2017.01.18
転移学習(Transfer Learning)を用いた、効率的なモデル作成
こんにちは、次世代システム研究室のA.Zです。今回はtransfer learning(転移学習)について紹介したいと思います。
背景
機械学習アルゴリズムは基本的に、学習したデーターと同じドメインかつ同じ分布のデーターをしか対応できません。
データードメインと分布は時間と共に、変化していくケースもあります。
こちらの変化を対応する為に、新しいモデルが必要になります。
しかし、新しいモデルの作成するときに、以下の問題があります。
- もしデーター量が大きかったら、学習時間とコストが高くなります。
- データードメインの変化スピードが早い場合は、新規モデルの学習時間が追いつくことができません。
- 新しいデータードメインでは、labelデーター少ないまたはlabel データーがありません。label dataを作成するのはコストが高いです。
以上の問題を解決する為に、機械学習分野のなかで、transfer learning(転移学習)という子分野があります。
転移学習は既存のモデルを利用し、新規モデルの学習はもっと効率化するには一つの目的です。
転移学習(Transfer Learning)とは
転移学習(Transfer Learning)は既存のモデルから、知識を新しいモデルに転移するプロセスです。つまり、新しいモデルを学習する時に、学習済みのモデルの知識や特徴を再利用することです。
こちらの方法を適用するにより、新しいモデルの学習時間と精度は0から学習するより、改善できます。
転移学習により、新規モデルの改善は以下のポイントで評価されます。
- jump start:新規モデルの初期performanceが改善できること
- asymptotic performance:最終のperformanceが転移学習なしより、改善できること
- 学習時間:転移学習なしの時間より、学習時間が改善できること
成功した転移学習の時に、performance graphは以下のようになります。
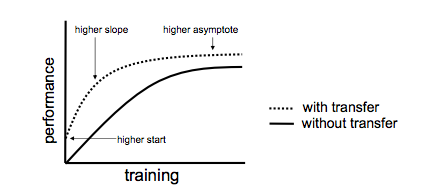
転移学習は失敗するときもあります。こちらのケースはnegative transferと呼ばれます。transfer learning分野でははpositive transferを最大化しながら、negative transferを最小化することは一つ大きなチャレンジです。
基本的に、転移学習は利用する機械学習アルゴリズムに依存します。一般的な方法は存在しませんが、
既存のモデルから、新しいモデルに転移するものにより、転移学習は以下の種類に分類することができます
- instance transfer
既存モデルのドメインデーターと新規モデルのドメインデーターがoverlappingする部分がたくさんある時に利用されます。こちらはアップローチは基本的にoverlappingする部分のerror penaltyみを低くし、overlappingではない部分のpenaltiを高くする。期待される結果としては新規ドメインのデーターにも高いpredictive精度が得られます。
- Parameter transfer
既存モデルのドメインデーターと新規モデルのドメインデーターが同じ事前分布または共通パラメータ持っている時に利用されます。例えば新規モデルを学習する時に、初期値がrandomで設定するより、既存モデルのパラメータを利用し、初期値として設定します。
- feature transfer
既存モデルのドメインデーターと新規モデルのドメインデーターが共通featureを持っている時に利用されます。このアップローチは最適化の共通featureを見つけ出し、既存ドメインデーターと新規ドメインデーターの差を最小化します。
- relational knowledge transfer
既存モデルのドメインデーターと新規モデルのドメインデーターが概念または特徴のマッピングを作成します。新規ドメインのデーターを既存のドメインデーターにマッピングした後、そのまま既存のモデルを利用することができます。
以上のアップローチから、今回はfeature transferのアップローチを利用し、deep neural network の転移学習を実験してみます。
転移学習の実験
今回の実験目的:
- 学習済みの画像認識モデルを利用し、新規タスク用のモデルを作成すること
- 新規タスク用のモデルの精度の確認すること
- 少ない学習データーで、新規タスクモデルの精度を確認すること
実験環境:
- python 3.5
- keras module with tensorflow backend
- keras pre-trained-model
https://github.com/fchollet/deep-learning-models
実験データー:
今回利用したデーターはkaggleのdogs-vs-catsのデーターです。
Training dataの概要:
各カテゴリに100件の画像を利用します。
Testデーターの概要:
各カテゴリに20件の画像を利用します
実験概要:
今回の実験内容は学習済みのモデルを利用し、新たな画像分類タスクのモデル作成し、精度の評価を行います。
今回利用した学習済みモデルは学習済みのモデルはimagenetのinception_v3(CNN)のモデルです。
このモデルは一番最後の層だけを削除し、featureの抽出器として利用します。
そして、そのモデルの上にさらに新しいタスク用の分類器層を追加します。
今回使っているコードは以下です。
np.random.seed(1337)
# dimensions of our images.
img_width, img_height = 150, 150
train_data_dir = 'data/train'
validation_data_dir = 'data/validation'
nb_train_samples = 200
nb_validation_samples = 40
nb_epoch = 10
def save_features_data():
# image net model load. include_top=FALSEの場合は、一番最後の層だけを取り除く
model = InceptionV3(weights='imagenet',include_top=False)
datagen = ImageDataGenerator(rescale=1./255)
generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=32,
class_mode=None,
shuffle=False)
features_train = model.predict_generator(generator, nb_train_samples)
np.save(open('features_train.npy', 'wb'), features_train)
generator = datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=32,
class_mode=None,
shuffle=False)
features_validation = model.predict_generator(generator, nb_validation_samples)
np.save(open('features_validation.npy', 'wb'), features_validation)
def train_top_model():
features_train=np.load(open('features_train.npy','rb'))
train_labels = np.array([0] * int(nb_train_samples / 2) + [1] * int(nb_train_samples / 2))
features_validation = np.load(open('features_validation.npy','rb'))
validation_labels = np.array([0] * int(nb_validation_samples / 2) + [1] * int(nb_validation_samples / 2))
top_model = Sequential()
top_model.add(Flatten(input_shape=features_validation.shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
top_model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
top_model.fit(features_train, train_labels,
nb_epoch=nb_epoch, batch_size=32,
validation_data=(features_validation, validation_labels))
save_features_data()
train_top_model()
実験結果:
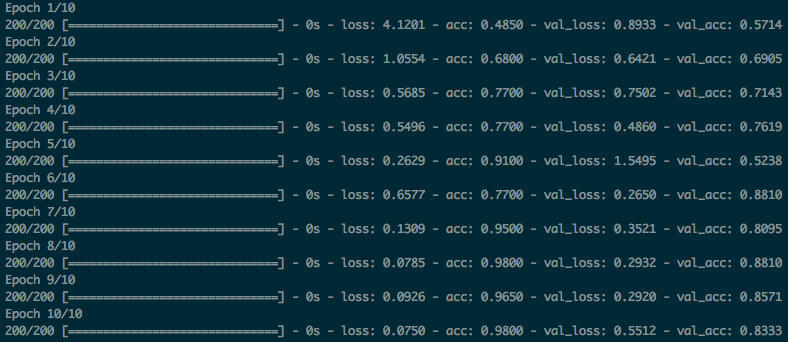
実験結果から見ると、精度が98%まで達成でき、inception_v3のimagenetモデルから新規モデルにtransfer learningがうまくできました。
こちらはimagenetでも、猫と犬のカテゴリも学習し、新規モデルを学習する時に、既存モデルで抽出したfeatureを利用し、少ないデーターで、短い学習期間で、良い精度モデルを作成することできました。
まとめ
- 転移学習で、学習済みモデルを利用し、新規タスク用のモデルが短縮で、良い精度で作成することができました。
- 転移学習を利用することで、少ない学習データーを利用しても、良い精度が達成できました。そして、正解データーの作成コストも削減することができると思います。
最後に
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD