2021.10.07
GAEの10000rps時の自動スケーリング検証
こんにちは。次世代システム研究室のM.Mです。
GAEに関するブログも今回で4回目になります。
前回はサービス公開に向けて必要となるドメインやロードバランサの設定について記載しました。
ただサービス公開にあたって必要となる作業はそれだけではなく、自動スケーリングの設定もしておく必要があります。
自動スケーリングの設定についてはスタンダード環境やフレキシブル環境のマニュアルに記載があるので、今回は設定についての説明ではなく、10000rpsまでリクエスト数を上げて自動スケーリングの検証をした際の結果を共有したいと思います。
1. 検証環境と検証内容
検証環境
- スタンダード環境(F1インスタンス)
- Python, Flask
- 0.01秒スリープして、Hello World!を出力するWEBアプリ
- 初期インスタンス数は1000rpsを処理できる程度の数を設定。その他パフォーマンス重視設定(2. 検証に利用したソースコード参照)
検証内容
- 1000rps(1分間) -> 2000rps(1分間) -> 5000rps(1分間) -> 10000rps(1分間) でリクエスト数を上げていく
- エラーやパフォーマンス遅延が発生しないか確認する
- どれぐらいインスタンス数が増えるか確認する
2. 検証に利用したソースコード
requirements.txt
Flask==2.0.1
app.yaml
runtime: python37 instance_class: F1 automatic_scaling: min_instances: 50 min_idle_instances: 30 target_cpu_utilization: 0.5 target_throughput_utilization: 0.5 max_concurrent_requests: 10 max_pending_latency: 100ms inbound_services: - warmup
min_instancesは何回か検証した際に、おおよそ1000rpsで必要になっていたインスタンス数にしています。
min_idle_instancesは適当ですが、急激なアクセス増があると見込んで多めの数字にしています。
target_cpu_utilization、target_throughput_utilizationはパフォーマンスを優先するように最小値を設定しています。
max_concurrent_requestsは最小値ではないですが、パフォーマンスを優先するように推奨される最小値としています。
max_pending_latencyは0.1秒ぐらいの遅延は許容するようにしています。
main.py
import time
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
time.sleep(0.01)
return 'Hello World!'
@app.route('/_ah/warmup')
def warmup():
return '', 200, {}
8行名で0.01秒スリープして、9行目でHello World!を出力しているのみです。
3. 検証結果
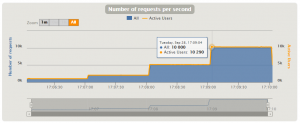
リクエスト数は期待通り、1000rps->2000rps->5000rps->10000rpsになっていることが確認できます。
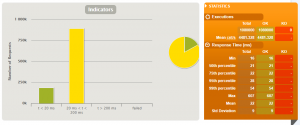
99パーセンタイルで0.054秒を維持しています。0.01秒スリープとFlaskのフレームワーク処理部分もあるので、まずまずな結果だと思えます。
また、GAEに備わっているキューの仕組みがうまく機能しており、処理が詰まってエラーレスポンスを返すといったこともなかったようです。
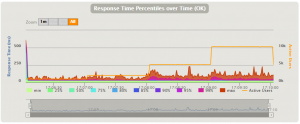
ただし、アクセス数が急増したタイミングで、上の図だと紫色の割合が増えているのが分かります。
やはりパフォーマンス重視の設定でも、自動スケーリングする際のインスタンス生成処理などで多少遅延はするようです。
今回はmin_idle_instancesを多めに設定しているのであまり目立っていませんが、小さく設定するとより多く遅延が発生すると思われます。
(小さく設定して検証した場合でも、数秒かかるような遅延は発生していませんでした)
とは言え、マニュアルにも記載がありましたが、インスタンス生成は秒レベルということで、数秒レベルの遅延で済み、キューの仕組みで処理が詰まるということはなさそうなので、秒レベルの遅延が許されないようなサービスでなければ、許容範囲ではないかと思います。
(ウォームアップ機能を使ってもうまく機能しないときがあるらしいので、インスタンス生成が秒レベルでも、コードの読み込みなど初期化に時間がかかるようなアプリの場合はより遅延は発生します。)
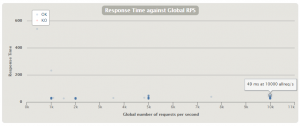
1k(1000rps), 2k(2000rps), 5k(5000rps), 10k(10000rps)の場合でも大きく遅延することなく、ほぼ50ms以内に収まっているのが分かります。
増えたインスタンス数
画面のスクリーンショットを取り忘れてしまったので、インスタンス数の増加傾向の図を見せることができませんが、10000rpsで300~400インスタンス生成されていました。
今回はインスタンスクラスF1でしか検証していないですが、F2, F4といったインスタンスクラスで実行されるワーカー数やスレッド数が多いようであれば、F2, F4に変えて自動スケーリングの設定を見直すことで、生成されるインスタンス数を減らすことができるので、インスタンス生成時の遅延を少なくすることができそうです。
4. まとめ
0.01秒スリープのWEBアプリの場合
- 1000rps->2000rps->5000rps->10000rpsといったようなアクセス増加でも問題なく自動スケーリングした。
- 自動スケーリング時にパフォーマンス遅延は発生するが1秒に満たないレベルだった。
- 処理が詰まってエラーレスポンスを返すといったエラーは発生しなかった。
- F1インスタンスクラスの場合300から400インスタンス生成された。
感想
GAEの自動スケーリングは非常にすばらしい機能だと感じました。
自動スケーリングの設定について難しいなと感じたところは、min_idle_instancesとmax_idle_instancesになります。
今回は検証なので、いつ・どれぐらいアクセスが増えるか分かっているので、その傾向に応じて設定すればよいですが、実際の本番運用では、いつ・どれぐらいアクセスが増えるかなんて分かりません。ある程度運用してアクセス傾向を調べるなどして適切な値を設定する必要がでてきそうです。
また、今回はスリープ程度のWEBアプリだったから問題ありませんでしたが、実際にはWEBアプリと連携しているデータベースなども自動スケーリングに耐えられないといけません。
自動スケーリングが有能だからといって、大きなシステム全体を1つのGAEのサービスで動かせばよいのではなく、GAEのコンセプトにもありますが、マイクロサービスアーキテクチャで複数サービスを連携させるようなシステム設計が求められることも意識しておく必要があると思いました。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD