2021.01.12
Hadoop+Spark+Delta LakeのクラスタにApache Zeppelinを繋いでみた
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
今回はSparkとDelta Lakeに関する前回の検証で残る課題の一つだった、BIツールとの連携を検証してみました。BIツールには、Sparkによる分散処理をメインに考えているので、Sparkと親和性の高いApache Zeppelinを試してみました。
1.Apache Zeppelinについて
Apache ZeppelinはQiitaのこちらの記事にわかりやすく書かれています。私も最初参考にさせていただきました。記事にあるとおりSparkを中心にした高機能なOSSノートブックです。
Apache Zeppelinで何ができるかというと、様々なデータソースのデータを処理したり、抽出したり、簡易グラフを作成できたりします。BigQuery、Cassandra、Elasticsearch、Hadoop、MongoDBなどのデータを扱えるようになっていて、JavaやPython、Sparkなどが使えます。JDBC経由でもアクセスできるので多くのRDBにも接続できると思います。
今回使いたいメインはSparkです。BIツール等がない場合、Hadoopなどのビッグデータを処理するには、sparkやpysparkのプログラムを書いて毎回spark-submitを実行することになってちょっと面倒です。Apache Zeppelinは設定を最初にしておけば、spark-submitをユーザーが意識しなくてもデータを扱うことができます。
さらにBIツールっぽくSQLだけである程度ビッグデータをノートブックで処理してみたいので、SparkSQLを使ってSQLだけでHadoop(+Delta Lake)上のビッグデータを扱うのを試してみます。
2.Apache Zeppelinのインストール
それではまずインストールをしてみます。前回、前々回の検証のHadoopクラスタ環境に、Apache Zeppelin用のノードを構築することにしました。Hadoop上のビッグデータを扱うためにHadoopと連携することを前提にした準備・設定を行います。
Apache Zeppelinは検証時の最新の0.9.0-preview2を使ってみることにしました。システム要件にOpen/Oracle JDK 1.8.151以上とありますが、今回はそのバージョン以上のOpen JDKがすでに入っている環境を使うので問題ありません。
前々回の検証で最初にHadoopクラスタの構築/管理ツールのAmbariを入れようとしたノードに、Apache Zeppelinをインストールします。インストール方法は、バイナリをダウンロードして展開し必要な準備をするだけです。
# バイナリダウンロード
wget https://ftp.kddi-research.jp/infosystems/apache/zeppelin/zeppelin-0.9.0-preview2/zeppelin-0.9.0-preview2-bin-all.tgz
tar zxvf zeppelin-0.9.0-preview2-bin-all.tgz
# ユーザー&グループ作成
groupadd hadoop
useradd -N -g hadoop zeppelin
chown -R root:hadoop /usr/hadoop/hadoop-3.2.1
chmod 775 /usr/hadoop/current/etc/hadoop
chown -R zeppelin:hadoop zeppelin-0.9.0-preview2-bin-all
mkdir /usr/zeppelin
chown zeppelin:hadoop /usr/zeppelin
mv zeppelin-0.9.0-preview2-bin-all /usr/zeppelin/
cd /usr/zeppelin
ln -s zeppelin-0.9.0-preview2-bin-all current
# Apache ZeppelinとHadoopクラスタ連携に必要なディレクトリを作成
mkdir -p /var/log/{hadoop,yarn,zeppelin}
mkdir -p /var/run/{hadoop,yarn,zeppelin}
chown -R zeppelin:hadoop /var/log/{hadoop,yarn,zeppelin}
chown -R zeppelin:hadoop /var/run/{hadoop,yarn,zeppelin}
chmod 775 /var/log/{hadoop,yarn,zeppelin}
chmod 775 /var/run/{hadoop,yarn,zeppelin}
上記のように展開してZeppelin用ユーザーと必要なディレクトリを作成しておきます。
続いて、zeppelinユーザーの環境変数を整えます。
# zeppelinユーザー
cat << _EOF_ >> ~/.bash_profile
export JAVA_HOME=/usr/lib/jvm/java
export HADOOP_HOME=/usr/hadoop/current
export PATH=\${HADOOP_HOME}/bin:\${HADOOP_HOME}/sbin:\${PATH}
_EOF_
Apache Zeppelinを構築しようとしているノードには、既にJAVAとHadoopが入っているのでそれぞれのホームディレクトリの環境変数をセットします。
ただ、まだSparkが入っていないので、Hadoopクラスタ環境の方に入れたspark-3.0.0-bin-hadoop3.2.tgzのバイナリを展開します。
# spark-3.0.0-bin-hadoop3.2.tgzを準備 tar zxvf spark-3.0.0-bin-hadoop3.2.tgz chown -R zeppelin:hadoop spark-3.0.0-bin-hadoop3.2 mkdir /usr/spark mv spark-3.0.0-bin-hadoop3.2 /usr/spark/ cd /usr/spark ln -s spark-3.0.0-bin-hadoop3.2 current
Hadoopクラスタ環境と連携するにはこれで終わりではなくて、Hadoop、YARN、Sparkの設定ファイル一式をコピーしておく必要があります。
# Hadoopクラスタの一つのノードで設定ファイル一式をtarで固める cd /etc/hadoop tar zcvf /tmp/hadoop_conf.tar.gz hadoop-env.sh yarn-env.sh workers topology.sh core-site.xml hdfs-site.xml yarn-site.xml cd /etc/spark tar zcvf /tmp/spark_conf.tar.gz spark-env.sh spark-defaults.conf hive-site.xml
hadoop_conf.tar.gzとspark_conf.tar.gzを、Apache Zeppelinを構築するノードにコピーして、/etc配下に配置します。
# /etc配下に各confディレクトリのシンボリックリンクを張っておく cd /etc ln -s /usr/hadoop/current/etc/hadoop hadoop ln -s /usr/spark/current/conf spark ln -s /usr/zeppelin/current/conf zeppelin cd /etc/hadoop tar zxvf hadoop_conf.tar.gz cd /etc/spark tar zxvf spark_conf.tar.gz
これでインストールは完了です!
3.Apache Zeppelinの設定
続いて、設定を行います。上述したQiitaの記事の設定編が参考になりますが、Apache Zeppelinは設定にかなり自由度があります。環境変数かプロパティのどちらかで設定するんですが、設定方法もzeppelin-env.shかzeppelin-site.xmlを編集するか、画面でインタープリター設定するかのいずれかで行います。
ただ、どれかでしか設定できないものもあり、ちょっとややこしいところがありました。設定する環境変数やプロパティの内容については、Apache Zeppelinの公式ドキュメント(0.9.0-preview2)を参照します。
3-1.環境変数の設定(zeppelin-env.sh)
先ず環境変数の設定を行います。JAVAのメモリなどの大事な設定は主に環境変数で行うので、先に色々調べて考えておく必要があります。
IPアドレスはApache Zeppelinを構築・起動するノードを指定して、ポートは何でも良いですが今回は8888としました。
Hadoop連携をする場合は、USE_HADOOP=trueを追記するように公式ドキュメントに書かれていたのでそのようにしています。
JAVA_HOME、SPARK_HOME、HADOOP_CONF_DIRも指定します。
# zeppelin-env.shファイルを作成 cd /etc/zeppelin cp zeppelin-env.sh.template zeppelin-env.sh # zeppelin-env.shを編集 export JAVA_HOME=/usr/lib/jvm/java export ZEPPELIN_ADDR="xx.xx.xx.xx" export ZEPPELIN_PORT=8888 export ZEPPELIN_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps" export ZEPPELIN_MEM="-Xms4069m -Xmx4069m -XX:MaxMetaspaceSize=512m" export ZEPPELIN_INTP_MEM="-Xms1024m -Xmx1024m -XX:MaxMetaspaceSize=512m" export ZEPPELIN_INTP_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps" export ZEPPELIN_INTERPRETER_OUTPUT_LIMIT=10240000 export ZEPPELIN_LOG_DIR=/var/log/zeppelin export ZEPPELIN_PID_DIR=/var/run/zeppelin export SPARK_HOME=/usr/spark/current export USE_HADOOP=true export HADOOP_CONF_DIR=/etc/hadoop
3-2.プロパティの設定(zeppelin-site.xml)
次にプロパティの設定をします。特定の箇所だけコメントアウトしたり、項目追加したりしないといけなくてミスしがちなところです。
連携したHadoopクラスタのリソース管理はYARNを前提にしているので、Apache Zeppelinからの処理もYARNのクラスターモードとなるように設定しました。YARNのための設定も公式ドキュメントに書かれています。
また、Apache Zeppelinのノートブックをどこに保存するかもプロパティで設定します。Hadoopクラスタ環境と連携しているので、今回はHDFS上に保存することにしました。
zeppelin.notebook.storageという項目の値がorg.apache.zeppelin.notebook.repo.FileSystemNotebookRepoとなっている設定だけを残して、他の値になっているzeppelin.notebook.storageの設定箇所はコメントアウトします。
# zeppelin-site.xmlファイルを作成 cd /etc/zeppelin cp zeppelin-site.xml.template zeppelin-site.xml
<!-- zeppelin-site.xmlを編集 --> ・zeppelin.server.addr(28行目)からzeppelin.server.ssl.port(44行目)までコメントアウト ・Notebook storage layer using hadoop compatible file systemの行を探し、この行だけコメントアウトし、zeppelin.server.kerberos.keytabとzeppelin.server.kerberos.principalはコメントアウトしたままの状態にする ・(350行目の)zeppelin.notebook.storageをコメントアウト <property> <name>zeppelin.spark.only_yarn_cluster</name> <value>true</value> <description>Whether only allow yarn cluster mode</description> </property> ・この後に以下の項目を追加 <property> <name>zeppelin.interpreter.launcher</name> <value>yarn</value> </property> <property> <name>zeppelin.interpreter.yarn.resource.memory</name> <value>2048</value> </property> <property> <name>zeppelin.interpreter.yarn.resource.memoryOverhead</name> <value>1024</value> </property> <property> <name>zeppelin.interpreter.yarn.resource.cores</name> <value>1</value> </property> <property> <name>zeppelin.interpreter.yarn.queue</name> <value>default</value> </property>
3-3.Apache Zeppelinの起動
インタープリターの設定は起動してから画面で行うので、ここでApache Zeppelinを起動してみます。起動シェルが準備されているのでそれを実行するだけです。
# zeppelinユーザーで実施 /usr/zeppelin/current/bin/zeppelin-daemon.sh start
実行したらすんなり起動するはずもなくお約束のエラー。/var/log配下のログを見てみると、どうやらHadoopのHDFSディレクトリで怒られていることがわかったので、HDFS上に/user/zeppelinディレクトリがないからなのかと思って作成しました。
それでも起動できず同じエラーが出るので一旦ルートディレクトリの/の権限をフルパーミッションにしてみたら、/userでなく/usr/zeppelinというディレクトリを作りたかったみたいでそれが作成できずエラーになっていました。Hadoopは慣習的に/user配下にユーザーディレクトリを作ることが多いので紛らわしいですね・・。
HDFS上に/usr/zeppelinができたら無事に起動できました!
補足
起動時に以下のWarningが出ました。short-circuit local readsをするために、libhadoopが必要ということみたいで、本番環境構築時はできるようにしておきたいところですが、今回はこのままにしています。
WARN [2020-12-10 20:09:14,286] ({ImmediateThread-1607598551834} DomainSocketFactory.java[<init>]:116) - The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
3-4.インタープリターの設定
最後にインタープリターの設定を行います。インタープリターとはApache Zeppelinで特定の言語やデータ処理を扱うためのプラグインのことです。インタープリターごとに設定をすることができます。
今回はSparkSQLを使うためsparkのインタープリターの設定を行います。
WebブラウザでApache Zeppelinが起動しているノードと8888ポートを指定して、画面を開きます。画面一番上のメニューバーの右端に「anonymous」と出ているのでそのプルダウンから「Interpreter」を選択します。
インタープリターの設定ページに遷移するので、sparkの設定項目までスクロールダウンするか、このページの上にある検索ボックスでsparkと検索します。
sparkの設定項目のところに行ったら、右上にある鉛筆マークの[edit]ボタンを押して以下を設定し、下の方に出てくる[save]ボタンを押します。
連携するHadoopクラスタ環境はSpark用のストレージであるDelta Lakeを使っているので、前回の検証と同じようにDelta Lakeを使えるようにする設定を入れました。インタープリターの設定でなくzeppelin-site.xmlでも設定できると思いますが、spark-submitを使うときによく変えそうなものは今回インタープリターの設定で行いました。
| Name | Value |
|---|---|
| spark.master | yarn |
| spark.submit.deployMode | cluster |
| spark.driver.memory | 2g |
| spark.executor.memory | 2g |
| spark.jars.packages | io.delta:delta-core_2.12:0.7.0 |
| PYSPARK_PYTHON | python3 |
| PYSPARK_DRIVER_PYTHON | python3 |
| zeppelin.spark.maxResult | 100000 |
下記の設定は既存の項目にないので、[edit]ボタンを押したあとに下の方に出てくる項目追加の[+]ボタンを使って追加します。設定したValueの型を指定する必要があり以下のようにしています。
| Name | Value | (型) |
|---|---|---|
| spark.sql.extensions | io.delta.sql.DeltaSparkSessionExtension | string |
| spark.sql.catalog.spark_catalog | org.apache.spark.sql.delta.catalog.DeltaCatalog | string |
| spark.delta.logStore.class | org.apache.spark.sql.delta.storage.HDFSLogStore | string |
| spark.sql.catalogImplementation | hive | string |
| spark.ui.enabled | (チェックしない) | checkbox |
これで全部の設定が終わりました!次はいよいよクエリの実行です。
4.SparkSQLだけでDelta Lakeのテーブルを参照する
検証の目的であるSparkSQLのクエリだけでHadoop(+Delta Lake)のビッグデータを扱えるかこれから試していきます。
最初にノートブックを作成します。画面の一番上のメニューバーの左端に「Notebook」とあるのでこちらから新規のノートブックを作成したり既存のノートブックを選択します。
4-1.先ずテーブル一覧を見る
とりあえずどのテーブルがあるかテーブル一覧をパッとを見れないちょっと不便と思うので、先ずはそれができるか試します。
SparkSQL(Spark)のインタープリターを使うには、ノートブックの各パラグラフで処理を書く冒頭に「%spark.sql」を付けます。
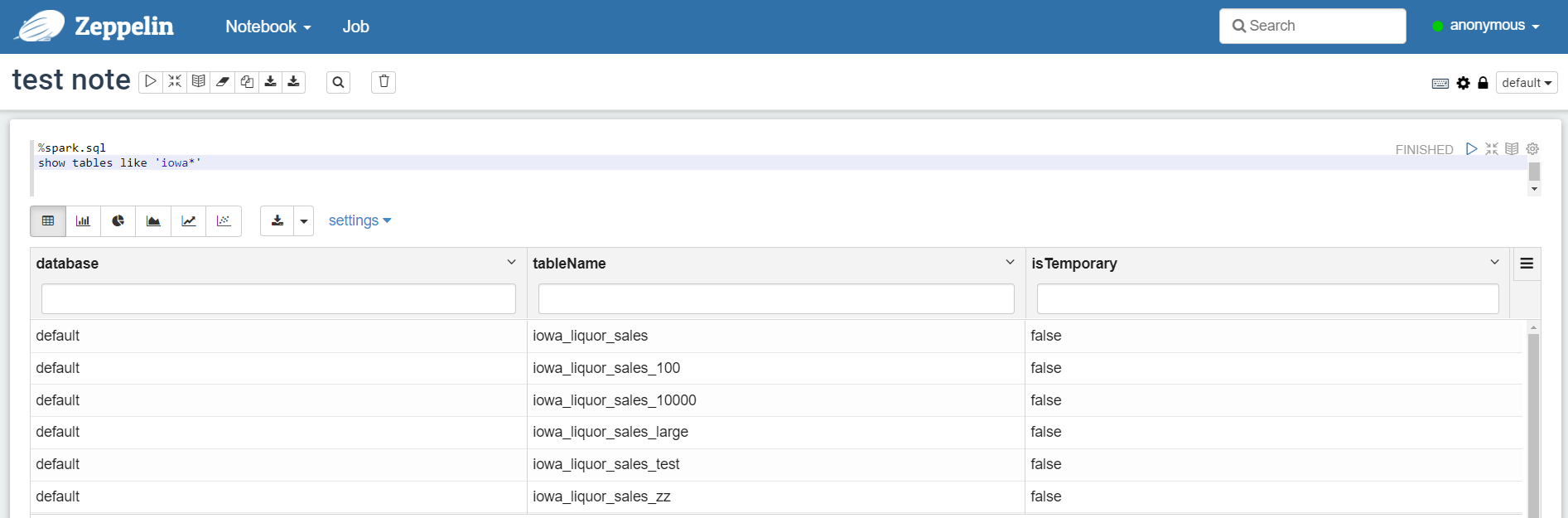
無事に結果が返ってきました!ちゃんとHadoop(+Delta Lake)と連携ができています。
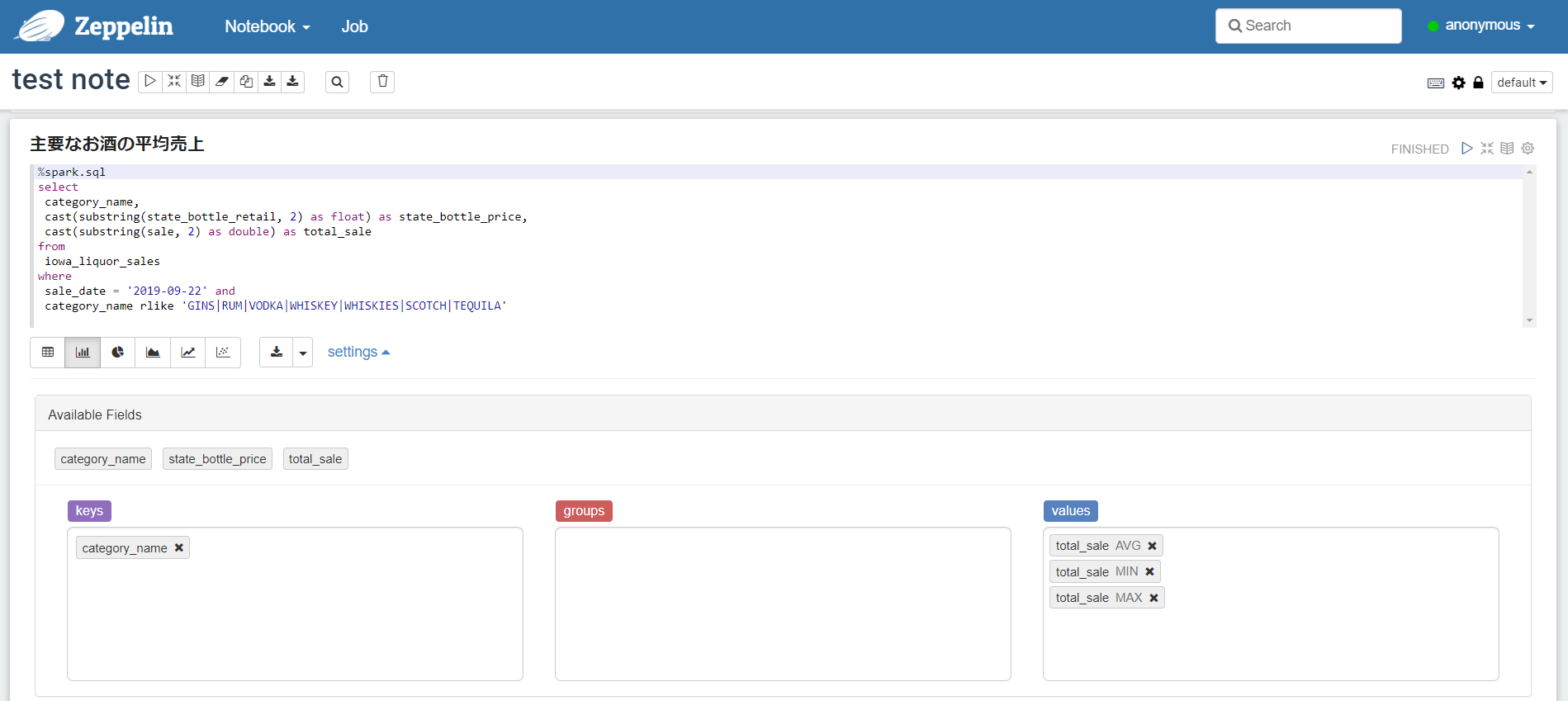
4-2.クエリからグラフを作る
今度はそれっぽいクエリを実行して、ノートブックで簡易グラフを作成してみます。クエリを実行するとデフォルトでは表形式で結果が表示されます。
ノートブックの所定のパラグラフでSQLを書いて、パラグラフ右上にある実行ボタン(右向きの三角のボタン)を押して実行します。
棒グラフに変える場合、keys(横軸:項目)とValues(縦軸:数値)を選択する必要があります。クエリ結果の項目が自動的に表示されてドラッグ&ドロップできるようになっています。ただしValuesは必ず合計/平均/MIN/MAXのいずれかに集計された結果になるので要注意です。
お酒の銘柄ごとの売上(total_sale)の平均/MIN/MAXを棒グラフにしてみました。
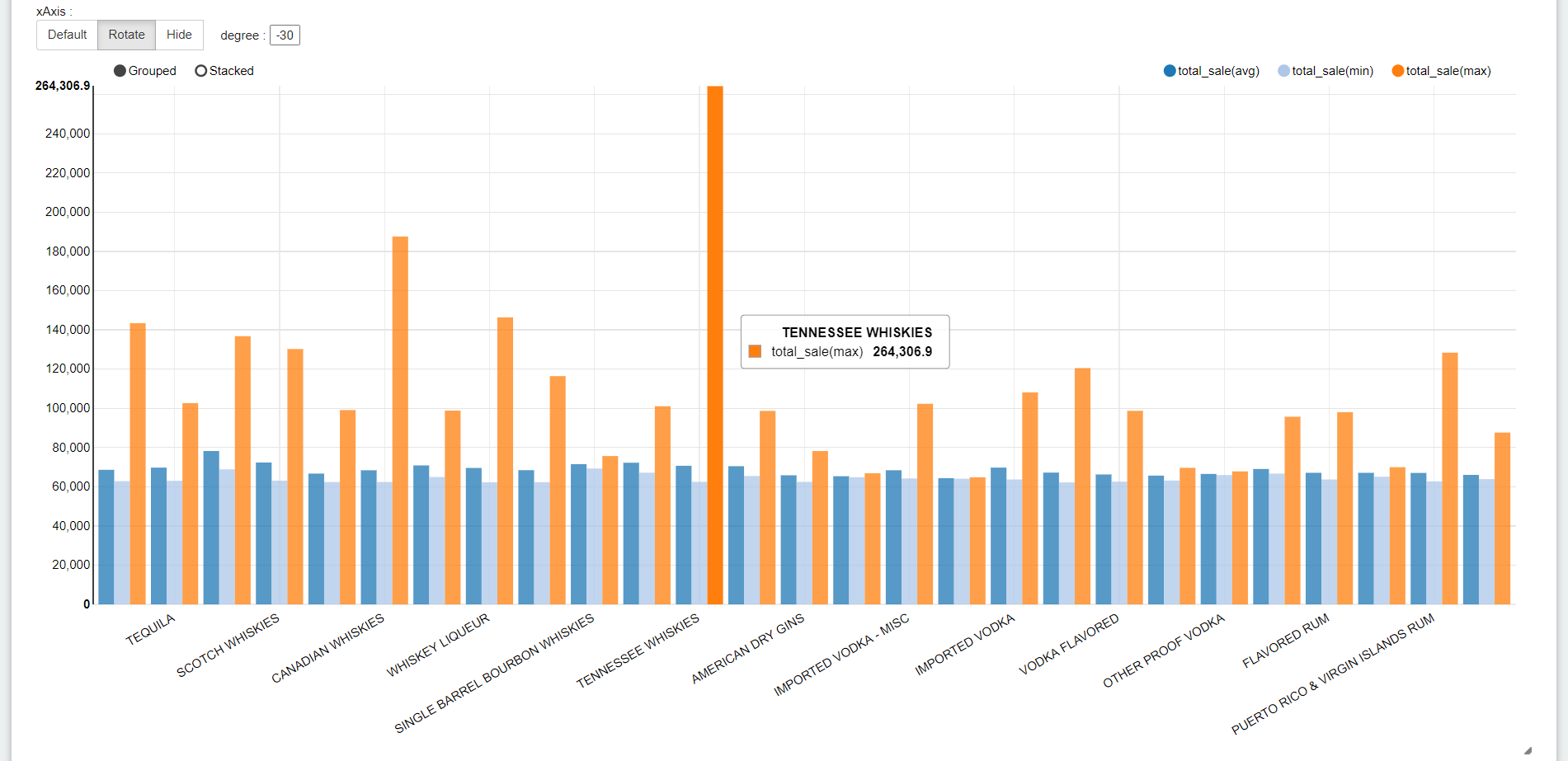
同じクエリ結果に対して今度は円グラフに変えてみます。Valuesが複数あると円グラフはわかりずらくなるのでtotal_sale(合計)だけにします。クエリを再実行しなくてもすぐに変換されます。
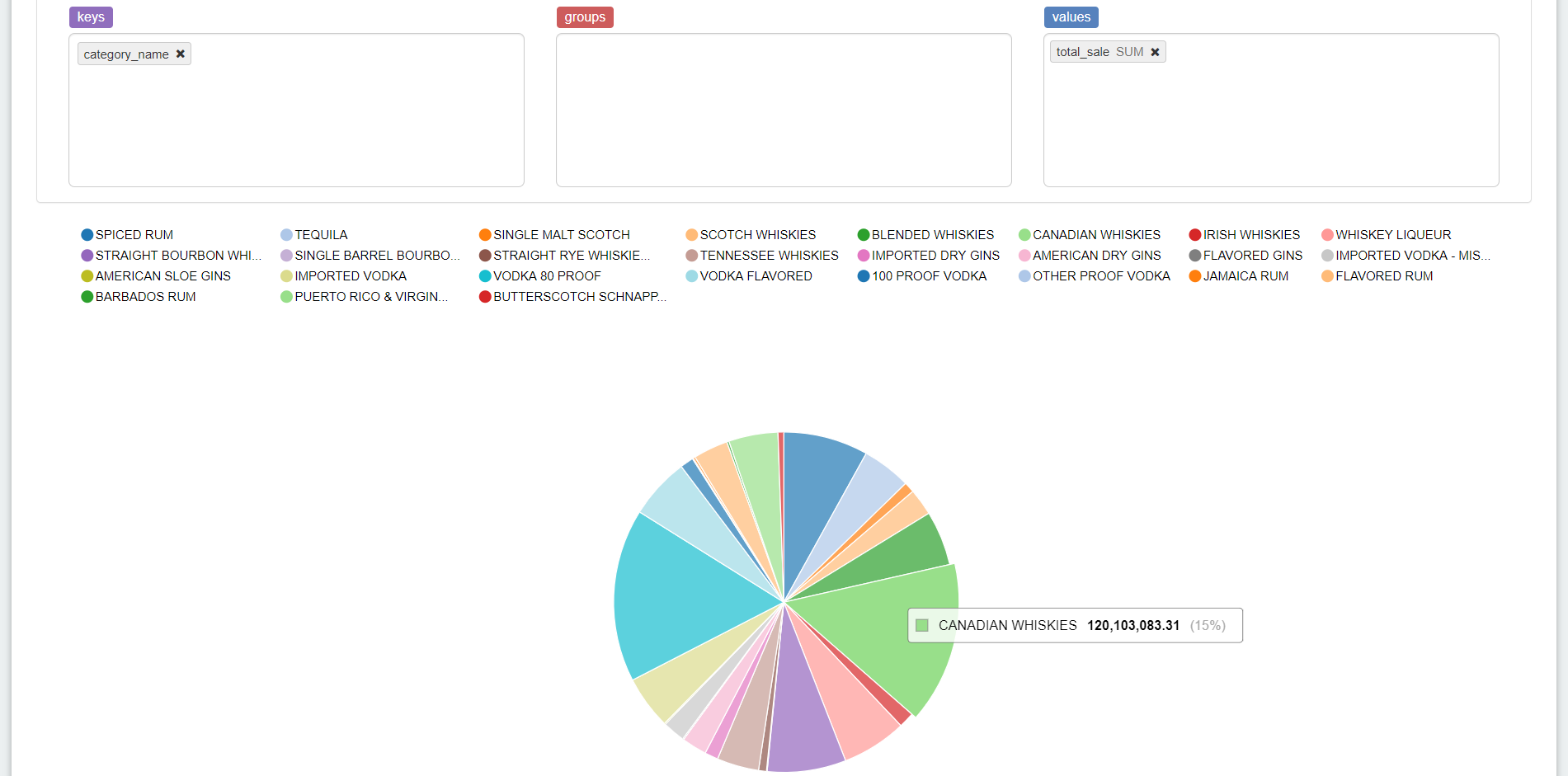
SQLだけで簡単にクエリの実行とグラフが作成できました!
4-3.巨大テーブルにクエリを投げる
最後に巨大テーブルにクエリできるかも試してみます。前回の検証でiowa_liquor_sales_largeというテーブルを作ったのですが、2億7700万件くらいのレコード、HDFS上のDelta Lakeフォーマットで15GB(プレーンテキストなら70GBくらい)のサイズがあり、このテーブルへクエリしてみます。
ちなみに上記のクエリのiowa_liquor_salesは1260万件ほどのレコード、HDFS上のDelta Lakeフォーマットで790MB(プレーンテキストで3.3GBくらい)のサイズです。
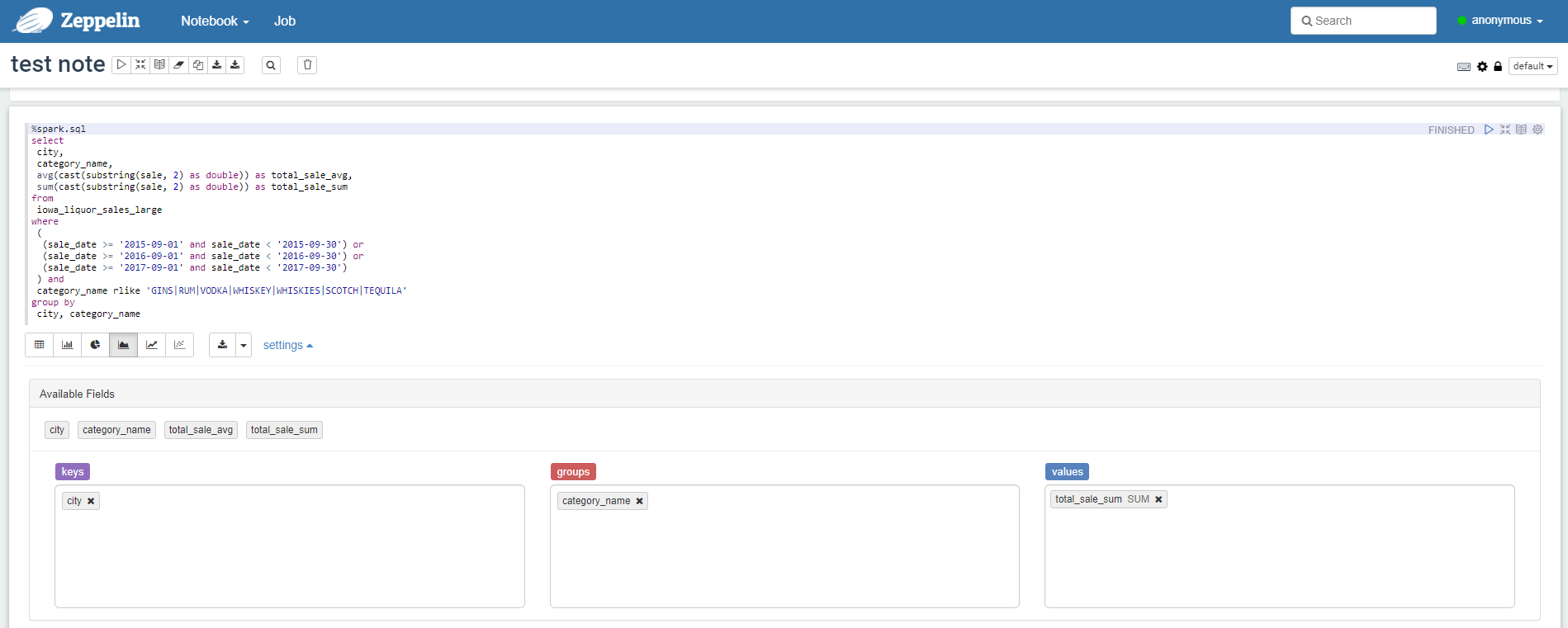
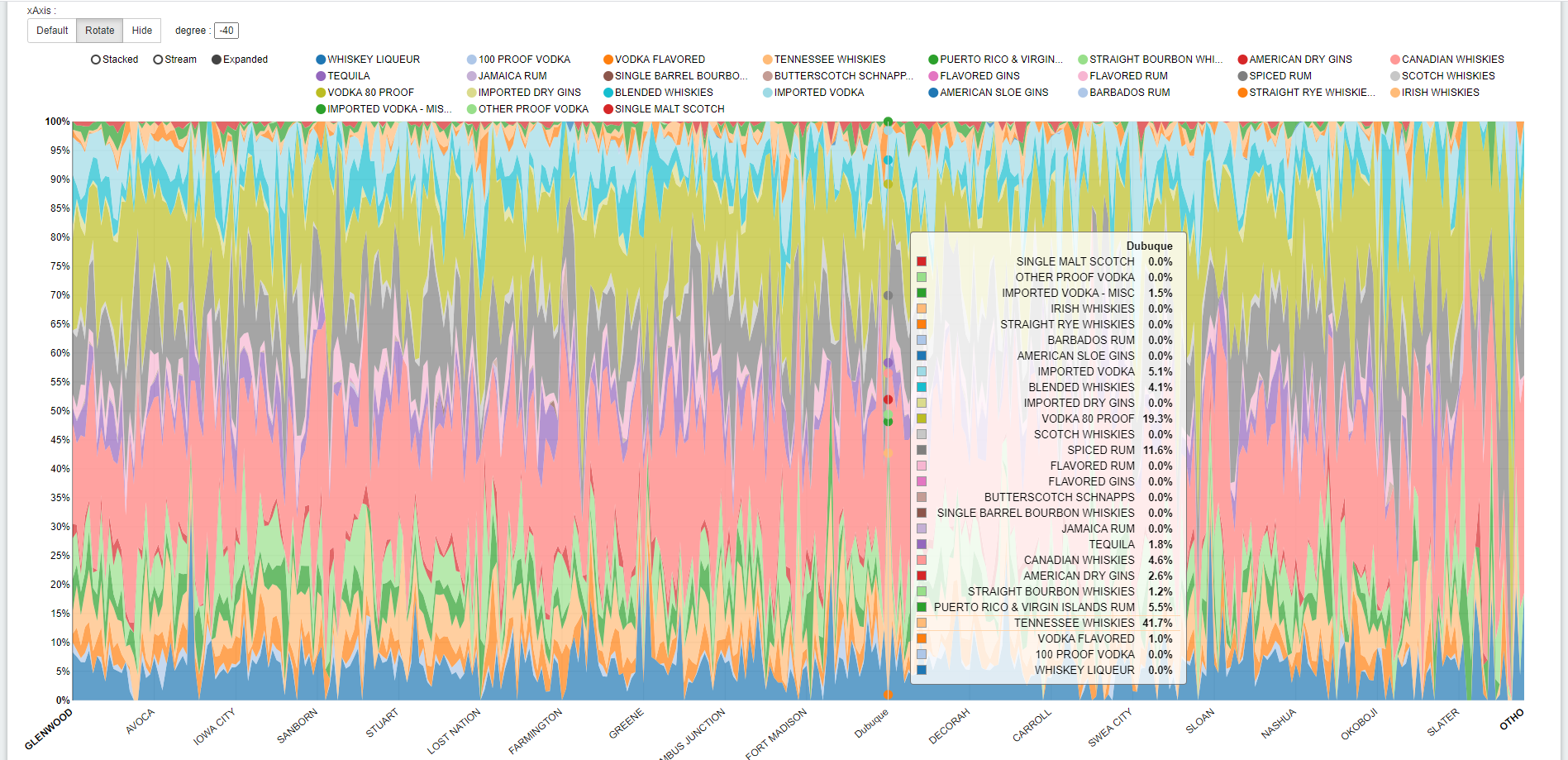
返ってきた結果の行数が多すぎると落ちてしまうので、group by句をかけたクエリにしましたが、巨大テーブルにも問題なく実行できました!
5.まとめ
Apache Zeppelinを構築してSQLだけで簡単にHadoop(+Delta Lake)クラスタ環境のビッグデータを処理できるかを検証しましたが、思ったよりスムーズにいきました。
前々回、前回、今回の一連の検証でHadoopクラスタ上にSpark(+Delta Lake)だけでビッグデータの解析環境を作れないかを試してみたわけですが、結構いけそうです!
Hiveを使わないでも、Spark+Delta Lake+Zeppelinの組み合わせだけである程度使える感じです。Apache Zeppelinのグラフはあくまで簡易的なものでしっかり解析するには足りないんだと思いますが、いちいちSparkやPySparkのプログラムを書いてspark-submitをしなくても、手軽にSparkのビッグデータへの分散処理ができてデータを抽出できるのは便利と思いました。
Sparkをメインに解析環境を構築するなら、Apache Zeppelinは手軽にデータ抽出できるツールとして有用なんではないでしょうか。
残る課題
BIツールとしては一度にたくさんのユーザーが同時に使うことが想定されるので、本番環境として使うなら同時接続のテストや設定が必要です。この点はいつか検証してみたいと思います。
6.最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




