2021.10.08
Google Cloud Speech-to-Text APIを使用してAndroidで音声登録とストリーミング音声認識してみた
こんにちは。次世代システム研究室のB.V.Mです。外国人で言葉遣いが間違いましたらご容赦ください。宜しくお願いします。
今期もAndroidアプリケーション開発することを経由して、GoogleクラウドAPIやGoogle Cloud Platform (GCP)など体験したいです。
前記: Google Translate APIを使用して、テキスト、音声ファイルを翻訳するのブログでGoogle Translate APIを使用してテキストや音声ファイルを翻訳してみました。
今回では、マイクからの入力などのストリーミングオーディオをテキストに変換する方法とターゲット言語に翻訳する方法を確認してみました。
目次
1.Google Cloud Speech-to-Text API
Google Cloud Speech-to-Text APIを使用すると、音声をSpeech-to-Textにストリーミングし、音声が処理されるときにストリーム音声認識の結果をリアルタイムで受信できます。詳細はこちらで確認してください。
もちろん音声制限もあります。詳細はストリーミング音声認識要求の音声制限も参照してください。 ストリーミング音声認識は、gRPCを介してのみ利用できます。
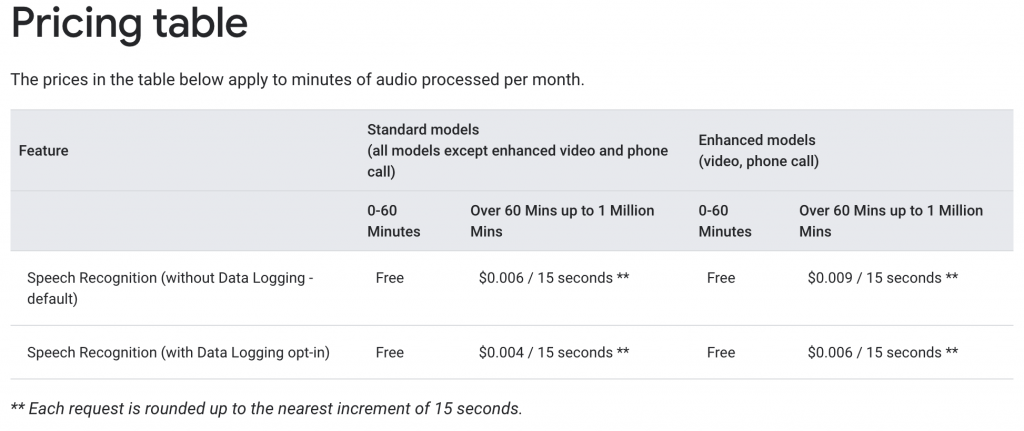
価格
結論ファースト:テスト用のためあまり使用していないので、気軽く使用できそうです。
たくさん使用する場合:下記の表で参照してください。
音声制限
Content Limits

Request Limits

2. マイクから録音機能追加
2.1 音声ファイルのタイプ
Googleのサンプルによりjavax.sound.sampledのTargetDataLineを使用しています。でも残念ながらjavax.sound.sampledはAndroidアプリがサポートしていません。ですので他の方法で録音するようになります。
Androidで音声録音するときMediaRecorderとAudioRecordがあります。
MediaRecorderの方はTHREE_GPP、MPEG_4、RAW_AMRなどサポートしています。
AudioRecordの方はENCODING_PCM_8BIT、ENCODING_PCM_16BIT、ENCODING_PCM_FLOAT、ENCODING_PCM_24BIT_PACKED、ENCODING_PCM_32BITなどサポートしています。
Googleサイトのベストプラクティスにより
・ロスレスコーデックを使用して、オーディオを録音および送信します。 FLACまたはLINEAR16をお勧めします。
・ストリーミング応答の待ち時間を長くするには、LINEAR16コーデックを使用します。
ここで少し迷ってしまいましたことがありますが、しばらく調べるとENCODING_PCM_16BITとLINEAR16実は1つです。
ですのでAudioRecord利用してENCODING_PCM_16BITで録音します。
ENCODING_PCM_16BITについて: オーディオサンプルは、通常、Javaのshortとしてshort配列に格納される16ビットの符号付き整数ですが、shortがByteBufferに格納される場合、ネイティブエンディアンです(デフォルトのJavaビッグエンディアンと比較して)。 ショートは[-32768、32767]からの全範囲を持つという定義があります。
2.2 音声を録音、再生
writeAudioDataToFile()関数を利用して、別のスレッドで音声データを録音します。
private void recordWithAudioRecord() {
// 可視性のために外部キャッシュディレクトリに記録する
fileName = getExternalCacheDir().getAbsolutePath() + "/test.pcm";
try {
isRecording = true;
recordingThread = new Thread(new Runnable() {
public void run() {
writeAudioDataToFile();
}
}, "AudioRecorder Thread");
recordingThread.start();
if (transcript != null && resultTextView != null) {
resultTextView.setText(transcript);
}
} catch (Exception e) {
e.printStackTrace();
}
}
音声ファイルを録音する時下記のような定義必要です。
SAMPLING_RATE: 44100 → 一秒で44,100サンプルを取得します。
RECORDER_CHANNELS: CHANNEL_IN_MONO → オーディオチャンネル
AUDIO_ENCODING: ENCODING_PCM_16BIT → 上記の音声ファイルのタイプのところに記載いたしました。
private static final int SAMPLING_RATE = 44100;
private static final int RECORDER_CHANNELS = AudioFormat.CHANNEL_IN_MONO;
private static final int AUDIO_ENCODING = AudioFormat.ENCODING_PCM_16BIT;
下記のコードでファイルに録音できます
private void writeAudioDataToFile() {
try {
// 出力オーディオをバイト単位で書き込む
int bufferSizeInBytes = AudioRecord.getMinBufferSize(SAMPLING_RATE, RECORDER_CHANNELS, audioFormat);
byte[] audioData = new byte[bufferSizeInBytes];
dataOutputStream = new FileOutputStream(fileName);
audioRecorder = new AudioRecord(
MediaRecorder.AudioSource.MIC,
SAMPLING_RATE,
RECORDER_CHANNELS,
audioFormat,
bufferSizeInBytes);
audioRecorder.startRecording();
while (isRecording) {
int numberOfShort = audioRecorder.read(audioData, 0, bufferSizeInBytes);
} catch (IOException e) {
e.printStackTrace();
}
}
dataOutputStream.close();
} catch (IOException | OutOfRangeException e) {
e.printStackTrace();
}
}
録音したファイルから再生したいときstartPlaying関数を使います。
private void startPlaying() {
try {
int bufSize = android.media.AudioTrack.getMinBufferSize(SAMPLING_RATE, AudioFormat.CHANNEL_OUT_MONO, AUDIO_ENCODING);
audioTrack = new AudioTrack.Builder()
.setAudioAttributes(new AudioAttributes.Builder()
.setUsage(AudioAttributes.USAGE_VOICE_COMMUNICATION)
.setContentType(AudioAttributes.CONTENT_TYPE_SPEECH)
.build())
.setAudioFormat(new AudioFormat.Builder()
.setEncoding(AUDIO_ENCODING)
.setSampleRate(SAMPLING_RATE)
.setChannelMask(AudioFormat.CHANNEL_OUT_MONO)
.build())
.setBufferSizeInBytes(bufSize)
.build();
byte[] wavData = getBytesDataByActualFilePath(fileName);
// 再生する
audioTrack.play();
// ヘッダ44byteを抜かす
audioTrack.write(wavData, 44, wavData.length - 44);
} catch (IOException e) {
Log.e(LOG_TAG, "IOException: " + fileName + ": \n" + e.getMessage());
}
}
3 ストリーム音声認識
ストリーム音声認識したい時上記のwriteAudioDataToFileの中に録音しながらGCPにリクエストを投げます。
主要な手順は、簡単にまとめると下記のようになります。詳細はこちらをご覧ください。
- Media Translation にリクエストを送信するために使用する
ServiceClientクライアントを初期化します。同じクライアントは複数のリクエストに再利用できます。 - 音声の処理方法を指定する
SpeechConfigリクエスト オブジェクトを作成します。 StreamingSpeechRequestリクエスト オブジェクトのシーケンスを送信します。StreamingSpeechResultレスポンス オブジェクトを受け取ります。- ストリーミングには 5 分間の制限があります。この制限を超えると、OUT_OF_RANGE エラーが返されます。
3.1 初期設定
手順1と2を展開します。
private ClientStream<StreamingRecognizeRequest> initRecognizeClientStream() throws IOException {
RecognitionConfig recognitionConfig =
RecognitionConfig.newBuilder()
.setEncoding(RecognitionConfig.AudioEncoding.LINEAR16)
.setLanguageCode("en-US")
.setSampleRateHertz(SAMPLING_RATE)
.build();
CredentialsProvider credentialsProvider = FixedCredentialsProvider.create(ServiceAccountCredentials.fromStream(getResources().openRawResource(R.raw.gg_credentials)));
// 1. ServiceClientクライアントを初期化する
SpeechClient speechClient = SpeechClient.create(SpeechSettings.newBuilder().setCredentialsProvider(credentialsProvider).build());
ResponseObserver<StreamingRecognizeResponse> responseObserver = getResponseObserver();
ClientStream<StreamingRecognizeRequest> clientRecognizeStream =
speechClient.streamingRecognizeCallable().splitCall(responseObserver);
// 2. 音声の処理方法を指定するstreamingRecognitionConfigを作成する。
StreamingRecognitionConfig streamingRecognitionConfig =
StreamingRecognitionConfig.newBuilder().setConfig(recognitionConfig).build();
// ストリーミング呼び出しの最初のリクエストは設定である必要がある
StreamingRecognizeRequest requestRecognize =
StreamingRecognizeRequest.newBuilder()
.setStreamingConfig(streamingRecognitionConfig)
.build();
clientRecognizeStream.send(requestRecognize);
return clientRecognizeStream;
}
手順4のレスポンス オブジェクトを受け取ります。
private ResponseObserver<StreamingRecognizeResponse> getResponseObserver() {
return new ResponseObserver<StreamingRecognizeResponse>() {
ArrayList<StreamingRecognizeResponse> responses = new ArrayList<>();
public void onStart(StreamController controller) {
}
// 4. StreamingTranslateSpeechResultレスポンス オブジェクトを受け取る
public void onResponse(StreamingRecognizeResponse response) {
System.out.println("responses.add(response): " + response.toString());
responses.add(response);
}
public void onComplete() {
System.out.println("onComplete");
for (StreamingRecognizeResponse response : responses) {
StreamingRecognitionResult result = response.getResultsList().get(0);
// 最初の選択肢は最も可能性結果
SpeechRecognitionAlternative alternative = result.getAlternativesList().get(0);
System.out.printf("Transcript : %s\n", alternative.getTranscript());
}
}
public void onError(Throwable t) {
System.out.println(t);
}
};
}
3.2 処理
2.2のwriteAudioDataToFile()関数にリクエスト送信コードを追加します。
while (isRecording) {
int numberOfShort = audioRecorder.read(audioData, 0, bufferSizeInBytes);
try {
long estimatedTime = System.currentTimeMillis() - startTime;
dataOutputStream.write(audioData, 0, bufferSizeInBytes);
// 3. requestRecognizeリクエストオブジェクトのシーケンスを送信する
StreamingRecognizeRequest requestRecognize =
StreamingRecognizeRequest.newBuilder()
.setAudioContent(ByteString.copyFrom(audioData))
.build();
clientRecognizeStream.send(requestRecognize);
System.out.println("clientStream.send(request) . audioData length: " + audioData.length);
if (estimatedTime > 2000) { // 2 seconds
System.out.println("Stop speaking.");
stopRecording();
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
3.3 結果
英語で「set alarm after ten minutes」と言いましたら、プログラムのログからちゃんと「set alarm after 10 minutes」がもらっています。
正確度は0.9026232(90.2%)になります。
I/System.out: responses.add(response): results {
alternatives {
transcript: "set alarm after 10 minutes"
confidence: 0.9026232
}
is_final: true
result_end_time {
seconds: 1
nanos: 890000000
}
}
5: {
1: 15
}
間違って認識した場合もありました。
I/System.out: alternatives {
transcript: "set alarm 4:30 a.m."
confidence: 0.744931
}
is_final: true
result_end_time {
seconds: 1
nanos: 910000000
}
}
5: {
1: 15
}
エラー発生:
I/System.out: responses.add(response): error {
code: 11
message: "Audio Timeout Error: Long duration elapsed without audio. Audio should be sent close to real time."
}
音声がリアルタイムでないと上記のエラーが発生するのがわかりました。
4 ストリーム音声翻訳
上記の処理と大体同じですが
StreamingRecognizeRequest
代わりに
StreamingTranslateSpeechRequest
を使用します。
もちろん、今度は翻訳ですがターゲット言語設定も必要です。
4.1 初期設定
手順1と2を展開します。
private ClientStream initClientTranslateStream() throws IOException {
CredentialsProvider credentialsProvider = FixedCredentialsProvider.create(ServiceAccountCredentials.fromStream(getResources().openRawResource(R.raw.gg_credentials)));
// 1. ServiceClientクライアントを初期化する
SpeechTranslationServiceClient speechTranslationClient = SpeechTranslationServiceClient.create(SpeechTranslationServiceSettings.newBuilder().setCredentialsProvider(credentialsProvider).build());
ResponseObserver responseTranslateObserver = getTranslateResponseObserver();
ClientStream clientTranslateStream =
speechTranslationClient.streamingTranslateSpeechCallable().splitCall(responseTranslateObserver);
// 2. 音声の処理方法を指定するSpeechConfigリクエスト オブジェクトを作成する
TranslateSpeechConfig audioConfig =
TranslateSpeechConfig.newBuilder()
.setAudioEncoding("linear16")
.setSourceLanguageCode("en-US")
.setTargetLanguageCode("ja") // ターゲット言語設定する
.setSampleRateHertz(SAMPLING_RATE)
.build();
StreamingTranslateSpeechConfig streamingTranslateConfig =
StreamingTranslateSpeechConfig.newBuilder().setAudioConfig(audioConfig).build();
// 3. peechRequestリクエスト オブジェクトのシーケンスを送信する
// ストリーミング呼び出しの最初のリクエストは設定である必要があります
StreamingTranslateSpeechRequest requestTranslate =
StreamingTranslateSpeechRequest.newBuilder()
.setStreamingConfig(streamingTranslateConfig)
.build();
clientTranslateStream.send(requestTranslate);
return clientTranslateStream;
}
手順4のレスポンス オブジェクトを受け取ります。
private ResponseObserver getTranslateResponseObserver() {
return new ResponseObserver() {
@Override
public void onStart(StreamController controller) {
}
// 4. StreamingTranslateSpeechResultレスポンス オブジェクトを受け取る
@Override
public void onResponse(StreamingTranslateSpeechResponse response) {
StreamingTranslateSpeechResult res = response.getResult();
String translation = res.getTextTranslationResult().getTranslation();
String source = res.getRecognitionResult();
if (res.getTextTranslationResult().getIsFinal()) {
System.out.println(String.format("\nFinal translation: %s", translation));
System.out.println(String.format("Final recognition result: %s", source));
} else {
System.out.println(String.format("\nPartial translation: %s", translation));
System.out.println(String.format("Partial recognition result: %s", source));
}
}
@Override
public void onError(Throwable t) {
System.out.println(t);
}
@Override
public void onComplete() {}
};
}
4.2 処理
2.2のwriteAudioDataToFile()関数にリクエスト送信コードを追加します。
while (isRecording) {
int numberOfShort = audioRecorder.read(audioData, 0, bufferSizeInBytes);
try {
long estimatedTime = System.currentTimeMillis() - startTime;
dataOutputStream.write(audioData, 0, bufferSizeInBytes);
// 3. requestTranslateリクエストオブジェクトのシーケンスを送信する
StreamingTranslateSpeechRequest requestTranslate =
StreamingTranslateSpeechRequest.newBuilder()
.setAudioContent(ByteString.copyFrom(audioData))
.build();
clientTranslateStream.send(requestTranslate);
if (estimatedTime > 2000) { // 2秒
System.out.println("Stop speaking.");
stopRecording();
break;
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.3 結果
英語で「set alarm after five minutes」と言いましたら、プログラムのログ確認するとPartial translationとFinal translationは同じく「5分後にアラームを設定します。」がもらいました。
I/System.out: Partial translation: 5分後にアラームを設定します。 I/System.out: Partial recognition result: I/System.out: Partial translation: 5分後にアラームを設定します。 Partial recognition result: I/System.out: Final translation: 5分後にアラームを設定します。
エラー発生:
I/System.out: com.google.api.gax.rpc.OutOfRangeException: io.grpc.StatusRuntimeException: OUT_OF_RANGE: Audio Timeout Error: Long duration elapsed without audio. Audio should be sent close to real time. I/System.out: com.google.api.gax.rpc.OutOfRangeException: io.grpc.StatusRuntimeException: OUT_OF_RANGE: Timeout between requests
前回と大体同じエラーが出ました。タイムアウトエラーも出ますので、タイムアウトしないように注意必要です。
5 感想
Googleでのサンプルにjavaxを使用して、別の方法を使用するようにかなり苦労しました。でも、Google Cloud Speech-to-Text APIが使用でいるのは良い点だと思われます。次回、もっと詳しく調査していきたいと思います。
参考リンク
- https://cloud.google.com/translate/media/docs/streaming/
- https://cloud.google.com/speech-to-text
- https://cloud.google.com/translate/media/docs/best-practices
最後に
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。 皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





