2022.01.12
自然言語処理と時系列を考慮した推薦システムの関係(Transformer4Rec)
こんにちは。次世代システム研究室のT.Y.です。よろしくお願いします。
皆さん、推薦システム使っていますか?
ここで使っていないと答える方はほぼいないのではないでしょうか。
わかりやすいところではSNSや動画サイト、ECサイトで使われていますが、その他にもニュースサイトやインターネット上の広告など、気づかないうちに様々な場所で我々は情報を推薦されています。
そんな推薦システムですが、実は機械学習の分野で推薦システムは自然言語処理と深い関わりがあるという話があります。こう言うと、「ニュースとかSNSとか、テキストを含んだ情報を推薦するのだから当たり前では?」と思われる方もいるかもしれません。
確かにテキスト情報は推薦システムを構築するときによく使う情報で、テキスト情報を扱うときには自然言語処理は欠かせないのですが、今回のお話はそういう関わりの話ではありません。
今回の話は、自然言語処理の機械学習のネットワークと、推薦システムの中でも時系列を考慮した推薦システム(Sequential Recommender System)の機械学習のネットワークは解いている問題がとてもよく似ていると言う話です。
自然言語処理の機械学習の擬似タスク
自然言語処理とは、我々が日常会話で使っているような言語(自然言語)を数学的なモデルで表現し、単語の羅列である自然言語を、機械の処理に適した形、つまり数字の羅列に変換する処理です。自然言語処理を行う目的は、文章を自動で生成したいとか、文章から感情を分析したいといったことなので、自然言語処理を行う機械学習のネットワークの最終的なタスクは、単語や文章の入力に対して適切な文章を生成するとか文章から読み取れる感情を数値化して出力する、ということになります。
機械学習は、入力に対して、出力と、その出力を評価する関数を用意し、出力とその評価を最適な出力が得られるまで繰り返します。そのため、文章生成を例に挙げて考えると、まずは生成された文章が適切かどうかを評価する関数を設計することになりますが、これはなかなか難しいです。人間が見ればすぐわかりますが、文章が適切かどうかを数学的に定量的に判断するための関数を出せと言われると…人間の頭の中身はどうなっているんですかね? 評価関数が複雑だと、最適解を見つけるのが難しくなるので、できるだけシンプルにしたいです。そこで、「入力された単語や文章に対して適切な文章を生成する」という問題を解く代わりに「入力された単語や文章に対して、その次に来る単語を当てる」という問題を解くことを考えます。これならば、適当な文章の入力に対して出力された単語が実際の単語と同じか近い意味のものならOKというような評価をする関数を設計すればいいので、生成された文章全体を考慮するよりはだいぶ楽になりましたね。次に来る単語の出力を繰り返せば、文章を生成することができます。次に来る単語の予測が適切ならば、それを繰り返して得られた文章も適切だろうというわけです。(さすがに無理がある、という声が聞こえる気もしますが、実際にわりとまともな文章が生成できてしまうのです…)
このように本来の目的としている問題の代わりに、それを簡単にした問題を機械学習で解かせることで本来の目的を達成することはよく行われており、このような機械学習で実際に解いている方の問題を「疑似タスク」と言ったりします。
自然言語処理では、最終的な目的の前段階で文脈から単語の意味を学習していくので、文書生成以外でも、疑似タスクとして「次の単語を予測する」とか「文章中のある単語を周辺の単語から当てる」というようなタスクを解くことが多いです。
時系列を考慮した推薦システムの解いている問題、何かに似ていませんか?
推薦システムは、推薦を行うために使うデータによって色々なアプローチがありますが、大きく二つに大別されます。
一つは、ユーザやユーザに推薦するアイテムそのものの情報を使う方法です。ユーザの性別等の情報やアイテムのカテゴリ等の情報を使ってアイテムを推薦します。
もう一つは、ユーザとアイテムの関係を使う方法です。ユーザとアイテムの関係とは、ユーザがそのアイテムを見たり評価したり購入したりしたというような関係です。ユーザの行動によって蓄積されたユーザとアイテムの関係のデータを使って、ユーザが興味を示しそうなアイテムを推薦します。有名な手法は協調フィルタリング(あなたが購入した商品を買った人たちはこのような商品を買っています!というやつ)などがあります。
ユーザとアイテムの関係のデータは、具体的にはECサイト上のユーザの商品購入履歴といったものがあります。購入履歴は、ユーザに関係のあるアイテムの集合と見ても良いですが、だいたいユーザがアイテムを購入した時刻が使える、つまり、そこからわかるユーザがアイテムを購入した順序が使えるので、ユーザに関係のあるアイテムのシーケンスと見ることができます。アイテムの購入した順序を考慮することで、ユーザとアイテムの関係の時系列的な変化などを考慮した推薦システムを構築することができます。
このような時系列を考慮した推薦システムを機械学習で行うとき、機械学習のタスクは、「ユーザが購入したアイテムのシーケンスの次に来るアイテムを予測する」というタスクになります。
自然言語処理の疑似タスクとやっていることがだいぶ近いです。解いている問題が似ている気がしてきましたね。
しかしこれだけでは、ほとんど入出力が一緒という話ぐらいにしかなっていないので、もう少し似ているポイントを挙げていきます。
まず、次に来るものを予測するための仮定が似ています。自然言語処理で次の単語を予測するときは、「同じ文脈ならば、同様の単語が次に出現するだろう」という仮定のもとに予測をしています。推薦システムでは、「購入した商品が同様な人たちは、次に似たような商品を買うだろう」という仮定のもとに予測しています。また、自然言語処理のある単語とある単語が連続して出現しやすいという関係は、この商品とこの商品は一緒に買われやすいという関係に近いものがあります。自然言語処理と、時系列を考慮した推薦システムは、似たような関係を似たような仮定をおいてモデリングしているわけです。
自然言語処理の単語と推薦システムのアイテムの出現頻度の分布も似ています。自然言語処理に使うテキストデータ全体で各単語の出現回数をカウントすると、一部の単語が非常に多く出現し、その他の単語はあまり出現しないという分布になります。例えば「私」のような単語は全体で数百回使われているけど、「シーケンス」という単語は数回の使用に留まり、大半の単語は数回しか使われていないという結果になります。推薦システム上での、各アイテムの購入数の分布や閲覧数の分布も似たような形になります。一部の人気なアイテムの出現頻度が群を抜いて高く、その他のアイテムは一律に低いという分布です。SNSのバズった投稿と大半の投稿をイメージするとわかりやすいと思います。(このブログの各ページの閲覧数の分布もきっと…)
まとめると、似たような分布のデータで似たような仮定のもと同様の予測をしている、ということで、だいぶ問題として近いと言えるのではないでしょうか。
自然言語処理のアーキテクチャをもとにした推薦システムの手法
長々と話しましたが、自然言語処理のアーキテクチャをもとにした推薦システムの手法は図の通りに発表されており、問題設定として似ているというのは本当なんだろうなというのはこの図を見るとわかります。
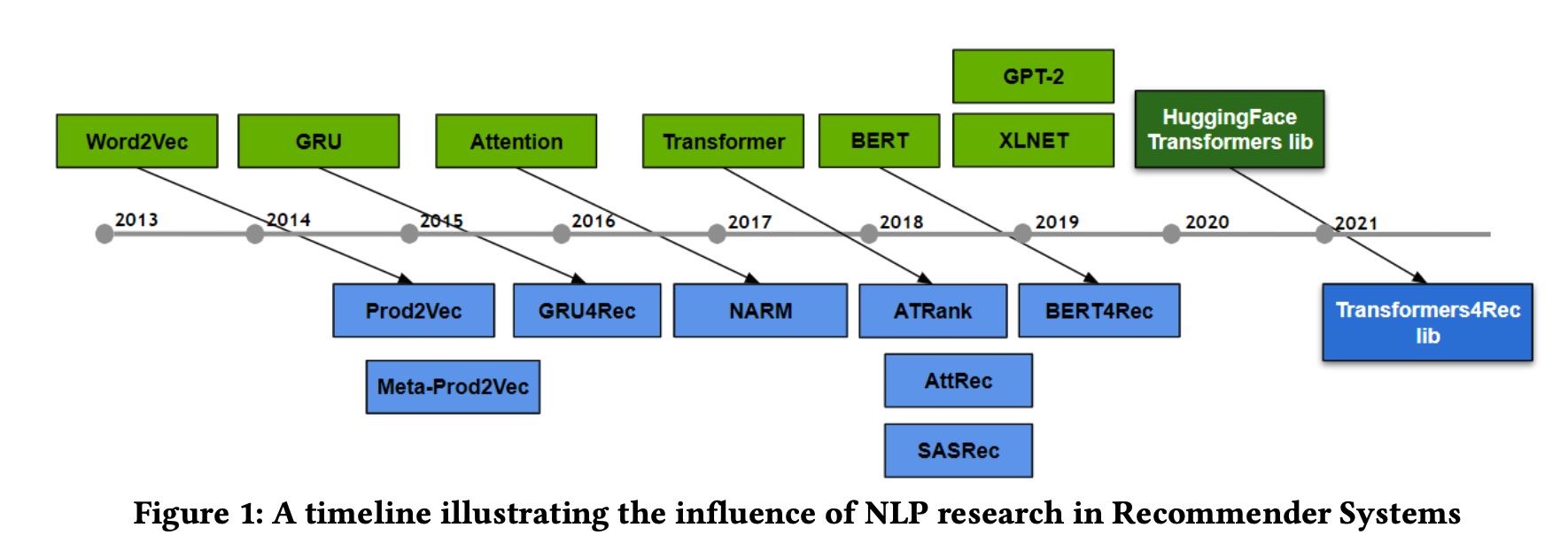
最初の手法はWord2VecをもとにしたProd2Vecです。Word2Vecは、文中である単語とある単語が連続して現れやすいなら近い関係にあるとする、というモデリングをする手法です。正直なところ、何かと何かの間に同様の共起する関係さえあれば適用できて、しかもそれで性能がそこそこいいという汎用性の塊だったので色々なところで使われたのですが、推薦システムでもしっかり有効でした。
Attentionは、とても簡単に言うと、シーケンスの中の大事な部分はどこかを学習して、その部分に補正をかけるというような手法で、時系列データを扱う機械学習モデルで非常に有効なものです。時系列を考慮する推薦システムでもやはり効きました。
BERTは…実は簡単にですが前回も説明していて、これを説明するのは大変なのでリンクを貼っておきます。日本語ALBERTのWord Embeddingsを考える
このような具合なので、画期的な自然言語処理の手法が出てくると推薦システムに適用できないかな…とみんな考えているとは思います。しかし、散々似ている似ていると言っていますが、推薦システムと自然言語処理にも異なるポイントはあるので、うまくそこを解消して自然言語処理のアーキテクチャを推薦システムに落とし込み適切なチューニングをして精度を出す、というのは誰にでもできることではないでしょう。
Transformer4Rec
Transformer4Recは、RecommenderSystemという推薦システムのトップ会議でNVIDIAのAIチームから発表された論文です。やっていることはシンプルで、Transformerを使った自然言語処理のアーキテクチャを推薦システムに適用してどの手法をどのように適用するのが良いか検証したというものですが、そのためのデータの前処理から学習、評価までをEnd-to-Endで行うパイプラインを実装していて、それが公開されています。データの前処理のあたりはNVIDIA NVTabularというライブラリでGPU高速化され効率化されており、モデルのアーキテクチャ部分はHugging faceで公開されているものを用いていて、複数のモデルを切り替えて試すことが容易なように設計されています。また、継続的な学習を行えるように設計されています。
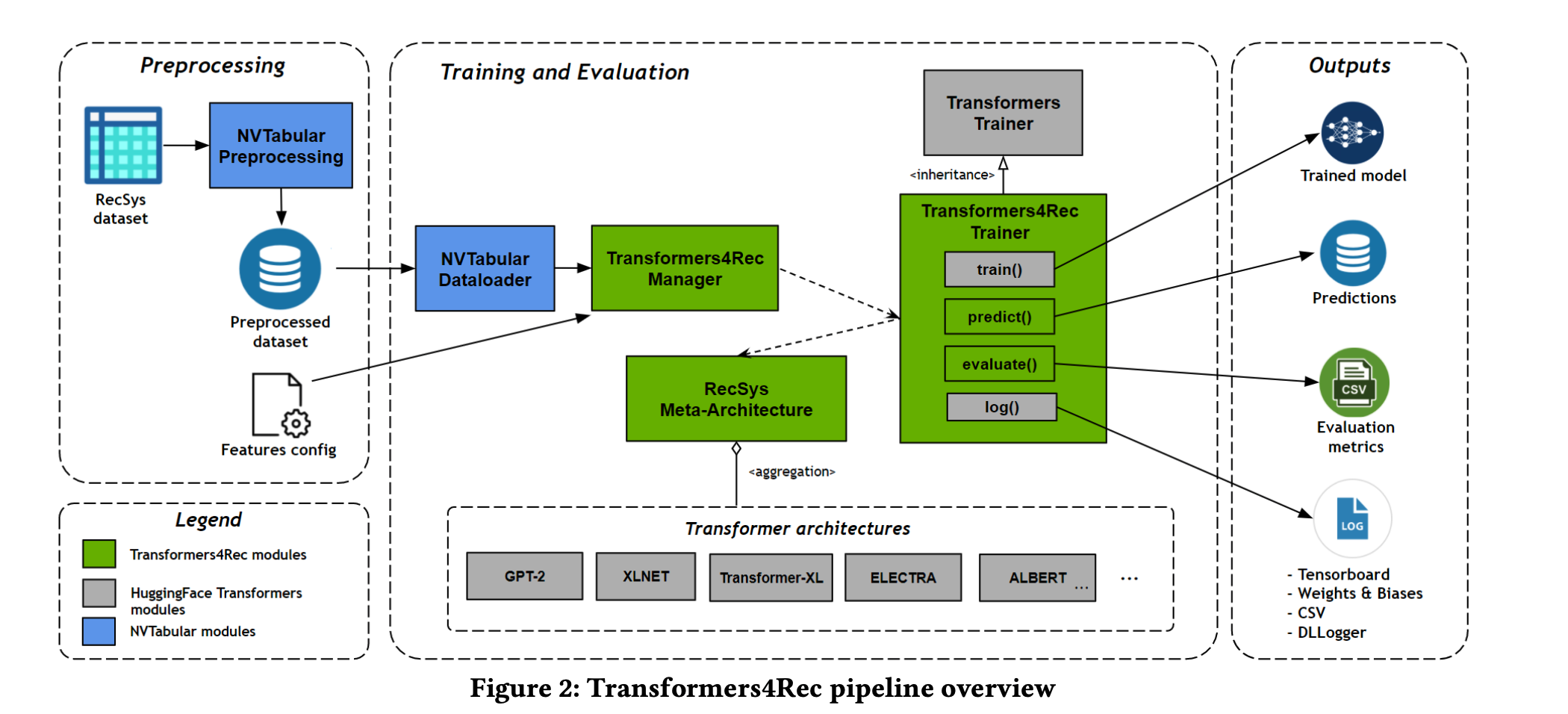
手法は一旦置いておいて、こちらの設計や実装が既にかなり参考になる気がしますね…
Transformer4Recのネットワークのアーキテクチャは以下の図のようになっています。
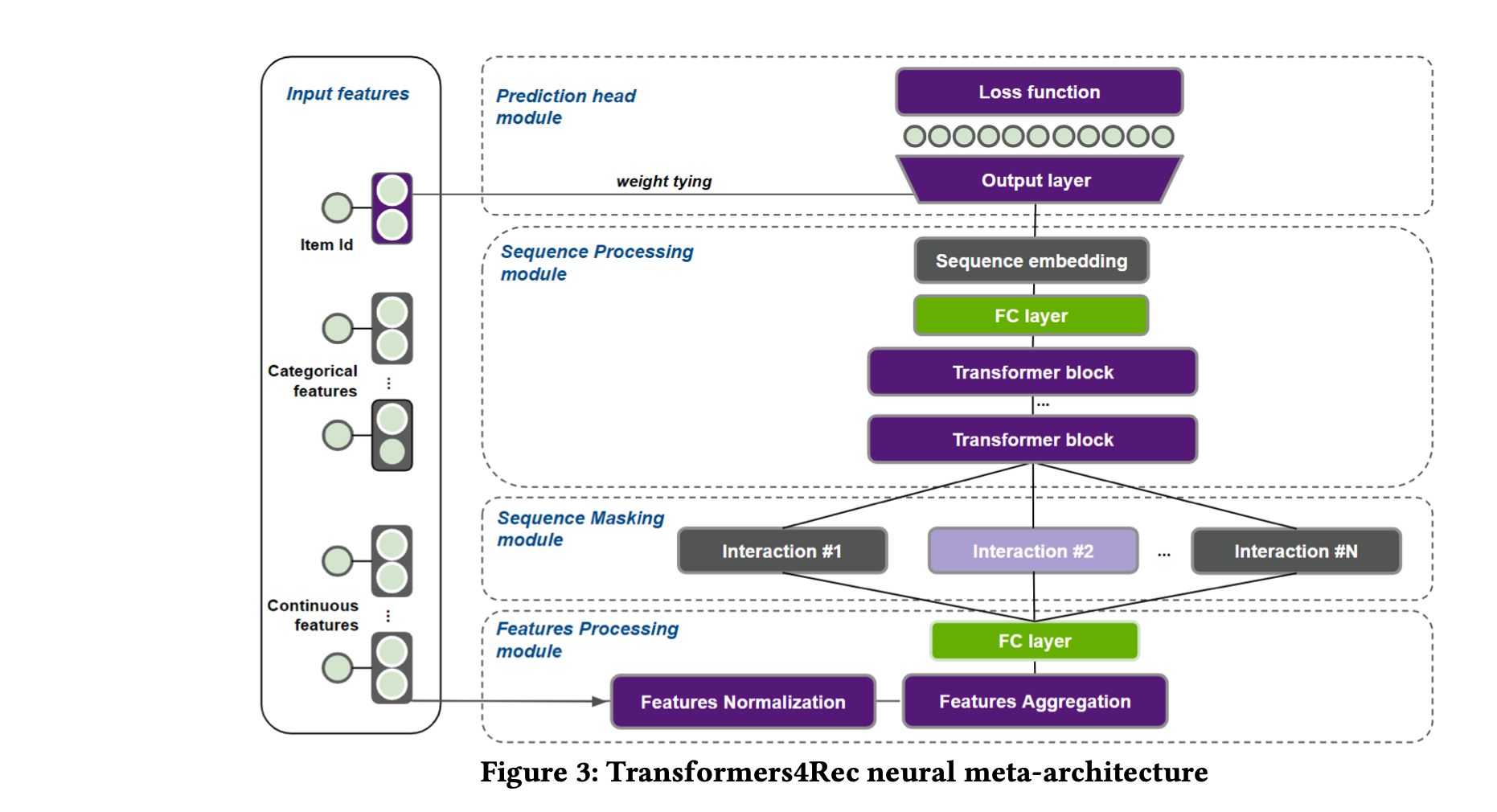
基本的にはTransfomerですが、推薦システムで使う上での精度向上の工夫として、入力するベクトルにアイテムのカテゴリなどのSide Informationをベクトル化して付加しています。
Side Informationのベクトル化にはSoft One Hot Encoding等を使い、それらは入力ベクトルにシンプルに結合するか要素積で付加されます。これがポイントで、自然言語処理と違い、推薦システムでは重要なSide Informationを考慮するようになっています。
また、アイテムのベクトル(Item Embeddings)は出力層の重みと共有されています。これはパラメータを減らし、学習を効率化するのが目的です。
評価はニュースの閲覧のデータセットとECサイトのデータセットで行っています。
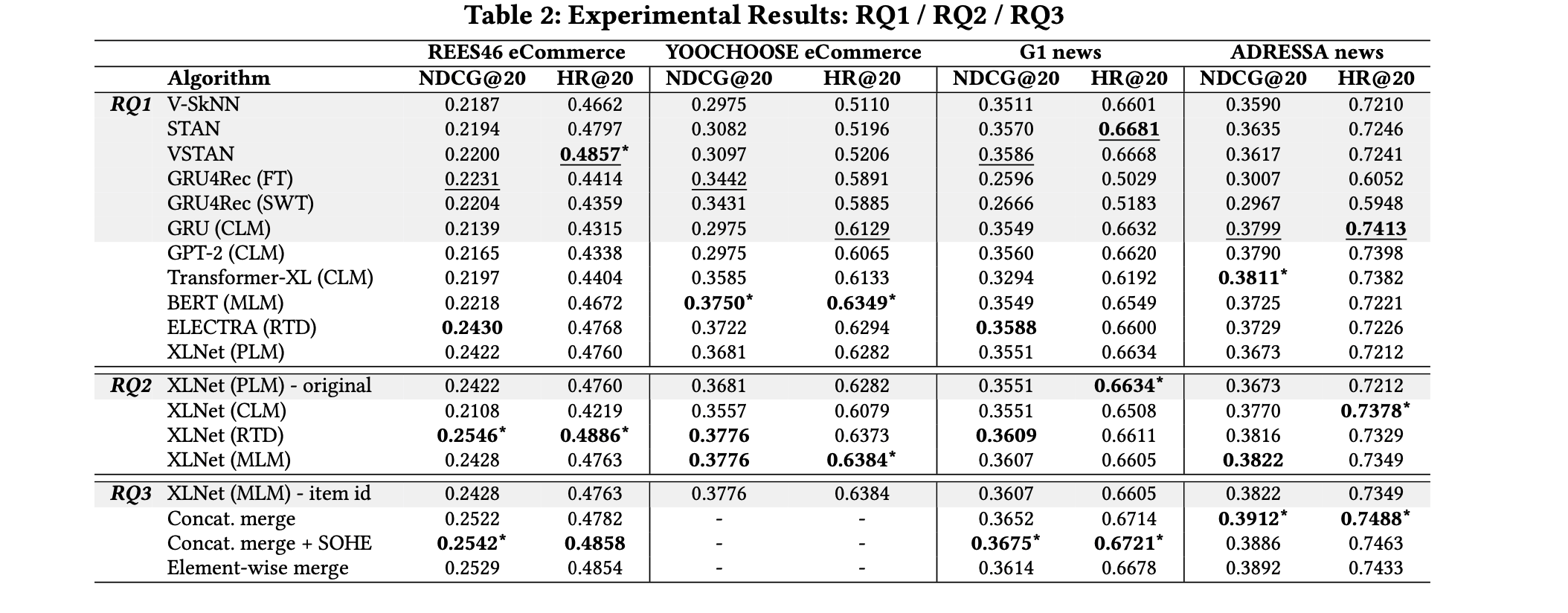
RQ1はTransformerのアーキテクチャとそれ以外のアーキテクチャを使った時の比較です。基本的にはTransformerのアーキテクチャの方が精度が良いようですが、どのTransformerのモデルが良いかはデータによるかもしれません。
RQ2はTransformerのトレーニングにどの疑似タスクを使うと良いかの評価です。結果を見ると、CLMよりはMLMの方が、双方向の時系列を考慮しやすいのか結果が良いようです。
RQ3はSide Informationの制度への影響の評価です。Side Infomationの効果はあるようですが、要素積より普通に結合するのが良さそうですね…
疑似タスクのイメージ図
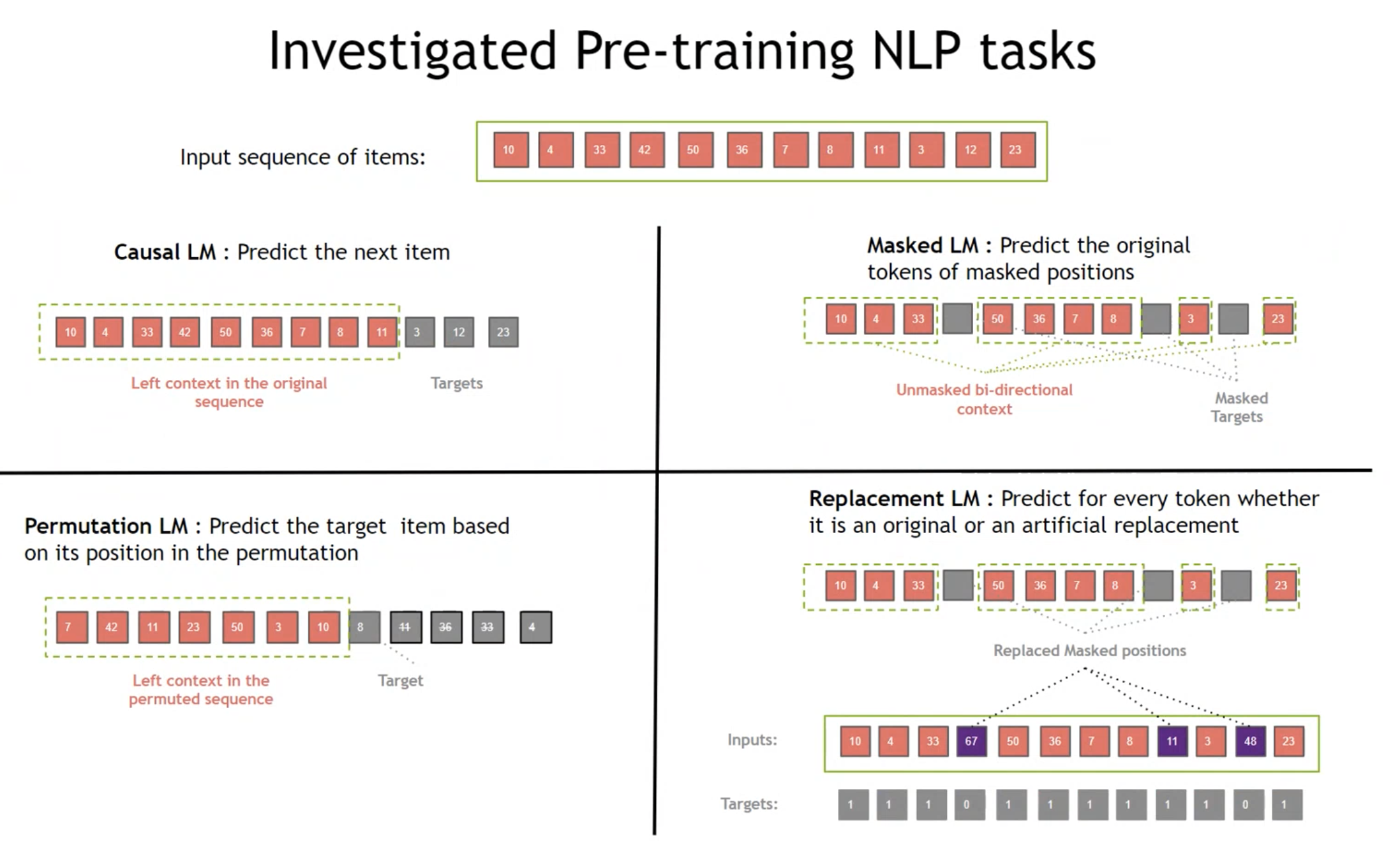
APIも整理されて使いやすそうではありますが、結局、Transformaerをトレーニングすることにはなるので、自分で試すとなると計算コストは高そうです。
参考
ALBERT: A Lite BERT for Self-supervised Learning of Language Representationshttps://arxiv.org/abs/1909.11942
BERT: Pre-training of Deep Bidirectional Transformers for Language Understandinghttps://arxiv.org/abs/1810.04805
Attention Is All You Need
https://arxiv.org/abs/1706.03762
Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendationhttps://dl.acm.org/doi/abs/10.1145/3460231.3474255
https://nvidia-merlin.github.io/Transformers4Rec/main/examples/tutorial/04-Inference-with-Triton.html
NVTabular https://github.com/NVIDIA-Merlin/NVTabular
最後に
Transformer4RecのチュートリアルはこちらでNVIDIAから動画が公開されています。https://www.youtube.com/watch?v=ajegb0W-JbU
またRecommenderSystemでの発表の動画は、公式のYoutubeに投稿される気がするので英語が苦手でなければそちらをどうぞ。
また、Huggingface Transformersで公開されているモデルにはオンラインデモが用意されているものもあります(Rinnaのオンラインデモ)。こちらも是非。
次世代システム研究室では、 Web アプリケーション開発を行うアーキテクトを募集しています。募集職種一覧からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD