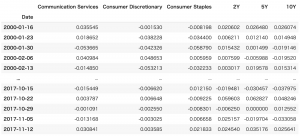
2021.12.27
知識グラフの紹介:CausalNexで因果推論を試してみたい
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
前回(2021Q3)のブログでは「クッキーレス(cookieless)時代のインターネット広告に向き合いたい:固有表現抽出と知識グラフ編」で固有表現抽出(Named Entity Recognition; NER)と知識グラフ(Knowledge Graph)の周りを紹介し、知識グラフに基づいて、クリック予測のためのクリックされたエンティティの関連性について少しヒントをもらった気がします。そこで、知識グラフで、単語の因果知識はどこまで使えるのか、具体的にどうやって実装するか、を調べたくなりました。
というわけで、今回(2021Q4)は知識グラフをおさらいし、その中にある因果分析の技術を試してみたいと思います。最終的には、自然言語処理の因果分析までを試したいですが、今回は理論や簡単な例の実装までを紹介し、クリック予測については、アイデアベースとして書かせていただきます。
1. 知識グラフ(Knowledge Graph)のおさらい
知識グラフ(Knowledge Graph)は様々な知識をグラフにまとめて可視化するものです。前回のブログでは軽く説明しましたが、今回は詳細を解説します。主に、この論文を引用し、重要なポイントをまとめました。
知識グラフは主な四つのカテゴリー(下記の図)に分けられ、1. Knowledge Representation Learning, 2. Knowledge Acquisition, 3. Temporal Knowledge Graph, 4. Knowledge Aware Application です。
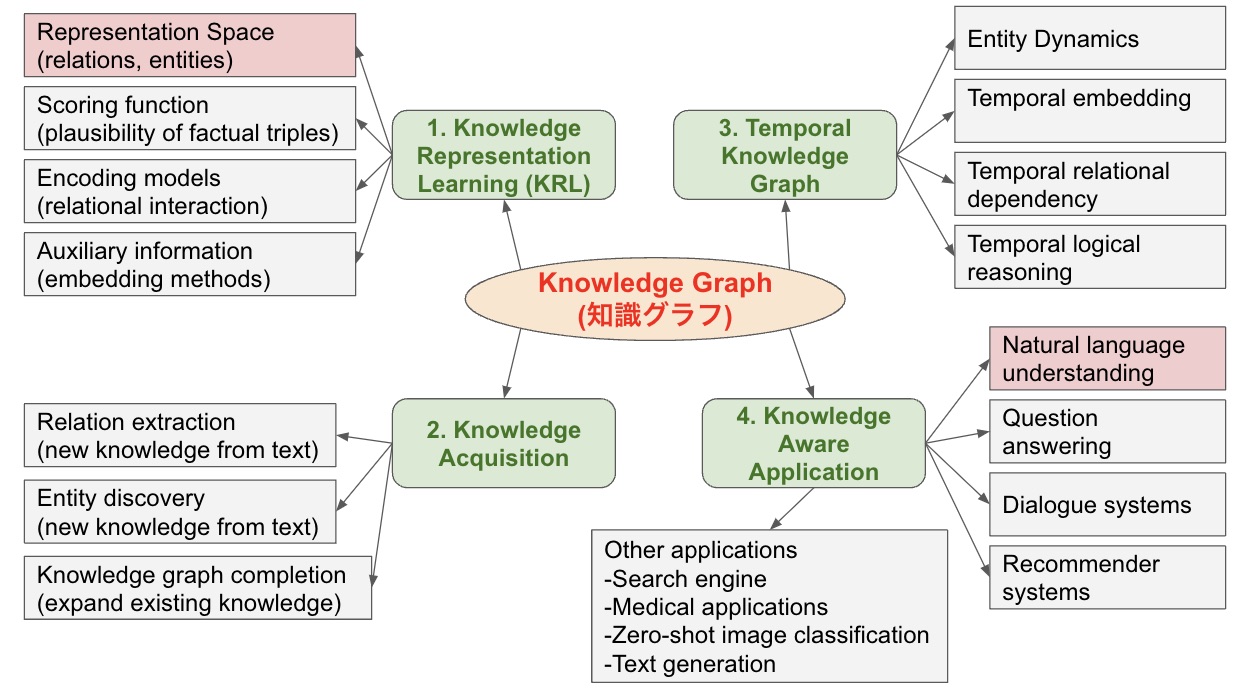
1. Knowledge Representation Learning(KRL、表現学習)はエンティティ(entities)と関係(relation)を低次元ベクトルにマッピングし、それらの意味(semantics)を獲得します。技術的には4つの視点で考えられ、A. Representation space, B. Scoring function, C. Encoding models, D. Auxiliary informationになります。A. Representation space(表現空間)の重要な課題はエンティティと関係の低次元分散埋め込み(embedding)を学習することです。主な手法はPoint-wise space, Complex vector space, Gaussian distribution, Manifold and groupです。ここにはこのブログが注目している因果関係(原因と結果)の関連技術も含まれています。B. Scoring functionは尤度を測定するために使用されます。これは、エネルギーベースの学習フレームワークでのエネルギー関数がよく使われます。主な手法はDistanceやSemantic matchingの辺りになります。C. Encoding modelsは特定モデルアーキテクチャを介して、エンティティと関係の相互作用をencodeします。モデルの例はLinear/Bilinear, Factorization, Neural nets, Convolutional Neural Network(CNN), Recurrent Neural Network(RNN), Transformers, Graph Convolutional Network(GCN)になります。 D. Auxiliary informationは、テキストの説明、エンティティのカテゴリー、画像情報、といった外部の情報を投入して、より効果的な知識表現を行います。
2. Knowledge Acquisition(知識獲得)は知識グラフを構築することを目的としています。非構造化テキストおよびその他の構造化または半構造化情報から、既存の知識グラフを完成させ、発見した「エンティティ」と「エンティティとの関係」とを認識します。適切に構築された大規模な知識グラフは幅広い分野での応用役立ちます。これは、アプリケーションと知識を意識したモデルに力を与える常識的な推論によって、AI発展の貢献を期待できます。主なタスクは A.Relation extraction, B. Entity discovery, C. Knowledge graph completionです。技術的には、A.Relation extractionは大規模な構築を行うための重要なタスクです。テキストから未知の事実関係を抽出し、それらを知識に追加することにより、知識グラフが自動的に作成されます。B. Entity discoveryはテキストと知識グラフ間の知識を融合します。エンティティの曖昧性解消(Disambiguation)やAlignmentの問題を取り込んでいるイメージです。C. Knowledge graph completionは 既存エンティティと関係の間の欠落しているリンクを完成する技術です。エンティティを指定して、エンティティの関係を推測します。主な手法はEmbedding-based ranking, path-based reasoning, rule-based reasoning, meta relational learning, triple classificationです。
3. Temporal Knowledge Graphは動的な情報をKRLに取り込むことです。現在の知識グラフの研究は静的な手法に注目し、時間と共に変化していく知識グラフはまだそんなに研究されていません。ただし、時間情報は非常に重要で、構造化された知識は特定の範囲内でのみ保持されるため、期間や進化は時系列に従います。このアイデア関連に取り込んでいる研究はA.Entity dynamics, B.Temporal embedding, C.Temporal relational dependency, D.Temporal logical reasoningになります。
4. Knowledge Aware Applicationについて、豊富に構造化された知識はAIアプリケーションに役立ちます。しかし、そのような象徴的な知識をどのように統合するか、実世界のアプリケーションの計算フレームワークはまだチャレンジ中です。現在の応用としては、A.Natural language understanding, B.Question Answering, C. Dialogue systems, D. Recommender systems, E.その他(search engine, medical applications, zero-shot image classification, text generation, sentiment analysis, etc.)のようなイメージです。
上述のように、このブログでは最終的な目的として「知識グラフにより、単語と単語の因果関係を見つけて、単語ベースの因果によるクリック確率を予測できるか」という仮説を検証したいと思います。それで、上記に説明したカテゴリー関連では、「1A.Representation space」と「4A.Natural language understaning」の辺りに関係があります。細かく言うと、単語とクリックの因果を検討したいので、因果分析を掘り下げていきます。
2. 因果分析(Causal Analysis)の紹介
原因分析(causal analysis)では、データ生成プロセスの基礎となる因果関係メカニズムを活用できます。これは、機械学習手法の予測や説明性よりも高度です。因果分析の主要な研究トピックは二つあり、因果推論(casual inference)と因果発見(causal discovery)です。因果推論の目的は結果に対する処置(treatment)の因果効果を推定することです。言い換えると、行われた決定や取られた行動の結果の因果効果です。因果関係の発見は変数間に一連の因果関係が依存するかを調べます。今回は知識グラフの作成関連で、因果推論に注目します。ちなみに、因果推論は機械学習(AI)の解釈性としにも使われています。
2.1. 因果推論(Causal Inference)
因果推論は対策の効果、例えば薬の副作用の評価などを始めとして、経済学、社会科学、医学の分野で幅広く適用されています。効果の推定は、適用された処理によって引き起こされる結果に関連付けられています。用語として処置(treatment)と結果(outcome)の2つあり、それぞれ、行われた決定または取られた行動とその結果という意味です。
因果推論のイメージ(下記の図)を掴むため、論文の例を引用し説明します(左図)。さらに、将来的に、どういう感じに試したいのかも想像してみました(右図)。
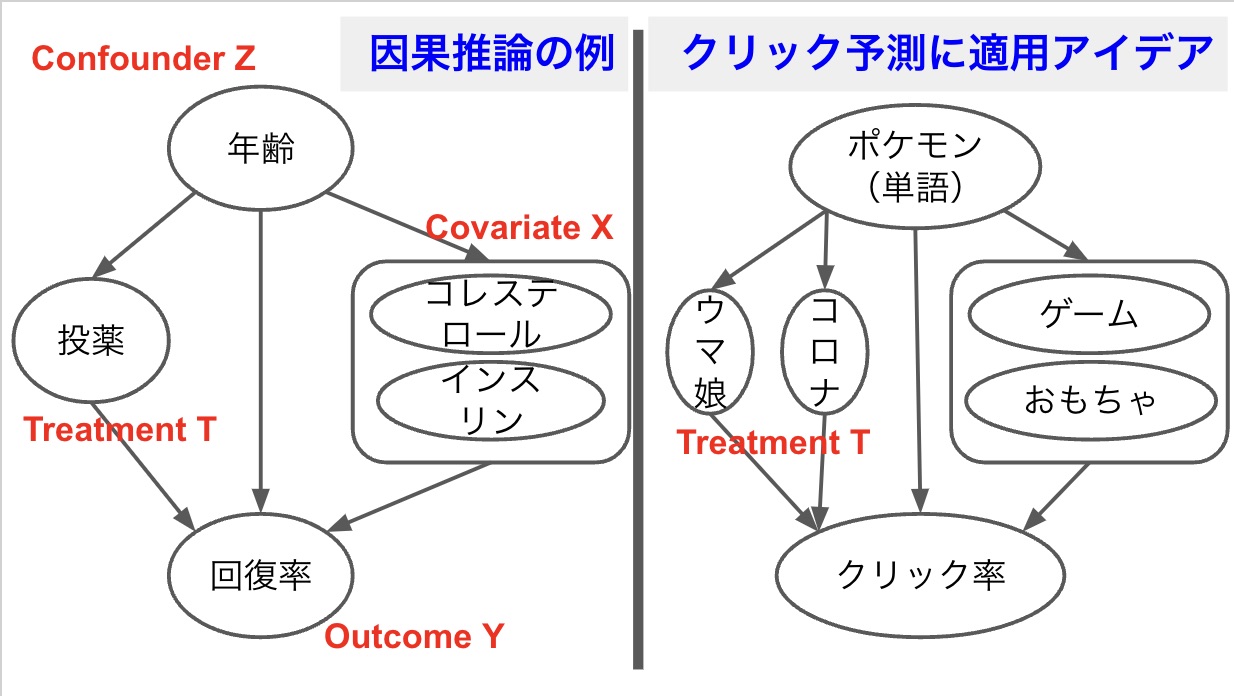
まず、病気に対する投薬の効果の例を説明します(左図)。研究者は患者の回復率に対するプラス効果を評価する必要があります。図のように、変数間の因果関係が示されます。処置(Treatment T)は投薬、観察された特徴量(Covariate X)は患者の状態(コレステロールやインスリンレベルなど)です。結果(Outcome Y)は回復率、年齢(Confounder Z)は交絡因子です。若い人たちには投薬が必要ない可能性もあり、年齢が患者に薬を適用する必要性に影響します。また、年齢も回復率に影響します。若者は高齢者より回復する可能性が高いと考えられるからです。大枠のロジックがまとまれば、図のような因果グラフを書くこともできます。
次に、投薬の例を真似て、クリック予測の仮説について、どのように実施可能かを考えてみました(右図)。Outcome Yはクリック率にします。Covariate X(状態)はクリックされた文章のカテゴリーとします。実は状態はユーザーの特徴が一番良いのですが、クッキーレスによって、ユーザーの情報が取れない可能性が高いので、代わりに、文章のカテゴリを活用してみることです。Treatment Tはポケモンをクリックした後の単語(impression)です。単語の選択肢は沢山ありますので、投薬の例と違ってTreatmentは投薬の有無ではなく、複数の単語(ウマ娘、コロナ、など)になります。こういう設計で、単語の因果関係で、クリック率に解釈できるかを実験してみようというアイデアです。期待としては「ポケモン」をクリックした後に、「ウマ娘」や「コロナ」の単語が出てきたら、それぞれのクリック率はいくらくらいになるかの因果を推論することができ、適切な単語を推奨することも可能になるということです。
それでは、因果推論は具体的に、どうやって実装できるのかを紹介します。
2.2. 因果モデル(Causal Model)
因果推論が利用する重要なモデルは二つの構造があり、structural causal modelとpotential outcome frameworkです(下記の図)。

Structural causal modelは因果グラフと構造方程式の2つの要素から成ります。因果グラフは確率的グラフィカルモデルで、事前知識とデータ生成プロセスに関する仮定を表現できます。zeta(因果グラフ)はnu(nodes)とepsilon(edges)から定義されます。構想方程式はedgesの因果関係を示します。そうすることで、上記の因果推論の例のX,T,Yは下記の式で計算可能になります。
Potential outcome frameworkではバイナリ処理を考慮し、二つの可能な結果を推定します。投薬効果推定の場合、T=0では、投薬なしでのコントロールセットとして、T=1は投薬に割り当てられ、可能な結果はY0とY1になります。
2.3. 処置効果評価(Treatment Effect Metric)
因果推論と因果モデルに基づいて、処置効果(Treatment effect)はいくつかのレベルで測定できます。主な手法は、Individual Treatment Effect(ITE), Average Treatment Effect(ATE and ATT), Conditional Average Treatment Effect(CATE)になります。
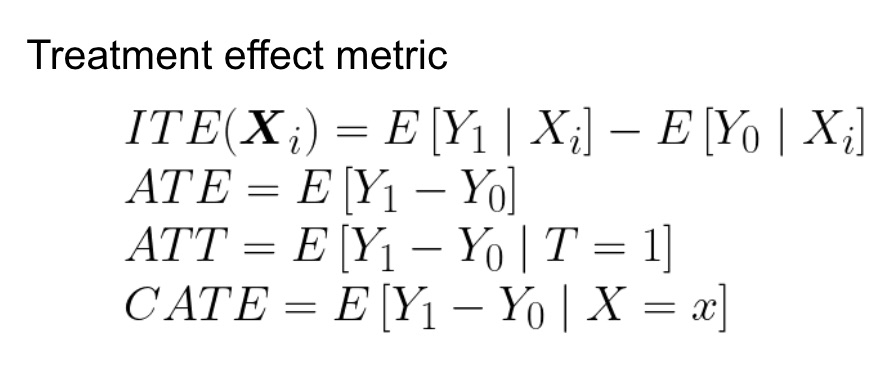
ITEは一つずつのXに対して、Y0とY1の変化を測定します。本来なら、treatment effectでは二つの効果の差を測定したいですが、一つのtreatmentでは一つの効果しか観測できず、二つのtreatmentを与えることができないので、現実にはITEで測定するのは難しいです。そこで、ATEとATTがよく使われます。ATEは全体のtreatment effectを測定し、ATTはグループに対しての測定を行います。さらに、CATEによって、特徴量に対しのサブグループの測定も可能です。これは、heterogeneous treatment effectと呼ばれます。それぞれの計算式は下記になります。
また、自然言語処理への適用も同じコンセプトで、幅広く使われています。例えば、医療文献と電子医療記録からの因果グラフの構築などにも使われています。
3. 実装
いよいよ、実装です。
やりたいことはCausalNexを利用し簡単に因果推論を試してみることです。
3.1. 実装環境とデータ
実装環境
環境はGoogle Colaboratoryを利用ました。また、因果推論の計算については、CausalNexを利用しました。CausalNexはQuantumBlackがオープンソース化している因果関係を明らかにするためのPython Libraryです。
データセット
データセットはUCI(University of California, Irvine)が提供している癌のデータセットを利用しました。下記のように、データをダウンロードし、そのままで使わせて頂きました。
import wget # Download cancer dataset: http://archive.ics.uci.edu/ml/datasets/Breast+Cancer url = "http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer/breast-cancer.data" wget.download(url, '')
使ったデータは上記の説明に合わせて、少し絞りました。例に合わせて説明すると、Confounder Zはages(年齢)、Treatment Tはirradiation(例は投薬ですが、データは放射線で、コラム名はirradiat)、Outcome Yはevents(例は回復率ですが、データは癌の再発有無)になります。また、軽くTreatmentとOutcomeのデータを確認すると、データの偏りが見られますが、そのまま使います。また、Covariate Xはmenopause(閉経)やbreast(胸)にしました。他は癌のステージ関連情報の項目で、今回は使わないことにしました。
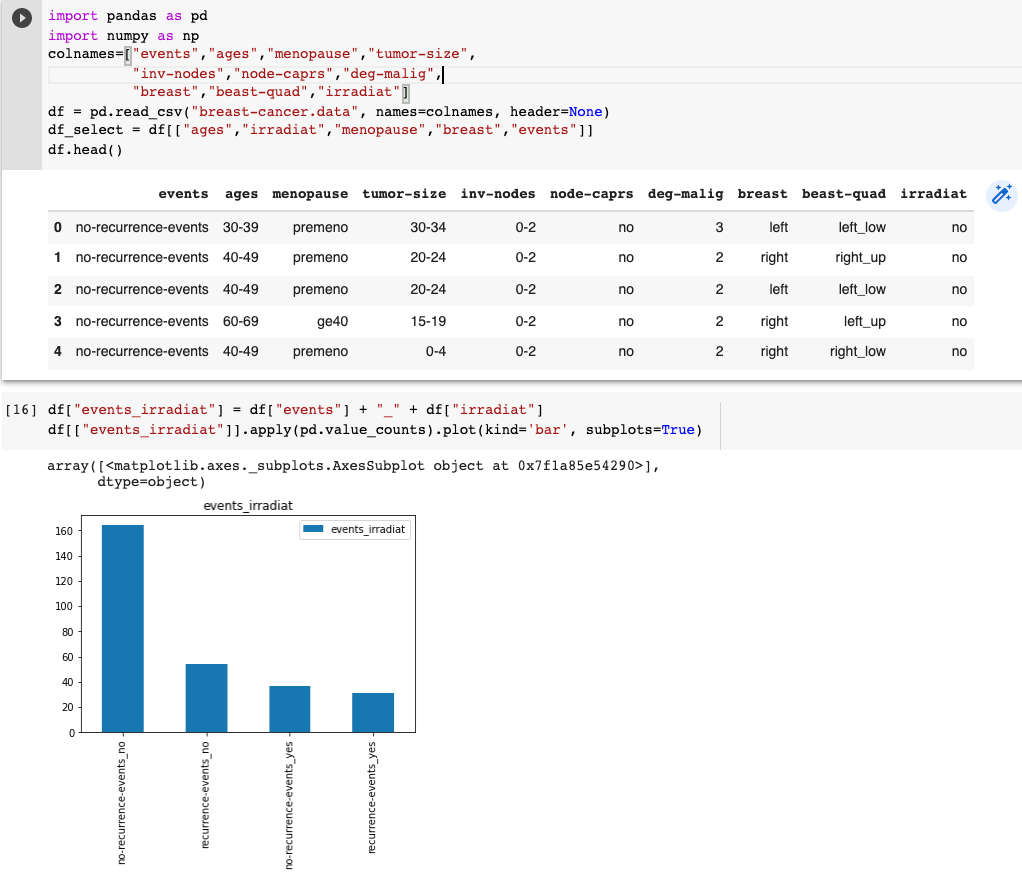
3.2. CausalNexで因果推論を試してみたい
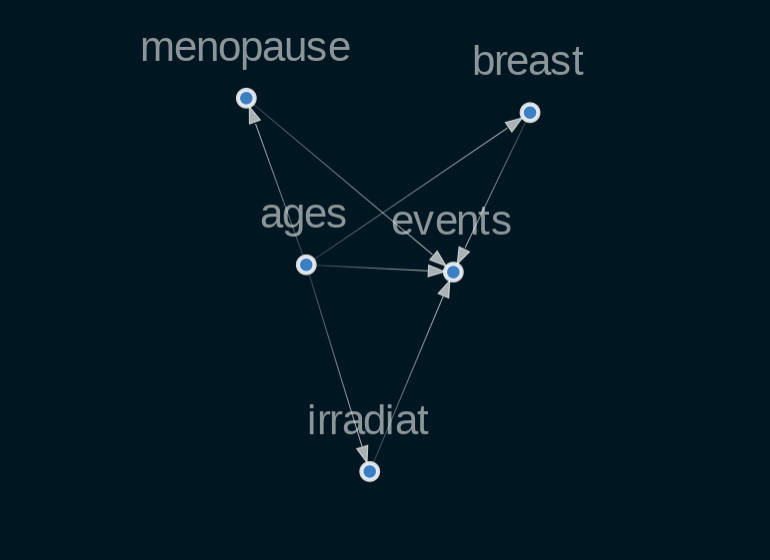
ここでは、CausalNexを利用し、放射線は癌の再発の治療効果があるかどうかの因果を推論します。まず、因果モデルを作成します。モデル構想は下記のコードになります。
from causalnex.structure import StructureModel
sm_cancer_true = StructureModel()
sm_cancer_true.add_edges_from([
('ages', 'events'),
('ages', 'irradiat'),
('irradiat', 'events'),
('ages', 'menopause'),
('menopause', 'events'),
('ages', 'breast'),
('breast', 'events'),
])
viz = plot_structure(
sm_cancer_true,
graph_attributes={"scale": "0.7"},
all_node_attributes=NODE_STYLE.WEAK,
all_edge_attributes=EDGE_STYLE.WEAK,
)
Image(viz.draw(format='png'))
次に、学習とテストのため、データを分けます。それから、Bayesianネットワークで学習し、テストデータからAUCで評価します。軽く試してみただけでも、AUC 0.68くらいになり、そんなに悪くないですね。
from sklearn.model_selection import train_test_split
from causalnex.network import BayesianNetwork
from causalnex.evaluation import roc_auc
# seperate train/test data
train, test = train_test_split(df_select, train_size=0.8, random_state=42)
# generate BayesianNetwork
bn_true = BayesianNetwork(sm_cancer_true)
print("sm_cancer_true: ", sm_cancer_true)
print("bn_true: ", bn_true)
# fit the model with train data
bn_true = bn_true.fit_node_states(df_select)
bn_true = bn_true.fit_cpds(train, method="BayesianEstimator", bayes_prior="K2")
# test the model using test data
roc, auc = roc_auc(bn_true, test, "events")
print("\nAUC: {}".format(auc))
print("\nConditional Probability Distributions (CPDs):\n{}".format(bn_true.cpds['irradiat']))

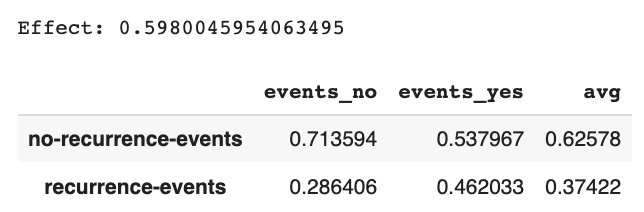
最後に、効果を測定します。学習されたBayesianネットワークを使って、放射線の有無による、癌の再発ありなしの確率がどれくらいあるのかを計算します。結果は下記のテーブルです。放射線なしの場合、癌再発は0.28で、放射線ありの場合、癌再発は0.46でした。この結果を使って、放射線の効果を計算すると、0.598でした。
def compute_irradiat_cf_and_effect(bn):
# counterfactual while performing irradiat
ie = InferenceEngine(bn)
ie.do_intervention("irradiat", {'yes': 0.0, 'no': 1.0})
events_no = pd.Series(ie.query()["events"])
ie.do_intervention("irradiat", {'yes': 1.0, 'no': 0.0})
events_yes = pd.Series(ie.query()["events"])
cf = pd.concat([events_no, events_yes], axis=1)
cf.rename(columns={0:"events_no", 1:"events_yes"}, inplace=True)
cf["avg"] = (cf["events_no"] + cf["events_yes"])/2.0
expected_no = cf["avg"]["no-recurrence-events"]
expected_yes = cf["avg"]["recurrence-events"]
effect = expected_yes / expected_no
print("\nEffect: {}\n".format(effect))
return cf
counterfactuals = compute_irradiat_cf_and_effect(bn_true)
counterfactuals
4. まとめと考察
今回は知識グラフをおさらいし、その中にある因果分析の技術を紹介しました。雰囲気を掴むため、簡単な例も実装してみました。結果は当たり前のようなものですが、因果分析の適応可能性が見えてきました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD