2018.04.11
機械学習におけるConcept-Driftの対策または検知について
こんにちは、次世代システム研究室のA.Zです。今回はConcept-Driftについて紹介したいと思います。
背景
多くの機械学習の予測モデルは、インプットデータとアウトプットデータに「隠れた因果関係」があると想定されます。その関係は以下のように表わされます。
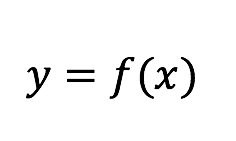
しかし、実際には、この関係は時間と外部の影響により変化していくケースが多く、その結果、構築した予測モデルの精度は時間とともに劣化することになります。
特に金融系のデータはその関係の変化が激しく、モデルの性能の劣化も早くなります。劣化したモデルを利用すると、損失のリスクも高くなるので、利用しているモデルが劣化したかどうかの指標または判断基準が必要になります。
機械学習分野において、この問題はConcept-Driftと呼ばれます。今回は、対策と検知手法を紹介したいと思います。
Concept-Driftとは
Concept-Driftとは、アウトプットデータとインプットデータの関係が、時間や外部影響によって変化することです。
Concept-Driftの対策と検知において最も難しい課題は、真のConcept-DriftとNoiseを区別することです。あるアルゴリズムはNoiseに対する反応が敏感すぎ、NoiseはConcept-Driftとして誤解されます。また、あるアルゴリズムはNoise検知の性能は良いのですが、concept-driftの検知は遅くなります。
良いアルゴリズムには、Noise検知性能の正しさ(ロブスト)とConcept-Drift検知性能の素早さのバランスが必要です。
さらに、Concept-Drift自体は、繰り返し起こることが多いため、この繰り返しのパターンを素早く検知できることが重要となってきます。
従って、理想的なConcept-Driftの対策・検知アルゴリズムは以下の条件を満たす必要があります。
- 素早くConcept-Driftを検知し、変化に対応させること
- 正しくNoiseとConcept-Driftを区別できること
- 繰り返すConcept-Driftに対応できること
Concept-Driftの対策
一般的なConcept-Driftの対策は、4つがあります。
1. Forgetting
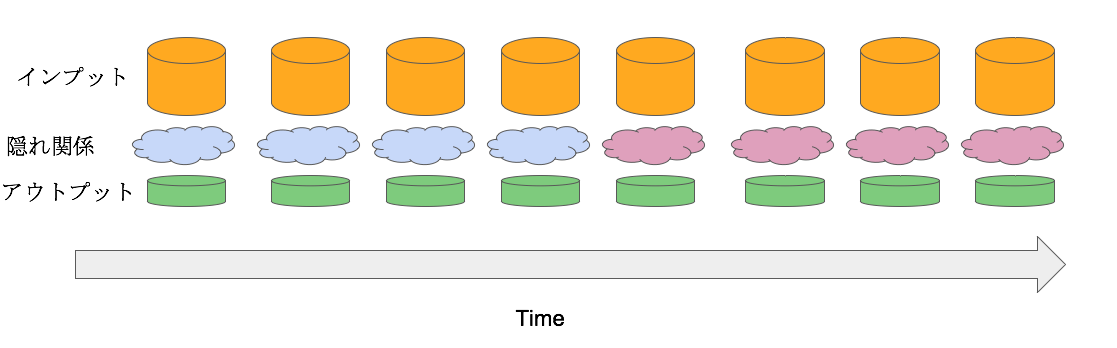
Forgettingは、利用しているモデルを定期的に学習させる対策方法です。その学習で利用するhistorical dataは、その都度スライドさせていきます。
その結果、変化は徐々にモデルに反映していくことになります。イメージは以下の図になります。
2. Detectors
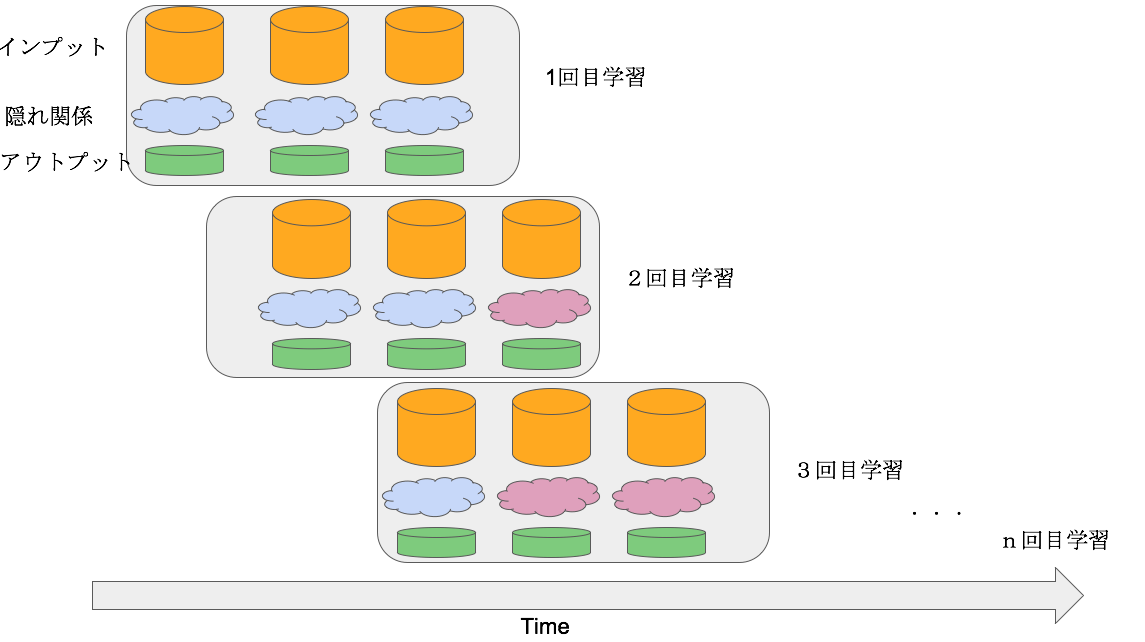
Detectorsは、Concept Driftの発生したタイミングを検知し、その後、モデルの再学習を行います。再学習を行うとき、Driftした前のデータを完全に捨てます。
具体的には以下の図になります。

3. Dynamic Ensemble
Dynamic ensemble手法は、利用するモデル構造自体は複数モデルのensembleから作られ、時間とともに、各モデルを評価し、重み付けをします。アウトプットが正しく予測されるモデルはリワードとして重みを増やします。一方、間違って予測されたモデルはペナルティとして、重みを減らします。具体的に、以下の図になります。
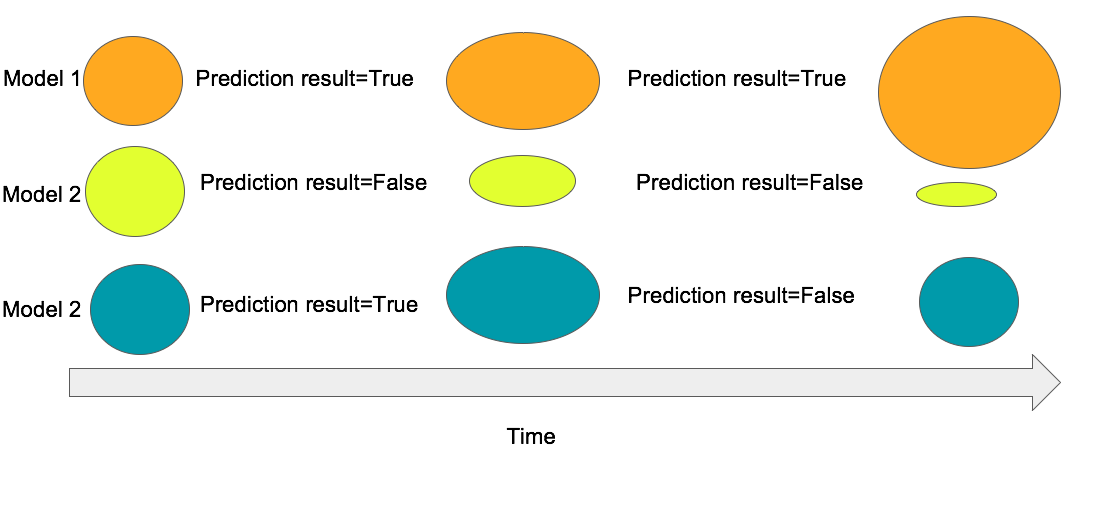
※ 以上の図に、モデルの大きいさはensemble中の重みを表します。
4. Contextual
Contextual手法は、いくつかの隠れた因果関係のパターンに対する複数モデルを作成し、予測するデータがインプットされた場合に、どのモデルを利用するかを判断する。基本的に、各隠れ因果関係のパターンは様々な統計情報で表します。具体的には以下の図の通りです。
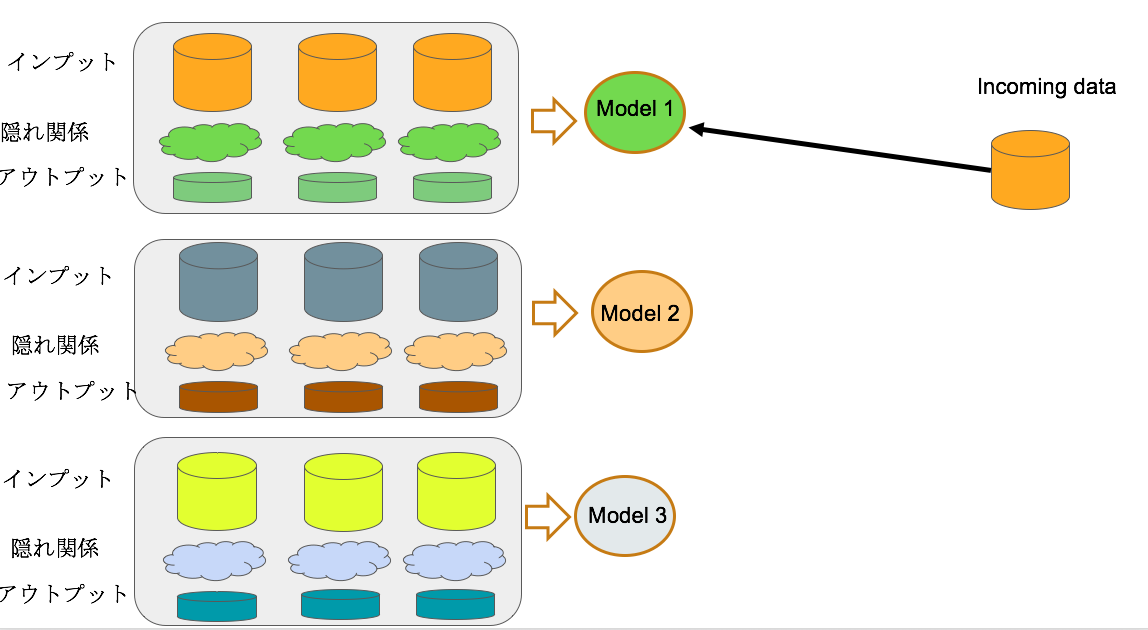
以上の対策の中でどれが最も適切かは場面によって異なります。以下はいくつかの視点から
Model Classifierの数の視点
- single classifier: Forgetting, Detectors
- ensemble : Contextual, Dynamic Ensemble
Concept-Driftに合わせ方の視点
- ゆっくり変化する : Forgetting, Dynamic Ensemble
- すぐに変化する : Detectors, Contextual
Concept-Driftの速さの視点
- 突然のConcept-Drift : Forgetting, Detectors
- 徐々に起こるConcept-Drift : Dynamic Ensemble
- 繰り返すConcept-Drift : Contextual
Concept-Driftの検知について
以上の4つの対策方法中から最も取り入れやすいのは、Detectorの手法です。理由は以下の通りです。
- 現在利用しているモデルや仕組みの変更が不要
- モデルの選択肢が自由
- NoiseがTrainingデータに入りにくい
こちらの対策手法を利用するために、良いの検知アルゴリズムが必要です。
今回はいくつかのConcept-Driftの検知アルゴリズムの性能を簡単に実験してみました。
実験の環境は以下の通りです。
- Python 3.6
- Data stream mining framework with Concept-Drift detection algorithm
https://github.com/alipsgh/tornado - Dataset
以上のframeworkに用意されているデータ(data_streams/sine1_w_50_n_0.1/sine1_w_50_n_0.1_101.arff)。こちらデータセットは基本的にy=sin(x)関数とrandom noiseで生成されます。
今回試したアルゴリズムは以下です。
- FHDDM (Fast Hoeffding Drift Detection Method)
- FHDDMS (Stacking Fast Hoeffding Drift Detection Method)
- CUSUM (Cumulative Sum Method)
- PH (Page Hinkley)
- DDM (Drift Detection Method)
- EDDM (Early Drift Detection Method)
- ADWIN (ADaptive WINdowing)
- SeqDrift2
- HDDM_A_test (Hoeffding’s Bound based Drift Detection Method With A test scheme)
- HDDM_W_test (Hoeffding’s Bound based Drift Detection Method With W test scheme)
まずは、Naive Bayesモデルを利用し、「Concept-Drift検知あり(以上のアルゴリズム)」と「Concept-Drift検知なし」の実験を行ってみました。その結果が以下の図となります。
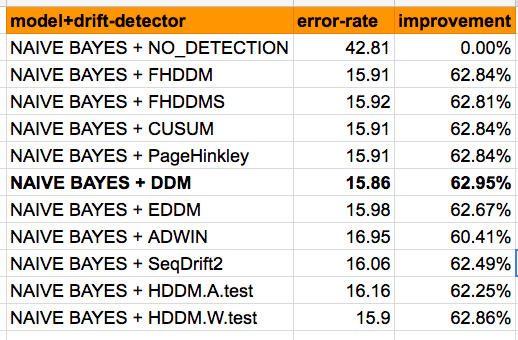
Concept-Drift検知のアルゴリズムを利用しない場合、エラーレートはかなり高くなります(43%)。他方、Concept-Drift検知を利用した場合、エラーレートは約15%-16%まで減らすことができました。検知アルゴリズムの中では、DDMが最も良い結果を示しました。
別のモデルを利用した場合、改善率と最適なアルゴリズムがどう変化するか、Perceptron Modelを利用し、同じ実験を行いました。その結果が以下の図になります。
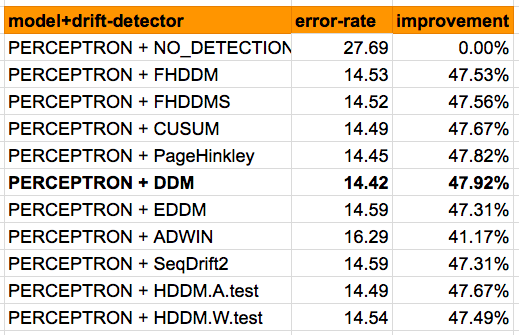
Concept-Drift検知なしの場合、エラーレートは約28%です。検知なしNaive bayesモデルに比べてかなり改善されました。
さらに、Concept-Driftのアルゴリズムの検知を加えると、エラーレートは約14%-16%まで減らすことができました。この場合の最適な検知アルゴリズムの結果も、DDMが最も良い数値を示しました。
以上の実験から得られた結論は以下の通りです。
- Concept-Drift検知アルゴリズム利用した場合、エラーレートは約14%-16%まで減少した。
- 検証したConcept-Drift検知アルゴリズムの中から、DDMが最も良い数値を示した。
しかし、利用するデータとモデルによって、以上の結論は変わる可能性があります。
また、各アルゴリズムの性能(実行時間、必要なメモリなど)も考慮したほうが良いではないかと思います。
まとめ
- 一般的ななConcept-Driftの対策を紹介しました。
- Concept-Driftの対策を行うことで、隠れた関係の変化に対するエラーレートは改善されることを確認できました。
最後に
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD