2020.09.30
追加データゼロでできる自然言語識別 – huggingface#zero-shot-classification –
こんにちは。次世代システム研究室のT.S.です
ここ数ヶ月、NLP界隈ではGPT-3という新たな言語モデルが話題をかっさらっていきました
GPT-3とは、OpenAI社が発表した巨大な言語モデルであり、追加データがない(Zero-shot)もしくは数個(Few-shot)で様々なタスクに対応でき、かつそれぞれが高精度であるといった驚きのモデルでした
GPT-3自体は巨大かつあまりに精度が高すぎるため、学習済みモデルは現在配布されておらず、OpenAI社が提供するAPIを利用するしかありません
API自体はまだ全面開放されておらず、WaitingListも多いため、自由自在には使えない状況になっています
こんな状況の中、実はNLPライブラリのデファクトスタンダードであるhuggingfaceが識別問題に特化したZero-shot Pipelineを実装・公開しました(V3.1.0)
GPT-3のように多種多様なタスクへの対応はできませんが、Fine Tuningなしにいろいろな識別問題に対応できることは非常に魅力です
今回はそんなhuggingfaceの新機能を試した結果を共有します
モデル概要
huggingface.zero-shot-classificationではリリース直後、以下の3つのモデルが利用可能でした
- facebook/bart-large-mnli
- 通常
- joeddav/bart-large-mnli-yahoo-answers
- yahoo-answersを追加したモデル。Topic分類はこちらを利用する方がよいと論文ないにあり
- joeddav/xlm-roberta-large-xnli
- 多言語モデル。アジア圏だと中国語、タイ語、ベトナム語、ウルドゥー語などあるが日本語は対応外
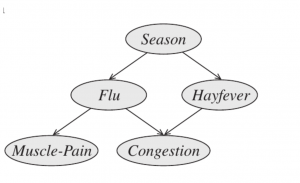
感の鋭い方はモデル名の[mnli]という名称を見て、このモデルがどういったことをしているのかなんとなく想像がつく方もいるかと思います
MNLI自体は「含意/矛盾/中立」を予測するタスクであり、このモデル自体は対象テキストが「含意」しているがどうかを判断に学習しています
概要は以下のようなイメージです。
対象文章に、hypothesisという文章をConcatします。これは「it is related with {}」といった文章で対象文書が{}に関連しているどうか問う文言になっています
このConcatした文章が「含意(entailment)」か、そうでないかを判断するよう学習しているモデルのようです
これによって従来の0,1…といった無意味なラベルに対する識別ではなく、意味を学習するため様々なタスクに対応できるといった仕組みとなります

コーディング例
コーディングも非常に簡潔実施できるようになっています
まずはclasiffierを宣言します
CPU/GPUで引数が変わるので注意ください
#CPUの場合は末尾のdeviceを削除する
classifier = pipeline("zero-shot-classification", model='facebook/bart-large-mnli', device=0)
その次に識別したいテキストを用意します
classifierにはListで対象を一括で渡せるようになっています
#dfから変換
sequence = df.text.to_list()
#List作成
sequence = [
"Darth Vader",
"Mr.Spock",
"May the Force be with you"
]
これで事前データ作成は完了したので、ここから識別のためのパラメータを用意します
必須は識別ラベルです。識別したい名称を作成します
candidate_labels = ["Star Wars", "Star Trek"]
また必要であればhypothesisを設定することも可能です。
(基本はデフォルトで問題ないかとおもいます)
# 必要に応じて
hypothesis_template = "The sentiment of this review is {}."
さあこれまでで事前準備は完了しましたので、実行するだけです
実行も非常に簡潔ですね
# hypothesisを設定しない場合は該当変数削除 classifier(sequences, candidate_labels, hypothesis_template=hypothesis_template)
結果は以下の通り、List[dict]で返されます
該当ラベルで学習していないにも関わらず、人間の感覚と同じものを返していることがわかるかと思います
一つ注意しなくてはいけない点として、labelsの順が確率が高い順に並んでいることですね
与えたラベル順ではないのでお気をつけください
[{'labels': ['Star Wars', 'Star Trek'],
'scores': [0.9714018702507019, 0.028598114848136902],
'sequence': 'Darth Vader'},
{'labels': ['Star Trek', 'Star Wars'],
'scores': [0.9821363091468811, 0.017863718792796135],
'sequence': 'Mr.Spock'},
{'labels': ['Star Wars', 'Star Trek'],
'scores': [0.7835115194320679, 0.21648848056793213],
'sequence': 'May the Force be with you'}]
また多言語モデルを使えば、他の言語も同様にZero-shotで判定できます
classifier = pipeline("zero-shot-classification", model='joeddav/xlm-roberta-large-xnli', device=0)
# 1行目は→をフランス語に翻訳: "I hated this movie. The acting sucked.",
# 2行目は→をベトナム語に翻訳: "This movie didn't quite live up to my high expectations, but overall I still really enjoyed it."
# 3行目は→を中国語(簡体)に翻訳: "This movie didn't quite live up to my high expectations, but overall I still really enjoyed it."
sequence = [
"Je détestais ce film. Le jeu des acteurs était nul.",
"Bộ phim này không hoàn toàn đáp ứng được kỳ vọng cao của tôi, nhưng nhìn chung tôi vẫn thực sự thích nó.",
"我喜欢"
]
# ラベルは英語でOK
candidate_labels = ["positve", "negative"]
classifier(sequence, candidate_labels)
結果:
[{'labels': ['negative', 'positve'],
'scores': [0.995663046836853, 0.004336906131356955],
'sequence': 'Je détestais ce film. Le jeu des acteurs était nul.'},
{'labels': ['positve', 'negative'],
'scores': [0.984123706817627, 0.015876272693276405],
'sequence': 'Bộ phim này không hoàn toàn đáp ứng được kỳ vọng cao của tôi, nhưng nhìn chung tôi vẫn thực sự thích nó.'},
{'labels': ['positve', 'negative'],
'scores': [0.9862578511238098, 0.013742138631641865],
'sequence': '我喜欢'}]
多言語になっても結果は問題なさそうです
非英語圏などへの展開の場合、そもそもの教師データをあつめるのに苦労することが多いですが、こういった仕組みを利用すればその手間が著しく低減できそうなことがわかります
(日本語への対応が期待されます、、、)
精度確認
サンプルデータではうまくいくことを実データではどうなんでしょうか?
そこでとある実データを利用して精度を算出してみました。
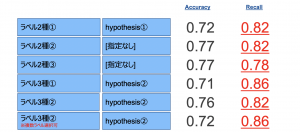
以下に複数ラベル、hypothesisで検証し、そのAccuracy(正解データ数/全データ数)とrecall(ラベルが1のデータのうち、正しく1と予測された数)を記します
いろいろなパラメータを比較したのですが、概ね高い精度が得られています
もちろん特化したデータでFine Tuningしたモデルには敵わないでしょうが、学習時間やコーディング時間が圧倒的に短くなる利点を考えれば十分なものであると考えられます
「早期リリースしたい!」なんて時には一番最初に試すべきものだと言っても過言ではないのかなと感じています
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD