2017.03.28
Apache Apex を使ってストリーム処理を書いてみよう
こんにちは。次世代システム研究室で Hadoop 周辺をよく触っている T.O. です。
Hadoop 周辺をよく触っているので、最近 Hadoop 周辺を触ってきて得た話などを書いていきます。
ということで今回は、数あるストリーム処理エンジンの中のひとつ Apache Apex を少々触ってストリーム処理を書いてみよう、という話を。
Apache Apex とは
ひとことで言えば、いわゆるストリーム処理エンジン。
ストリーム処理エンジンというと、 Storm, Flink, Heron, Spark Streaming, Gearpump, Beam, Nifi, Kafka Stream, … など、たくさんあるわけですが、そんな中で Apache Apex は、どのような特徴があるのでしょうか?
例のごとく、公式サイトを読め、という話になりますが、ぱっと目につく特徴を挙げると…
- YARN の上で動く
- Exactly Once ができる
- Java で書ける
- 関連情報を検索しづらい
があります。
YARN の上で動く
これは文字通りで、ストリーム処理が、 Hadoop YARN を使って動きます。
Apex によるストリーム処理は、 Operator と呼ばれるノードをつなげた DAG によって表現しますが、そのそれぞれの Operator が YARN の Container として動くわけです。
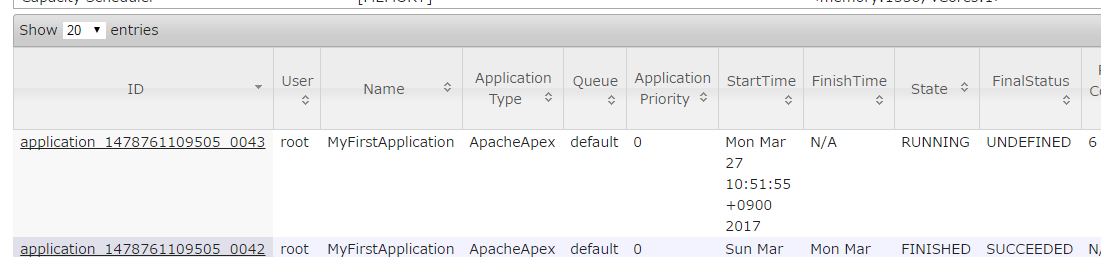
YARN のすぐ上で動くものとしての存在なので、 MapReduce や Tez や Spark と同じレイヤーの存在であり、 Resource Manager の WebUI における ApplicationType も下のスクリーンショットのように ApacheApex になっています。
もちろん「そもそも Hadoop 使ってないし、 Hadoop なしでストリーム処理をやっていきたい」という方にとっては、 YARN で動く、というのはメリットにならないどころか、ノックアウトファクターになるわけですが、 Hadoop を運用してるのであれば、そこそこにメリットになるのではないかと思います。
Exactly Once ができる
ストリーム処理エンジンというと、その特徴として、 At Least Once, At Most Once, Exactly Once のどれができるのか・できないのか、というポイントがありますが、 Apache Apex は Exactly Once ができます。
なぜこれができる、ということになっているかというと、 Checkpointing の仕組みがあるためです。
Checkpointing というのは、 Apache Apex – Development Best Practices の Checkpointing のセクションに書かれているとおり、 “Checkpointing is a process of snapshotting the state of an operator and saving it” 、つまり Operator の状態のスナップショットを取る仕組みです。
この機構を使って、 Operator を適切に実装すれば Exactly Once ができる、という話です。
逆に言えば、 Operator を実装する際に、そのあたりをちゃんと書かなければ、 Exactly Once にはなりません。
Java で書ける
「Apex によるストリーム処理は、 Operator と呼ばれるノードをつなげた DAG によって表現します」と書きましたが、その Operator や DAG は Java で書けます。
DAG については JSON やプロパティファイルでも定義できるようですが。
Java で書ける、という点は人によって受け取り方が変わってきそうですが、個人的には嬉しいポイントです…。
関連情報を検索しづらい
これは地味に痛いやつです。
Apex という語が、プロダクトやサービスの名前に打ってつけ(なにせ「頂点、先端、頂上、最高点」というような意味である)なので、検索で不利です。
しかも、多少、専門用語を含めたところで、 Salesforce が出している Apex というプログラミング言語があるため、そちらがひっかかることもしばしば。
ということで、 Apache Apex について調べるときには、少なくとも -salesforce を含めるべきです。
Apache Apex を使ってストリーム処理をやってみよう
さて、今回は試しに Apex を使ってみよう、というところなので、それなりにストリーム処理であることを活かせそうなことを考え、下記のような流れのシステムをつくってみました。
- 各サーバで dstat を実行して結果を取る
- dstat の結果を Fluentd で Kafka に送る
- Kafka から取り出して Apex に流し、 CPU 使用率が一定以上であれば Slack に通知する
なお、今回のメイントピックはあくまで Apex なので、 Fluentd と Kafka の細かい話はしませんが、 dstat の結果を Fluentd を利用して Kafka に入れるところは、 fluent-plugin-dstat と fluent-plugin-kafka を使うとかんたんにできます。ということで、以降では、 Apex の中でやることについて書いていきます。
Apache Apex での処理の流れ
今回は、以下のような流れの DAG を組みました。
- Apex Malhar の Kafka Input Operator を使って、 Kafka からメッセージを読み込む
- Apex Malhar の Json Parser を使って Kafka から読み取られたメッセージを POJO にする
- Apex Malhar の Filter を使って POJO にしたメッセージの内容を見て絞り込みをする
- Apex Malhar の Json Formatter を使って、絞り込まれた POJO を JSON の String に変換する
- Simple Slack API を利用する Operator を実装し、そこで再び JSON になったメッセージを Slack に書き込む
こうして、 Kafka から取り出したメッセージが、 Apex 内で絞り込まれ、最終的に Slack に書き込むことができています。
Apex Malhar
ところで、道具のリストでしれっと Apex Malhar というモノを書いていますが、これは、端的に言えば Apex の Operator 集です。
よく使うであろう基本的な Operator は Malhar に含まれています。
今回もほとんどの Operator は Malhar に含まれているモノを使っています。
短期間でストリーム処理アプリケーションを実装する上で、 Malhar の理解と利用は欠かせないものになると思います。
Operator を書く、ということ
前述のとおり、今回使った Operator はほとんどは Malhar に含まれているものですが、 Slack に書き込む Operator だけは独自に実装しています。
Malhar に含まれている Operator で事足りる分にはいいのですが、なければ独自に実装する必要があるわけです。
Operator の実装はそう難しいものではなく、 Apache Apex – Development Best Practices を参考にしつつ、 Malhar のリポジトリを覗き、 既存の Operator のコードを見てマネしていけばなんとかなります。
DAG を書く、ということ
DAG は Java か JSON かプロパティファイルで記述することができます。
DAG の記述については Application Developer Guide の Developing An Application のセクション以降をよく読めばわかりますが、参考までに今回、私が書いた Java による DAG の記述を貼り付けておきます。
public void populateDAG(DAG dag, Configuration conf) {
KafkaSinglePortInputOperator kafkaInputOp = dag.addOperator("KafkaConsumer", new KafkaSinglePortInputOperator());
JsonParser jsonParser = dag.addOperator("JsonParser", new JsonParser());
FilterOperator filterOp = dag.addOperator("Filter", new FilterOperator());
JsonFormatter jsonFormatter = dag.addOperator("JsonFormatter", new JsonFormatter());
SlackOutputOperator slackOp = dag.addOperator("SlackOutput", new SlackOutputOperator());
dag.addStream("toPOJO", kafkaInputOp.outputPort, jsonParser.in);
dag.addStream("toFilter", jsonParser.out, filterOp.input);
dag.addStream("toString", filterOp.truePort, jsonFormatter.in);
dag.addStream("toSlack", jsonFormatter.out, slackOp.input);
}
おおまかに言えば、 Operator のインスタンスをつくって登録し、あとはそれらをつなげる、ということをやっているだけですね。
これ以外に多少、設定ファイルに記述する必要はありますが(例えば接続する Kafka や Slack の情報など)、とはいえ、基本的には、上記の記述だけで、ストリーム処理を実現することができます。
これは十分に直感的でかんたんだと思います。
Apex アプリケーションを書く、ということ
DAG を書く、というところは、前セクションの例のとおり populateDAG メソッドの中身を書いているだけですが、これを呼び出す側である、 Apex アプリケーションという器の用意の仕方については、 Apache Apex Development Environment Setup を読むとわかりますが、 Maven を使ってつくることができます。
これによって、雛形というかサンプル的な Apex アプリケーションのコード群が生成されるので、あとは、これをベースに手を入れていけば OK 、ということになります。
Apex アプリケーションを実行する、ということ
Apex アプリケーションの実行には、 Apex CLI を使えばよいようですので、ドキュメントを読み使い方を覚えましょう!
といっても、とりあえず覚えるべきことはアプリケーションの起動に使う launch と終了させるのに使う shutdown-app と kill-app 、そして、実は覚えておいた方がよいのは、起動したアプリケーションの DAG の実行計画を見るための show-physical-plan ではないかと思います。
Apex アプリケーションというのは YARN の上で動くわけですが、デバッグやトラブルシューティングの際には、 YARN を使って具体的にどう動いているのか、をまず把握する必要があるはずで、そのために show-physical-plan を打つことも多いのではないかと思っています。
その他細かい話
以上で Apex アプリケーションをつくり、動かす上での大枠の話は書いたわけですが、実際に進めていくといろいろ細かい話もつきものなので、それらも合わせて書いておきます。
ConsoleOutputOperator
今回、最終的には上記のように Slack に流す、ということにしましたが、もちろん最初からそうしたわけではなく、開発初期は古き良き printf デバッグ的に、 ConsoleOutputOperator を使っていました。
ところで、そもそも YARN を使って分散処理する際の ConsoleOutput すなわち標準出力は、どこになるのでしょうか?
冒頭の方で「Operator が YARN の Container として動く」と書いたとおり、これは、「 ConsoleOutputOperator が動いているコンテナ」ということになるので、どのコンテナが ConsoleOutputOperator が動いているコンテナなのかを特定し、そのコンテナの標準出力を ResourceManager の WebUI から確認する、というようなことをやることになります。
Filter と Janino
Filter での絞り込み条件の記述は、ほぼ Java のコードで書くことができますが、これは、コード中では、 Java のコードではなくあくまで String として保持し、実行時にそれを解釈し、実行しているようです。
Filter ではこのために Janino を使うことになっているようで、これがアプリケーションに含まれていないと、
Caused by: java.lang.ClassNotFoundException: No implementation of org.codehaus.commons.compiler is on the class path. Typically, you'd have 'janino.jar', or 'commons-compiler-jdk.jar', or both on the classpath.
と怒られてしまいます。
Janino は Maven の Central Repository にも入っているので、ふつうに pom.xml の dependencies に含めれば OKです。
Json Parser を使うには
Json Parser を使うには json-schema-validator も pom.xml で dependencies に入れる必要がありましたが、 Json Parser が書かれたときのバージョンと最新のバージョンとで、一部のクラスのパッケージが変更されているようで、動かすとエラーになりました。
ということで、今回、は使用例のコードに倣い、バージョン 2.0.1 を dependencies に入れる、という方法でとりあえずの解決をはかりました。
まとめ
ということで、 dstat → Fluentd → Kafka → Apex → Slack という構成で、 Apex の中で流れてきた dstat の結果を絞り込んで Slack に書き込む、ということが実現できました。
「その他細かい話」のセクションで書いたような細かいところでつっかかるところは多少ありましたが、概ねかんたんにストリーム処理を書くことができました。
DAG の記述もシンプルで直感的でしたね。
YARN の上で動く、ということで、既に YARN を動かしていてリソースに余裕があるならば、ストリーム処理をやる方法として便利なのではないか、と思います。
また、実際に使っていく中では、やりたいことを実現するために Operator を実装していくことが重要となりそうですが、その Operator もよく使いそうなものは Apex Malhar に含まれており、もしそこになかったとしても、とてもかんたんに実装できるので、この点も便利です。
また、今回試した中ではあまり気にしていませんでしたが、 Exactly Once ができたり、耐障害性も高い、という点は、実運用では大きなアドバンテージになっていくだろうと思います。
最後に
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。
インフラ設計・構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、
ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD