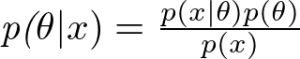2018.12.26
メタ学習(meta-learning)の紹介:Deep Reinforcement LearningとLSTMの関連技術
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
前回のブログでは、メタ学習(meta-learning)のコンセプトを紹介し、簡単な実装で、MAMLというメタ学習の有名なアルゴリズムを使って、東京の気温を予測してみました。今回のブログでは、もう少し深くメタ学習についての最新技術を勉強しながら、メタ学習の最新論文を紹介したいと思います。
このブログの構成は、以下のとおりです。
① メタ学習と関連技術のおさらい
② 最新論文の紹介
③ まとめと考察
① メタ学習と関連技術のおさらい
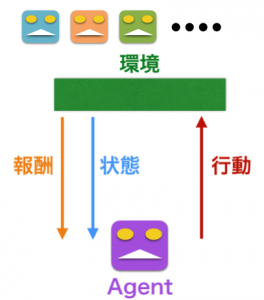
近年、機械学習(特に深層強化学習:deep reinforcement learning)という人工知能(AI)の学習技法が進化してきていて、人が見出せないことをデータから見つける専門的能力が高くなってきました。機械は沢山のデータから学習することで、よりよい判断が可能となり、ゲームで人間を打ち負かすことができるようになりました。しかし、人間ができることで、機械がまだできない主な課題が二つあります。ひとつ目は、人間は少ない経験からでもタスク内容が理解できますが、機械は理解するために沢山のデータを学ぶ(学習する)必要があります。もう一つは、人間はある条件だけを学んでも他の条件に適応することが可能ですが、機械の適応性はまだ不十分です。
この二つの課題に挑戦するため、メタ学習という技術の研究が広がってきました。メタ学習とはなにか前回のブログでも紹介しましたが、今回は少しだけをおさらいさせて頂きます。
メタ学習は機械が学習する能力を高めるのを目的として、学習プロセスを学んでいくということ(learning to learn)です。学習プロセスを理解することで、機械が自分自身で人間のように、少ないデータ量でもタスク内容を認識し、他のタスクにも適応できるようになると期待されています。このため、多くの研究者がメタ学習に様々な機械学習技術を組み合わせて、より人間らしくなっていくアルゴリズムを発展してきました。その中、よく使われている技術は最近人間に勝つことができた深層強化学習(deep reinforcement learning)です。深層強化学習は機械が結果のよい報酬を期待し、行動を適化するように、試行錯誤を重ねる学習です。この前のブログでも話しましたので、参考にして頂ければと思います。
また、これから話していく内容を理解するため、もう二つキーワードを把握することが必要です。一つ目はマルコフ決定過程(Markov Decision Processes; MDPs)、二つ目は長・短記憶(Long short-term memory; LSTM)です。
MDPsは状態遷移が確率的に生じる動的システムの確率モデルです。MDPで天気の状態遷移を例として説明します。例えば、晴れの翌日の天気は50%の確率で晴れとします。今日が晴れた場合、明日は50%晴れ(確率=0.5)の可能性があります。明後日の晴れ確率は0.5×0.5=0.25なので、25%晴れの可能性があることが予測できます。同じような雨や曇の確率も計算できます。そうすると、様々な組み合わせが出てきます。様々の条件の確率値に対しての起こりやすさは確率分布として表見できます。MDPは天気の確率分布を利用し、現在の天気の状態を見て、次の天気の予測を判断するというプロセスになります。この後、MDPと確率分布という話がまた出てきますので、MDPに慣れていない方はこの二つの用語を覚えて頂ければと思います。実は強化学習の試行錯誤のプロセスもMDPのコンセプトを利用しています。MDPsについての詳細はこのブログ がおすすめです。
LSTMは時系列データを解析し、将来を予測する技術です。時系列解析の基本的アプローチとしては、各時刻ステージに思い出を入れる箱のようなメモリセル(memory cell)を作り、情報を記録していくようなものがありますが、LSTMはもっともっと長い期間を記録できるようにするため、思い出箱をベルトコンベアで繋いでいくようなアプローチをとります。ベルトコンベアのようなものをセル状態(cell state)と言います。セル状態のおかけで、LSTMは時系列的な情報を繋ぐことができるようになります。今後、セル状態の話が出てきますので、イメージを覚えて頂ければと思います。詳細はこのブログ がおすすめです。日本語版もあります。
② 最新の論文紹介
多くのメタ学習の研究では、様々なタスクの答えを見つけ出すため、タスクの順番を考えず、一つずつタスクを拾って、学習プロセスを学習し、繰り返して正解を見つけていきます。この時、機械に多くの情報を入力するため、沢山のタスクの中に、似たようなタスクや同じタスクが再び現れる可能性があります。そのような場合、メタ学習が同じことを繰り返し、再学習しますので、冗長な作業を行うことになります。よりよい学習効率を高めるため、理想的には、機械が以前の学習の結果を取得し、現在学習しようとしているタスクが再び学習するかどうかを認識した上で、再学習すべきかどうか判断する必要があります。しかし、現在のメタ学習システムではまだそのような想起(リコール)のサポートに適応していません。この問題を解析するために、今年2018年6月にこの論文「Been There, Done That: Meta-Learning with Episodic Recall」が誕生しました。論文のタイトルを見てみると、「とうとう、やった、メタ学習がエピソード的に想起できる」という話のニュアンスが感じられますが、具体的に、この論文ではなにができるのか、どうやってリコール問題を解決できるのか、を共有したいと思います。数式の詳細などは論文内で書かれているため、要点だけをお話ししたいと思います。
さて、論文が注目したメタ学習の問題解明化とその問題を乗り越えるための解析提案を簡単にまとめさせていただきます。
論文に注目されたメタ学習の問題解明化
上に述べたように、この論文は学習したことがあったタスクを無駄に再学習しないため、タスクの表現性、再発性が認識できるようなアイデアを提案しました。
具体的に、普段のメタ学習はすべてのタスクをマルコフ決定過程(Markov Decision Process: MDPs)でタスク分布D(task distributions D)を定義し、m~DとしてMDPサンプリングを繰り返しています。ここで、新規や再発タスクの開始と終了の順番(sequence)を構築するため、MDPs mと共に確率論(stochastic)的なタスクプロセスのcontexts(コンテクスト、文脈)cを提案しました。
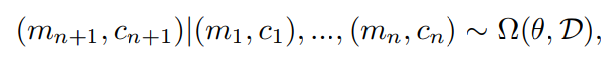
MDPと共にコンテクストを付けると、学習内容を把握でき、学習するときのタスクの順番に追いつくことが可能になります。しかし、その順番はどうやって特定するのか、特定できたら、どうやって再使用するのかは次の課題になります。
問題を乗り越えるための解析提案
このセクションはタスクの再発時の特定と再利用というこの論文の主題になります。この課題を解決するため、まず、この論文はdeep reinforcement learning agentsを適応します。アルゴリズムは「Learning to Reinforcement Learn(L2RL)」という論文に提案されたフレームワークを利用します。 L2RLはdeep reinforcement learning とLSTMを組み合わせた技術です。細かく言うと、L2RLはメタ学習の一つの種類であるメタ強化学習のタスクの学習プロセスを効率よく学習するため、LSTMを適用するものです。そこで、L2RLではLSTM-based agentsが含まれ、そのagentsがタスク分布するために適切な誘導バイアスを利用し、新しいタスクを探求するために学習します。L2RLはLSTM構造を利用しているため、タスク内の学習内容を取得することができ、早く新しいタスクを探検することが可能ですが、再発タスクを利用することがまだできません。そこで、今回主に紹介する論文の著者が「人間のエピソード記録は過去の作業記憶状態を取り出すこと」という事実を真似て、L2RLにエピソードメモリシステム(episodic memory system)を追加しました。エピソードメモリシステムとはセル状態(cell state)と状況から得られる手掛かりを保存し、その後、似たような手がかりが見つかったら、記録セル状態を取り戻すことです。このアイディアを実現するため、differentiable neural dictionary (DND)が適用されました。DNDは配列の各行にkey/value(キーと値)のペアを格納します。keyはタスクコンテクスト(task context c)、valueはLSTMセル状態(LSTM cell state)を表します。こうすると、タスク内容に基づいた過去の探査の結果を検索でき、L2RLでは情報が忘れられてしまう課題を解決することが可能になります。
図1はこの論文が提案したモデルアーキテクチャと構造です。この構造はL2RLとepisodic LSTM(eqLSTM)の組み合わせですので、epL2RLと定義されました。
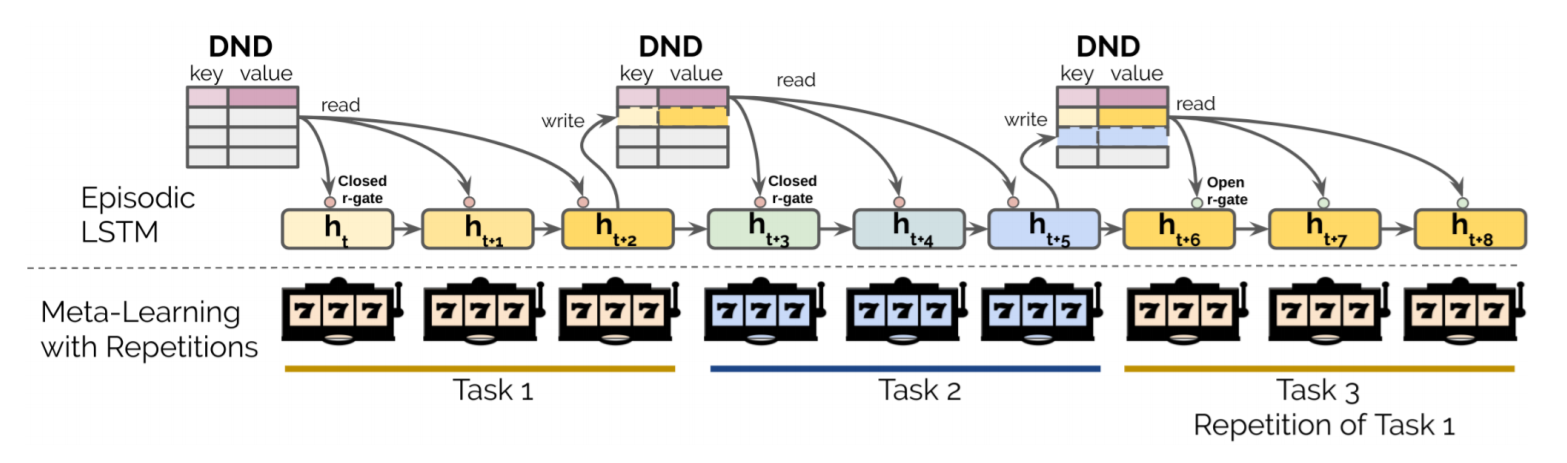
図1:モデルアーキテクチャと構想論文の図を転載
eqL2RLの全体的な学習の流れはどういう感じなのかを説明させて頂きます。まず、学習するときに、タスク1, 2, 3を順番で学習していきます。カラーバーは学習終了具合をイメージしてください。濃い色は学習済みです。例えば、タスク1でDNDからのkey/value(タスクコンテクスト/LSTMセル状態)情報をr-gate(multiplicative reinstatement gate: 情報を復帰するための入り口)経由でepLSTMに読み込みます。ここまで、まだなにも学習したことがないのを認識した上で、学習が始まります。タスク終わると、タスクコンテクストとLSTMセル状態をDNDのkeyとvalueに書き込みます。それから、タスク2の学習が開始します。タスク1と同じくDNDから情報を取得し、タスク2はタスク1と違うコンテクストを認識して、最初から最後までタスクを学習していきます。終わると、タスク3の学習が続きます。ここに注目してください。タスク3はタスク1の再発です。タスク3の学習が開始するときに、DNDから過去の学習履歴を読み込みます。そうすると、DNDの情報から、タスク3はもう学習したことがあるのを認識し、r-gate経由でお知らせします。そこで、もう一度再学習する必要がなくなるので、r-gateが開き、同じタスクコンテクストでの学習済みLSTMセル状態がタスク3のLSTMセル状態に入れ替わってタスク3の学習は再学習せずに学習が終了にします。
また、具体的にシステムの詳細構造の中に、epLSTMは普通のLSTMとどう違うのか、r-gateはどこに追加されたのか、見て行きましょう。図2を参考して下さい。グレーは一般的なLSTMで、彩色したものはepLSTMに新しく追加されたものです。一番注目していただきたいのはreinstatement-gate(rt)です。
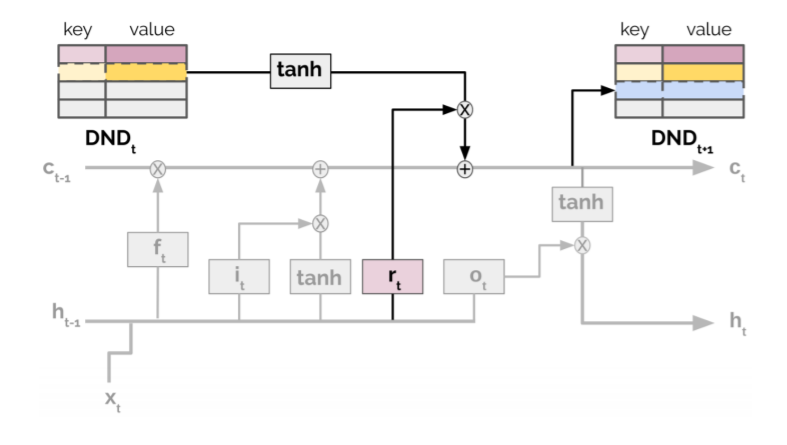
図2:The episodic LSTM。論文の図を転載
基本的に、LSTM自身は時系列解析に強く、過去の情報を利用しながら、タスクの中にある長期的な依存関係を学習することができます。著者がこのLSTMの強さを適応し、タスクの現在使用しているメモリと取り戻す状態の特別な関係を利用しました。
普通のLSTMはゲートiとfがあります。
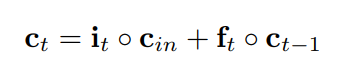
この論文に復活メモリ状態が追加されました。
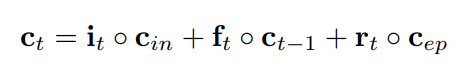
このrはゲートiとfと同じように式が作られました。ゲートrがDNDにつながって、DNDを読み込むことができ、学習履歴で参考した上、タスクの再学習が必要かどうかを判断します。
ゲートrが追加されたことで、eqL2RLが時系列で過去に学習したタスクを明確に認識し、学習効率が高めながら、人間らしく学習できるようになってきたと感じます。
③ まとめと考察
今回はメタ学習の最新技術の理論を紹介しました。実装的な実験はまだ行っていませんが、機会があったら、試してみたいと思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD