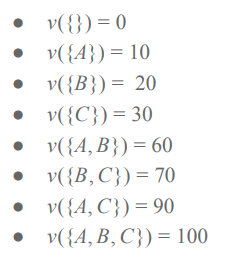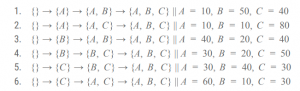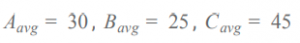皆さんはじめまして。次世代システム研究室 新卒のY.Sです。初ブログです、よろしくお願いします。
最近、業務で初めてGoogle Cloud Platform (GCP)に触れました。コマンド数行でサービスをデプロイしたり、コンソール上でログを確認したりできるのは便利ですね。
GCPといえば、今年7月にGoogle CloudがAI Explanations(ベータ版)をリリースしました。AI PlatformにデプロイされているAIモデルで予測を行った際に、入力特徴の各々がどの程度予測に貢献したのか(attribution)を計算・可視化できます。いわゆるExplainable AI (XAI)ですね。colaboratoryやAI Platform Notebooksにチュートリアルがあるので、気軽に試すことができます。
今回はExplainable AIに入門するにあたって、Googleの
AI Explanations Whitepaperを読みましたので、その内容をご紹介します。特徴の貢献度 (attribution score)の算出方法、AI Platform上でattributionを可視化する例、attributionに基づいてモデルの学習を評価する際に気をつけること等が書かれています。
Explanable AIは、どちらかといえば意思決定等のビジネス文脈で語られることが多いかと思いますが、今回はAIモデル作成者の立場から、XAIを現場でどのように活用できるかを考えてみました。
TL;DR
- AI Explainは、AI Platformにデプロイされているモデルを変更することなく、特徴の予測に対する貢献度を算出できる。さらにWhat-If toolを使うことで可視化も可能。特に難しい追加コードも無し。お手軽で非常に便利。
- explainabe AIについての知識のある人同士で運用・議論しないと、誤った洞察・考察になってしまう。 (モデルが学習したパターンのうち、attributionでは拾いきれないものもある。一概に「attribution scoreが低い = その特徴は必要ない」と判断するのはキケン。そもそもモデルが学習しきれていないだけの場合もあったり。。)
-
現場で使うときは、モデルが正しい予測をしたサンプルに適用して、モデルの学習を解釈する手段として使えそう! (人間の直感に沿った学習をしているか、leakageが起きていないか等)
- 現行のモデルがAI Platform & tensorflowで動いているなら、使ってみるのも手。そうでないならば、わざわざ移植するのはコスパ悪そう。
導入
最初に、Explainable AIの文脈における「説明」とは何かや、用語の紹介を行います。あまり固い感じにしたくはないのですが、これを書かずに進めるのはキツイので、少々お付き合いください。
Explainable AIでは、ある事象Pが起こった説明を求めるといった時に、「なぜ事象Pが起こったのか」ではなく、「なぜ他の事象Qではなくて、事象Pが起こったのか」を考えます。この時、実際に起こった事象Pをfact、他に起こり得た事象Qをfoilと呼びます。
foilは複数考えられ、各foil毎に妥当な説明も変わります。White Paperの例を挙げると、“Why did Gray smash his plate?” (なぜGrayは皿を割ったのか?)という問いには、“Gray doesn’t smash his plate”を表現するfoilがいくつか考えられます。
“He leaved his plate in one piece”というfoilに対しては、“Because he was upset” (彼は焦っていたので、皿を無傷にしておかず、割ってしまった)という説明が妥当でしょうし、“He smashed his glass instead.”というfoilに対しては、“Because he was at a Greek wedding rather than Jewish one.” (彼はユダヤ式ではなくギリシャ式の結婚式に出席していたので、グラスではなく、皿を割った)という説明が妥当でしょう。(ユダヤ式の結婚式ではグラスを、ギリシャ式の結婚式では皿を割る文化があるらしいです)
人は予想外の結果が得られた時に、得られた結果をfact、予想していた結果をfoilとして、説明を求めます。例えば、クレジットをスコアリングするアプリケーションでは、”perfect credit”が理想のfoilに選ばれ、そうならなかった説明として「クレジット履歴が短い」や「未払いのクレジットが多い」等が挙げられることでしょう。
このように、説明を求めるときは、期待していた出力に沿った適切なfoilを設定し、そうならなかった理由を探索します。
Shapely value
Shapely valueは、各特徴がどの程度出力に貢献したかを算出する手法です。
Shapely valueの考え方を理解する例として、3人の従業員{A,B,C}を雇っていて利益v(N)を上げている会社が、各従業員の貢献度に基づいて給料を支払うような場合を考えます。Shapely valueでは、全ての雇い方のパターンにおいて、各従業員を雇うことで向上する利益と、誰も雇わなかった場合の利益とを比べます。
各従業員セットNを雇った場合の利益は以下の通りです。Aだけを雇った場合は利益10、AとBを雇った場合は利益60といった具合になります。
誰も雇わなかった場合の利益は0で、これをfoilとします。
各従業員は、雇ったときの状況によって上昇する利益が異なります。例えば、誰も雇っていない状況でAを雇った時と、Bが雇われている状況でAを雇った時とでは、前者の上昇分は10, 後者は20です。
そのため、全てのパターンについて、各従業員を雇った時にどの程度利益が向上するのかを計算します。
各従業員の最終的なShapely valueは、それぞれの状況で算出された上昇値の平均値とします。この値が大きい従業員ほど、雇った時の利益向上が大きいといえます。
AIモデルでは、利益v(X)をモデルのアウトプット、従業員の雇い方Xを入力特徴として、各入力が出力にどの程度貢献したかのattribution scoreを上記のような方法で求めます。
ただし、shapely valueの計算量は特徴の数に関して指数的に増大するため、基本的には近似的手法(attribution method)を用いて、より少ない計算量で求めます。attribution methodはいくつか提案されています。微分可能なモデルに適用できるもの、微分不可能なモデルにも適用できるもの、画像に特化したもの等、様々な特性があるので、適用する状況に合わせて手法を選択する必要があります。
また、attribution methodsは単一インスタンスのattribution scoreを算出する手法ですが、インスタンス全体に渡ってscoreを集計することで、よりモデル全般に対するインサイトを得ることが可能です。
Baseline
上の例ではfoilとして、従業員を誰も雇わない状況{}とその時の利益0を選択しました。この選択は、「各従業員によって、どの程度利益が上昇するか?」という問いを反映しています。
一方で、「Aが既に雇われているとき、BとCをそれぞれ雇うことで、どの程度利益が上昇するか?」という問いには、Aを雇っている状況{A}と、その時の利益10がfoilとなります。
このように、foilによって結果が変わるため、問いに対して適切なfoilを選択する必要があります。
実際にAIモデルの予測に対して説明を求めるときは、前述したように、「なぜ他の結果ではなく、この予測結果なのか」といった問を立てます。
この、(実際には起こっていない)“他の結果”というものを反映するように、数あるfoilの中から具体的にひとつを選択する必要があります。この選ばれたfoilをbaselineと呼び、baselineに対するモデルの予測をbaseline scoreと呼びます。baselineの選択は、attributionに大きな影響を与えるため、慎重に行います。
baselineの選び方として、uninformative baselineとinformative baselineがあります。
uninformative baselineは、画像入力における黒・白・ランダム画像、テキスト入力におけるストップワード・セパレートトークン、数値入力における中央値、カテゴリカル入力における最頻値など、特筆する意味を持たないものです。単純にある予測に貢献した特徴を探索する場合はこちらを用います。
informative baselineは、明確な比較対象がある場合に用います。例えば「why did my credit score drop 50 points since last month?」のような問いに対し、先月との差を引き起こした特徴はどれかを探索するような場合に、先月のアカウント情報をinformative baselineとして用います。
実際に使ってみる例
(この章では使い方や動作の説明は行いません。その辺りの理解は、
チュートリアルをポチポチやるのが一番手っ取り早いので是非!AI Platformにモデルのデプロイを行ったことがない方でも、1~2時間あれば完了できる内容です。)
AI Explanationでは説明を得るために、ユーザーがモデルを変更したり、追加のコードを書いたりする必要はありません。
モデルと同じディレクトリにexplanation_metadata.jsonというjsonファイルを配置し、attributionを作成する入力テンソル、出力テンソル、ベースラインを指定すれば、説明を得ることができます。
Google AIのPAIRチームが開発したWhat-If toolを用いて、得られたattributionを可視化できます。
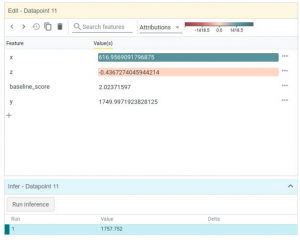
下記の図では、x,zの二つの変数からyを予測する回帰モデルをテストしたときの、とあるインスタンスに関するattributionを可視化しています。このインスタンスに関しては、xの値が予測に大きく貢献したことがわかります。
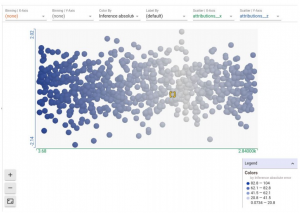
また下記の図は、各インスタンスのxのattribution scoreとzのattribution scoreをプロットしたものです。x軸がxのscore、y軸がzのscoreです。色の濃さは予測誤差の大きさを示します。この図を見ると、誤差の比較的小さいインスタンスは、xのattribution scoreがある範囲に収まっていることがわかります。このことから、zは予測に貢献してもしなくても、精度には影響が少ないと考えられます。
入力が画像であれば、予測に貢献した部分をハイライトして表示してくれたりもします。
attributionを扱う上で念頭においておくこと
attribution methodはモデルの予測を解釈するための手法ですが、attribution scoreが低いからといってその特徴は予測に貢献しないと一概に決められない場合があります。また、学習された表現によってはattributionに現れず、混乱を招く場合があります。
attribution scoreに基づいてモデルの学習や予測を評価する場合は、人の直感と異なる場合があることや、attribution methodの特性上の限界があることを把握しておく必要があります。
- attributionは、モデルが学習したデータのパターンを反映しているに過ぎません。attributionによって何かがおかしい(直感とズレる)と分かったときに、モデルに問題があるのか、データに問題があるのかの切り分けが別途必要です。
-
attribution scoreが低いからといって、必ずしもその特徴と結果の間にパターンや関係がないとは言えません。モデルが関係を学習できていないだけの可能性があります。
-
前述の通り、attribution scoreはベースラインに完全に依存してるため、議論するときは常に選択したbaselineを念頭に置く必要があります。
- モデルが学習した表現が、attribution scoreに現れない場合があります。
-
attribution methodによって近似的に算出しているとはいえ、attribution scoreの算出は予測に比べて計算コストが高いです。各attribution methodはパラメータによって、計算量と近似精度のトレードオフを調節する必要があります。
気をつけること、たくさんありますね。。。
attributionでできること・できないことをきちんと把握して評価しないと、「誤った洞察に基づいて突き進む」みたいなことになるのは恐ろしいですね。
モデル開発の現場でXAIをどう活かすか
開発サイクルに組み込みのはムズカシイ??
モデル作成・評価の現場では、予想に反する予測の原因を特定し、モデルやデータセットの改善に繋げたいというニーズが大きいです。結論から言うと、そのようなプロセスに組み込むにはXAIは不安定な要素が多く、気軽に取り入れられそうではないという印象です。問題がよりややこしくなってしまう場合は、無理に組み込むものではないと思います。
第一に、attributionから間違えたサンプルに関する特徴の貢献具合が分かったとして、モデルの表現力が足りていないのか、学習方法がマズかったのか、データが偏っているのかの判断には直接結びつきません。
また、attributionはbaselineや近似手法のパラメータに非常にsensitiveなため、得られたattributionをどの程度信用するかの判断も必要になります。評価者の直感に反するattributionが得られた場合、直感を信じるべきか、attributionの数値を信じるべきかといった判断も、悩ましいポイントです。
さらに、前述したとおりモデルの学習がattributionに現れてこないケースがあります。
モデルの学習を把握するのには使えそう
一方で、ある程度精度の出るモデルが完成した後で、モデルが何を学習したのかをきちんと把握しておくために、XAIを活用するのはアリだと思います。
例えば下記は、attributionを確認することによってleakageを発見した例です。レントゲン写真から胸部の病気の有無を判断するモデルですが、attributionでは胸部の情報は識別に貢献していないと示しています。実はこのモデルは、医者によるペンマークの有無を判別基準として学習していて、胸部の特徴は全く無視していました。当然、このモデルをペンマークの無い実データに適用した場合、病気を正しく識別することはできません。
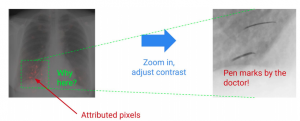
また、attribution scoreが特徴全体を通してフラットである場合、「モデルは特徴の相互作用や全体の傾向を学んでいる可能性がある」という仮説を立てることができます。(前述のXORやtextureの例)
もちろん、精度が出ているモデルで、attributionもこちらの直感や意図に合致している場合は、確信を持ってモデルを運用していけます!
まとめと感想
今回はモデルを作る立場から、Explainable AIを開発・運用の現場で活用できないかという内容の記事でした。
結論としては、モデルの改善サイクルに積極的に組み込むよりは、モデルが期待通りに表現を学習しているかの確認程度に使うのが無理のない使い方だと思います。
現状既にAI Platformでモデルを運用しているような場合には、AI Explainを使ってattributionを確認してみるのもアリではないでしょうか。そうでなければ、わざわざこのためにAI Platformに移行するのは、コスパが悪いなという印象です。
Explainable AIの基本となるattribution score算出の考え方はとてもシンプルなのですが、その数値を正しい洞察・判断に結びつけるためには、多くのことを理解し、注意深く評価する必要があります。正直、white paperを読んでいるだけで頭がパンクしそうでした。こういうことを、実装 -> 評価 -> deploy判断のサイクルに組み込んで実践されている方々は凄いなと素直に感じました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。