Spark 3.0の新機能によるFXデータの抽出時間を短縮してみた
こんにちは。次世代システム研究室のT.D.Qです。
2020年6月にビッグデータを並列処理するクラスタコンピューティングフレームワーク「Apache Spark 3.0.0」が公開されました。性能面では、Adaptive Query Execution(AQE)、Dynamic Partition Pruning(DPP)、各種の最適化機能により、TPC-DSのベンチマークテストでは、Spark 3.0はSpark 2.4よりもおおよそ2倍高速です。今回の記事は大量FXデータの抽出にどのくらい時間を短縮できるかSpark 3.0の新機能を検証して紹介したいと思います。
検証実行環境
今回利用するミドルウェアは、以下のものでCentOS7.8サーバで構築されたクラスタで試しました。- Hadoop 3.2.1
- Spark 3.0.0
- Delta Lake 0.7 (delta-core_2.12)
環境構築手順はこちらの記事をご参照ください。
また、今回の検証はPySparkで実現するので、Jupyter Notebookと連携するように設定し、以下のコマンドでPySparkを起動しておきます。
#!/bin/bash
timestamp=`date "+%Y%m%d%H%M"`
nohup pyspark --name 20204QBlogSparkApplication${timestamp}
--packages io.delta:delta-core_2.12:0.7.0
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension"
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" &> pyspark.log
Jupyter Notebookから起動したSparkContextにアクセスすることができます。
検証データの準備
今回の検証データはHistData.comから各クロス円通貨ペアの直近3年間のCSVデータをダウンロードしてHDFSに事前に格納しました。データサイズは31.4GB前後です。
hdfs dfs -du -s -h /tmp/forex_data 10.5 G 31.4 G /tmp/forex_data
一括CSVデータ取り込む
HDFSに通貨ペア別月別にCSVフォーマットで複数ファイルを格納しましたが、SparkのDataFrameに複数CSVファイルを一括ロードしていきたいと思います。
from pyspark.sql.functions import col, lit
from pyspark.sql.types import StructType,StructField, StringType, FloatType
def get_df_from_csv_paths(commodity):
file_path="/tmp/forex_data/{0}/*.csv".format(commodity)
quote_schema = StructType([ \
StructField("quote_timestamp",StringType(),True), \
StructField("bid_quote",FloatType(),True), \
StructField("ask_quote",FloatType(),True), \
StructField("volume", StringType(), True)
])
df = spark.read.format("csv").option("header", "false").\
schema(quote_schema).\
option('delimiter', ',').\
option('mode', 'DROPMALFORMED').\
load(file_path)
# volumeカラムは使わないのでforex_pairに変更。
new_df = df.withColumn("volume", lit(commodity)).withColumnRenamed("volume", "forex_pair")
# 検索時間を短縮する目的でレート日付でテーブルのPartitionを作るため、quote_dateカラムを作成する。
new_df = new_df.withColumn("quote_date", new_df.quote_timestamp[0:7])
return new_df
def load_all_quote_data():
forex_pairs=["audjpy","cadjpy","chfjpy","eurjpy","gbpjpy","nzdjpy","sgdjpy","usdjpy"]
all_quote_df = None
for forex_pair in forex_pairs:
quote_df=get_df_from_csv_paths(forex_pair)
if all_quote_df is None:
all_quote_df = quote_df
else:
all_quote_df = all_quote_df.union(quote_df)
return all_quote_df
上記の関数で準備した8通過ペア、264,260,447件のレートデータを無事にSparkのDataFrameにロードすることができました。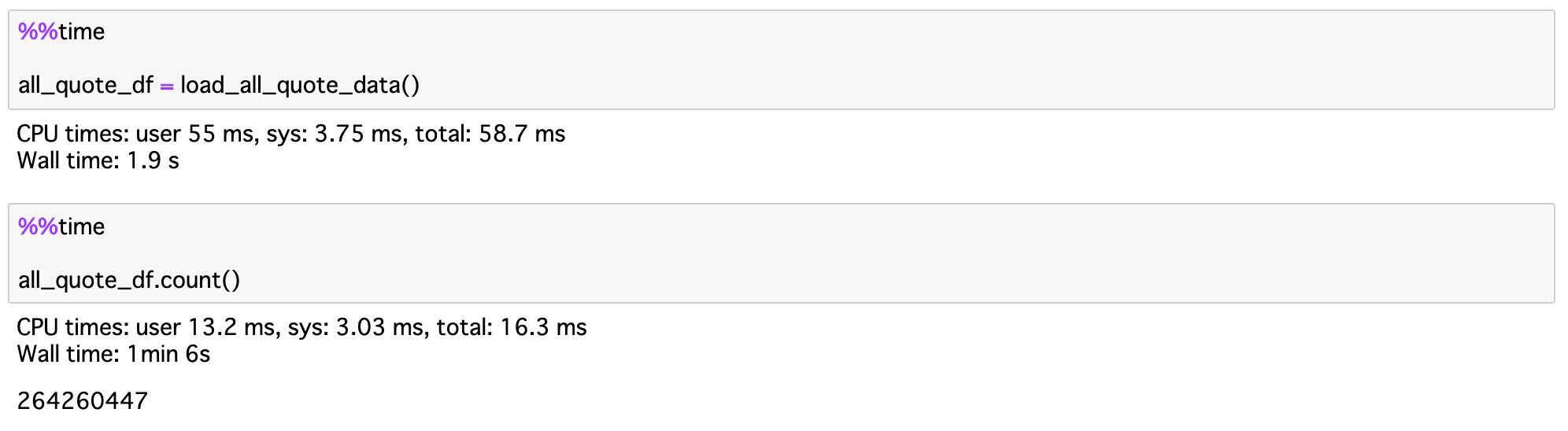
Delta Lakeにデータ格納
今回は大量のテーブルを結合して実行時間を短縮していきたいので、all_quote_dfから3テーブルを作成してDelta Lakeに格納します。
def createDeltaTable(dataframe, table_name, partition_cols=None):
#To create a Delta table, write a DataFrame out in the delta format. #.save(table_location)
dataframe.write.format("delta") \
.partitionBy(partition_cols) \
.option("mergeSchema", "true") \
.option("overwriteSchema", "true") \
.mode('overwrite') \
.saveAsTable(table_name)
quote_historyテーブル
大量のテーブルです。quote_date,forex_pairカラムでPartitionします。
Midプライス(mid_price_history)テーブル
このテーブルはサイズが大きいので、quote_date,forex_pairカラムでPartitionします。
get_mid_price_sql ="""
select
quote_date,
forex_pair,
quote_timestamp,
(bid_quote + ask_quote)/2 as mid_quote
from quote_history
"""
df_mid = exec_sql(get_mid_price_sql)
createDeltaTable(dataframe=df_mid, table_name="mid_price_history", partition_cols=["quote_date", "forex_pair"])
通貨ペアマスタ(forex_pairs)テーブル
このテーブルはサイズが非常に小さいです。Partitionなし。
def exec_sql(query):
df_result = spark.sql(query)
return df_result
get_forex_pairs_sql ="""
select
forex_pair,
upper(concat(substring(forex_pair,0,3), '/', substring(forex_pair,4,3))) forex_pair_name
from (select distinct forex_pair from quote_history) tmp
"""
df_forex_pair = exec_sql(get_forex_pairs_sql)
df_forex_pair.write.format("delta").mode('overwrite').option("mergeSchema", "true").saveAsTable("forex_pairs")
パフォーマンス改善したいSQLについて
Spark 3.0の新機能を使って大量のテーブル結合クエリの実行時間を短縮できるか検証したいので、今回は以下のクエリを作成しました。
def get_quote_by_pair_names(forex_pair_names, min_quote_date):
quote_query="""
select
qh.forex_pair,
qh.quote_timestamp,
qh.bid_quote,
qh.ask_quote,
mph.mid_quote
from
quote_history qh
inner join
mid_price_history mph
on qh.forex_pair=mph.forex_pair
and qh.quote_timestamp=mph.quote_timestamp
inner join
forex_pairs fp
on
qh.forex_pair=fp.forex_pair
where
fp.forex_pair in ({0})
and qh.quote_date >= '{1}'
""".format(forex_pair_names, min_quote_date)
return exec_sql(quote_query)
df_quotes = get_quote_by_pair_names("'usdjpy', 'chfjpy', 'cadjpy', 'nzdjpy', 'sgdjpy'", '20200601')
早速実行結果を確認しましょう。抽出結果は27,566,217件でしたが実行時間は3分58秒かかってしまいました!
Adaptive Query Execution
Adaptive Query Execution(AQE)は、Spark SQLの実行中に実際のデータの統計情報を見て発生するクエリを再最適化します。Spark 3.0でAQEのデフォルト設定がOffなので、使いたい時にはspark.sql.adaptive.enabledをtrueに設定する必要があります。AQEの詳細についてはこちらをご参照ください。Spark3.0ではAQEはまだDynamic Partition Pruningと一緒に動かないようですので、優先されるDynamic Partition PruningをOffにしておきます。
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "false")
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
Spark 3.0はDataFrameのexplain()メソッドで実行プランを確認できます。クエリが実行される前または実行中に、AdaptiveSparkPlanがisFinalPlanフラグはfalseとして表示されます。クエリの実行が完了すると、isFinalPlanフラグはtrueに変わります。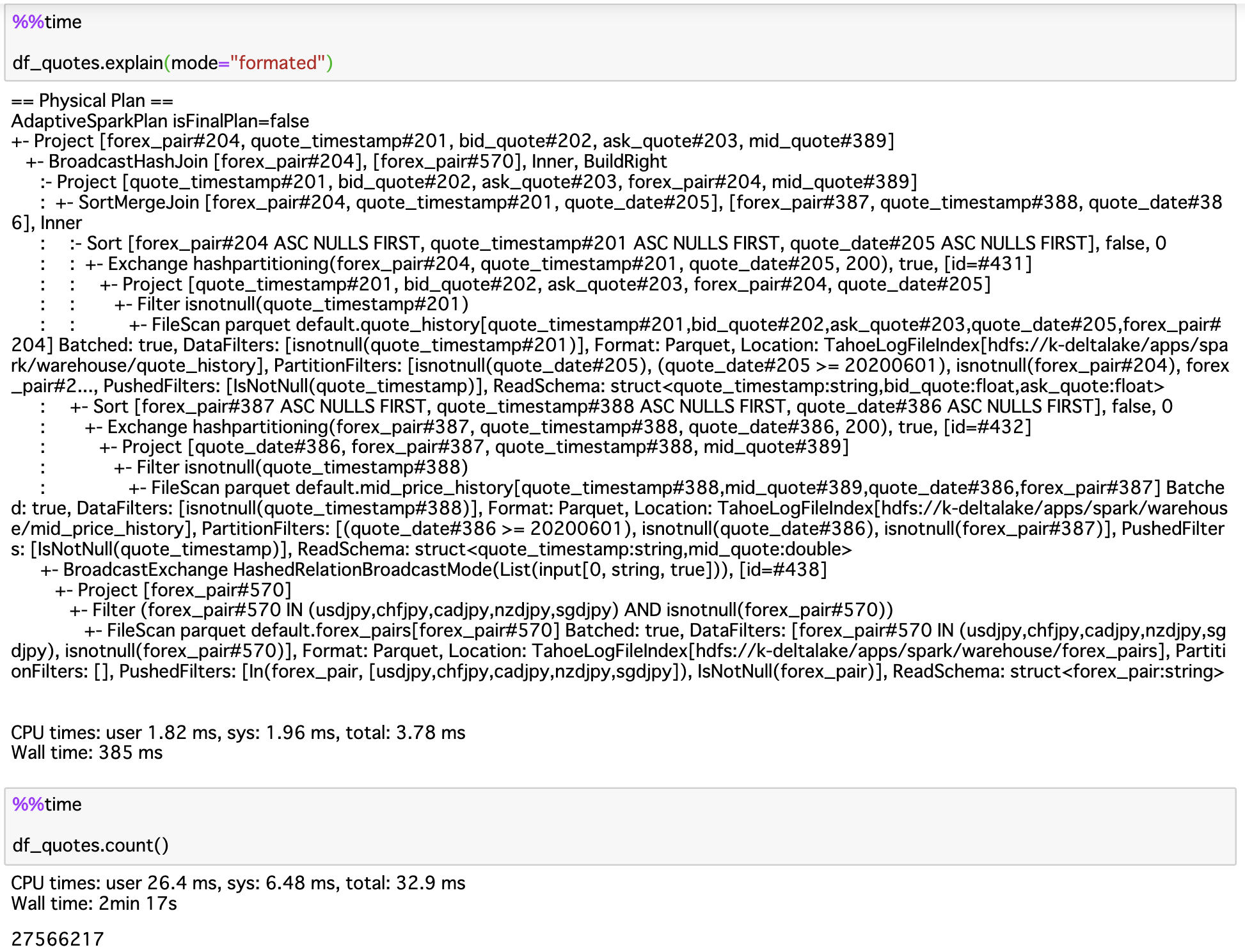
実行時間が2分17秒になりました!良さそうですね。他の改善できそうなポイントがないかクエリプランを詳しく確認しましょう。
PartitionFilters及びPushedFilters
PushedFiltersはPushdownPredicateによってDataSourceをフィルタリングする際に使用され、プッシュダウンされた条件句を表示します。
PartitionFiltersはパーティションキーによってDataSourceをフィルタリングする際に使用されます。PushedFiltersより速いです。
今回のSQLを実行後にSpark UIにてクエリのDAGを確認したところは、 サイズの大きいテーブル両方ともPartitionFilters: [(quote_date#386 >= 20200601), isnotnull(quote_date#386), isnotnull(forex_pair#387)], PushedFilters: [IsNotNull(quote_timestamp)]で、絞りたい通貨ペアが適用されなかったので、抽出したデータのサイズ、行数がまだ非常に多かったため、次の最適化処理に時間かかってしまいました。
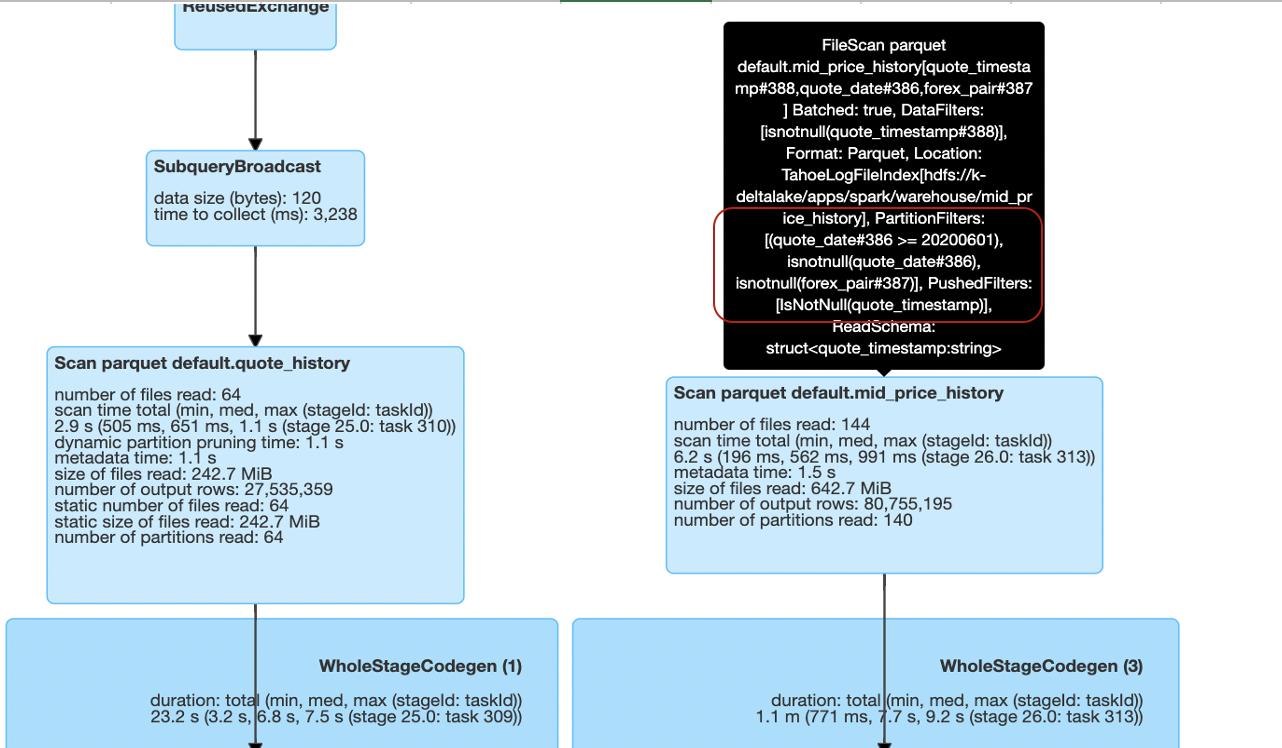
PartitionFiltersに絞りたい通貨ペアを検索条件に加えてみましょう。改修したSQL文は以下のようになりました。
def get_quote_by_pair_names(forex_pair_names, min_quote_date):
quote_query="""
select
qh.forex_pair,
qh.quote_timestamp,
qh.bid_quote,
qh.ask_quote,
mph.mid_quote
from
quote_history qh
inner join
mid_price_history mph
on qh.forex_pair=mph.forex_pair
and qh.quote_timestamp=mph.quote_timestamp
and qh.quote_date=mph.quote_date
inner join
forex_pairs fp
on
qh.forex_pair=fp.forex_pair
where
fp.forex_pair in ({forex_pairs})
and qh.forex_pair in ({forex_pairs})
and mph.forex_pair in ({forex_pairs})
and qh.quote_date >= '{quote_date}'
""".format(forex_pairs=forex_pair_names, quote_date=min_quote_date)
return exec_sql(quote_query)
df_quotes = get_quote_by_pair_names("'usdjpy', 'chfjpy', 'cadjpy', 'nzdjpy', 'sgdjpy'", '20200601')
以下はDataFrameのexplainの一部抜粋ですが、quote_history、mid_price_historyの最初から絞りたい通貨ペアをPartitionFiltersに追加されました。
df_quotes.explain(mode="formatted")
== Physical Plan ==
AdaptiveSparkPlan (19)
+- Project (18)
+- BroadcastHashJoin Inner BuildRight (17)
:- Project (12)
: +- SortMergeJoin Inner (11)
: :- Sort (5)
: : +- Exchange (4)
: : +- Project (3)
: : +- Filter (2)
: : +- Scan parquet default.quote_history (1)
: +- Sort (10)
: +- Exchange (9)
: +- Project (8)
: +- Filter (7)
: +- Scan parquet default.mid_price_history (6)
+- BroadcastExchange (16)
+- Project (15)
+- Filter (14)
+- Scan parquet default.forex_pairs (13)
(1) Scan parquet default.quote_history
Output [5]: [quote_timestamp#201, bid_quote#202, ask_quote#203, quote_date#205, forex_pair#204]
Batched: true
Location: TahoeLogFileIndex [hdfs://k-deltalake/apps/spark/warehouse/quote_history]
PartitionFilters: [isnotnull(quote_date#205), forex_pair#204 IN (usdjpy,chfjpy,cadjpy,nzdjpy,sgdjpy), (quote_date#205 >= 20200601), isnotnull(forex_pair#204)]
PushedFilters: [IsNotNull(quote_timestamp)]
ReadSchema: struct<quote_timestamp:string,bid_quote:float,ask_quote:float>
(6) Scan parquet default.mid_price_history
Output [4]: [quote_timestamp#388, mid_quote#389, quote_date#386, forex_pair#387]
Batched: true
Location: TahoeLogFileIndex [hdfs://k-deltalake/apps/spark/warehouse/mid_price_history]
PartitionFilters: [forex_pair#387 IN (usdjpy,chfjpy,cadjpy,nzdjpy,sgdjpy), (quote_date#386 >= 20200601), isnotnull(quote_date#386), isnotnull(forex_pair#387)]
PushedFilters: [IsNotNull(quote_timestamp)]
ReadSchema: struct<quote_timestamp:string,mid_quote:double>
クエリプランが良さそうですのでSQLを実行してみましょう。
実行時間が1分29秒になりました!
Dynamic Partition Pruning
Dynamic Partition Pruning(DPP)はSpark 3.0から導入された機能で、オプティマイザがコンパイル時にディメンションテーブルにパーティションされたテーブルとフィルターがないかをチェックし、プルーニングを行うことでクエリと関係ないパーティションのスキャンをスキップすることでパフォーマンス改善する機能です。DPPのイメージとしては下図のようにBroadcast ExchangeによるDynamic FilterとBroadcast Hash Joinで構成されます。
DPPを使うため、まずはdynamicPartitionPruningの設定をenabledにしておきます。

spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly", "true")
次にクエリプランを確認しましょう。以下はDataFrameのexplain()の一部抜粋ですが、注目するのがquote_historyテーブルのPartitionFiltersの部分にdynamicpruningexpression(forex_pair#204 IN dynamicpruning#579)ですね。
df_quotes.explain(mode="formatted")
== Physical Plan ==
* Project (21)
+- * BroadcastHashJoin Inner BuildRight (20)
:- * Project (14)
: +- * SortMergeJoin Inner (13)
: :- * Sort (6)
: : +- Exchange (5)
: : +- * Project (4)
: : +- * Filter (3)
: : +- * ColumnarToRow (2)
: : +- Scan parquet default.quote_history (1)
: +- * Sort (12)
: +- Exchange (11)
: +- * Project (10)
: +- * Filter (9)
: +- * ColumnarToRow (8)
: +- Scan parquet default.mid_price_history (7)
+- BroadcastExchange (19)
+- * Project (18)
+- * Filter (17)
+- * ColumnarToRow (16)
+- Scan parquet default.forex_pairs (15)
(1) Scan parquet default.quote_history
Output [5]: [quote_timestamp#201, bid_quote#202, ask_quote#203, quote_date#205, forex_pair#204]
Batched: true
Location: TahoeLogFileIndex [hdfs://k-deltalake/apps/spark/warehouse/quote_history]
PartitionFilters: [isnotnull(quote_date#205), forex_pair#204 IN (usdjpy,chfjpy,cadjpy,nzdjpy,sgdjpy), (quote_date#205 >= 20200601), isnotnull(forex_pair#204), dynamicpruningexpression(true), dynamicpruningexpression(true), dynamicpruningexpression(forex_pair#204 IN dynamicpruning#579)]
PushedFilters: [IsNotNull(quote_timestamp)]
ReadSchema: struct<quote_timestamp:string,bid_quote:float,ask_quote:float>
(7) Scan parquet default.mid_price_history
Output [4]: [quote_timestamp#388, mid_quote#389, quote_date#386, forex_pair#387]
Batched: true
Location: TahoeLogFileIndex [hdfs://k-deltalake/apps/spark/warehouse/mid_price_history]
PartitionFilters: [forex_pair#387 IN (usdjpy,chfjpy,cadjpy,nzdjpy,sgdjpy), (quote_date#386 >= 20200601), isnotnull(quote_date#386), isnotnull(forex_pair#387)]
PushedFilters: [IsNotNull(quote_timestamp)]
ReadSchema: struct<quote_timestamp:string,mid_quote:double>
===== Subqueries =====
Subquery:1 Hosting operator id = 1 Hosting Expression = forex_pair#204 IN dynamicpruning#579
ReusedExchange (22)
(22) ReusedExchange [Reuses operator id: 19]
Output [1]: [forex_pair#570]
この設定でSQLを実行結果を確認したところはSQLの実行時間が58.6秒に短縮することができました!
Skew joinsの設定
上記のSQLを実行した後に、Spark UIのDAGを確認したところは、大量データを持つquote_historyとmid_price_historyのSortMergeJoinタスクに実行時間が集中されてしまったことを確認できました。この2個テーブルが結合するときにコストの高いShuffleが発生してしまい、クラスタ上に作業分散のバランスが崩してしまったからです。Spark3.0とDeltaLakeはSkew joinの対応をサポートするので、効果があるか設定をやってみます。
# CoalesceはJoin Skew機能をブロックする恐れがあるので、coalesce避けておきます
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "false")
# Skew joinの閾値を設定する
spark.conf.set("spark.sql.shuffle.partitions", "20")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "2")
spark.conf.set("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "10KB")
# 以下の設定も必要です。 最適化するPartitionが小さすぎないように設定しておきます
spark.conf.set("spark.sql.adaptive.advisoryPartitionSizeInBytes", "1B")
Skew joinの設定完了ということでDataFrameのExplainを確認しましょう。
df_quotes.explain(mode="formatted")
== Physical Plan ==
* Project (24)
+- * SortMergeJoin Inner (23)
:- * Sort (16)
: +- Exchange (15)
: +- * Project (14)
: +- * SortMergeJoin Inner (13)
: :- * Sort (6)
: : +- Exchange (5)
: : +- * Project (4)
: : +- * Filter (3)
: : +- * ColumnarToRow (2)
: : +- Scan parquet default.quote_history (1)
: +- * Sort (12)
: +- Exchange (11)
: +- * Project (10)
: +- * Filter (9)
: +- * ColumnarToRow (8)
: +- Scan parquet default.mid_price_history (7)
+- * Sort (22)
+- Exchange (21)
+- * Project (20)
+- * Filter (19)
+- * ColumnarToRow (18)
+- Scan parquet default.forex_pairs (17)
SQLの実行時間が39.1秒になりました!良さそうですね。
Join Hints
Spark3.0はJoin hintsがさらに改善されました。Join Hintsにより、開発者はSparkが使う必要があるJoin方法を提案することができます。上記の実行プランを見るとforex_pairsが小さいテーブルですがSparkがSortMergeJoin方法で実行プランが作成されましたので、Broadcastに変更すると実行時間の短縮を期待できるかもしれないので、Join Hintをここで使いたいと思います。
def get_quote_by_pair_names(forex_pair_names, min_quote_date):
quote_query="""
select
/*+ BROADCAST(fp) */
qh.forex_pair,
qh.quote_timestamp,
qh.bid_quote,
qh.ask_quote,
mph.mid_quote
from
quote_history qh
inner join
mid_price_history mph
on qh.forex_pair=mph.forex_pair
and qh.quote_timestamp=mph.quote_timestamp
and qh.quote_date=mph.quote_date
inner join
forex_pairs fp
on
qh.forex_pair=fp.forex_pair
where
fp.forex_pair in ({forex_pairs})
and qh.forex_pair in ({forex_pairs})
and mph.forex_pair in ({forex_pairs})
and qh.quote_date >= '{quote_date}'
""".format(forex_pairs=forex_pair_names, quote_date=min_quote_date)
return exec_sql(quote_query)
実行プランを見ると、SortMergeJoinをBroadcastHashJoinになりました。
df_quotes.explain(mode="formatted")
== Physical Plan ==
* Project (21)
+- * BroadcastHashJoin Inner BuildRight (20)
:- * Project (14)
: +- * SortMergeJoin Inner (13)
: :- * Sort (6)
: : +- Exchange (5)
: : +- * Project (4)
: : +- * Filter (3)
: : +- * ColumnarToRow (2)
: : +- Scan parquet default.quote_history (1)
: +- * Sort (12)
: +- Exchange (11)
: +- * Project (10)
: +- * Filter (9)
: +- * ColumnarToRow (8)
: +- Scan parquet default.mid_price_history (7)
+- BroadcastExchange (19)
+- * Project (18)
+- * Filter (17)
+- * ColumnarToRow (16)
+- Scan parquet default.forex_pairs (15)
SQLの実行時間が28.6秒になりました!

今回はSpark3.0の一部新しい機能を使って実行したいSQL分の実行時間を短縮してみました。見事、4分前後のクエリは28.6秒に短縮することができました。まだまだチュニーニングすべきなところが多々あると思いますが、Spark3.0の使いやすさとSpark2系より改善された機能に驚きました。興味の方々是非使ってみてください。
それではまた!
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。