2021.01.07
Transformer で画像認識をやってみる ~ Vision Transformer ~
こんにちは、次世代システム研究室のT.I.です。最近、量子コンピュータ関係のことばかりしていた気がするので、今回は全う(?)な機械学習のテーマとして最近発表のあった画像認識モデルについて紹介したいと思います。
TL;DR
- Deep Learning の画像認識タスクでは、Convolutional Neural Network を利用することが標準的であるが、自然言語処理で高い性能を発揮した Transformer を画像認識に応用するモデル(ViT)が最近発表され、各種タスクでSOTAを達成
- モデルの紹介と、PyTorchでの実装を元に簡単な画像認識タスクのデモ
- 実は、ViT で高い性能を発揮するためには、膨大なデータを用いた事前学習と、個別のタスクに合わせた fine-tuning が必要、利用に際しては要注意
導入
2012年、Convolutional Neural Network (CNN) を応用した Deep Learning モデルが発表され、その高い性能で一躍脚光を浴びました。CNNは周囲の情報を畳み込んで取り入れる構造を持ち、現在では、画像認識で必須といえるモジュールです。一方、自然言語処理の分野では、従来は Recurrent Neural Network によるモデルが主に研究されていました。これも、2017年にAttention という構造に基づいた Transformer-based モデルが発表され、その高い性能から瞬くまに旧来のモデルを駆逐して、Transformerを応用したBERTやGPT-3などのモデルへと繋がりました。今回紹介する Vision Transformer とは、この画像認識で一般的なCNNではなく、Transfomerを利用してみるというものです。
Vision Transformer (ViT)
今回紹介するのは、Vision Transformer ですが、似たような名前で Visual Transformers [arXiv:2006.03677] というものも発表されています。前者は、CNNを一切使っていないモデルですが、後者はCNN+Transformerというモデルですのでご注意ください。
Attention & Transformer
簡単に述べると、Attention layer とは、memory (key + value) の対して、input (query) と近いkeyのvalueを重み付き平均を出力する neural networkです。Attention と通常の Multilayer Perceptron (MLP) を交互に重ねたものが Transformer (以下の図は元論文”Attention Is All You Need” arXiv:1706.03762より引用)と呼ばれます。モデルの詳細については、以前のBlogなどで紹介したので割愛しますが、左側を Transformer-Encoder, 右側を Transformer-Decoder と分けて呼ぶこともあり、今回のViTではこの Transformer-Encoder を少し修正して利用します。
![]()
ViT
さて、今回紹介する Vision Transformer (ViT)は、Transformer (より正確には、若干構造を変えた Transformer-Encoder)を利用した画像認識モデルです。“An image is worth 16×16 words: Transformers for image recognition at scale”, arXiv:2010.11929 という論文が発表されています。ViTはモデルの概略は以下の通りです。(図は論文より引用)
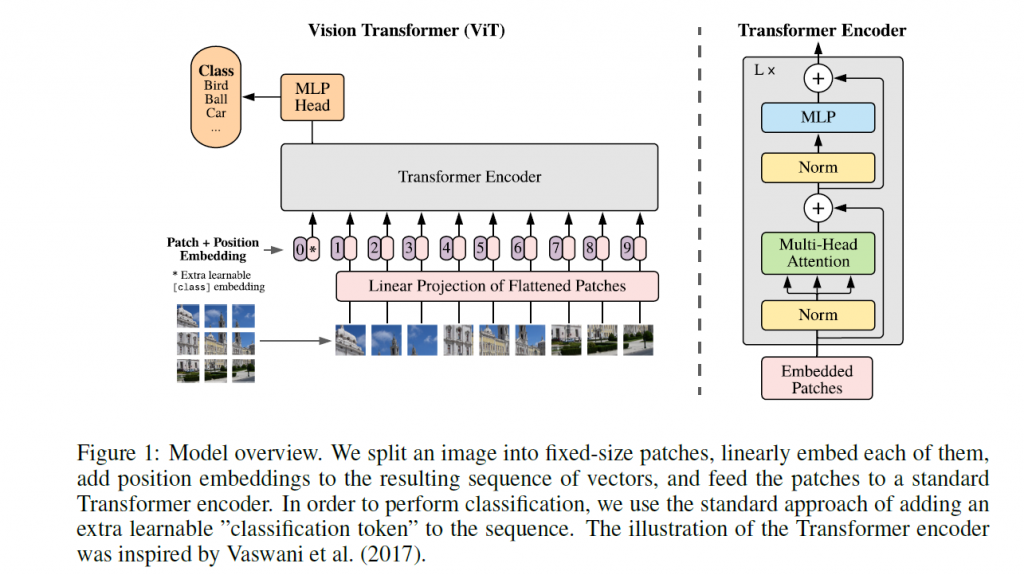
Transformer では通常は一定の固定長の1次元シークエンスを入力に受け取りますので、2次元(+カラーの情報)を持った入力を受け取ることが、そのままではできません。以下のような方法で前処理します。
- 画像のパッチ化
元画像の解像度を(H, W)、channel (C)とし、1枚の画像をN枚の(P,P)の解像度のパッチに分割
%7D%0A%5Cend%7Balign*%7D&f=t&r=150&m=p&b=f&k=f)
- 行列Eで、パッチを射影する。この行列Eは訓練で学習するパラメータ
%20%5Ctimes%20D%7D%0A%5Cend%7Balign*%7D&f=t&r=150&m=p&b=f&k=f)
- 元のパッチの位置情報を作成
%5Ctimes%20D%7D%0A%5Cend%7Balign*%7D&f=t&r=150&m=p&b=f&k=f)
以上のデータを組み合わせて、Transformer Encoder に入力するデータ![\begin{align*} x_0 = [ x_\mathrm{class}; x_p^1 \mathbf{E}; x_p^2 \mathbf{E}; \cdots ; x_p^N \mathbf{E}] + \mathbf{E}^\mathrm{pos} \end{align*}](https://texclip.marutank.net/render.php/texclip20210106174224.png?s=%5Cbegin%7Balign*%7D%0Ax_0%20%3D%20%5B%0Ax_%5Cmathrm%7Bclass%7D%3B%20x_p%5E1%20%5Cmathbf%7BE%7D%3B%0Ax_p%5E2%20%5Cmathbf%7BE%7D%3B%20%5Ccdots%20%3B%20x_p%5EN%20%5Cmathbf%7BE%7D%5D%0A%2B%20%5Cmathbf%7BE%7D%5E%5Cmathrm%7Bpos%7D%0A%5Cend%7Balign*%7D&f=t&r=150&m=p&b=f&k=f)
の準備できました。(BERTのように[class]トークンを入力の頭に追加してあります)
Transformer-Encoder は Multi-Head Self-Attention (MSA) + MLP + Norm の組み合わせからできていますが、ViTで利用する Transformer-Encoder はオリジナルと以下の点が異なっています。上で引用した2枚の図を比較すれば違いが判ると思います。
- 正規化 layer (LN) の順序
ViTでは、Attention, MLPの後ではなく先に実行される - MLPの活性化関数
ReLUではなく、GELU(Gaussian Error Linear Units)
)%20%2B%20z_%7B%5Cell%20-%201%7D%2C%0A%5Cqquad%20%5Cell%20%3D%201%2C%20%5Ccdots%2C%20L%20%5C%5C%0Az_%5Cell%20%26%3D%20%5Cmathrm%7BMLP%7D(%5Cmathrm%7BLN%7D(z_%7B%5Cell%7D%5E%5Cprime))%20%2B%20z_%7B%5Cell%7D%5E%5Cprime%2C%0A%5Cqquad%20%5Cell%20%3D%201%2C%20%5Ccdots%2C%20L%20%5C%5C%0A%5Cend%7Balign*%7D&f=t&r=150&m=p&b=f&k=f)
これをL層分、繰り返します。各層への入力 z をそのまま加算することで(参考 ResNet)、深いネットワークであっても信号の消失を避けることが可能となります。
Transformer-Encoder の出力を更にMLPに入力し、タスクに応じたアウトプットを得ます。今回の例では、画像のクラス分けということで、Transofrmer-Encoder の出力結果を更にMLPに入力し、その画像が特定のクラスである確率を算出します。
ViTのデモ
オリジナル実装のコードも公開されていますが、今回は、Pytorch による実装https://github.com/lucidrains/vit-pytorch を元に実際の機械学習の分類タスク(CIFAR-10)を試してみたいと思います。
CIFAR-10 とは、以下のような、解像度32×32でカラーの画像、10種類のクラスに分けられた画像分類のベンチマークといえるデータセットです。

さて、通常データセットをダウンロードして展開・読み込みなどの作業が煩わしいですが、pytorchを利用すればデータを準備と前処理が簡単に完了します。
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batch_size,
shuffle=True, num_workers=2)
test_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
今回の vit-pytorch を使うと(pip install vit-pytorch で導入できます)以下のように簡単・手軽に ViT を試すことができます。
import torch
from vit_pytorch import VIT
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
net = ViT(
image_size=32,
patch_size=4,
num_classes=10,
dim=256,
depth=3,
heads=4,
mlp_dim=256,
dropout=0.1,
emb_dropout=0.1
).to(device)
ここで、それぞれのパラメータの意味は、CIFAR-10の画像ファイルは(H, W) = (32, 32)、num_classes は分類するクラス数(CIFAR-10はその名の通り10種), (dim, depth, heads) は、Attention のパラメータ、mlp_dim は MLP のサイズになります。
さて、早速モデルの学習をしてみましょう。
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
epochs = 20
for epoch in range(0, epochs):
epoch_train_loss = 0
epoch_train_acc = 0
epoch_test_loss = 0
epoch_test_acc = 0
net.train()
for data in train_loader:
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()/len(train_loader)
acc = (outputs.argmax(dim=1) == labels).float().mean()
epoch_train_acc += acc/len(train_loader)
net.eval()
with torch.no_grad():
for data in test_loader:
inputs, labels = data[0].to(device), data[1].to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
epoch_test_loss += loss.item()/len(test_loader)
test_acc = (outputs.argmax(dim=1) == labels).float().mean()
epoch_test_acc += test_acc/len(test_loader)
print(f'Epoch {epoch+1} : train acc. {epoch_train_acc:.2f} train loss {epoch_train_loss:.2f}')
print(f'Epoch {epoch+1} : test acc. {epoch_test_acc:.2f} test loss {epoch_test_loss:.2f}')
結果は以下のようになりました。
Epoch 1 : train acc. 0.16 train loss 2.22 Epoch 1 : test acc. 0.21 test loss 2.11 ... Epoch 20 : train acc. 0.46 train loss 1.54 Epoch 20 : test acc. 0.47 test loss 1.50
はて、精度はあまり良くないですし、学習もなかなか進みません。色々とoptimizerやmodelのhyperparmeter を探索しましたが、残念ながら大きな改善は得られませんでした。
ちなみに以下のように適当なCNNを試してみると
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 9, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 32, 5)
self.fc1 = nn.Linear(32 * 5 * 5, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 32*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Epoch 1 : train acc. 0.15 train loss 2.28 Epoch 1 : test acc. 0.22 test loss 2.19 ... Epoch 20 : train acc. 0.72 train loss 0.81 Epoch 20 : test acc. 0.67 test loss 0.97
とあっという間にViTの性能を越えてしまいました。(細かいtuningしていないので、そもそも大した性能ではありませんが)
さて、ここまで進めておいてネタバラシという理由ではないですが、実は ViT の学習には注意が必要です。ViTでは、まずJFT-300Mという3億枚のデータセット(非公開のようです)を元に事前学習し、その後に各種タスク別に fine-tuning しており、論文によると、膨大なデータセットでの事前学習が個別のタスクへの高い性能を発揮すために必要だと書かれています。事前学習済みのデータが公開されていますので(https://github.com/google-research/vision_transformer)、これを元に個別のタスク向けにチューニングするのが良いのだと思います(JFT-300Mで事前学習したものは未公開のようです)。ネットでViTを検索すると精度が悪いという記事が見つかりますが、これが原因かと思われます。
この点については、つい先日に新たに発表された論文 “Training data-efficient image transformers & distillation through attention” (arXiv:2012.12877)によると、色々と工夫することで公開されているデータセットでも事前学習の改善が期待されるそうです。
まとめ
今回、自然言語処理で活躍している Transformer を画像処理に応用する Vision Transformer (ViT)を解説し、Pytorch で公開されている実装を元に画像処理タスクの結果を紹介しました。残念ながら、Transformer-based model であるためパラメータの数が膨大で、少数・シンプルな学習では、性能を発揮することはできませんでした。(まあ、たかだかCIFAR-10 に使う時点で牛刀割鶏な感がありますし)
最後に
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考資料
- “Attention Is All You Need”, https://arxiv.org/abs/1706.03762
- “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”, https://arxiv.org/abs/2010.11929
- Vision Transformer https://github.com/google-research/vision_transformer
- Vit-pytorch https://github.com/lucidrains/vit-pytorch
- “Training data-efficient image transformers & distillation through attention”, https://arxiv.org/abs/2012.12877
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD