2021.10.08
新人研修でマスターするDBのパフォーマンスチューニング
D. M. です。今回は新人研修で扱う DB のパフォーマンスチューニングについてのお話です。
この記事を書こうと思ったキッカケ
私はここ数年新人やインターンの学生のメンターをよく担当しているのですが、学生と会社員エンジニアの間にはデータベース( RDB )の知見に大きな溝があると感じています。
研修で「とりあえずサービスを作ってみよう!」という課題を出すと、最近の新卒の方は平均的なレベルが高く、いいアイディアでさらっと Web サイトを立ち上げることができます。
ただそのサイトが毎日 100 万人が使うことを想定して充分なチューニングができる人は新人段階ではほんのわずかです。毎回同じようなことを指摘するのですが、特に多いのが DB 関連です。多くの方が DB の経験がほとんどなくあまり扱えないのです。コンピュータサイエンス専攻出身の方はプログラミングスキルをはじめとした技術的な知見を持っているものの、 DB については何となく触れたことがある程度というのが大半なので、学生と開発現場とのギャップを最も感じます。
最近はマネージドなクラウドの利用が一般的になり、 Firebase などで簡単にサイトが立ち上げられますが、がっつりしたシステムを開発するとなるとやっぱり汎用性の高い DB は避けて通ることができません。ほぼ全システムが DB を前提にしているのでここがわかっていないと業務にならない。なので研修でも重要な項目として扱われます。
基本的な知識はググると大量の記事が出てきますしそのレベルではあまり差がつかないので、今回は私が研修中によく取り扱っている DB のチューニングの課題を紹介します。
結論
・最低限の理解としてクエリチューニングではインデックスとメモリがある。
・MySQL Workbench の Visual Explain でインデックスの利用とクエリのコストを確認する。
・インデックスオンリースキャンを狙ってみる。
・innodb_buffer_pool_size パラメータにメモリの8割を充てる。
対象者
・Web エンジニリングに関わる若手で DB を少し触れたが、インデックスがよくわかっていない人。
・研修で扱われる DB の実践的な課題が知りたい人。
DB のパフォーマンスにフォーカスする意義
DB ができると Web 開発者として安定的なバリューを出すことができます。
私はいわゆるサーバサイエンジニアとしてずっと業務をしていて、小さめなシステムでは包括的に全体を設計開発運用するため MySQL の管理、サーバの VM の設定も担当しますが、 Web 系システムのパフォーマンス=クエリのパフォーマンスと言えるほど DB の問題は頻出かつクリティカルです。さらに言うと大半の問題はインデックスとメモリのパラメータで解決できると感じています。なのでこの記事では Select 文を高速化することに特化し、チューニングを学ぶうえで1番初めに取り組むべき課題を記載します。
ここからは具体的な課題で理解を深めていきましょう。
課題
あなたは1年前に TODO を管理する Web アプリケーションをリリースした。
順調にユーザが伸びて現在は利用者10万人、1人あたりの TODO が100個ある状態になっている。
(つまり user テーブル10万レコード。 todo テーブル1000万レコードあるとする)
管理画面で可視化するために以下の SQL を書いてほしい。
「過去2か月間に登録したユーザが登録した TODO におけるステータス Todo, Doing, Done の割合を求める。」
環境は MySQL 8.0 を使用するものとする。
テーブル定義のER図
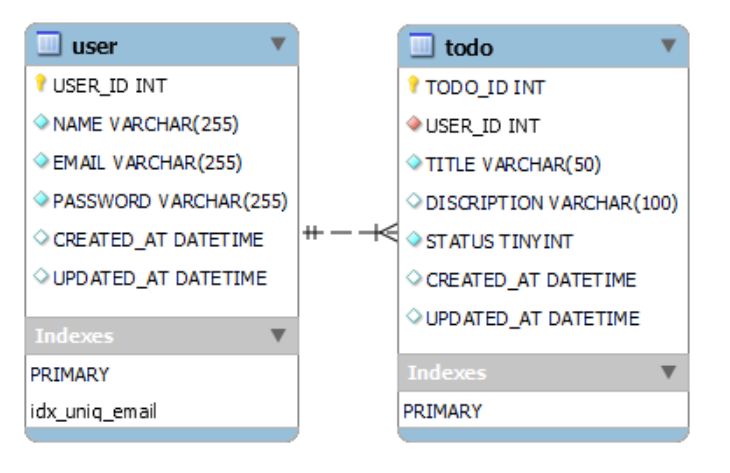
user テーブルと todo テーブルには過去1年間の日付でランダムにデータを入れています。
またステータスは todo テーブルの status カラムに Todo = 1 , Doing = 2, Done = 3 として登録されています。
この課題の目的はローカルで素の MySQL を立ち上げてクエリを書き、速度に関するチューニングを行うことです。
課題データ登録用クエリ。テーブルのCreate文、データのInsert文(折り畳んであります)
CREATE DATBASE todoDB
userテーブル作成 CREATE TABLE `user` ( `USER_ID` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'ユーザID', `NAME` varchar(255) NOT NULL COMMENT 'ユーザ名', `EMAIL` varchar(255) NOT NULL COMMENT 'メールアドレス', `PASSWORD` varchar(255) NOT NULL COMMENT 'パスワード', `CREATED_AT` datetime DEFAULT NULL COMMENT '作成日時', `UPDATED_AT` datetime DEFAULT NULL COMMENT '更新日時', PRIMARY KEY (`USER_ID`), UNIQUE KEY `idx_uniq_email` (`EMAIL`) ) ENGINE=InnoDB CHARSET=utf8
todoテーブル作成 CREATE TABLE `todo` ( `TODO_ID` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'TODO ID', `USER_ID` int unsigned NOT NULL COMMENT 'ユーザID', `TITLE` varchar(50) NOT NULL COMMENT 'タイトル', `DISCRIPTION` varchar(100) DEFAULT NULL COMMENT '説明文', `STATUS` tinyint NOT NULL COMMENT 'ステータス', `CREATED_AT` datetime DEFAULT NULL COMMENT '作成日時', `UPDATED_AT` datetime DEFAULT NULL COMMENT '更新日時', PRIMARY KEY (`TODO_ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8
userテーブル10万レコード作成クエリ
1つ目:素のデータ1つ投入。
insert user(name,email,password,created_at,updated_at) values( 'matsui' ,'[email protected]' , 'password' , now(), now())
2つ目:クロスジョインで4回実行すると10万になります。
insert user(name,email,password,created_at,updated_at)
select
'matsui'
,concat('matsui',ceil(rand()*1000000),ceil(rand()*1000000),'@example.com')
, 'password'
, addtime(now() + interval rand(now())* - 362 day ,'00:00:00')
, addtime(now() + interval rand(now())* - 365 day ,'00:00:00')
from user
cross join ( select * from user ) tmp_u limit 100000
todoテーブルのデータ生成クエリ
userテーブルをクロスジョインして1000万件生成。
insert into todo (user_id, title, discription, status, created_at, updated_at) select user.user_id , 'タイトル' , '説明' , ceil(rand()*3) , addtime( now() + interval rand(now())* -362 day ,'00:00:00') , addtime( now() + interval rand(now())* -365 day ,'00:00:00') from user cross join (select * from user limit 100) tmp_100
解答
ひとまずクエリから。
with count_tbl as
( select
status
, count(status) count
from user
inner join todo
on user.user_id = todo.user_id
where user.created_at > now() - interval 2 month
group by status
)
select
case when status = 1 then 'Todo'
when status = 2 then 'Doing'
when status = 3 then 'Done' end status
, count
/ ( select sum(count) from count_tbl ) * 100 percent
from count_tbl
order by status desc
やっていることとしては with 句で Group By 集計をしてしまい、次のクエリで表示を整えるため Case 文によるステータスの文字列表記変換とパーセントの計算をさせています。(このクエリ自体がいいとか悪いとか意見があるかもしれませんが)まあとりあえず SQL を書くのはある程度新人のみなさんもさらっとできることが多いです。
ただ、実行してみると遅い。
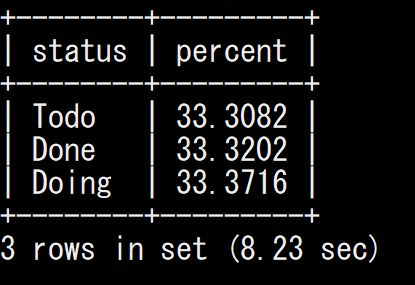
ノーチューニングで8秒です。
クエリのパフォーマンス情報を確認するため MySQL Workbench を使います。(公式)いろいろ見られるんですが今回は最低限の知識をミニマムに習得することを目的にしているのでので Visual Explain だけを確認します。これはクエリがどんな処理順序で実行されているかを図示してくれる機能です。
読んでみると todo の Full Table Scan が出ています。これは todo テーブル1000万件を愚直に全部確認しているということで、非常に効率が悪く、一番出てほしくない検索手段です。将来的にサイズに比例して処理速度に負の影響が出てしまうのは目に見えています。
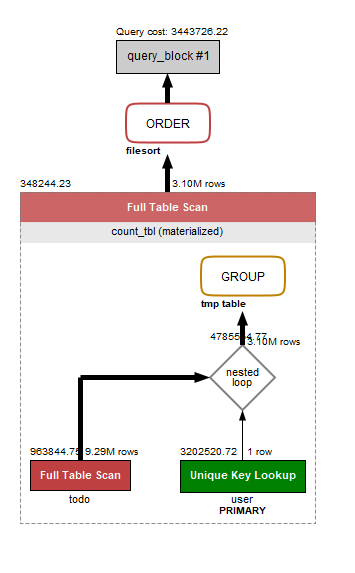
※補足
Visual Explain の読み方ですが、重要なのがテーブルの参照方法です。オブジェクト中のテキストに書いてある文字列の部分で、通常の EXPLAIN コマンドにおける type の値がわかります。
対応は以下の通り。
Single row: constant = const
Unique Key Lookup = eq_ref
Non-Unique Key Lookup = ref
Fulltext Index Search = fulltext
Index Range Scan = range
Full Index Scan = index
Full Table Scan = ALL
下のほうがクエリのコストが大きいです。避けたいやつです。ただ集計クエリというのは必然的に Single row では実現できないので Index Range Scan 以上の高コストな処理を覚悟しなければなりません。
インデックスによるチューニングの手順
ここからどうやったら Select 文が早くなるかを考えます。
第1の選択肢としてはインデックスを検討します。
本当にインデックスが全くわかっていない人は MySQL のインデックスについてまずここを読んで概要を把握してください。
https://dev.mysql.com/doc/refman/8.0/ja/mysql-indexes.html
今回の課題に対して、インデックスをどうやって貼るか。
そのインデックスがちゃんと使われているか。
これらを確認していきます。
インデックスの候補
これはもうほぼ自動的に決定されるのですが、仕組み上 where, order by. group by で指定されるカラムです。
インデックスの実体のイメージとしては、元テーブルから特定のカラムを取り出してあらかじめソートしたテーブルを別で作っておくようなものです。どこにどのデータがあるか検索が容易なので上記のような検索処理を最適化できます。
今回の集計クエリの場合はちょうど以下の部分が where, group by にあたります。
on user.user_id = todo.user_id where user.created_at > now() - interval 2 month group by status
したがって以下のカラムが候補として該当すると判断できます。
user テーブル: user_id, created_at
todo テーブル: user_id, status
user.user_id は PRIMARY なのでもともとインデックスが効いています。あえて貼り直さなくても大丈夫です。
さっそくボコボコと貼ってしまいます。
alter table user add index idx_created_at(created_at) alter table todo add index idx_status(status) alter table todo add index idx_user_id(user_id)
今回は単純な要件なのでB-TREEインデックスだけで対応していきます。
インデックスの利用制約
教科書通りの内容を改めて列挙しておきます。
・1テーブルにつき、1つしか使われない。
・複合インデックスはカラム1つ目、2つ目..の順で使われる。(2つ目以降を最初の条件に使うことはできない。)
・関数、式、否定構文、LIKE=インデックスは効かない(LIKEの前方一致では効く)
・PRIMARY KEY は UNIQUE INDEX として機能する。(貼り直す必要なし)
・インデックスは検索結果の行が少なくなるときに使われる。(本体テーブルの大半を読む必要があるときはわざわざインデックスを使わないほうが早い。)
・データのばらつきがあるほうが効率的に使われる。
・インデックス内のカラムのみでレスポンスできる場合、本体テーブルを参照しないで返すことができるのでより高速になる。(カバリングインデックス、インデックスオンリースキャン)
1つしか使われないとはいえ、全部のカラムに貼っておけばどれか効いてくれるだろうと思いそうですが、残念ながらできません。インデックス作成はもう1つテーブルが増えるようなものなので下手に増やすと更新のコストが上がってしまいます。
インデックス設定後にもう一度 Select のクエリを実行してみました。
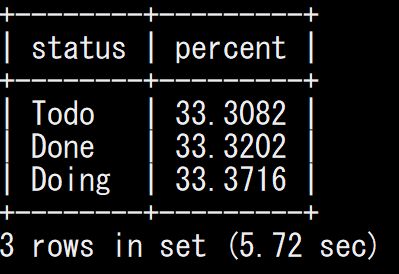
結果、もともと8秒だったのが5秒なりました。だいぶ改善しました。これだけでも結構よい。
インデックスがどう使われているか確認します。
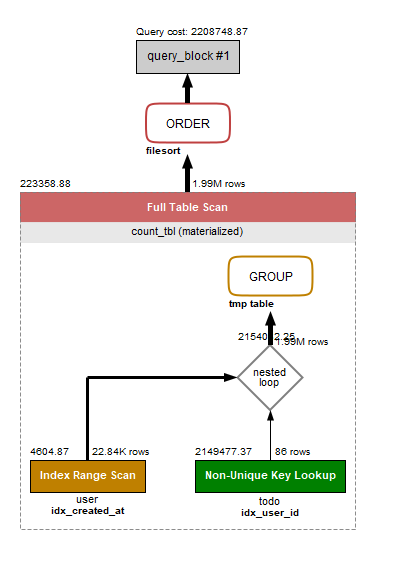
画像の通り、各テーブルの下に参照インデックスが記載されています。 todo は idx_user_id 、 user は idx_created_at が利用されていました。
はじめの Full Table Scan の時は3.10M行だったコストが、今回は Index Range Scan になり1.99M行にまで減ってきました。よし。
インデックスオンリースキャンにしてみる
もう結構充分な感じがしますが、せっかくなのでインデックスオンリースキャンを狙ってみましょう。
カバリングインデックスともよばれ、本体のテーブルを参照ぜずにインデックスのみで集計クエリが完了できるようになっている状態で、この状態が一般的に最速の最適解です。つまり where, order by, group by に加えて select の中身もインデックスに含まれている状態のことを指しています。
今回は user テーブルは created_at + user_id 、 todo テーブルは user_id + status が参照される複合インデックスを作れば実現できそうです。
それぞれ順序を変えて作ってみます。
alter table user add index idx_created_at_user_id(created_at, user_id) alter table user add index idx_user_id_created_at(user_id, created_at) alter table todo add index idx_status_user_id(status, user_id) alter table todo add index idx_user_id_status( user_id, status)
Select 実行結果
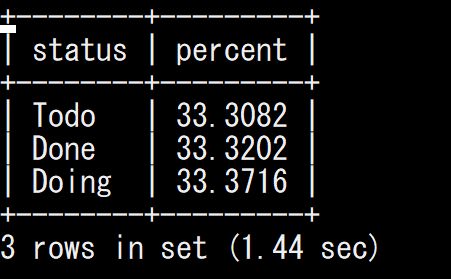
先ほどの5秒から1秒になりました。わかりやすく早くなっていますね。
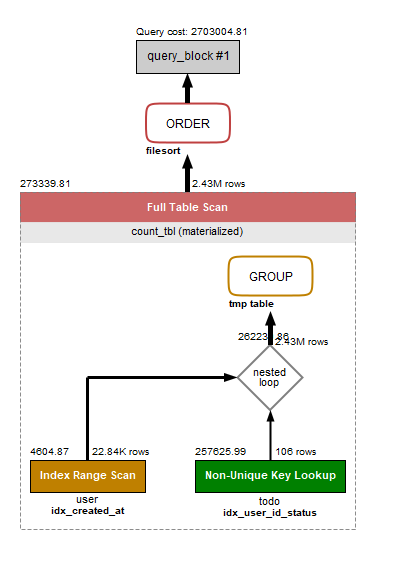
Visual Explain ではトータルコストは増えているように見えおりわかりづらいのですが、インデックスオンリースキャンを確認するには通常の Explain コマンドの結果を見る必要があります。以下の画像で右端の Extra の箇所に出ている Using index がそれを示しています。

複数のインデックスを用意しましたが、結果として使われたのは todo テーブルの idx_user_id_status でした。このインデックスにおける status は検索としては使用されず select 句内の表示のみで利用されていて、本体テーブルを参照することなくインデックスのみで結果を返すことができているため、全体の処理速度が上がっています。 DB のテーブルは所詮はファイルなので、イメージとしてはCSVファイルを1つ開くか2つ開くかどちらが早いかを考えると理解しやすいかと思います。
また逆に user テーブル側は idx_created_at が使われていて idx_created_at_user_id が使われませんでした。これはなぜでしょうか?パッと見は idx_created_at_user_id のほうがインデックスオンリースキャン状態に見えますが、これは実は全てのインデックス(厳密にいうとセカンダリインデックス)には暗黙的に主キーが含まれるためです。つまり idx_created_at にはもともと user_id が含まれていたのでこちらが使われたということになります。この点は漢のコンピュータ道に解説がありますので、読んでみてください。
知って得するInnoDBセカンダリインデックス活用術!
http://nippondanji.blogspot.com/2010/10/innodb.html
インデックスオンリースキャンのデメリットとして、結果を返すためだけにカラムを持たせるのでインデックスのサイズが増加してしまうというものがあります。したがって特にパフォーマンスが重要になるケースで利用を検討した方がいいと思います。
メモリチューニング: innodb_buffer_pool_size に8割あてる
最後にメモリを確認して当て込むチューニングを行います。具体的には innodb_buffer_pool_size を拡張します。この値はテーブルの本体データとインデックスをメモリにキャッシュしておく領域のサイズです。
MySQL にはうんざりするほどたくさんのパラメータがありますが、何か1番初めに覚えるべきものは何かと問われたら、私は innodb_buffer_pool_size と答えます。この値が充分であればクエリの速度に最も大きなプラス効果を与えることができます。
※ちなみにこの値は AWSの「パフォーマンス関連のパラメータ設定のベストプラクティス」でもまず真っ先に触れられてます。
https://aws.amazon.com/jp/blogs/news/best-practices-for-configuring-parameters-for-amazon-rds-for-mysql-part-1-parameters-related-to-performance/
とりあえずこいつを充分にあてておけば安心です。AWS の RDS でもデフォルト75%当たっており、つまりクラウドの場合はチューニングの必要はほとんどありません。
逆に最低どのぐらい必要かということを考えておきましょう。
該当 Select 処理に必要なテーブルの本体データとインデックスの全てをメモリにキャッシュさせることができればひとまずは問題ありません。
具体的には以下のクエリでサイズを確認できます。
SELECT
table_name, engine, table_rows AS tbl_rows,
avg_row_length AS rlen,
floor((data_length+index_length)/1024/1024) AS all_mb, #総容量
floor((data_length)/1024/1024) AS data_mb, #データ容量
floor((index_length)/1024/1024) AS idx_mb #インデックス容量
FROM
information_schema.tables
WHERE
table_schema=database()
ORDER BY
(data_length+index_length) DESC;
私の環境では結果はこんな感じでした。必要なのは all_mb を全部足した値なので今回は 1.5 G ぐらいでしょうか。
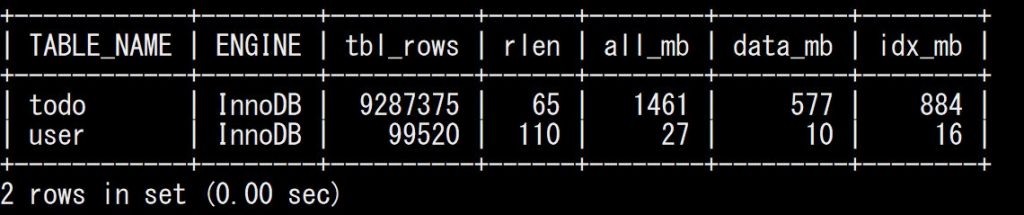
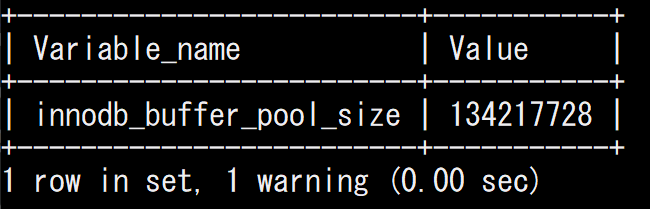
現状のinnodb_buffer_pool_sizeも確認しておきます。デフォルトでは 128M となっており、さすがに小さい。
SHOW GLOBAL VARIABLES LIKE 'innodb_buffer_pool_size'
余裕をもって 2G あててみます。
SET GLOBAL innodb_buffer_pool_size = 2415919104;
これで課題の Select クエリを飛ばしてみると。。

ついに1秒以内になりました。はじめの状態に比べて劇的に改善されたのではないでしょうか。
まとめ
DB にあまり触れてこなかった新卒社員はインデックスを知らないというケースのほうがほとんどですので、私は必ずといってほど研修でこの話題を取り扱っています。
・Where, order by, group by の対象カラムにはインデックスを貼る。
・Visual Explain でインデックスの利用状況を確認する。
・innodb_buffer_pool_size を変更してメモリを充て込む。
インデックスを使えばそのカラムへの検索は早くなりますし、インデックスオンリースキャンが使用できればさらに高速になります。
またとりあえずインデックスを貼るというのは完全に間違いです。余計なファイルが増えて DB 容量が上がるし、作成更新負荷も馬鹿になりません。あくまで必要性のあるカラムには貼るかどうかを検討するようにしてほしいと思います。
宣伝
次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットのいろんなアプリケーションの開発を行うアーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD