2022.01.12
Androidで長いオーディオファイルやビデオファイルなどを音声認識してみた
こんにちは。次世代システム研究室のB.V.Mです。外国人で言葉遣いが間違いましたらご容赦ください。宜しくお願いします。
今期もAndroidアプリケーション開発することを経由して、GoogleクラウドAPIやGoogle Cloud Platform (GCP)など検証したいです。
前記: Google Translate APIを使用して、テキスト、音声ファイルを翻訳するのブログでGoogle Translate APIを使用してテキストや音声ファイルを翻訳してみました。
と:マイクからの入力などのストリーミングオーディオをテキストに変換する方法とターゲット言語に翻訳する方法を確認しました。
今回では、長いオーディオファイルやビデオファイルなどを音声認識してみた。
目次
1. 長い音声ファイルの文字変換について
注意1:長い音声ファイルとは
長い音声ファイル(1 分以上)をテキストに変換する場合:非同期音声認識方法が必要です。
60 秒以下の音声ファイル:同期音声認識(早くて簡単)
60 秒を超えるファイル:非同期音声認識(ちょっと複雑が長時間対応)
注意2:60 秒を超えるファイルを認識したいならGoogle Cloud Storage バケットにデータを保存する必要があります。
詳細:
音声コンテンツをローカル ファイルから Speech-to-Text に直接送信し、非同期処理を行うことができますが、ローカル ファイルの音声時間の上限は 60 秒です。
60 秒を超えるローカル音声ファイルを文字変換しようとすると、エラーが発生します。
注意3:結果は 5 日後(120 時間)まで取得できます。
オペレーションの結果は、google.longrunning.Operations メソッドを使用して取得できます。Google Cloud Storage バケットに結果を直接アップロードできます。
それでは今回はGoogle Cloud Storage に保存されたファイルを認識し認識している
2. Google Cloud Storage ファイルを用意する
2.1 Google Cloud Storage
Googleの定義により、Google Cloud Storage(GCS)はクラウドベースのビジネス向けストレージ サービス。すべて Google Cloud のインフラストラクチャで動作します。
2.2 Google Cloud Storageにてファイル権限修正
自分のbucketにアップロードして、ファイルアクセスできるように権限修正必要場合があります。
権限修正の例:
GCSのbucket管理画面
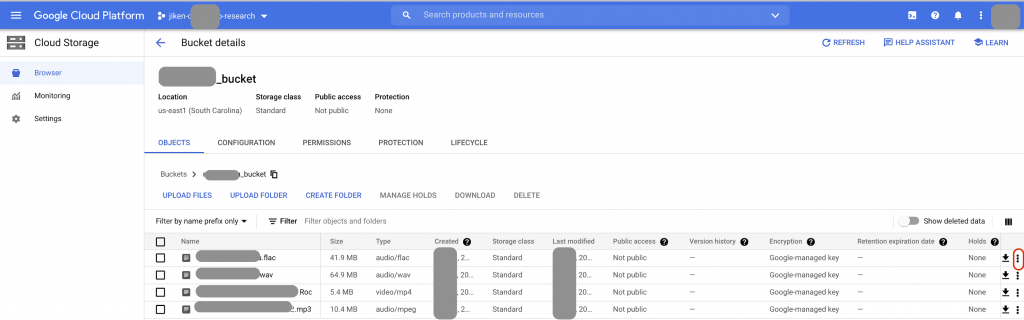
GCSのbucket管理画面でファイルを修正します。
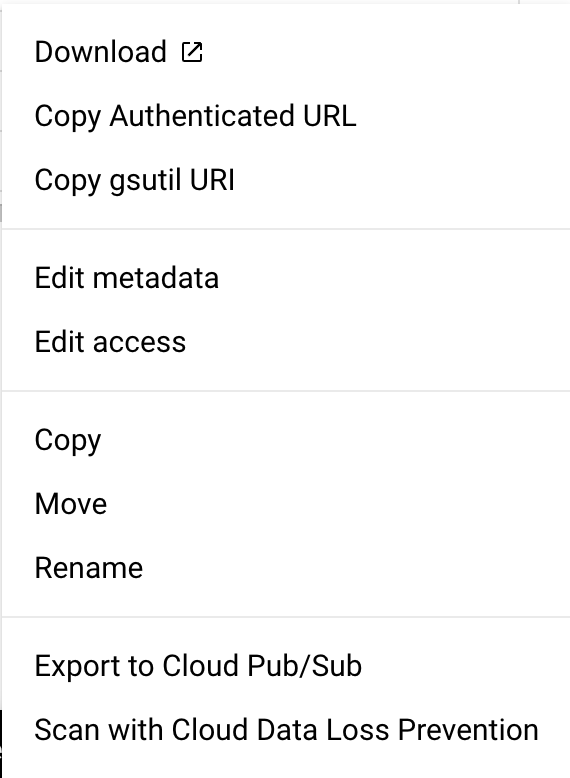
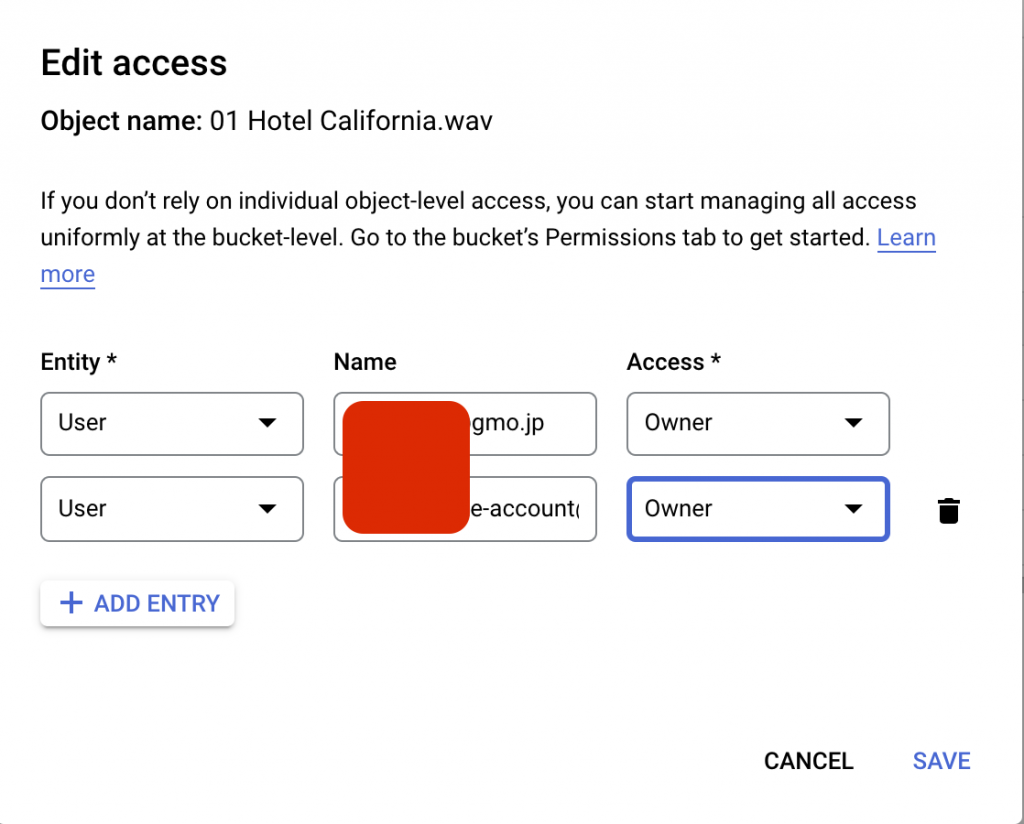
アカウントのメールアドレスを追加して、OwnerかReader権限付与できます。
3. 長い音声ファイルの認識
3.1 非同期処理
上記が書いたた通り、長い音声ファイル認識の時非同期処理が必要になります。
TimedRetryAlgorithmを初期化必要です。ポーリング操作をいつ実行するかを決定するために指数バックオフ係数を使用する、操作時限ポーリングアルゴリズム。 ポーリングが合計タイムアウトを超えると、このアルゴリズムはポーリングをキャンセルします。実装コードは下記のようになります。
private TimedRetryAlgorithm getTimedRetryAlgorithm() {
return OperationTimedPollAlgorithm.create(
RetrySettings.newBuilder()
.setInitialRetryDelay(Duration.ofMillis(1500L))
.setRetryDelayMultiplier(1.5)
.setMaxRetryDelay(Duration.ofMillis(50000L))
.setInitialRpcTimeout(Duration.ZERO) // ignored
.setRpcTimeoutMultiplier(1.0) // ignored
.setMaxRpcTimeout(Duration.ZERO) // ignored
.setTotalTimeout(Duration.ofHours(24L)) // set polling timeout to 24 hours
.build());
}
設定したパラメータ:
- InitialRetryDelay
- RetryDelayMultiplier
- MaxRetryDelay
- InitialRpcTimeout
- RpcTimeoutMultiplier
- MaxRpcTimeout
- TotalTimeout
非同期の処理
非同期の処理のため、この後この処理は新しいスレッドで実行させます。
public void asyncRecognizeGcs(String gcsUri, RecognitionConfig recognitionConfig) throws Exception {
// 資格情報をロードしてspeechSettingsを作成する
CredentialsProvider credentialsProvider = FixedCredentialsProvider.create(ServiceAccountCredentials.fromStream(getResources().openRawResource(R.raw.gg_credentials)));
SpeechSettings.Builder speechSettings = SpeechSettings.newBuilder().setCredentialsProvider(credentialsProvider);
// Configure polling algorithm
speechSettings.longRunningRecognizeOperationSettings().setPollingAlgorithm(getTimedRetryAlgorithm());
try (SpeechClient speechClient = SpeechClient.create(speechSettings.build())) {
RecognitionAudio audio = RecognitionAudio.newBuilder().setUri(gcsUri).build();
// 音声認識を取得するためにノンブロッキング呼び出しを使用する
OperationFuture<LongRunningRecognizeResponse, LongRunningRecognizeMetadata> response =
speechClient.longRunningRecognizeAsync(recognitionConfig, audio);
// 処理完了まで待ちます。
while (!response.isDone()) {
System.out.println("Waiting for response...");
Thread.sleep(10000);
}
System.out.println("response.isDone");
List results = response.get().getResultsList();
StringBuilder translatedResult = new StringBuilder();
for (SpeechRecognitionResult result : results) {
for (SpeechRecognitionAlternative alternative : result.getAlternativesList()) {
System.out.printf("Transcription: %s\n", alternative.getTranscript());
translatedResult.append(alternative.getTranscript() + "\n");
}
}
// 結果テキストに反映します。
resultTextView.setText(translatedResult.toString());
}
}
3.2 ファイルにより設定フォマットが適切に設定
MP3フォマットファイルを翻訳する場合
今回は私の母語の童話を自分で録音して、認識してみました。このファイルは08分16秒、7.6 MB、MP3ファイルです。
translateButton.setOnClickListener(v -> {
(new Thread(new Runnable() {
@Override
public void run() {
// EditTextが変更されない場合デフォルト値を使用する
String gcsUri = "";
if (gcsUriEditText.getText().toString().equals("") || gcsUriEditText.getText().toString().equals(getString(R.string.gcs_uri_translate))) {
gcsUri = "gs://***/***.mp3"; // デフォルトに童話を認識する
} else {
gcsUri = gcsUriEditText.getText().toString();
}
String languageCode = "en-us";
System.out.println("gcsUri: " + gcsUri);
RecognitionConfig configForMP3 =
RecognitionConfig.newBuilder()
// encoding may either be omitted or must match the value in the file header
.setEncoding(RecognitionConfig.AudioEncoding.MP3)
.setLanguageCode(languageCode)
.setSampleRateHertz(sampleRateHertz)
// .setModel("video")
.build();
try {
asyncRecognizeGcs(gcsUri, configForMP3);
} catch (Exception e) {
e.printStackTrace();
}
}
})).start();
});
ビデオの音声を認識、翻訳する場合setModelところでvideoモデルを設定したらより効果が出ますが、お金もかかると説明がありました。私もvideoモデルを設定してvideoファイルを認識してみましたが、あまり変化がないのでここに記載致しません。
Flacフォマットファイルを翻訳する場合
RecognitionConfigのaudio_channel_countは指定されていないか、FLACヘッダーの値と一致している必要があります。そうしないと下記のエラーが出ます。
INVALID_ARGUMENT: audio_channel_count `1` in RecognitionConfig must either be unspecified or match the value in the FLAC header `2`.
下記はFlacファイルのRecognitionConfigの例です:
// Configure remote file request for FLAC
RecognitionConfig configForFlac =
RecognitionConfig.newBuilder()
.setEncoding(RecognitionConfig.AudioEncoding.FLAC)
.setLanguageCode(languageCode)
.setSampleRateHertz(sampleRateHertz)
.setAudioChannelCount(2) // FLAC の場合注意必要な設定です。
.build();
3.3 結果
今回は母語の童話のを認識してみました。
下記のビデオは左の方はログが出るところです。右の方はAndroid端末のシミュレーターです。
4. 感想
長い音声ファイルを認識してくれました。長いテキストの結果ももらいました。結果が結構正しいですが、精度の方はそんなに高くないかと思います。間違っているところはまだあります。そして音声ファイルにより、自分が聞くの時は問題ないです(母語だから?)が、認識結果はあまりできていない場合もあります。モデルはまだよくないか、設定はまだ適切にできていないかそれとも準備していたファイルの事態が良くないかいろんな原因があるかと思います。精度を上がるようもっと頑張らなきゃと思います。
参考リンク
- https://cloud.google.com/speech-to-text/docs/async-recognize
- https://cloud.google.com/speech-to-text
- https://cloud.google.com/translate/media/docs/best-practices
最後に
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。 皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD