2023.01.11
Cloud Run jobsを使ってみた
こんにちは。次世代システム研究室のM.Mです。
前回のブログでは、バッチ処理をサーバーレスで実現するサービスとして、GCP Batchを試しました。
今回はその続きとして、GCP Cloud Run jobsを試します。
また、バッチ処理でデータベースにアクセスするケースも多いと思うので、今回はCloud Run jobsにてCloud SQLに接続してデータを取得するところも試してみようと思います。
1. Cloud Run jobsの概要
Cloud Run jobsの解説として、以下にわかりやすく解説されている記事がありました。
今回は、Cloud Run jobsのジョブをGoogle WEBコンソールを利用して、実際に作成・実行して、どのようなことが確認できるのか見ていきたいと思います。
実施する内容としては、前回のGCP Batchと同様、事前にバッチを実行する環境となるDockerイメージを用意して、Cloud Run jobsのジョブを作成する際に、そのDockerイメージを設定する流れとなります。
そして作成されたジョブを実行することで、設定したDockerイメージのコンテナが立ち上がりバッチが実行されます。
またタスク数・並列実行数を指定して実行することもできるので、実際に試してみようと思います。
2. Cloud SQLインスタンスの作成
今回は、Cloud Run jobsからCloud SQLに接続してデータ取得も試すので、まずCloud SQLのDBインスタンスを作成します。
PostgreSQL 14を選択しました。
■Cloud SQLのDBインスタンスを作成する
Cloud SQL自体の検証ではないので、作成についての記載はしませんが、GCP WEBコンソールの画面から簡単に作成できます。
パブリックIPを利用する用途はないので、プライベートIPのみ割り当てるように構築した程度で、他は低スペックで必要最低限の設定のみにしました。
■ユーザー、データベースを作成する
Cloud SQLのDBインスタンスの作成が完了したら、以下の図のように、ユーザー、データベースの項目があるので、そこから作成することができます。
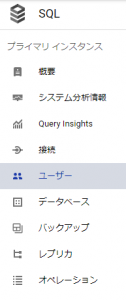
今回は、
データベース名:mmtest_db
ユーザー名: mmtest
として作成しました。
■テーブル、データを作成する
テーブル、データに関しては、残念ながらGCP WEBコンソールにテーブル、データを作成する為のGUIは用意されていません。
また、プライベートIPのみ割り当てたDBインスタンスの場合、さらに面倒になるところです。
パブリックIPを割り当てた場合、以下の図にある「CLOUD SHELLを開く」を選択して、gloucd sql connectコマンドを使うことで、簡単にDBインスタンスに接続することができますが、プライベートIPのみ割り当てたDBインスタンスの場合、その方法では接続ができません。
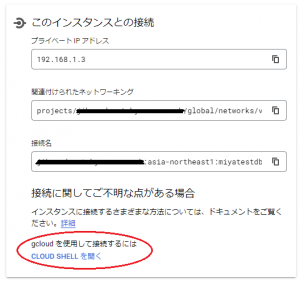
面倒ですが、今回は、同じVPCネットワークにGCEインスタンス(CentOS 7)を作成して、そこからDBインスタンスに接続して、テーブル、データの作成を行います。
以下、作成したGCEインスタンスにて実施した内容になります。
# yum install postgresql
# yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
# yum install postgresql13-libs
# psql -h 192.168.1.3 -U mmtest -d mmtest_db
mmtest_db=> create table testusers (
id serial primary key,
name text not null,
created_at timestamp without time zone not null
);
mmtest_db=> insert into testusers(name, created_at) values('mm1', now());
mmtest_db=> insert into testusers(name, created_at) values('mm2', now());
mmtest_db=> insert into testusers(name, created_at) values('mm3', now());
mmtest_db=> select * from testusers;
id | name | created_at
----+------+----------------------------
1 | mm1 | 2023-01-05 04:25:12.537292
2 | mm2 | 2023-01-05 04:25:18.672467
3 | mm3 | 2023-01-05 04:25:23.244033
mmtest_dbにtestusersテーブルを作成し、データを3件登録しました。
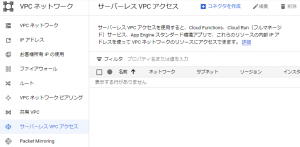
■Cloud Run jobsからCloud SQLに接続するため、サーバーレスVPCアクセスコネクタを作成する
以下の図のように、GCP WEBコンソールにある、VPCネットワークのサーバーレスVPCアクセスから作成することができます。
また、今回は以下の図のようにmm-svrless-connectorという名称で作成しました。
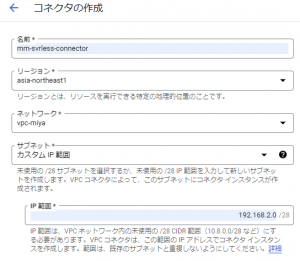
Cloud RunやApp EngineなどサーバーレスアプリケーションからVPCネットワーク内のリソースに内部IPアドレスを使ってアクセスするには、サーバーレスVPCアクセスコネクタが必要になります。
また、Cloud SQLに関してもプライベートIPのみ割り当てたインスタンスにしたので、プライベートサービスアクセスの設定が必要になります。
ネットワークについては、以下を参照するとよいと思います。
これで、Cloud Run jobsからCloud SQLに接続してデータを取得する準備ができたので、次はCloud SQLに接続するバッチの準備をします。
3. Cloud SQLに接続するバッチの作成
python3、psycopg2を利用してDBインスタンスに接続、データを取得するバッチを作成します。
■requirements.txt
Click==7.0 psycopg2-binary==2.9.5
■test.py
import os
import click
import psycopg2
import time
@click.command()
@click.argument('code', type=int)
def exec_test(code):
print('Input code: {}'.format(code))
task_index = os.getenv('CLOUD_RUN_TASK_INDEX')
print('CLOUD_RUN_TASK_INDEX: {}'.format(task_index))
time.sleep(60)
db_uri = 'postgres://mmtest:[email protected]/mmtest_db'
with psycopg2.connect(db_uri) as pg_conn:
with pg_conn.cursor() as curs:
curs.execute('SELECT * FROM testusers WHERE id = %(id)s', {'id': task_index})
result = curs.fetchall()
print(result)
if __name__ == '__main__':
exec_test()
10行目: 環境変数CLOUD_RUN_TASK_INDEXについては、Cloud Run jobsで実行される各タスクに割り当てられる値です。この値によって各タスク毎に処理を分けるような実装が可能になります。
13行目: 並列実行されるか確認するため60秒スリープさせています。
15行目: 作成したCloud SQLのDBインスタンスのプライベートIPにて接続するようにしています。
18行目: 作成したtestusersテーブルからデータを取得するようにしています。
4. Dockerイメージの登録
■Dockerfile
FROM centos:7
COPY ./requirements.txt ./
RUN yum update yum -y && \
yum install -y python3 python3-devel && \
yum install -y gcc-c++
RUN python3 -m pip install --upgrade pip && \
python3 -m pip install --no-cache-dir -r requirements.txt
RUN localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
ENV LANG="ja_JP.UTF-8" \
LANGUAGE="ja_JP:ja" \
LC_ALL="ja_JP.UTF-8"
COPY ./test.py ./
RUN chmod +x ./test.py
ENTRYPOINT ["python3", "./test.py"]
CMD ["0"]
python3、利用したいモジュールをインストールして、上記にて作成したtest.pyを配置して、ENTRYPOINTにてそのバッチを実行するようにしているのみです。
ビルドして、DockerイメージをArtifact Registryに登録します。
登録手順は前回ブログに記載した内容と同じです。
これで、Cloud Run jobsのジョブ作成、および実行する準備ができました。
では、実際にCloud Run jobsのジョブ作成・実行に進みます。
5. Cloud Run jobsのジョブの作成
GCP WEBコンソールのCloud Runを選択すると、以下の図のように、ジョブ[プレビュー]タブがあるので選択します。
(※2023/1/6時点ではまだプレビュー段階となっています)
ジョブの作成をクリックすると以下の図のような画面が表示されます。
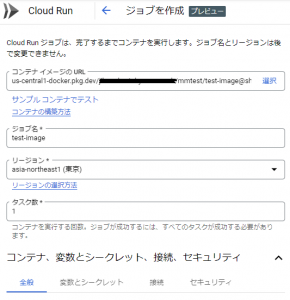
コンテナイメージのURLの個所にて、Artifact Registryに登録したDockerイメージを選択します。
まず、タスク数は1としておきます。
また全般タブを選択すると、以下の図のように、エントリポイントやコマンドの設定ができるようになっています。
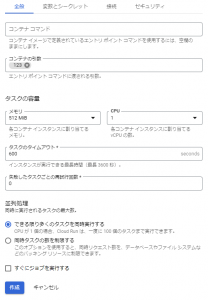
また、並列処理のところに「できる限り多くのタスクを同時実行する」「同時タスクの数を制限する」を選択できるようになっています。
今回は「できる限り多くのタスクを同時実行する」にチェックをしていますが、タスク数を1にしているので、並列処理はされません。
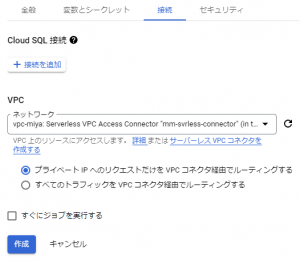
さらに接続タブを選択すると、以下の図のように、VPCネットワークの項目があるので、そこに上記にて作成したサーバーレスVPCアクセスコネクタ(mm-svrless-connector)を選択します。
作成を完了すると、以下の図のようにジョブの一覧に表示されます。
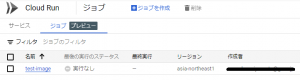
まだ、実行していないので、最後の実行のステータスは、実行なしとなっています。
実行すると、以下の図のように実行結果を参照することができます。
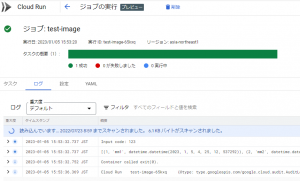
ログの出力内容は、何回かバッチを修正する前のものなので、上記に記載したtest.pyで出力される内容と異なりますが、Cloud SQLからデータが取得されて出力されていることが分かります。
6. タスクの並列実行・直列実行
並列実行・直列実行させるには、上記Cloud Run jobsのジョブを作成した際にあったタスク数・並列処理の設定を行うことで可能となります。
まず、並列実行させてみます。
作成したジョブは編集することが可能なので、以下の図のように、タスク数を2に変更して保存します。
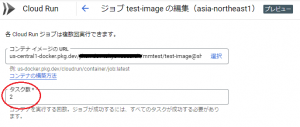
並列処理のところは、特に変更せず、「できる限り多くのタスクを同時実行する」のままにしておきます。
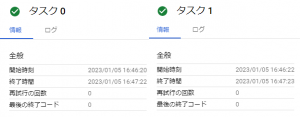
実行すると以下の図のようにタスク0、タスク1の2タスク実行されていることが分かります。
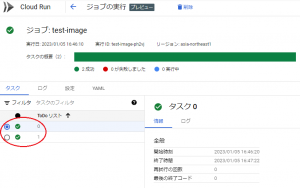
上記はタスク0が選択されていますが、タスク1を選択することで、タスク1の情報を確認することができます。
また、以下の図にあるタスク0とタスク1の開始時刻、終了時間を比較すると、ほぼ同じタイミングで終了していることが分かります。
バッチには60秒スリープを入れていたので、並列処理されていなければ、同じタイミングで終了することはないので、意図したとおり並行処理がされたことが分かります。
では、次に直列実行してみます。
タスク数は2のままで、以下の図のように並列処理のところを、「できる限り多くのタスクを同時実行する」ではなく、「同時タスクの数を制限する」にチェックして、並列処理のカスタム上限を1に変更して実行します。

出力されたログは以下の図のようになっています。
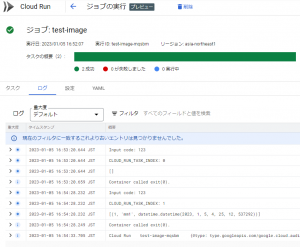
タスク0で実行されたバッチは、環境変数CLOUD_RUN_TASK_INDEXが0、タスク1で実行されたバッチは、環境変数CLOUD_RUN_TASK_INDEXが1になっています。
また、直列実行されてタスク0が終わってから、タスク1が実行されていることが分かります。
またバッチはCLOUD_RUN_TASK_INDEXの値を元に、SELECT * FROM testusers WHERE id = ?としていたので、タスク0はid = 0でSQLが実行され対象データがなく、[]と出力されています。
タスク1はid = 1でSQLが実行されるため、idが1のデータが取得され[(1, ‘mm1’, …)]と出力されています。
7. ジョブのスケジュール実行
Cloud Run jobsのジョブのスケジュール実行は、以下の図のようにCloud Run jobsの対象ジョブの画面にある、トリガータブから設定することができます。
スケジューラトリガーを追加をクリックすると、以下の図のようにスケジュール登録ができます。
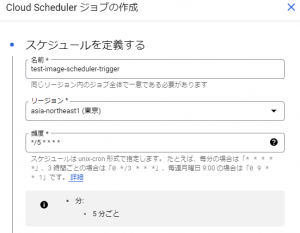
今回は5分間隔で設定しました。
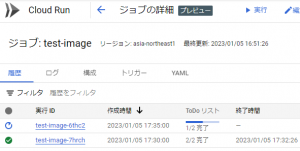
すると、以下の図のように5分間隔で実行させることができました。
8. まとめ
非常に簡単にCloud Run jobsのジョブ作成・実行ができることが分かりました。
Cloud Run jobsにはタスクの最大処理時間は1時間というような制限はありますが、Cloud Run jobsの要件を満たすようなバッチの場合、かなり手軽に利用できるのではないかと感じました。
ただ、新しいサービスでこれからバッチを作っていくといったプロジェクトだと良いですが、実際には、現状GCEで実行しているバッチを、サーバーレス化して運用コスト削減をしたい、バッチが増えてきたので分散したい、バッチの依存関係を考慮した実行をさせたいなど、既存システムの改善の取り組みとしてGCP BatchやCloud Run jobsなどのクラウドサービスの利用を検討することのほうが多いのではないかと思っています。
そうなると、すでに長時間実行されるようなバッチが存在している。そもそも並列で実行すれば効果が得られるような設計のバッチになっていない。
もはやどのように構築した分からないようなGCE上でバッチが動いていて、同等のモジュールがインストールされるようなDockerfileを用意する方が大変といったように、Cloud Run jobsのメリットを活かせないケースもそれなりにあるのではないかと思います。
なので前回実施したGCP Batchと今回のCloud Run jobsで、どちらが良いとは言えないですが、それぞれの特徴を理解することで、既存バッチの移行を含むのであれば、VMインスタンステンプレートを利用してバッチ実行できるGCP Batchのほうが移行しやすい、Spotインスタンスを利用してコスト削減できるかもといった判断や、新しいサービスでバッチ処理が必要になったが、まだ本格的にバッチシステムを構築するまでもない段階だから、Cloud Run jobsを利用してみるといった判断ができるようになるのではと思いました。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




