselineの平均Return=1.7 pipsに対して、TRPOモデルの平均Return=9.24Pips、T-検定のp-valueもほぼゼロである。下図はOpenPositionとClosePositionの平均プライス変化量。0時点はOpen/Closeの時点で、マイナスの時間軸はOpen/Closeの前、プラスの時間軸はOpen/Closeの後で、Y軸は、0時点のプライス(注文時のPrice)を引き、売買Sideを掛けたプライスの変化量である。注文前のプライス変化量はBeforemathと呼び、注文後のプライス変化量はAftermathと呼ぶ。ClosePositionのBeforemath/Aftermathから見ると、モデルは上手くパータンを見つけ、買い決済なら、プライス上昇が始める段階で行い、売り決済なら、プライスが下がり始めるときで行う。
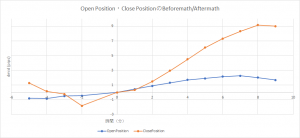
-
Featureの重要性:Scaling&Selection
次は、真のMarketデータを投入し、検証する。だが、結果がまったくだめ、ほぼランタンに決済すると同じくらい。そして、未来のプライスもFeatureに入れて、試しても、平均Returnはほぼゼロだった。色んな調査をしたあと、FeatureのScaleに気づいた。USDJPYの生プライスのスケールが1e2くらいものの、ポジションの含み損益や標準偏差なら、1e-3か1e-1である。さらに、新規買なら、上昇相場がプラス働きだが、新規売りなら、マイナス働きなので、プライスの変化量に新規売買の方向を掛けるべき。このようなFeatureをScaling/Normalizationしたら、未来のプライス情報をLeakyする場合は、モデルがちゃんと学習でき、平均Returnは0.5Pipsまで上がった。下図は1分先のPriceもFeatureにした結果:ClosePositionのタイミングは、買い決済なら上昇し始める時に入ったことが分かる。(OpenPositionはランダムなので、BeforemathもAftermathもほぼゼロ付近)
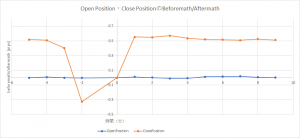
それにしても、情報Leakyしなければ、平均Returnはほぼゼロで、上手く行けない。色んなFeatureを追加したら、最終的に、平均Return=0.048 Pips vs Baseline=0.003 Pipsというこう結果になった。
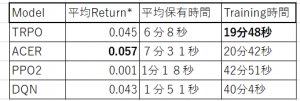
上記のテーブルは、4つモデルの性能比較である。Hyperparameterのチューニングが行わずに、実行環境もクレンジング していないので、あくまでも参考レベルの比較になるが、単純の収益性(平均Return*=モデルの平均Return-Baselineの平均Return)から見ると、ACER(Actor-Critic方法)がよりよい結果が出ている。
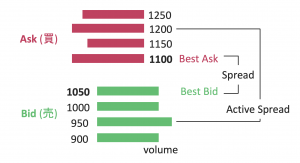
強化学習モデルは決済タイミングを上手く学習ができるが、真のマーケットでは、その優位性がまだ低い(0.05 Pips弱)、スプレッド(USDJPYなら0.2Pipsくらい)を考慮すると、実際取引したら損する。ただ、改善空間がまだ多くあるので、チューニングしていけば、実取引にも応用できる可能性があるだろう。また、未来プライスをLeakyした実験から見ると、決済でもマーケットの先を予測出来たら、新規注文と同じくらい優位性が出る。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。