2020.04.07
Gymトレーニングenvの作成から、DDPGとTD3によりFX取引してみる(二)
こんにちは。次世代システム研究室のC.Zです。外国人です。よろしくお願いします。
前回は強化学習の基礎手法を復習し、DDPGのFX取引実践をしました。
https://recruit.gmo.jp/engineer/jisedai/blog/rl_ddpg_fx_trading_explore/
但し、取引条件についてほぼ制限されなく、非常に非現実的なテストになりました。なので、より効率的な学習試行をし、ビジネス発想がもっと自由に適用できるよう、取引の環境を高度なカスタマイズ化する必要があります。
本文はOpenAIのgymのFX取引専用environmentの作成からを紹介します。後で、トレーニングenvを用いて、DDPGとその拡張手法であるTD3によりFX実践してみます。
1、DDPGとTD3為のGym環境
GymはOpenAIより提供し、各機械学習手法の性能などをテストするための複数環境です。
今回もstable-baselinesのフレームワークを使いますので、まず簡単の例としてstable-baselinesのDDPGドキュメントソースを挙げます。
import gym
import numpy as np
from stable_baselines.ddpg.policies import MlpPolicy
from stable_baselines.common.noise import NormalActionNoise, OrnsteinUhlenbeckActionNoise, AdaptiveParamNoiseSpec
from stable_baselines import DDPG
env = gym.make('MountainCarContinuous-v0')
# the noise objects for DDPG
n_actions = env.action_space.shape[-1]
param_noise = None
action_noise = OrnsteinUhlenbeckActionNoise(mean=np.zeros(n_actions), sigma=float(0.5) * np.ones(n_actions))
model = DDPG(MlpPolicy, env, verbose=1, param_noise=param_noise, action_noise=action_noise)
model.learn(total_timesteps=400000)
model.save("ddpg_mountain")
del model # remove to demonstrate saving and loading
model = DDPG.load("ddpg_mountain")
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
gymの使い方は簡単で、gym.makeよりテスト問題を指定し、envが一行で作られます。上記の例なら、DDPGを使って、gymの”MountainCar”のテスト問題を解決してみますね。
ここで、gymのenv構成からDDPG利用ための注意点から説明します。
①gym環境の構成
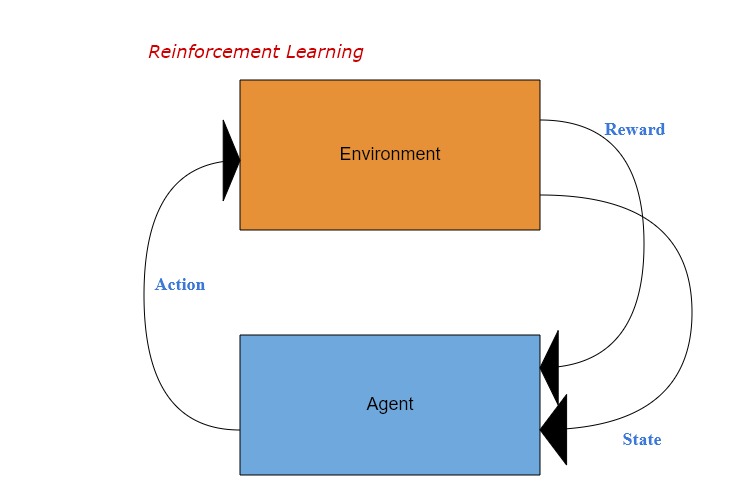
上記ループ必要な全ての機能がgymのenvに含まれます。
即ち、agentがどのような指標を見て、どのようなactionを取れ、さらにどのようなRewardを受け取るか、すべてenvironmentに定義されます。
またenvのcontinuous_mountain_carをソース例にして、クラスの構成はメインは以下のようになります。
class Continuous_MountainCarEnv(gym.Env)
...
def __init__(self, goal_velocity = 0):
...
# action_space(採用できるaction)の定義
self.action_space = spaces.Box(low=self.min_action, high=self.max_action,
shape=(1,), dtype=np.float32)
# observation_space(観察する情報)の定義
self.observation_space = spaces.Box(low=self.low_state, high=self.high_state,
dtype=np.float32)
...
self.reset()
def step(self, action):
# 一回のループを実行する
# output:次回ループ用の新observation情報、reward
...
return self.state, reward, done, {}
def reset(self):
# 環境を初期化する
...
return np.array(self.state)
def render(self, mode='human'):
# 結果を出力(ただのprintか、matplotlibのグラフなど)
...
②DDPGとTD3の注意点
前回紹介した通り、DDPGの特性として、stateが連続的だけではなく、actionも連続的なものになります。
stable-baselinesのテーブルに参照すれば、
https://github.com/hill-a/stable-baselines
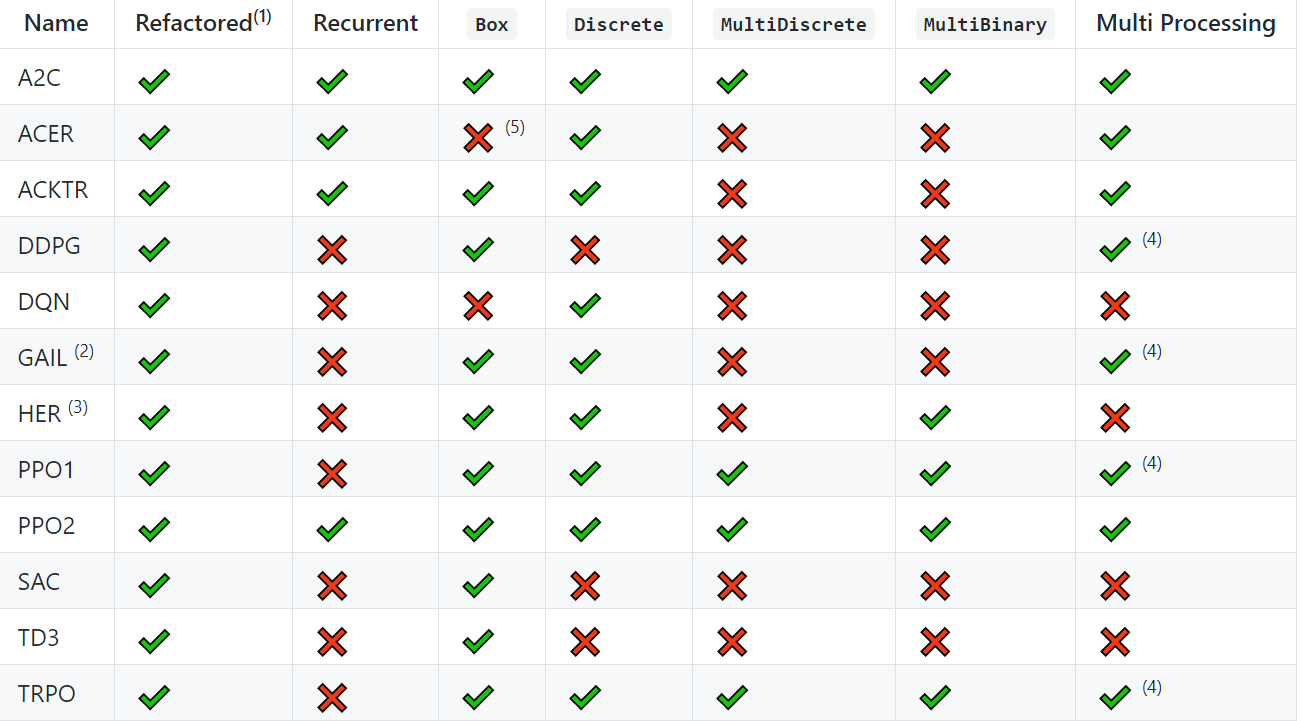
DDPGとTD3は、Discreteのactionが使えなく、Box(continuous)のactionが使えることが分かりましたね。
2、取引条件のカスタマイズ
今回は幾つの仮設観点を基づき、ソースポイント(細かいセットアップを略)を挙げながら一つトレーニングenvを作りましょう。
①action_space(採用できるaction)
・取引種類 → 売買だけ、holdという選択なし
本当に正しい判断ができれば、buyかsellかの一方が必ず利益得られるので、holdというactionを減らすより、学習の複雑性を大分減少することになれる
・「決済」を考えない → ticketではなくポジションのみをベースに収益を考える
最終目的は、一つの個別取引の利益を得るためではなく、全体かつ長期の収益性を最大化したい
・actionは「売買」+「売買Amount」の組み合わせ
買:buyのamount / agentの所有資金
売:sellのamount / agentの保有ポジション
=>
self.sell_min = -1
self.buy_max = 1
self.amount_balance_ratio_min = 0
self.amount_balance_ratio_max = 1
self.action_space = spaces.Box(low = np.array([self.sell_min, self.amount_balance_ratio_min]),
high = np.array([self.buy_max, self.amount_balance_ratio_max]),
dtype = np.float32)
②observation(観察したい情報)
一番直感的なinput指標として、今回はrateを工夫しましょう。
・spreadを考えなく、midプライスを考える
もっと長期的な収益を目指すため、スキャルピングなどの手法に適しない
・1分、10分、30分、60分それぞれのopen・close・high・lowを作る
BackWindow = 5
rate1 = np.array(df_ob.iloc[Current - BackWindow:Current])
rate10 = np.array(df_ob['close'].resample('10min').ohlc().dropna().iloc[Current - BackWindow:Current])
rate30 = np.array(df_ob['close'].resample('30min').ohlc().dropna().iloc[Current - BackWindow:Current])
rate60 = np.array(df_ob['close'].resample('60min').ohlc().dropna().iloc[Current - BackWindow:Current])
・テクニカル指標なども追加する
自力作成も難しくないですが、今回はta-libというパッケージを使いました。
https://github.com/mrjbq7/ta-lib
# EMA、SMAとAPOを使いました(指標紹介は略します)
self.ema = np.array([talib.EMA(df_ob_np["close"], timeperiod=BackWindow)])
self.sma = np.array([talib.SMA(df_ob_np["close"], timeperiod=BackWindow)])
self.apo = np.array([talib.APO(df_ob_np["close"],
fastperiod = int(BackWindow/2),
slowperiod = BackWindow,
matype = 0)])
・observation_spaceの作成
self.observation_space = spaces.Box(low = 0, high = np.inf,
shape = (4, BackWindow, 7), dtype = np.float32)
③reward
今回はbalance(所有)だけにしました。
→ balance * step_discount( step / max_step)
#短期の利益重視ではなく、長期の利益を最大化することが目的
reward = self.balance * (self.step_current / max_step)
④render(アウトプット)
profitを出力(print)します。
3、Twin Delayed DDPG(TD3)とそのFX実践
①TD3の紹介
前回紹介したDDPGアルゴリズムの基本ロジックは大体同じですが、主に二つの工夫を追加しました。
その工夫をした理由は、DDPGの主な欠点であるQ-valueの過剰評価問題を解決するためです。
では、式から見てみましょう。

・Twin
target valueはDDPGと同じ、一つしかないですが、その計算は二つのQ learning(DDPGが一つ)が使われています。
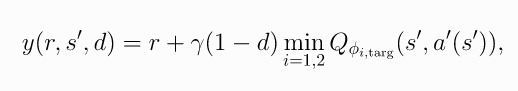
#もっと小さいQ valueが使われています。
さらに、この二つのQ valueをそれぞれのloss関数により最適化させます。
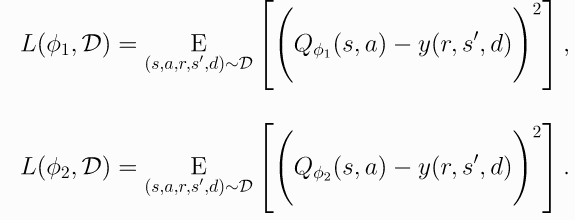
・Delayed
上記のTwinからわかるように、一回のpolicy更新には二つのQ value更新があります。
TwinとDelayedにより(もう一つの改善は、targetのactionにnoiseを追加した)、DDPGの性能が大幅に改善されるといわれています。
②カスタマイズFXトレーニング環境でDDPGとTD3より取引してみる
初期資金を10万円、3回(一日)テストの結果(profit)は以下のようになります。
DDPG: 13450、1023、-11980
TD3: 20340、1303、1201
結果の信憑性について、まだ何にも言えないところですが、TD3はとりあえずマイナスなしですね。
次のステップ
トレーニング環境の高度カスタマイズができましたため、
よい投入指標を探し、DDPGをはじめ各強化学習手法のハイチューニングにより、取引の性能向上を目指します。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD