2016.03.03
Galera Cluster を無停止で新規ノードにデータを完全同期する
D.M. です。複数の案件で Galera Cluster を利用したシステムの運用を2年ぐらいしています。現状 Galera Cluster については日本語での資料が少ないため運用時の問題解決に苦労することが多い状況です。実際原因不明のクラッシュに悩まされバージョンアップを余儀なくされたこともありました。現状わかっているノウハウをここにまとめたいと思います。
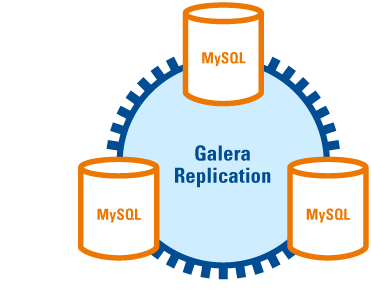
Galera Cluster は MySQL, MariaDB, Percona Server のマルチマスター構成を実現する仕組みです。最低3台で動くため、マスター DB が単一障害点となる問題を回避できるという非常に優れたメリットを持っており、無償で利用できます。リアルタイムでデータを同期しており、ノードの新規追加や切り離し、復旧においてもほぼ自動的にデータを同期することができます。公式ページはこちらです。
以前の記事: Galera Cluster のノード切断時に rsync にて障害から復旧する方法
http://recruit.gmo.jp/engineer/jisedai/blog/mariadb_galera_cluster/
インターネットで検索するとインストールや初期化の記事は多いのですが、新規追加や障害復旧時のデータ同期の情報は現時点では限られています。今回は Xtrabackup によるデータ同期をメインに書いていこうと思います。
基本用語の理解
Galera Cluster の基本用語を以下に列挙します。
・ Node : クラスタを構成する個々のDBインスタンス。全てがマスターとして動作する。(以下ノードとする)
・ Donor : 元データを保持するノード。1番初めに起動したノード。(以下ドナーノードとする)
・ Joiner : 2番目以降に追加されたノード。(以下ジョイナーノードとする)
・ Primary : プライマリーノード。1番最新のデータを持っているノード。
・ SST : State Snapshot Transfer 。ノード追加時にデータに不整合があればプライマリーなノードからデータを完全同期する仕組み。 my.cnf で同期方法3種類のいずれかを設定する。
・ IST : Incremental State Transfer 。更新情報のキャッシュから差分情報のみデータを同期する仕組み。一時的にノードがダウンした場合などはこの仕組みで同期される。
・ Xtrabackup : Percona 社が開発したMySQLのバックアップツール。データディレクトリのファイルを利用して高速に動作する。クラッシュリカバリの仕組みを利用している。コマンドのラッパーツールである InnoBackupex とともに利用する。
SST と IST の基本的な機能
ノードの起動時にドナーノードとの差分があると判断された場合、まず IST のキャッシュで差分だけの同期が可能か確認され、不可能な場合は SST によりゼロから完全に同期されます。まずは SST と IST について基本的な内容を整理します。
SST によるデータ完全同期
SST は各ノードの起動時にデータを自動で完全同期する方法です。 my.cnf に以下の3つのいずれかの方法を設定します。
・ rsync
・ mysqldump
・ Xtrabackup
Xtrabackup が最も可用性が高い仕組みです。 Xtrabackup 以外の方法を利用すると元データを保持するドナーノードの更新がロックされます。 Xtrabackup はデータ同期の際にロックしません。 Xtrabackup v2.0 以降が利用できるヴァージョンからは Xrtabackup がデフォルトになっています。
速度の比較についてはこちらが詳しいです。 XtraBackup はリストア時に最速の結果を出しています。
MySQLバックアップツール比較 XtraBackup / mysqldump / Mydumper
http://www.submit.ne.jp/1211
IST によるデータ完全同期
IST はキャッシュファイルから完全同期を行う方法です。一時的に1つのノードが切り離されて更新状態が遅れてしまった場合に、キャッシュのサイズの範囲であれば更新ロックなしで同期できます。非常に高速かつ低負荷で動作するため、できるかぎり IST による同期を図っていくべきです。 my.cnf にキャッシュ上限値が設定できます。
動作中には以下のようなログが出ます。
ドナーノード
160226 22:33:23 [Note] WSREP: async IST sender starting to serve tcp://192.168.0.3:4568 sending 23569-23570
ジョイナーノード
160226 22:33:24 [Note] WSREP: SST received: 958aacc5-daf7-11e5-bf1f-f22f12225ea8:23568 160226 22:33:24 [Note] WSREP: Receiving IST: 2 writesets, seqnos 23568-23570 160226 22:33:24 [Note] /usr/sbin/mysqld: ready for connections. Version: '10.0.23-MariaDB-wsrep' socket: '/var/lib/mysql/mysql.sock' port: 3306 MariaDB Server, wsrep_25.11.r21a2415 160226 22:33:24 [Note] WSREP: IST received: 958aacc5-daf7-11e5-bf1f-f22f12225ea8:23570 160226 22:33:24 [Note] WSREP: 2.0 (db3): State transfer from 1.0 (db1) complete.
キャッシュサイズ以上の差分が発生してしまった場合は IST できない状態になり、自動的に SST が呼ばれます。ドナーノードにて以下のようなログが出ていれば SST の処理が始まり、全てのデータを 0 から同期します。
160227 0:27:22 [Note] WSREP: IST first seqno 28899 not found from cache, falling back to SST
IST のキャッシュサイズの決め方
1時間あたりどのぐらいのデータ更新を行っているかを確認して決めます。現状利用できる統計情報は wsrep_replicated_bytes と wsrep_received_bytes の値ですが、クエリ実行時点の更新データ量の累計を取得することしかできませんので、1分間に行われる更新量を測定するためにはたとえば以下のようなクエリを利用することが必要です。これはバイナリーログの増量サイズとほぼ同じです。
1分および1時間の更新データ量を測定し、現状の GCACHE の値で何分以内なら IST が可能かを見積もります。
mysql> set @start := (select sum(VARIABLE_VALUE/1024/1024) from information_schema.global_status where VARIABLE_NAME like 'WSREP%bytes'); do sleep(60); set @end := (select sum(VARIABLE_VALUE/1024/1024) from information_schema.global_status where VARIABLE_NAME like 'WSREP%bytes'); set @gcache := (select SUBSTRING_INDEX(SUBSTRING_INDEX(SUBSTRING_INDEX(SUBSTRING_INDEX(variable_value,';',29),';',-1),'=',-1),'M',1) from information_schema.global_variables where variable_name like 'wsrep_provider_options'); select round((@end - @start),2) as `MB/min`, round((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, round(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`; +--------+---------+-----------------+-----------------------+ | MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) | +--------+---------+-----------------+-----------------------+ | 0.61 | 36.60 | 1 | 1.64 | +--------+---------+-----------------+-----------------------+ 1 row in set (0.00 sec)
仮にキャッシュサイズ 1M 、1時間あたりのデータ量 36M とすると、 IST 可能なのはざっくり1分半ぐらいです。上記の例の場合 gcache.size=100M にすれば切断後2時間半ぐらいは IST で同期可能です。
データ同期の基本的な考え方
初期構築の場合
最も安全で確実な方法は、全てのDBを停止した状態でデータディレクトリ自体をまるごと手動でコピーして全ての DB で同じ状態を作り出してから起動することです。また、起動はしているが更新が完全に停止している状態では SST の rsync により同期することも可能です。(この方法はある程度ウェブに情報があるためここでは取り扱いません)
運用中に新規ノードを追加する、また通信障害で切断したノードが復帰する場合
1番手のかからない方法は SST の Xtrabackup により全自動で完全同期する方法です。新ノードを起動するだけでドナーノードの更新処理を無停止でジョインできるので、システム運用中でも実行できます。
ただ同期にはドナーノードのCPUやディクス読み書きである程度負荷があることや、大きなデータを扱って長時間同期していると突然通信上の問題で SST が失敗する可能性があることを考慮に入れておく必要があります。またクラッシュリカバリの仕組みを使用しているためか、時折同期完了後にジョイナーノードでデータが読み込めなくなるエラーが発生したりするので、新ノードを追加する場合は定期バックアップファイルを利用して手動で Xtrabackup からデータディレクトリを構築し IST にて同期する方法を理解しておいたほうが安全です。
手動で行う場合は以下の手法があります。
・定期フルバックアップを Xtrabackup で取得している場合
⇒ フルバックアップ + IST
・何もない場合
⇒ 手動で Xtrabackup のフルバックアップ + IST (下記 A で手順を示します)
・フルバックアップ + IST ではキャッシュサイズを上回る更新があり同期できない場合
⇒ フルバックアップ + 増分バックアップ + IST (下記 B で手順を示します)
SST を避けて手動で完全同期する方法
本題です。既存で動いている db1, db2 に新規 db3 を加えるというユースケースに対して、 Xtrabackup と IST を利用した半自動同期を行う手順を紹介します。
A : db1 で手動で Xtrabackup を取って db3 のデータディレクトリを構築し、最終的に IST で同期します。
B : 上記 A の IST でデータ同期が完了できない場合、フルバックアップに増分バックアップを追加して IST を当てる方法で対応します。
これから手順の説明を読む前に以下の用語を頭に入れておいてください。
・フルバックアップ : 全データのバックアップ。定期的に取っていることが想定されるが、今回はその場で手動で取得する。
・増分バックアップ : Incremental Backup 、または差分バックアップ。定期フルバックアップ以降の増分データ。
・チェックポイント : フルバックアップの最終地点。 Xtrabackup ではこの点が記述されたチェックポイントファイルを利用して点以降のデータを増分バックアップとして取得する。
手動で Xtrabackup のフルバックアップ + IST で同期する手順
まずは上記の A から説明します。
以下の例では db1: 192.168.0.1, db2: 192.168.0.2, db3: 192.168.0.3 とします。
A1. Galera Cluster と Xtrabackup をインストールした新規ノード DB3 を立てる
インストールは yum でも可能です。詳細は Galera Cluster および MariaDB, Percona の公式ページが詳しいです。
CentoOS 6.5 に yum でインストールする例
cat > /etc/yum.repos.d/MariaDB.repo << EOF [mariadb] name = MariaDB baseurl = http://yum.mariadb.org/10.0/centos6-amd64 gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=1 EOF yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm -y yum install http://ftp-srv2.kddilabs.jp/Linux/distributions/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm -y yum install libev -y yum install http://dl.fedoraproject.org/pub/epel/6/x86_64/socat-1.7.2.3-1.el6.x86_64.rpm -y yum install MariaDB-Galera-server MariaDB-client rsync galera -y yum install percona-xtrabackup-24.x86_64 -y
my.cnf
[galera] wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_address="gcomm://192.168.0.1,192.168.0.2,192.168.0.3" wsrep_cluster_name='galera_cluster' wsrep_node_address='192.168.0.3' wsrep_node_name='db3' wsrep_sst_method=xtrabackup wsrep_sst_auth=sst_user:sst_user_password
今回 SST を使用しないのですがいざというときのためにSST用ユーザを全ノードで作成しておきます。
GRANT ALL PRIVILEGES on *.* to sst_user@'localhost' IDENTIFIED BY 'sst_user_password'; GRANT ALL PRIVILEGES on *.* to sst_user@'192.168.0.%'; FLUSH PRIVILEGES;
A2. IST のキャッシュである gcache.size を全ノードで上げる
これは前述のとおり更新データ量と空きメモリの状態を検討した上で決定してください。今回は 1G とします。
$ vi ./my.cnf wsrep_provider_options="gcache.size=1G"
$ service mysql restart
A3. フルバックアップを取得
定期バックアップをとってあることが望ましいですが、その場で取得する流れを記載します。まずは作業用ディレクトリにバックアップをコピーします。
※作業ディレクトリには DB のデータが全てコピーされるためディスクスペースの空きを確保して多くことが必要です。今回の例では /var 以下に充分な空きがあることを前提にしています。
[root@db3]$ mkdir -p /var/restore/original_full
Xtradackup のフルバックアップを Innobackupex コマンドで取得し、 db3 のバックアップフォルダへ流し込みます。
[root@db1]$ innobackupex --user=root --galera-info --stream=tar --socket=/var/lib/mysql/mysql.sock ./ | pigz | ssh root@db3 "tar xizvf - -C /var/restore/original_full"
このコマンドはストリームで外部フォルダにデータを直撃で流し込みますが以下のログが延々と出続けるときはどこか前処理で詰まっています。(私の場合は ssh 接続設定の不備があった)
160226 17:21:41 >> log scanned up to (91932426256) 160226 17:21:42 >> log scanned up to (91932426256) 160226 17:21:43 >> log scanned up to (91932426256) 160226 17:21:44 >> log scanned up to (91932426256) 160226 17:21:47 >> log scanned up to (91932426256) 160226 17:21:48 >> log scanned up to (91932426256) 160226 17:21:49 >> log scanned up to (91932426256)
A4. バックアップファイルから利用可能なデータファイルを生成
作業ディレクトリにコピーしてから innobackupex コマンドを実行します。(ディスク容量に余裕がなければコピーは不要) apply-log は未適用のトランザクションをデータファイルに適用するためのオプションです。
[root@db3]$ cp -r /var/restore/original_full /var/restore/full [root@db3]$ innobackupex --apply-log /var/restore/full
以下が出力されたら完了となります。
160226 18:00:01 completed OK!
A5. データディレクトリ差し替えと起動
データディレクトリをリネームしてからバックアップファイルと置き換えます。DB 動作中であれば停止して作業します。
[root@db3]$ service mysql stop [root@db3]$ mv /var/lib/mysql/ /var/lib/bk_mysql/ && mkdir /var/lib/mysql/ [root@db3]$ innobackupex --copy-back /var/restore/full [root@db3]$ chown -R mysql:mysql /var/lib/mysql
※もし Galera Arbitorator が動作していたら止めておく。 Galera Arbitorator についての詳細はこちら。
[root@db3]$ killall -9 garbd
起動すれば IST が動作し接続完了です。
[root@db3]$ service mysql start
フルバックアップ + 増分バックアップ + IST で同期する手順
フルバックアップ + IST ではキャッシュサイズの限界を超えた場合に同期が完了できず SST によるフル同期がゼロからはじまってしまいます。フルバックアップのサイズが非常に大きい場合、作業時間が長くなってしまうため、せっかく手動で適用しても IST では復旧できない状態になってしまうことが充分起こりえます。この場合は、対応策として増分バックアップを別途取得し、フルバックアップとキャッシュの差を埋めてデータ同期する手法が使えます。
ここからは B の説明になります。以下の手順は一度上記 A のフルバックアップ + IST を適用した前提で進めます。
B1. DB3 に増分バックアップ用ディレクトリ作成
[root@db3]$ mkdir -p /var/restore/incremental
B2. xtrabackup_checkpoints を元に DB1 の増分バックアップを作る
DB1 のディレクトリに DB3 の xtrabackup_checkpoints をコピーします。
[root@db1]$ mkdir -p /var/restore/check [root@db1]$ scp root@db3:/var/restore/full/xtrabackup_checkpoints /var/restore/check
DB1 で xtrabackup_checkpoints を読み込んで増分バックアップを取得します。結果を DB3 のディレクトリにストリームで流し込みます。
[root@db1]$ innobackupex --user=root --incremental --galera-info --incremental-basedir=/var/restore/check --socket=/var/lib/mysql/mysql.sock --stream=xbstream ./ | ssh root@db3 "xbstream -x -C /var/restore/incremental"
B3. フルバックアップと増分バックアップをマージ
フルバックアップを再度初期状態で用意し、そこに増分バックアップを適用してマージします。増分バックアップを追加する場合はフルバックアップ側のログ適用に redo-only オプションが必要です。
詳細は公式ページを確認してください。
Incremental Backups with innobackupex
[root@db3]$ mv /var/restore/full /var/restore/bk_full [root@db3]$ cp -r /var/restore/original_full /var/restore/full [root@db3]$ innobackupex --apply-log --redo-only /var/restore/full [root@db3]$ innobackupex --apply-log /var/restore/full --incremental-dir=/var/restore/incremental
B4. Galera Cluster の情報を適用
増分バックアップの xtrabackup_galera_info 情報をフルバックアップの grastate.dat に反映します。
まずは増分側の内容確認。
[root@db3]$ cat /var/restore/incremental/xtrabackup_galera_info d38587ce-246c-11e5-bcce-6bbd0831cc0f:1352215
/var/restore/full に grastate.dat を作成し、増分バックアップ xtrabackup_galera_info の情報を書き込みます。
[root@db3]$ vi /var/restore/full/grastate.dat # GALERA saved state version: 2.1 uuid: d38587ce-246c-11e5-bcce-6bbd0831cc0f ← 書き換え seqno: 1352215 ← 書き換え cert_index:
B5. データディレクトリ差し替えと起動
ここから先はフルバックアップ単体を適用するときと同じ手順です。
[root@db3]$ service mysql stop [root@db3]$ mv /var/lib/mysql/ /var/lib/bk2_mysql/ && mkdir /var/lib/mysql/ [root@db3]$ innobackupex --copy-back /var/restore/full [root@db3]$ chown -R mysql:mysql /var/lib/mysql
※フルバックアップ適用時と同じく garbd 動作中であれば停止します。
起動します。 IST で同期されて完了です。
[root@db3]$ service mysql start
この記事が参考になりました。
How to Avoid SST when adding a new node to Galera Cluster for MySQL or MariaDB
http://severalnines.com/blog/how-avoid-sst-when-adding-new-node-galera-cluster
こんなエラーでハマりました
このエラーが出たらこれというのは英語でも日本語でもあんまりまとまっておらず、だいたいが掲示板や個人のブログの情報に頼らざるを得ない状況です。いくつかハマッたエラーをまとめます。エラーログが出たら何が起こっているのかを判断する助けになればと思います。
IST が待機状態でつながらない
ジョイナーノードのほうでこんなログが出ました。
160225 22:25:15 [Warning] WSREP: Member 1.0 (db1) requested state transfer from '*any*', but it is impossible to select State Transfer donor: Resource temporarily unavailable
これは1つのドナーノードに 2つのノードを同時に追加しようとすると port に接続できない状態で固まります。しばらくリトライログが出つづけます。片方が完了するまで待つか KILL する必要があります。
Xtrabackup SST 完了後にクラッシュする
SST の完了ログの後に突然 CRASH のログが出ることがあります。 tablespace がおかしくなってしまったようです。
160226 20:57:42 [Note] WSREP: SST complete, seqno: 21744 2016-02-26 20:57:42 7fef5a01a820 InnoDB: Warning: Using innodb_locks_unsafe_for_binlog is DEPRECATED. This option may be removed in future releases. Pl ease use READ COMMITTED transaction isolation level instead, see http://dev.mysql.com/doc/refman/5.6/en/set-transaction.html. 160226 20:57:42 [Note] InnoDB: Using mutexes to ref count buffer pool pages 160226 20:57:42 [Note] InnoDB: The InnoDB memory heap is disabled 160226 20:57:42 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins 160226 20:57:42 [Note] InnoDB: Memory barrier is not used 160226 20:57:42 [Note] InnoDB: Compressed tables use zlib 1.2.3 160226 20:57:42 [Note] InnoDB: Using Linux native AIO 160226 20:57:42 [Note] InnoDB: Not using CPU crc32 instructions 160226 20:57:42 [Note] InnoDB: Initializing buffer pool, size = 128.0M 160226 20:57:42 [Note] InnoDB: Completed initialization of buffer pool 160226 20:57:42 [Note] InnoDB: Highest supported file format is Barracuda. 160226 20:57:42 [Note] InnoDB: The log sequence numbers 92004218759 and 92004218759 in ibdata files do not match the log sequence number 92004966724 in the ib_logfiles! 160226 20:57:42 [Note] InnoDB: Database was not shutdown normally! 160226 20:57:42 [Note] InnoDB: Starting crash recovery. 160226 20:57:42 [Note] InnoDB: Reading tablespace information from the .ibd files... 160226 20:57:42 [Note] InnoDB: Restoring possible half-written data pages 160226 20:57:42 [Note] InnoDB: from the doublewrite buffer... 2016-02-26 20:57:42 7fef5a01a820 InnoDB: Error: page 7 log sequence number 92017319057 InnoDB: is in the future! Current system log sequence number 92004966724. InnoDB: Your database may be corrupt or you may have copied the InnoDB InnoDB: tablespace but not the InnoDB log files. See InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html InnoDB: for more information. 2016-02-26 20:57:42 7fef5a01a820 InnoDB: Error: page 5 log sequence number 92017328607 InnoDB: is in the future! Current system log sequence number 92004966724. InnoDB: Your database may be corrupt or you may have copied the InnoDB
このエラーですが実は自動的に復旧することも多いです。 Xtrabackup は InnoDB のクラッシュリカバリの仕組みを利用しているため不可避的に発生すると思われます(詳細はこちら)。
ただ SST による Xtrabackup が途中で停止してしまうなどトラブルがあると、InnoDB のファイルが本当にクラッシュしてしまうことがあります。完全に壊れてしまった場合は Galera Cluster は上記で紹介したフルバックアップに IST を当てる方法でリカバリしなければなりません。 “crash recovery” で検索すると innodb_force_recovery を my.cnf に記載して再起動し、全データを DUMP で抜いてからデータを削除し再投入することで復旧する方法が紹介されていますが、DUMP 同期は全体を停止する必要があるので、状況に応じて使い分けが必要です。
Primary を決めれられない
複数台が同時に落ちるなどして、どちらが最新データなのか決めることができない場合は、ドナーノード側で受け入れを拒否するログが出ます。
ジョイナーノード(db3)
160226 18:42:05 [ERROR] WSREP: failed to open gcomm backend connection: 110: failed to reach primary view: 110 (Connection timed out)
at gcomm/src/pc.cpp:connect():161
160226 18:42:05 [ERROR] WSREP: gcs/src/gcs_core.cpp:long int gcs_core_open(gcs_core_t*, const char*, const char*, bool)():206: Failed to open backend connection: -110 (Connection timed out)
160226 18:42:05 [ERROR] WSREP: gcs/src/gcs.cpp:long int gcs_open(gcs_conn_t*, const char*, const char*, bool)():1379: Failed to open channel 'galera_cluster' at 'gcomm://192.168.0.1,192.168.0.2,192.168.0.3': -110 (Connection timed out)
160226 18:42:05 [ERROR] WSREP: gcs connect failed: Connection timed out
160226 18:42:05 [ERROR] WSREP: wsrep::connect(gcomm://192.168.0.3) failed: 7
160226 18:42:05 [ERROR] Aborting
ドナーノード(db1)
160226 18:41:36 [Note] WSREP: (34479483, 'tcp://0.0.0.0:4567') turning message relay requesting off
160226 18:42:04 [Note] WSREP: (34479483, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.0.3:4567
160226 18:42:05 [Note] WSREP: forgetting 1f5ea389 (tcp://192.168.0.3:4567)
160226 18:42:05 [Note] WSREP: (34479483, 'tcp://0.0.0.0:4567') turning message relay requesting off
160226 18:42:05 [Note] WSREP: view(view_id(NON_PRIM,34479483,80) memb {
34479483,0
} joined {
} left {
} partitioned {
1f5ea389,0
})
160226 18:42:05 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
160226 18:42:05 [Note] WSREP: Flow-control interval: [16, 16]
160226 18:42:05 [Note] WSREP: Received NON-PRIMARY.
160226 18:42:05 [Note] WSREP: New cluster view: global state: 958aacc5-daf7-11e5-bf1f-f22f12225ea8:20638, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
160226 18:42:05 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
160226 18:42:10 [Note] WSREP: cleaning up 1f5ea389 (tcp://192.168.0.3:4567)
こうなってしまった場合、既存のドナーノード側でクラスタの初期化をします。初期化はデータは消えるわけではないのですがクラスタを初期から再構築する手段なので慎重に行ってください。
service mysql start --wsrep-new-cluster
その後に残りのノードで通常の接続をします。(新規扱いのため内部的に SST が走ってドナーノードのデータを完全同期します。手動で同期する方法も視野に入れたほうがよいです)
service mysql start
Primary Key がないためノードが1つダウンする
これはうっかり実際ハマりました。主キーが無いテーブルを運用しているとノードが突然死する現象が発生します。必ず Primary Key をつけましょう。
BF-BF X lock conflict RECORD LOCKS space id 36440 page no 3 n bits 376 index `GEN_CLUST_INDEX` of table `test_db`.`test_table` trx id 1AB4ED7 lock_mode X locks rec but not gap 160202 5:08:16 [ERROR] mysqld got signal 6 ;
こちらの記事が詳しいです。
Become a MySQL DBA blog series – Troubleshooting Galera cluster issues – part 1
http://severalnines.com/blog/become-mysql-dba-blog-series-troubleshooting-galera-cluster-issues-part-1
Xtrabackup のパフォーマンスへの影響
Xtrabackup バックアップによる同期は親ノードをロックしませんが、パフォーマンス上の影響は少なからずあります。これはCPUとディスクIOがテーブル数や書き込み数によって差が出るものと思われるため、一概に何%遅くなるとは言えないのですが、今回2コアマシンで検証用1テーブルだけを同期したところ MySQL 100% に対し Innobackupex はおよそ 30% の使用状態となりました。動作中に使用するメモリはデフォルト100MBですが use-memory パラメターで設定できます(詳細はこちら)。
またテーブル1つ10G程度のデータを SST したところ、所要時間は10分弱でした。環境やデータ状況によって異なると思われるため、いくつかの状況で検証をしたいところです。本番適用の際には実際のデータを使用したテストが必須と思います。
最後に
現状 Galera Cluster の情報はほとんどが英語の状態ですので、良い情報を見つけ次第、検証して日本語の記事としてまとめていこうと思います。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD