マーケットメーキングのための強化学習モデル
目次
1. はじめに
みなさんこんにちは、グループ研究開発本部 AI研究開発室のK.Fです。前回は、深層強化学習を用いた暗号資産のマーケットメイキング手法について文献を調査しました。文献から、マーケットメイキング戦略に強化学習を用いるのが有用であることがわかりました。
今回は、実際に取引所のマーケットのデータを取得してみて、強化学習モデルを検討してみようと思います。
結論
強化学習を用いたマーケット戦略の「環境・状態・行動・報酬」を、実際の取引所のデータを用いて定義しました。2. マーケットメーキングおさらい
マーケットメーキングの取引戦略は、mid priceを基準として、その付近の上下に指値を出し、そのスプレッド分の利益を得るというものです。t秒間に取りうる値幅 (Active Spread) をいかに予測するかがこの戦略の肝になってきます。ある時点での板の状況が上図のようになっていたとします。ここで、Best Askより少し下に売り指値 1,099円、Best Bidよりも少し上に買い指値1,051円を出すとすると、両方約定した場合 1,099 – 1,051 = 48円が利益になります。もし、t秒間で1,200円から950円の間まで変動すると予測できたとすると、1,199円と951円でそれぞれ売りと買いの指値を出し、1,199円 – 951円 = 248円の利益を得ることができます。
つまり、このActive Spreadを正確に予測することが利益に直結します。予測がうまくいかないと、片方だけ約定しない、または、両方とも約定しないことがあります。(在庫を抱えることになります。)不利なポジションを持ったままの状態で、価格が動いてしまうと、その分損することになります。
3. マーケットの情報を取得する
3.1. マーケットから取得できるデータとは?
マーケットメイキング戦略を考えるにあったって、値動きのチャートでよくみる4本値(OHLC)の分足のようなデータでは情報が遅く、より詳細にマーケットの状態を把握できる以下の2つのデータを用いることが多いです。- 約定履歴: 全取引履歴
- 板情報: 売り注文と買い注文のスナップショット
そのため、マーケットメイキング戦略をバックテストするには、約定履歴の情報を利用するのが一般的です。
3.2. Public APIから約定履歴を取得する
GMOコインの場合は、https://api.coin.z.com/data/trades/ から全約定履歴のcsvをダウンロードすることができます。含まれている情報は、以下の4つです。
- symbol: マーケットの種類 (例: BTC)
- side: 売買種別 BUY/SELL
- size: 注文量
- price: 価格
- timestamp: 約定時刻
4. 強化学習を用いたマーケット戦略を考える
4.1. 前提
強化学習の枠組みでは、エージェントの行動が環境に対して影響を及ぼし、変化を与えるというのが一般的ですが、バックテストにおいてエージェントの注文・約定が環境に与えるマーケットインパクトを考慮するのは困難です。そのため、マーケットインパクトは考慮しない前提でモデルを考えていきます。4.2. 環境
OpenAI Gymにて独自の環境 (CustomEnv) を構築します。OpenAI Gymの環境では、以下のようなgym.Envを継承するカスタムクラスを定義します。
import gym
class CustomEnv(gym.Env):
def reset(self, seed):
# 乱数seedを用いた初期化処理を記述する
pass
def step(self, action):
# 行動(action)を受け取って変化した
# 状態(observations)と報酬(reward)を返却します
# doneは終了判定をbooleanで返却し、
# infoはパラメータの情報をdictionary型で返します
return observations, reward, done, info
def render(self):
pass
環境のイベントの分割間隔は、さまざまな方法があり、例えば- 時間ベースイベント: 1秒、1分、1時間など時間的に均等な間隔でサンプルします
- 取引量ベースイベント: 取引量の合計が一定量を超えた間隔でサンプルします
- 価格変動ベースイベント: mid priceの時間変化量が一定量を超えた間隔でサンプルします
4.3. 行動: Action
ニューラルネットベースの強化学習モデルでは、連続値の行動空間を定義することもできますが、今回は、単純化するために、離散値で行動空間を表現します。| action_id | 詳細 |
|---|---|
| 0 | Hold(何もしない) |
| 1,2,3 | Best Bid & 指値買い(小,中,大) |
| 4,5,6 | Best Ask & 指値売り(小,中,大) |
| 7,…,16 | 指値買い&指値売り(小,中,大 x 小,中,大 ) |
| 17 | 成行買い or 成行売り (在庫処分) |
4.4. 状態: State
- 保有ポジション(在庫)
- 約定履歴
保有ポジションはエージェントの行動によって変化するパラメータであり、約定履歴は外生的に与えられる行動に依存しないパラメータです。
4.3節で説明した、価格変動ベースのイベントで約定履歴を分割し、集計した結果を状態として用います。
たとえば以下のような集計を行います。
""" print(df.column) >> 'symbol', 'side', 'size', 'price', 'timestamp' """ # OHLCV open_ = df['price'].iloc[0] high = df['price'].max() low = df['price'].min() close = df['price'].iloc[-1] volume = df['size'].sum() # ask bid best_bid = df.loc[df['side'] == 'BUY']['price'].max() best_ask = df.loc[df['side'] == 'SELL']['price'].min() spread = best_bid - best_ask # midpoint midpoint = (best_bid + best_ask) / 2 # pre_midpoint represents midpoint in t-1 step change_in_midpoint = math.log(midpoint) - math.log(pre_midpoint) # quantity quantity = (df['size'] * df['price']).sum() quantity_bid = ( df.loc[df['side'] == 'BUY']['size'] * df.loc[df['side'] == 'BUY']['price'] ).sum() quantity_ask = ( df.loc[df['side'] == 'SELL']['size'] * df.loc[df['side'] == 'SELL']['price'] ).sum() # imbalance imbalance = (quantity_bid - quantity_ask) / (quantity_bid + quantity_ask)また、保有ポジションを正規化した値を状態に加えます。計算式は以下のとおりです。
# inventory_long: ロングポジション(買い在庫) # inventory_short: ショートポジション(売り在庫) # max_inventory: 許容するポジション最大値 v = (inventory_long - inventory_short) / max_inventory最後に、行動空間 (上に記載の表)をOne-Hot vectorにした値を状態に加えます。
4.5. 報酬: Reward
前回の記事で参考にしていた論文で用いられていた報酬関数を参考に、報酬関数を設計していきます。実際にバックテストを行って得られる報酬を確定報酬Rとすると、Rが取引手数料σよりも大きいかどうかで報酬関数を設計していきます。
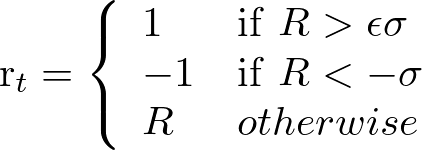
ここで、εは係数を表し、例えばε=2の場合は、2倍の手数料よりも確定報酬が大きくなった場合に、報酬を1とします。