2021.07.07
Google Cloud PlatformでクラウドネイティブなHadoopクラスタを作ってSpark+Delta Lake+BigQueryを試してみた
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
今までオンプレミス環境を前提に自前で仮想サーバーを構築して、色んなHadoopの技術検証をしてきました。どこかでクラウドネイティブな構成も試さないとなーと思ってましたが、今回その機会が得られたので、遂に!?Google Cloud Platformでの構成を試すことにしました。
といっても仮想サーバーを自前で立てるのでは今までやってきたことなので、今回はGoogle Cloud Platformのマネージドのサービスを活用して、クラウドネイティブなHadoopクラスタを検証してみることにします。
やりたいこと
Hadoop界隈の最近の流れと勝手に思っているのは、ストレージノードとコンピュートノードを分離してスケーラブルな構成にすることです。計算リソースが足りないときはコンピュートノードだけたくさん増やして処理が終わったら減らして元に戻す、といった使い方でコストを抑えながら処理時間も減らせることがメリットですね。オンプレミス環境では動的にノードを増やしたり減らしたりするのは難しいことの一つなので、クラウドを活用するならまずこの構成です。
そして、ストレージノードの分離。より正確にはストレージをHadoopクラスタのノードと分離、でしょうか。Hadoopクラスタを構成するHDFSのノードをメインのストレージノードとしてしまうと、データが増える度に仮想サーバーを増やさないといけなくなってしまいます。データが巨大になるとたくさんのストレージノードが必要で、コンピュートノードと分離すると余計に全体のノード数を増やすことになりかねません。そうはしたくないですね。
スケーラブルで、低コストで、バージョン変更に強いHadoopクラスタを作る
そこで、ストレージノードの代わりに、クラウドに必要不可欠なオブジェクトストレージにデータを置くことができれば一番良いやり方になります。オブジェクトストレージは低コストでたくさんのデータを保存でき、クラウドのどのサービスからでも入出力できるのが強みなので、それを活かさない手はありません。
クラウドネイティブなHadoopクラスタ構成への要求をまとめると、すでに見出しに書いちゃってますが、
- スケーラブル
- 低コスト
- バージョン変更に強い
の3つが挙げられます。
1のスケーラブルはクラウドなら程度の差こそあれ大体満たしてくれますね。2の低コストは普段は安いストレージに置いておいて処理する時だけ取り出してシステムリソースを消費した分だけ課金、になるべく近付けられるかです。3のバージョン変更に強いというのは、システム移行の負担が少ないということです。オンプレミス環境などでインフラ運用を少しでも経験したことがある方はよくわかると思いますが、5年や10年も使っていると技術が古くなって技術負債になるので、新しいバージョンの技術を使ったシステムに移行しないといけなくなり、これが最も重たい業務の一つなんですよね・・。
この3つの要求を満たすには、Hadoopクラスタからストレージノードを分離してやることが最も肝心で、これらをシステム要件として洗い出してみると、
- ストレージノードとコンピュートノードを分離
- ストレージノードにオブジェクトストレージを使う
- 必要に応じてコンピュートノードを増やしたり減らしたりする
- オブジェクトストレージにあるデータをテーブルとして簡単に扱いたい
となりました。
急に4つ目を付け足した感じですが、データを扱うのに手間がかかるのもあまりモダンな構成とは言えないですよね。簡単にデータを扱うにはやっぱりSQLが一番で、今回検証するGoogle Cloud Platformには最も強力なBigQueryがあります。オブジェクトストレージにあるデータをBigQueryで手間をかけずに扱えるかどうかも大事なポイントです。
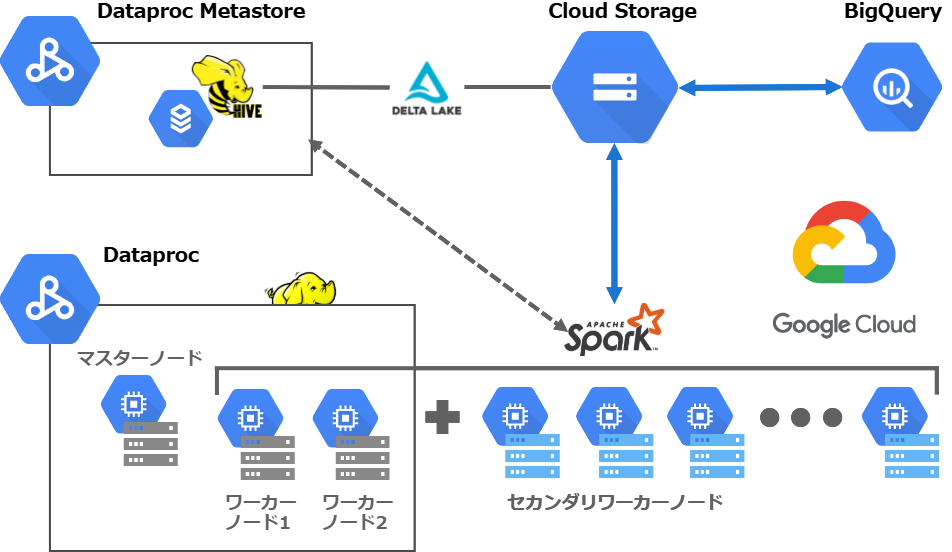
Cloud Storage(GCS)にHiveテーブルを直接置いてBigQueryを使う
HadoopでデータをデータベースのテーブルのようにSQLライクに扱う技術といえばHiveです。Hiveのテーブル管理をGoogleのオブジェクトストレージのCloud Storageに適用してSparkで処理できるかと、Sparkで処理したデータのテーブルをBigQueryで手間をかけずに参照できるかを今回の検証項目の一つにしました。前者をやるための肝となるのが、後で触れるGoogle Storage Connectorです。後者はBigQueryの外部テーブル機能を利用します。
BigQueryは一般的にはCloud StorageなどからデータをBigQuery側に取り込んで使うことが多いと思いますが、データ取り込みも管理が後々大変になるのでなるべくしたくありません。そこで今回はCloud StorageのテーブルデータをBigQueryの外部テーブルとして直接読むやり方を試しました。
クラウドネイティブなHadoopクラスタ構築
上記のやりたいことに書いたことを満たすクラスタがクラウドネイティブなHadoopクラスタですね。
兎にも角にも先ずDataproc
マネージドサービスを利用してHadoopクラスタを構築する場合、Google Cloud PlatformにはDataprocというサービスがあるので、それを使うことになります。でも別のやり方として、Dataprocを使わずにCloud Storage(GCS)とKubernetes Engine(GKE)だけを使うこともできます。Hadoopクラスタのコンテナを自分で作っておいて、処理するときだけKubernetesからそのコンテナをデプロイして終わったら削除するというやり方です。こちらの方がストレージノードとコンピュートノードを分離する構成において理想形に近い、よりモダンな感じですね。ただ、Hadoopクラスタのコンテナを自前で構築・管理しなくてはいけなくてその点は手軽ではありません。このやり方は次回以降の検証に取っておこうと思います。
というわけでDataprocでHadoopクラスタを作ります。
最小構成で作る
Dataprocを使って最小構成でHadoopクラスタを作ります。Dataprocは以下のように設定して作成します。DataprocではHadoopのレプリカ数はデフォルトで2になっているようで、データノード(Dataprocではワーカーノード)を2台にします。今回はマスターノード1台とワーカーノード2台を最小構成としました。Hadoopを本番運用するときは通常はHDFSのNameNodeやYARNのResourceManagerの冗長化が必須です。その場合マスターノードを複数台立ててそのうえで冗長化をするのが定石なので、クラスタタイプを高可用性にします。ただ、今回試しているクラウドネイティブなHadoopクラスタの構成は大事なデータはCloud Storageで保存できているので、Hadoopクラスタがおかしくなったら作り直すことができます。まさにこれがオンプレミス環境では絶対できないクラウドのメリットですね。
いくら最小構成といってもHadoopクラスタを構成するノードのスペックが低すぎるとうまく動かないことが起きかねないので、ある程度のスペックにしておく方が良いです(特にメモリ。8G以上はあるべき)
| クラスタ全体 | |
|---|---|
| クラスタタイプ: | 標準(マスター1個、ワーカーN個) |
| リージョン: | asia-northeast1(東京) |
| 自動スケーリング: | ポリシー:None |
| バージョニング: | 2.0(CentOS 8, Hadoop 3.2, Spark 3.1) |
| コンポーネント: | オプションコンポーネント →どれも選択しない |
| ネットワークインターフェース: | ネットワーク →default、サブネットワーク →default |
| プロジェクトアクセス: | 同一プロジェクトですべてのGoogle Cloudサービスに対するAPIアクセスを許可します →選択する |
| マスターノード | |
| マシンタイプ: | n1-standard-4(vCPU x 4、メモリ 15GB) |
| メインディスク: | サイズ →200GB、Primary disk type →Standard Persistent Disk |
| ローカルSSDディスク: | なし |
| ワーカーノード | |
| マシンタイプ: | n1-standard-4(vCPU x 4、メモリ 15GB) |
| Number of worker nodes: | 2 |
| メインディスク: | サイズ →200GB、Primary disk type →Standard Persistent Disk |
| ローカルSSDディスク: | なし |
Google Storage Connectorが一番のポイント
Dataprocで作ったHadoopクラスタを使ってSparkの分散処理を試すにあたり、そのクラスタのHDFSにあるデータではなく、Dataprocの外側にあるCloud Storageのデータをどう読み込むかが課題になると思いますが、実はGoogle Cloud Platformでは最初からソリューションが提供されちゃってまして、それがGoogle Storage Connectorです。
DataprocではGoogle Storage Connectorが最初からどのノードからでも使えるようになっています。使い方もとても簡単で、hdfs/hadoopコマンドやSparkのプログラム内で、データを示すパスを書く際に「gs://」から始まるCloud Storageのデータへのパスを書くだけです。つまり何も特別なことをしないで済みます。
Google Storage Connectorを通してDataprocのHadoopクラスタとCloud Storageがシームレスに連携できていることが、クラウドネイティブな構成にとって大事なストレージノード分離の一番のポイントです。
データを用意してSparkの分散処理を試す
DataprocのHadoopクラスタができたら、今度はデータを用意します。自分が検証でいつも使っているアイオワ州のお酒販売のサンプルデータを使いました。
PARQUETフォーマットのデータをCloud Storageに
SparkではカラムナストレージであるPARQUETのデータフォーマットがよく使われると思いますが、PARQUETフォーマットのデータをCloud StorageにSparkから読み書きできるかをまず試してみました。最初、前回のブログで作ったオンプレミスのHadoopクラスタ環境でサンプルデータをSparkを使ってPARQUETフォーマットに変換し、そのデータをCloud Storageに突っ込んでみたのですが、エラーが出て読み込むことができませんでした。
pyspark.sql.utils.AnalysisException: Unable to infer schema for Parquet at . It must be specified manually
スキーマ(=テーブルのカラム定義)がわからないから手動で定義して読み込めというエラーですが、オンプレミス環境でスキーマを定義してPARQUETフォーマットに変換しているので、通常なら一度作れば問題なく読み込めるはずです。オンプレミス環境のSparkと今回のDataprocのSparkで同じ3系でも完全に同一バージョンではないので、そのあたりの問題かもしれません。バージョン変更に強いHadoopクラスタを作るにはもっと調査する必要がありますが、今後の課題とします。
今回は深追いせずにCSVフォーマットのサンプルデータをCloud Storageに上げて、Dataprocの環境でPARQUETフォーマットを作り直しました。いきなりすべてのデータをspark-submitして分散処理をすると、デバッグしづらくてハマりこむので、サンプルデータから大きく件数を減らしたテストデータを用意してまずPySparkクライアントを使って試しました。
このときはDataprocのコンソールからDataprocのマスターノードにssh接続してPySparkクライアントを利用しました。
from pyspark import SparkContext
from pyspark.sql import Column, DataFrame, SparkSession, SQLContext, functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from py4j.java_collections import MapConverter
import sys
spark = SparkSession \
.builder \
.appName("test-spark-dataproc") \
.getOrCreate()
tab_schema = StructType([
StructField("invoice_item_number", StringType(), False),
StructField("sale_date", DateType(), False),
StructField("store_number", IntegerType(), True),
StructField("store_name", StringType(), True),
StructField("address", StringType(), True),
StructField("city", StringType(), True),
StructField("zip_code", IntegerType(), True),
StructField("store_location", StringType(), True),
StructField("county_number", IntegerType(), True),
StructField("county", StringType(), True),
StructField("category", StringType(), True),
StructField("category_name", StringType(), True),
StructField("vendor_number", IntegerType(), True),
StructField("vendor_name", StringType(), True),
StructField("item_number", IntegerType(), True),
StructField("item_description", StringType(), True),
StructField("pack", IntegerType(), True),
StructField("bottle_volume", IntegerType(), True),
StructField("state_bottle_cost", StringType(), True),
StructField("state_bottle_retail", StringType(), True),
StructField("bottles_sold", IntegerType(), True),
StructField("sale", StringType(), True),
StructField("volume_sold_liters", FloatType(), True),
StructField("volume_sold_gallons", FloatType(), True),
])
load_path = "gs://test-bucket01/csv_test"
tab_location = "gs://test-bucket01/parquet_iowa_liquor_sales"
checkpoint_location = tab_location + "/_checkpoints/streaming_ckp"
spark \
.readStream \
.format('csv') \
.options(header='true', inferSchema='false', quote='"', dateFormat='MM/dd/yyyy') \
.schema(tab_schema) \
.load(load_path) \
.writeStream \
.format('parquet') \
.outputMode('append') \
.option('checkpointLocation', checkpoint_location) \
.start(tab_location)
df = spark.read \
.parquet(tab_location)
PySparkクライアントから上記のようにSparkのStructured Streamingを使ってテストデータのCSVをPARQUETフォーマットのデータに変換しました。Cloud Storageへのパスを「gs://」から始まるパスにしています。これはうまくいって、ちゃんとCloud Storageにデータが書き込まれました!
セカンダリワーカーを追加して使う
テストデータでうまくいったので、次にすべてのサンプルデータをspark-submitでCSVからPARQUETフォーマットに変換します。
最小構成のままなので、ここでコンピュートノードを追加してみます。Dataprocではセカンダリワーカーがそれに該当します。通常のワーカーノードと違ってHDFSのデータノードとしては組み込まれません。そしてセカンダリワーカーにもプリエンプティブルと非プリエンプティブルの2種類があります。デフォルトはプリエンプティブルです。プリエンプティブルのセカンダリワーカーを選ぶと、Google Cloud Platformの都合によってセカンダリワーカーの仮想サーバー自体が削除されることもあります。その分コストが安くなりますが、長時間かかる重要なバッチを走らせるときは非プリエンプティブルのセカンダリワーカーにした方が良さそうです。
注意点としては一つのHadoopクラスタでは、プライマリワーカー(HDFSに組み込まれる通常のワーカーノード)をゼロにできないのと、プリエンプティブルと非プリエンプティブルの2種類のセカンダリワーカーを混在させることができません。プリエンプティブルのセカンダリワーカーを追加する場合、削除される可能性があることを考えると、安定稼働させるにはワーカーノードの総数の50%未満にした方がよいと推奨されています。
このあたりはワークロードにあわせて最適な構成を考える必要がありそうです。バッチ毎に開始時にセカンダリワーカーを作って処理後にすべて削除するとか、プリエンプティブルと非プリエンプティブルのセカンダリワーカーで別々にHadoopクラスタを構築してしまうといった大技も簡単できちゃうので、オンプレミス環境ではまずできない運用を考えることができますね。
セカンダリワーカーの追加自体はコンソールからでもコマンドからでも簡単にできます。公式ドキュメントに丁寧に書いてあるのでそちらをみて見てください。今回は非プリエンプティブルでセカンダリワーカーを3台追加しました。
セカンダリワーカーが追加できたところで、すべてのサンプルデータのPARQUETフォーマット変換を行います。先に結果を言うと、うまくいかなくてかなりハマりました・・。幾つかの理由でエラーが出ていてそれを対応していったんですが、最後までspark-submitすると何故か上記のPySparkクライアントでできたStructured Streamingがうまく動かない問題が残り、エラーが一見出ないもののCloud Storageにデータが作成されない状態に。結局Structured Streamingを諦めて通常の読み書きにしたら処理できました。Structured StreamingとCloud Storageの問題か、Structured StreamingとDataprocのセカンダリワーカーの問題か、何か根深い問題がありそうで今後の課題にしようと思います。
上記のPySparkのプログラムを以下の箇所だけ書き換えてiowa_liquor_sales_parquet.pyというファイルに保存、
#!/usr/bin/env python3
load_path = "gs://test-bucket01/csv_data"
tab_location = "gs://test-bucket01/parquet_table/iowa_liquor_sales"
spark \
.read \
.format('csv') \
.options(header='true', inferSchema='false', quote='"', dateFormat='MM/dd/yyyy') \
.schema(tab_schema) \
.load(load_path) \
.write \
.format('parquet') \
.mode('append') \
.save(tab_location)
iowa_liquor_sales_parquet.pyを以下のようにspark-submitしたらうまくいきました。そこまで大きなデータではないんでですが、なかなか速く処理が終わった印象です。
spark-submit \ --master yarn \ --deploy-mode cluster \ --executor-memory 4G \ --driver-memory 2G \ --conf spark.driver.memoryOverhead=1G \ --conf spark.executor.memoryOverhead=1G \ iowa_liquor_sales_parquet.py
spark-submitでCloud Storageにデータを書き込めたので今度は読み込めるか試してみます。上記のようにPySparkクライアントに接続してセッションを張り、以下のようにデータフレームとして読み込んで一時的にテーブル扱いできるようにして参照しました。値がちゃんと返ってきたので、SparkでCloud StorageにPARQUETフォーマットでデータを読み書きすることができることがわかりました。
tab_location = "gs://test-bucket01/parquet_table/iowa_liquor_sales"
df = spark.read.parquet(tab_location)
df.createOrReplaceTempView("iowa_liquor_sales")
q = "SELECT * FROM iowa_liquor_sales ORDER BY sale_date DESC, volume_sold_liters DESC LIMIT 20"
spark.sql(q).show(truncate=False)
Hiveテーブルを簡単に管理して使う
SparkでCloud Storageにデータを読み書きできることがわかったら、今度は簡単にCloud Storageのデータをデータベースのテーブルのように扱えるかを試します。それにはSparkではHiveのテーブル定義管理を使うんですが、選択肢が二つあります。一つは、自前でHiveのテーブル定義を格納するデータベース(Cloud SQL)を立ててHiveメタストアを使うための特別な設定や作業をしたDataprocのHadoopクラスタを作るか、マネージドのメタストアのDataproc Metastoreを利用してクラスタを作るかです。Dataproc Metastoreは比較的最近安定版が出たのもあって、今回はこちらを使って簡単にやってみようと思います。
フルマネージドのDataproc Metastoreを使ってみる&Hadoopクラスタ再構築
Dataproc Metastoreを使うのは難しいことはしません。Dataprocにあるメタストアのメニューに行ってDataproc Metastoreのサービスを以下のような設定で新規作成し、DataprocのHadoopクラスタをそのDataproc Metastoreサービスを使うように新しく作り直します。ストレージノードをCloud Storageに分離しているので、Hadoopクラスタを作り直しても困らないのが本当に良いところ。
気を付けるところはバージョンで、Dataprocのバージョンを2.0(Hadoop 3.2, Spark 3.1)にしているとMetastore versionはデフォルトで選択状態になっている2.3.6にするとうまくいきませんでした。一つ上の最新バージョンの3.1.2にする必要があります。
| Dataproc Metastore | |
|---|---|
| サービス名: | {メタストアの任意の名前} |
| Data location: | asia-northeast1 |
| Metastore version: | 3.1.2 |
| Release channel: | Stable |
| Service tier: | Developer |
| ネットワーク: | default |
Dataproc Metastoreを作った後でDataprocのHadoopクラスタを作り直す際、以下の設定を一つ付け加えます。
| クラスタ全体 | |
|---|---|
| Metastoreサービス | {作成したメタストアの名前} |
Delta LakeフォーマットのテーブルをCloud StorageにSparkで作る
Dataproc Metastoreを使う準備ができたら、SparkSQLを使ってHiveテーブルを作ってみます。PARQUETフォーマットでできたので、以前のブログで検証したDelta LakeのフォーマットでCloud Storageにテーブルを作ってみることを思いつきました。Delta LakeはDatabricksが開発したフォーマットですが、保存される実体のファイルはPARQUETフォーマットだからですね。
まずHiveのデータベースを作成します。Oracleデータベースでいうところのスキーマです。PySparkクライアントで接続して作業しますが、Delta Lakeを利用するようなオプションをつけて接続します。Delta Lakeは最近1.0になったのでそのバージョンを指定しました。
pyspark \ --packages io.delta:delta-core_2.12:1.0.0 \ --driver-memory 4G \ --executor-memory 4G \ --conf spark.driver.memoryOverhead=1G \ --conf spark.executor.memoryOverhead=1G \ --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" \ --conf "spark.delta.logStore.class=org.apache.spark.sql.delta.storage.HDFSLogStore"
PySparkに接続したらCloud StorageにLOCATIONを指定してCREATE DATABASE文でlakehouseという名前のHiveデータベースを作成してみます。Sparkのセッションを作る際に、enableHiveSupport()をつけます。
from pyspark import SparkContext
from pyspark.sql import Column, DataFrame, SparkSession, SQLContext, functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from py4j.java_collections import MapConverter
import sys
spark = SparkSession \
.builder \
.appName("test-spark-dataproc") \
.enableHiveSupport() \
.getOrCreate()
ddl = """
CREATE DATABASE lakehouse LOCATION 'gs://test-bucket01/lakehouse.db'
"""
spark.sql(ddl)
何かエラーでも出るかもと思いましたが、ここまであっさりといけました。
spark.sql("use lakehouse")
ddl = """
CREATE TABLE iowa_liquor_sales (
invoice_item_number STRING,
sale_date DATE,
store_number INTEGER,
store_name STRING,
address STRING,
city STRING,
zip_code INTEGER,
store_location STRING,
county_number INTEGER,
county STRING,
category STRING,
category_name STRING,
vendor_number INTEGER,
vendor_name STRING,
item_number INTEGER,
item_description STRING,
pack INTEGER,
bottle_volume INTEGER,
state_bottle_cost STRING,
state_bottle_retail STRING,
bottles_sold INTEGER,
sale STRING,
volume_sold_liters FLOAT,
volume_sold_gallons FLOAT
)
USING DELTA
PARTITIONED BY (sale_date)
"""
spark.sql(ddl)
今作ったlakehouseデータベースに移動して、sale_dateという日付カラムでパーティショニングしたDelta Lakeのテーブルを作成してみましたが、問題なくできていました。
Delta Lakeのテーブルを作ったらいよいよデータを挿入します。先ほどspark-submitで作ったPARQUETフォーマットのデータを外部テーブルにして、SparkSQLからINSERT SELECT文でやってみようと思います。
ddl = """ CREATE EXTERNAL TABLE iowa_liquor_sales_parquet ( invoice_item_number STRING, sale_date DATE, store_number INTEGER, store_name STRING, address STRING, city STRING, zip_code INTEGER, store_location STRING, county_number INTEGER, county STRING, category STRING, category_name STRING, vendor_number INTEGER, vendor_name STRING, item_number INTEGER, item_description STRING, pack INTEGER, bottle_volume INTEGER, state_bottle_cost STRING, state_bottle_retail STRING, bottles_sold INTEGER, sale STRING, volume_sold_liters FLOAT, volume_sold_gallons FLOAT ) STORED AS PARQUET LOCATION 'gs://test-bucket01/parquet_table/iowa_liquor_sales' """ spark.sql(ddl)
上記のように外部テーブルを作成したら、以下のプログラムをiowa_liquor_sales_deltalake.pyというファイルに保存、
#!/usr/bin/env python3
from pyspark import SparkContext
from pyspark.sql import Column, DataFrame, SparkSession, SQLContext, functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from py4j.java_collections import MapConverter
import sys
spark = SparkSession \
.builder \
.appName("test-spark-dataproc") \
.enableHiveSupport() \
.getOrCreate()
dml = """
INSERT INTO iowa_liquor_sales SELECT * FROM iowa_liquor_sales_parquet
"""
spark.sql('use lakehouse')
spark.sql(dml)
iowa_liquor_sales_deltalake.pyを以下のようにspark-submitしました。
spark-submit \ --packages io.delta:delta-core_2.12:1.0.0 \ --master yarn \ --deploy-mode cluster \ --executor-memory 4G \ --driver-memory 2G \ --conf spark.driver.memoryOverhead=1G \ --conf spark.executor.memoryOverhead=1G \ --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" \ --conf "spark.delta.logStore.class=org.apache.spark.sql.delta.storage.HDFSLogStore" \ iowa_liquor_sales_deltalake.py
問題なく処理できて、コンソールからCloud Storageのブラウザを見ると日付ごとにパーティショニングされて(ディレクトリが分かれて)PARQUETフォーマットのデータファイルができていました!
BigQueryで外部テーブルを作りCloud Storage上のDelta Lakeのテーブルを参照してみる
最後にBigQueryからCloud Storageに作成したDelta Lakeのテーブルを読み込めるか試してみます。
BigQueryでデータセットを作成し(asia-northeast1のリージョンでlakehouseというデータセットにしました)、BigQueryの外部テーブルを作成します。最初、CREATE TABLE文のDDLを試したんですが、うまくいかず。
-- (失敗例1) CREATE EXTERNAL TABLE lakehouse.iowa_liquor_sales( invoice_item_number STRING, store_number INT64, store_name STRING, address STRING, city STRING, zip_code INT64, store_location STRING, county_number INT64, county STRING, category STRING, category_name STRING, vendor_number INT64, vendor_name STRING, item_number INT64, item_description STRING, pack INT64, bottle_volume INT64, state_bottle_cost STRING, state_bottle_retail STRING, bottles_sold INT64, sale STRING, volume_sold_liters FLOAT64, volume_sold_gallons FLOAT64 ) WITH PARTITION COLUMNS ( sale_date DATE ) OPTIONS ( uris=['gs://test-bucket01/lakehouse.db/iowa_liquor_sales/*'], format=PARQUET, hive_partition_uri_prefix='gs://test-bucket01/lakehouse.db/iowa_liquor_sales' ); -- (失敗例2) CREATE EXTERNAL TABLE lakehouse.iowa_liquor_sales WITH PARTITION COLUMNS ( sale_date DATE ) OPTIONS ( uris=['gs://test-bucket01/lakehouse.db/iowa_liquor_sales/*'], format=PARQUET, hive_partition_uri_prefix='gs://test-bucket01/lakehouse.db/iowa_liquor_sales' );
上記のDDLでは、PARQUETフォーマットはカラム定義できないと怒られたり、パーティションキーと関係ないディレクトリが’gs://katano-bucket01/lakehouse.db/iowa_liquor_sales/’配下にあることで怒られたようです。SparkからDelta Lakeのテーブルを作ると、テーブルのパスの直下にパーティションのディレクトリとは別に_delta_logというディレクトリも作られます。CREATE TABLE文のオプションのhive_partition_uri_prefixで指定したパスにパーティションと関係ないディレクトリがあるとダメみたいです。
そこで、下記のような書き方をしたらテーブルを作ることができました。
-- (失敗例3)
CREATE EXTERNAL TABLE lakehouse.iowa_liquor_sales
OPTIONS (
uris=['gs://test-bucket01/lakehouse.db/iowa_liquor_sales/*'],
format=PARQUET,
hive_partition_uri_prefix='gs://test-bucket01/lakehouse.db/iowa_liquor_sales/{sale_date:DATE}'
);
データを見ることができたので良かったと思っていたら、実はこのテーブルもうまくいってなかったみたいで、全件カウントするクエリを投げたら怒られてしまいました・・。
試行錯誤した結果、結局コンソールから以下のように作成することでうまくいきました。
| ソース | |
|---|---|
| テーブルの作成元: | Google Cloud Storage |
| GCSバケットからファイルを選択: | test-bucket01/lakehouse.db/iowa_liquor_sales/*.parquet |
| ファイル形式: | Parquet |
| ソースデータパーティショニング: | →チェックする |
| ソースURIの接頭辞を選択: | gs://test-bucket01/lakehouse.db/iowa_liquor_sales |
| パーティション推論モード: | 独自推定 →チェックする |
| +フィールドを追加 →押す | 名前 →sale_date、型 →DATE |
| 送信先 | |
| プロジェクト名: | test-study01 |
| データセット名: | lakehouse |
| テーブルタイプ: | 外部テーブル |
| テーブル名: | iowa_liquor_sales |
実はコンソールからでも何回か失敗したんですが、「GCSバケットからファイルを選択」でパスの最後に「*.parquet」と付けたのが効きました。Delta Lakeテーブルの実体はPARQUETフォーマットのファイルと言いましたが、拡張子が「.parquet」なので、これを付けることでパーティションと関係ないディレクトリやファイルが混ざっていても怒られずにデータを読み込んでくれるようです。
BigQueryの外部テーブルを通して、Cloud StorageにあるDelta Lakeのテーブルデータを見ることが遂にできました!本番運用を考えると、データサイズが巨大なテーブルのときのパフォーマンスなどの問題もきっとあると思いますが、Cloud Storageへの外部テーブルを基本にして、必要なものだけBigQuery側にデータを取り込んだり、データ解析したいときだけBigQuery側にテーブルを作ったりすると、低コストでBigQueryをうまく使えそうですね。
まとめ
冒頭のやりたいことに書いた3つの要求(スケーラブル、低コスト、バージョン変更に強い)とそれを基にした4つの要件(ストレージノードとコンピュートノードの分離、ストレージノードにオブジェクトストレージを使用、コンピュートノードの増減、オブジェクトストレージのデータをテーブルとして扱う)は今回の構成で結構満たせそうなことがわかりました。
バージョン変更に強い、というところはもっと検証や工夫がいる感じでしたが、それでもオンプレミス環境よりはだいぶ手軽にいけそうです。そしてコスト面。オンプレミス環境とクラウドネイティブな環境でどちらが低コストか、というのはデータや処理の規模・ランニングコスト・構築運用にかかる人手のコストなどをどう考えるかで変わってくるので一概には言えないですが、今回の構成の中でいうと、DataprocのディスクとDataproc Metastoreが比較的コストかかる結果となりました。
課金単位のSKUでみると、この二つです。
- Storage PD Capacity in Japan
- Dataproc Metastore Service Developer Tier Hours
検証なので使わないときはDataprocのHadoopクラスタはこまめに停止してはいたんですが、クラスタ停止してもDataprocのディスクはサイズに応じて?継続的に幾らかかかっていそうなのと、Dataproc Metastoreはとても便利ですが時間課金で停止がないのである程度コストがかかりそうです。といっても規模との兼ね合いなので、本番環境でかなりの規模なら相対的に安上がりになるかもしれないですね。
今後の課題
- バージョン変更の更なる検証
- Sparkのバージョンが混在したときに、Cloud Storageへのデータの読み書きどうなるか。
- Kubernetes構成の検証
- Dataprocを使わずにCloud StorageとKubernetes Engineの構成を試す(ついでにSpark on Kubernetesも検証)。
- Dataproc Metastoreのエクスポートとインポート
- Dataproc Metastoreを作り直す検証(削除→作成を自動で繰り返してコストを抑えられるかも試してみたい)。
このあたりの課題はまた機会を改めていつかやってみたいと思います。
最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD