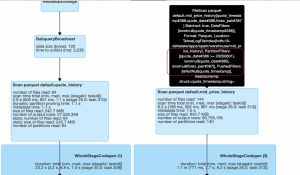
2021/01/07 Spark 3.0の新機能によるFXデータの抽出時間を短縮してみた Adaptive Query ExecutionAQEDeltaLakeDynamic Partition PruningForexFXHadoopJoin HintsPerformance TuningSparkspark 3.0パフォーマンスチューニングビッグデータ