2021.04.08
ConoHaでHadoop(+Delta Lake)クラスタ再構築 ~Erasure Coding機能を使ってみた
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
ここのところずっとHadoopに関する検証を行ってきたのですが、今度検証の環境を自社のVPSサービスのConoHaを使うことになり、新たに作り直すことになりました。
どうせなら新機能も試したかったので、ずっと気になっていたHadoopのErasure Coding機能を使ってみようと思います。
1.HDFSのErasure Codingについて
Hadoopは知っていても、Erasure Codingは聞いたことがない、という人も多いのではないでしょうか。Erasure CodingはHadoop3系から導入された機能で、従来のHDFSのReplicationの冗長化に比べてより効率的にデータを保存し使用量を減らすことができる冗長化の仕組みです。
LINEさんのトラブルシューティングの記事やYahoo!さんの紹介の記事にとてもよくまとめられていますので、ぜひご一読ください。
Erasure Codingは簡単に言うと、ハードディスクでいうRAID5のような仕組みです。元のデータファイルから複数のデータブロックとパリティブロックを作成して格納します。
データブロックとパリティブロックをどの構成で作るかのポリシーがあり、以下の5つのポリシーが最初から用意されています。
- RS-3-2-1024k
- RS-6-3-1024k
- RS-10-4-1024k
- RS-LEGACY-6-3-1024k
- XOR-2-1-1024k
HDFSでErasure Codingを有効化した場合、デフォルトではRS-6-3-1024kが選択されるようです。もちろん自分で選択して有効化もできます。
ものすごく大事なこととして、各ポリシーの二つ目(データブロック数)と三つ目の数字(パリティブロック数)の合計の数だけデータノードが必要になります。足りないとデータを書き込もうとしたときにエラーで怒られます。
実は最初あまり考えずにHadoopクラスタ構築してからErasure Codingを有効化しようとして、データノードが足りずに怒られました・・。有効化は成功するのに書き込んで初めてエラーというのがちょっと嫌らしいところ・・。
2.ConoHaでHadoopクラスタ
Hadoopクラスタはそれなりのスペックとある程度の台数は必要になっちゃいますが、ConoHaでいい感じに作れました。
VPSを使っていて最新のビッグデータ技術(HadoopやSpark)を自分でも試してみたいという方は、時間課金プランで稼働時間を限定して試してみるのも良いですね。
2-1.サーバースペック
今回のHadoopクラスタでは、ConoHaの以下のスペックで8台VPSサーバーを立てました。検証なのであえてCentOS Streamを使っています。
| CPU: | 6Core |
| メモリ: | 8GB |
| SSD: | 100GB |
| OS: | CentOS Stream8(64bit) |
2-2.ネットワーク設定
ConoHaでHadoopクラスタを立てるときにもっとも大事なのがネットワーク設定です。ConoHaはVPS1台ごとにグローバルIPが割り当たっていますが、クラスタ構成を組む時は色んなポートを利用することもあり、プライベートネットワークで閉じる形にするのが望ましいです。
まずセキュリティのメニューからSSH Keyを追加します。次にコンパネからサーバー追加メニューで、不要なポートを閉じ追加したSSH Keyを選択してからVPSサーバーを立てます。
- 接続許可ポート IPv4 →SSH(22)のみにする
- 接続許可ポート IPv6 →今回使わないので全て拒否にする
- SSH Key →追加したキーを選択
プライベートネットワークの追加・割り当て
VPSサーバーを立てたら、ネットワークのメニューからプライベートネットワークを作成して、立てたVPSサーバーに割り当てておきます。このあたりのやり方はConoHaのご利用ガイドなども参考にしてみてください。
そしてIPアドレスを認識させるには実はもう一つ作業が必要になります。
CentOS Stream8では以下のようなコマンドで1台ずつIPアドレスを認識させました。192.168.XXX.XXXの箇所には1台ずつ割り当てたIPアドレスが入ります。
nmcli device status nmcli connection add con-name eth1 ifname eth1 type ethernet nmcli connection modify eth1 ipv4.address 192.168.XXX.XXX/24 nmcli connection modify eth1 ipv4.method manual nmcli connection modify eth1 connection.autoconnect yes nmcli connection up eth1
ConoHaのセキュリティグループの設定
プライベートネットワークの設定が済んだら、今度はConoHaのAPIを使ってConoHaのセキュリティグループを設定します。ConoHaのネットワーク設定はVPSサーバーの中に入ってfirewalldで設定することもできますが、OSより手前でセキュリティグループの設定でできるのが良いところです。
ConoHaのAPIを毎回叩くのは結構大変なんですが、ありがたいことに簡単に設定できるツールが公開されていたりします。詳細はこちらの記事も見てもらえればと思いますが、今回こちらのツールを使わせていただきました。
自分はWindowsのPCを使って作業しているので、Windows(amd64)用の実行ファイルを落として、Git Bashを使って以下のように実行しました。192.168.XXX.0/24の箇所がある行は、192.168.XXXのプライベートネットワークからの接続を許可するコマンドになります。
export OS_USERNAME=[APIユーザー名] export OS_PASSWORD=[APIパスワード] export OS_TENANT_ID=[テナントID] export OS_AUTH_URL=[Identity ServiceのエンドポイントURL] ./conoha-net create-group k-group ./conoha-net create-rule -d ingress -e IPv4 -P tcp -i 192.168.XXX.0/24 k-group ./conoha-net attach -n VPS名1 k-group ./conoha-net attach -n VPS名2 k-group ./conoha-net attach -n VPS名3 k-group ./conoha-net attach -n VPS名4 k-group ./conoha-net attach -n VPS名5 k-group ./conoha-net attach -n VPS名6 k-group ./conoha-net attach -n VPS名7 k-group ./conoha-net attach -n VPS名8 k-group
ConoHaのセキュリティグループの設定がしっかりできたら、各ノードでfirewalldを無効化します。セキュリティグループで設定していない通信は拒否されるので、firewalldを無効化しても問題ありません。
ConoHaではデフォルトのセキュリティグループが最初から用意されていて、コンパネの許可ポートの指定で割り当てが変わるようになっています。今回はIPv4のsshポート(22)だけ許可して構築しているのでそのためのセキュリティグループは自動で設定されます。
firewalldで設定する場合
とはいっても、セキュリティグループの設定がしっかりできていなかったときの怖さもあるのでfirewalldも設定しておきたい、という人は以下のようにfirewalldを設定すればプライベートネットワークからの通信のみ全ポート開放でそれ以外は拒否の設定になります。
firewall-cmd --permanent --add-rich-rule="rule family=ipv4 source address=192.168.XXX.0/24 accept" firewall-cmd --reload firewall-cmd --list-all
2-3.OS設定(CentOS Stream8)
Hadoopクラスタのために必要なOS設定を行います。CentOS Stream8はCentOS8系ですが、当然CentOS7系のときと違う点もあるので要注意です。DNSは使わずhostsファイルを使いました。全ノードで設定しておきます。
- /etc/hostsファイルの準備(FQDN形式で記述)
- Hadoop用OSユーザー:グループを作成
- hdfs:hadoop,hdfs / zookeeper:hadoop / yarn:hadoop / spark:hadoop
- chronyによるサーバー時刻同期
- 環境構築で使うOSパッケージ(curl、wget、rsyncなど)のdnf install
- transparent_hugepagesの無効化
- /etc/security/limits.confのリソース制限の変更
- (必要に応じて)systemdのログの永続化
Hadoopクラスタを構築したときのブログでも触れていますので良かったらお読みください。CentOS8系からntpがchronyに変わったので、chronyの設定だけ書こうと思います。chronyサーバーをHadoopクラスタのマスタノードの1台に構築し、他のノードはそこを見に行く構成としました。
chronyの設定
IPアドレスのxxxやホスト名は置き換えてください。
# マスターノード1で作業:chronyのサーバー構築 sed -e '/^pool /s/.*/pool ntp.nict.jp iburst/' /etc/chrony.conf > /etc/chrony.conf2 sed -i -e '/^#allow /s/.*/allow 192.168.XXX.0\/24/' /etc/chrony.conf2 sed -i -e '/^#local stratum /s/^#//' /etc/chrony.conf2 mv /etc/chrony.conf /etc/chrony.conf.org mv /etc/chrony.conf2 /etc/chrony.conf systemctl enable chronyd systemctl restart chronyd
# 他の全ノード:chronyのクライアント sed -e '/^pool /s/.*/server マスタノード1のホスト名 iburst/' /etc/chrony.conf > /etc/chrony.conf2 mv /etc/chrony.conf /etc/chrony.conf.org mv /etc/chrony.conf2 /etc/chrony.conf systemctl enable chronyd systemctl restart chronyd
chronyが構築できたら、ちゃんと時刻同期が起きているか以下のコマンドなどで確認して、問題なければ完了です。
chronyc sources chronyc tracking
3.Hadoopクラスタを作る
3-1.各種ソフトウェアのバージョンとJava&Pythonのセットアップ
今回のHadoopクラスタはそれぞれ以下のバージョンで構築しました。
| Python: | 3.6.8 |
| Java: | 1.8.0 (openjdk-1.8.0.282) |
| ZooKeeper: | 3.4.14 |
| Hadoop(HDFS/YARN): | 3.2.2 |
| Spark: | 3.1.1 (spark-3.1.1-bin-hadoop3.2) |
| Delta Lake: | 0.8.0 (delta-core_2.12:0.8.0) |
| Patroni: | 2.0.2 |
| PostgreSQL: | 13.2 |
JavaとPythonは全ノードで以下のようにセットアップしておきます。
## Javaの環境を整備 # 全ノードで作業 dnf -y install java-1.8.0-openjdk dnf -y install java-1.8.0-openjdk-devel
## pythonの環境を整備 # 全ノードで作業 alternatives --config python #→python3を選択してEnter update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 1
3-2.今まで試した構成の全部盛り(Hadoop+Delta Lake+Spark+Patroni)
ConoHaでHadoopクラスタを作り直すにあたって、Erasure Coding機能を使うだけでなく、今まで色々試した構成を全部盛り込んでみました。
今まで試した構成というのは、PatroniとPostgreSQL、HadoopとSparkおよびDelta Lakeなどです。
- DBクラスタをCentOS8にPostgreSQL12+Patroniで構築してみた
- ビッグデータの新しい基盤としてHadoop上でSpark+Delta Lakeを検証してみた
- Hadoop上でSpark+Delta Lakeを検証してみた~続き
図にすると以下のような構成のHadoopクラスタですね。
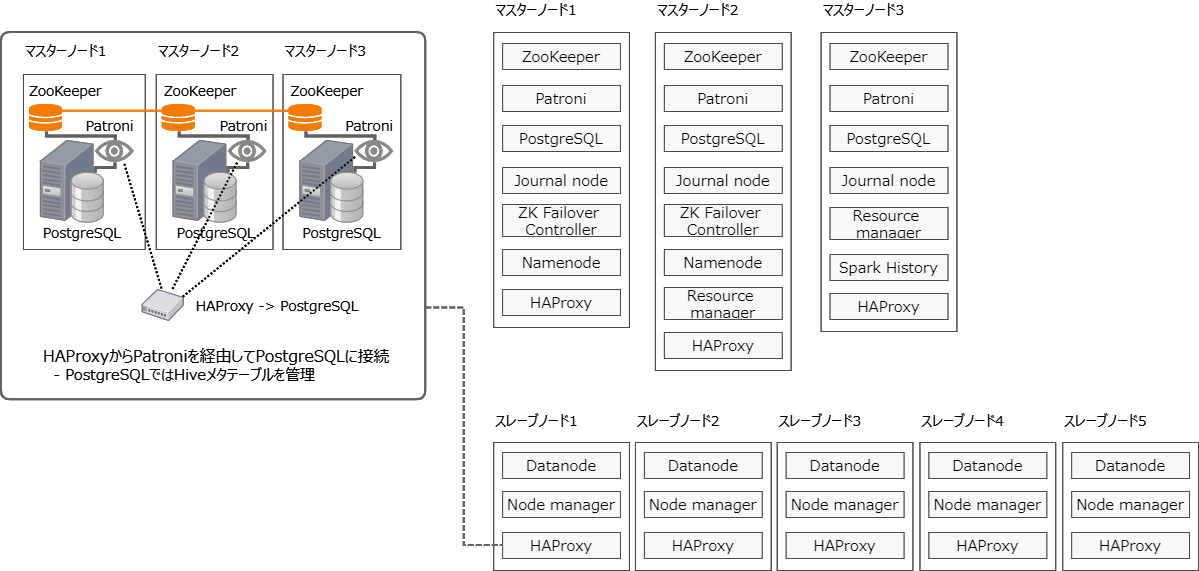
Delta LakeはDatabricksが開発したSpark用のストレージレイヤーの技術で、以前の検証のようにSparkで扱うときにHiveメタ情報テーブルと連携させて使います。今回はそのHiveメタ情報テーブルの格納先をPatroniでクラスタを組んだPostgreSQLにしました。
HAProxyからPatroniを経由してリーダーとなっているPostgreSQL1台に繋いでHiveメタ情報を取得します。Patroniは3台あるPostgreSQLのうち、リーダーとなっている1台がどれかわかるような情報を返すので、HAProxyがその1台に振り分けて接続するという仕組みです。
上記図では代表してスレーブノード1のHAProxyからPostgreSQLに接続する様子を切り出しました。Sparkは分散処理なのでどのノードからでもHiveメタ情報を取得できるようにしておかないといけないので、全ノードにHAProxyを構築します。
前の検証では、Patroniが使う分散データストアにetcdを使いましたが、今回はHadoopクラスタで必ず使うZooKeeperを使いました。
3-3.ZooKeeperとPatroni&PostgreSQLを構築
ZooKeeper構築
今回の構成では先ずZooKeeperを構築します。前に書いたZookeeperのインストール&構築と同じように構築しました。
Patroni&PostgreSQL構築
ZooKeeperを構築したら、PatroniによるPostgreSQLクラスタを構築します。先ずPostgreSQL13をdnfでインストールします。このやり方ではpostgresユーザーが自動で作成されます。
# マスターノード1~3で作業 dnf -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm # レポジトリ確認 rpm -qi pgdg-redhat-repo dnf -qy module disable postgresql dnf -y install postgresql13 postgresql13-server
次にPatroniを構築します。
# マスターノード1~3で作業 dnf -y install gcc dnf -y install python36-devel pip install --upgrade setuptools pip install kazoo dnf -y install python3-psycopg2 # 今回はZooKeeperを使うので[]でzookeeperを指定してインストール pip install patroni[zookeeper]
etcdではなくZooKeeperを使う場合は、pip install kazooとpip install patroni[zookeeper]の箇所が変わります。後の作業は以前に書いたPatroni設定のように行います。Patroniの設定ファイル(patroni.yml)はホスト/IPアドレスやディレクトリ、parametersセクションのメモリ設定などは今回の環境に合わせて変えましたが他は同じような内容にしました。
HAProxy構築
Patroniを経由してPostgreSQLに接続するためのHAProxyを全ノードで構築します。ホスト/IPアドレスのところ以外は以前書いたHAproxyインストール&設定と全く同じようにしました。
3-4.HDFSとYARNを構築
HDFS構築
HDFSについても以前に書いたHDFSの構築&HAの手順のように行いました。各種設定においてホスト/IPアドレスはもちろん今回用に直しています。
最初にhdfsユーザーとyarnユーザーがノーパスワードでsshできるようにしておきます。
- マスタノード1と2のhdfsユーザーがそれぞれ自ノードを含む全ノードにノーパスワードでssh
- マスタノード2と3のyarnユーザーがそれぞれ自ノードを含む全ノードにノーパスワードでssh
以前とは違う設定にしたのは主に以下のところです。
hadoop-env.sh
###
# NameNode specific parameters
###
export HDFS_AUDIT_LOGGER=INFO,RFAAUDIT
###
# DataNode specific parameters
###
export HDFS_DATANODE_OPTS="-server -XX:ParallelGCThreads=4 -XX:+UseConcMarkSweepGC -XX:ErrorFile=/var/log/hadoop/$USER/dn_err_pid%p.log -XX:NewSize=200m -XX:MaxNewSize=200m -Xloggc:/var/log/hadoop/$USER/gc.log-`date +'%Y%m%d%H%M'` -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xms1024m -Xmx1024m ${HDFS_DATANODE_OPTS} -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly"
###
# ZKFailoverController specific parameters
###
export HDFS_ZKFC_OPTS="-server -Xmx1024m ${HDFS_ZKFC_OPTS}"
###
# QuorumJournalNode specific parameters
###
export HDFS_JOURNALNODE_OPTS="-server -Xmx1024m ${HDFS_JOURNALNODE_OPTS}"
###
# HDFS Balancer specific parameters
###
export HADOOP_BALANCER_OPTS="-server -Xmx1024m ${HADOOP_BALANCER_OPTS}"
topology.sh
#!/bin/bash
echo $@ | xargs -n 1 | awk -F '.' '{print "/rack-"$NF}'
YARN構築
YARNも同じくYARNの構築&HAの手順のように行いました。
各種設定のホスト/IPアドレスを今回用に直した以外で以前と違う設定にしたのは主に以下のところです。
yarn-env.sh
### # Node Manager specific parameters ### export YARN_NODEMANAGER_HEAPSIZE=1024 # export YARN_TIMELINE_HEAPSIZE=4096 →コメントアウトor削除
yarn-site.xml
最初からyarn.nodemanager.aux-servicesの項目をSpark用に設定したのと、ConoHaのVPS環境にあわせてメモリ設定などを変えました。
<property>
<name>hadoop.registry.dns.enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.classpath</name>
<value>/usr/spark/current/yarn/*</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>5</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>7168</value>
</property>
3-5.Sparkの構築とHive連携
Spark構築
HDFSとYARNが構築できたら今度はSparkを構築します。今回はspark-3.1.1-bin-hadoop3.2.tgzのバイナリをダウンロードして構築しました。それ以外はSparkのインストール&構築の手順のように行います。
Hive連携
最後にHive連携してSparkSQLからテーブルを簡単に扱えるようにします。Hive連携といってもHive MetastoreやHive Server2などのHiveサービスを立ち上げるわけではなく、準備したRDBにHiveメタ情報テーブルを作成してSparkから接続できるようにすればOKです。
今回初めてPostgreSQLにHiveメタ情報テーブルを作成しました。
spark-3.1.1-bin-hadoop3.2を展開してみると、jarsディレクトリにhive-metastore-2.3.7.jarが入っていて、Hive2.3.7用のメタ情報テーブルを作成すればよいことがわかります。
PostgreSQLにHive連携用ユーザーとデータベースを作成し、Hiveメタ情報テーブルを作成するSQLを投入します。
# PatroniによってリーダーになっているPosgreSQLがあるサーバーで作業 wget https://github.com/apache/hive/archive/rel/release-2.3.7.tar.gz mv release-2.3.7.tar.gz hive-rel-release-2.3.7.tar.gz tar zxvf hive-rel-release-2.3.7.tar.gz cd hive-rel-release-2.3.7/metastore/scripts/upgrade/postgres
-- PatroniによってリーダーになっているPosgreSQLに接続して実行 postgres=# CREATE ROLE hive WITH LOGIN PASSWORD 'XXXXX'; postgres=# CREATE DATABASE hivedb OWNER hive; postgres=# \c hivedb hive hivedb=> \i hive-schema-2.3.0.postgres.sql;
このSQLを実行したところ、以下のワーニングが発生したんですがテーブル作成と初期データの挿入はできていたので問題はなさそうです。
psql:hive-schema-2.3.0.postgres.sql:1463: WARNING: no privileges could be revoked for "public" REVOKE psql:hive-schema-2.3.0.postgres.sql:1464: WARNING: no privileges were granted for "public" GRANT
Hiveメタ情報テーブルの作成まで終わったので、あとはSparkがHAProxy経由でPostgreSQLに接続できるように設定したhive-site.xmlを用意して、全サーバーの$SPARK_HOME/conf配下に配布したら準備完了です。
hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://localhost:5000/hivedb</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>XXXXX</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/apps/spark/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
</configuration>
HDFSディレクトリ準備
今まで試してきたHadoop+DeltaLake+Spark+Patroniの全部盛りクラスタが構築できたら、ちゃんとSparkの分散処理が動くかサンプルジョブを動かして確認します。
HDFSを構築したばかりだと、HDFSのルートディレクトリのパーミッションがなかったり他に何もディレクトリがなかったりしてジョブが失敗するので準備します。
# hdfsユーザー hdfs dfs -chown -R hdfs:hadoop / hdfs dfs -chmod 775 / hdfs dfs -mkdir /tmp hdfs dfs -chmod 777 /tmp hdfs dfs -mkdir /app-logs hdfs dfs -chown yarn:hadoop /app-logs hdfs dfs -chmod 775 /app-logs hdfs dfs -chown hdfs:hadoop /user hdfs dfs -chmod 775 /user hdfs dfs -mkdir /spark-logs hdfs dfs -chown spark:hadoop /spark-logs
以下のようにサンプルジョブをspark-submitして成功したら、これでHadoopクラスタの構築完了です!
spark-submit --class org.apache.spark.examples.SparkPi \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 1 \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.1.1.jar \
10
4.Erasure Codingを試す
Hadoopクラスタを構築したらいよいよErasure Codingを試します。最初調べる前はErasure CodingはHadoopクラスタ全体で有効か無効かしかないと勝手に思っていたんですが、実はHDFSのディレクトリ単位で有効にしたり無効にしたりできます。データが入った後でもErasure Codingに切り替えられます。ただその場合はデータ移行が必要になります。
あまり参照しない大量のデータを、ストレージ効率が良いErasure Codingを有効化したディレクトリに格納していくといった使い方ができそうです。
4-1.データベース作成とErasure Codingの有効化
今回はSparkSQLで全部扱えるようにしたいので、SparkSQLからHive連携でErasure Coding用のデータベースを作成し、そのHDFSのディレクトリに対してErasure Codingを有効化させます。
まず、PySparkシェルにDelta Lakeのパッケージを読み込んで接続します。
# sparkユーザー pyspark \ --packages io.delta:delta-core_2.12:0.8.0 \ --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" \ --conf "spark.delta.logStore.class=org.apache.spark.sql.delta.storage.HDFSLogStore" \ --conf "spark.sql.catalogImplementation=hive"で
データベース作成
以下のようにモジュールをimportしてHive連携を有効にしたsparkセッションを作成したら、SparkSQLでデータベース作成文を実行します。
>>>
from pyspark import SparkContext
from pyspark.sql import Column, DataFrame, SparkSession, SQLContext, functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from py4j.java_collections import MapConverter
from delta.tables import *
import timeit
import sys
spark = SparkSession \
.builder \
.appName("test-deltalake") \
.enableHiveSupport() \
.getOrCreate()
# データベース作成
ddl = """
CREATE DATABASE deltalake_db
"""
spark.sql(ddl)
# Erasure Coding用データベース作成
ddl = """
CREATE DATABASE deltalake_db_ec
"""
spark.sql(ddl)
これでHiveメタ情報テーブルにdeltalake_dbというデータベースの情報が書き込まれます。ここでいうデータベースはPostgreSQLのではなくHive(メタ情報)のデータベースになります。実体としてはHDFSのディレクトリです。
Erasure Codingの有効化
HDFS上にできたdeltalake_db_ecデータベースのディレクトリに対して、Erasure Codingを有効化します。Erasure CodingのポリシーはRS-3-2-1024Kにしました。冒頭で書きましたが、ポリシーの二つ目(データブロック数)と三つ目の数字(パリティブロック数)の合計の数だけデータノードが必要になるので、5台のデータノードの今回のHadoopクラスタ構成では、RS-6-3-1024kなどのポリシーは適用できません。
Erasure Codingの有効化はとても簡単で以下のようにhdfs ec -setPolicyコマンドを実行するだけだったりします。
# hdfsユーザー hdfs ec -setPolicy -policy RS-3-2-1024k -path /apps/spark/warehouse/deltalake_db_ec.db
どのポリシーでErasure Codingを有効化したかは、hdfs ec -getPolicyコマンドを実行します。deltalake_db、deltalake_db_ecの両方のデータベースのディレクトリに対して実行した結果は以下のようになりました。無事に有効化できました。
[hdfs@vps-m01 ~]$ hdfs ec -getPolicy -path /apps/spark/warehouse/deltalake_db_ec.db RS-3-2-1024k [hdfs@vps-m01 ~]$ hdfs ec -getPolicy -path /apps/spark/warehouse/deltalake_db.db The erasure coding policy of /apps/spark/warehouse/deltalake_db.db is unspecified
4-2.Erasure Codingを適用したテーブルのサイズ
HDFSの通常のディレクトリと、Erasure Codingを有効化したディレクトリでデータサイズがどれくらい変わるか自分でも試してみました。
まずそのためのデータを準備します。以前のブログでも使ったアイオワ州のお酒販売のデータを使って、データロードの手順に書いたようにCSVを少し加工して、SparkのStructured Streamingでテーブルに格納しました。
CSVの日付フォーマットを予め加工しなくても、Dateフォーマットを指定すればいいことに気が付いたので、今回は以下のようにストリーミングRead/Writeを行ってテーブルにロードしています。
>>>
csv_path = "/tmp/load_data/iowa_liquor_sales"
tab_location = "/apps/spark/warehouse/deltalake_db.db/iowa_liquor_sales"
checkpoint_location = tab_location + "/_checkpoints/streaming_ckp"
>>>
spark \
.readStream \
.format('csv') \
.options(header='true', inferSchema='false', quote='"', dateFormat='MM/dd/YYYY') \
.schema(tab_schema) \
.load(csv_path) \
.writeStream \
.format('delta') \
.partitionBy('sale_date') \
.outputMode('append') \
.option('checkpointLocation', checkpoint_location) \
.start(tab_location)
iowa_liquor_salesテーブルにCSVデータをロードし終わったら、より大きなサイズのテーブルを作ります。
同じテーブル定義のiowa_liquor_sales_largeというテーブルをdelatalke_dbとdelatalke_db_ecそれぞれのデータベースに作成し、10倍の125,904,290件になるようにデータを増やしてそれぞれに格納しました。
難しいことはしていなくてINSERT INTO文をspark-submitで並列で走らせた感じです。
結果、hdfs dfs -du -s -hコマンドで見ると以下のようになりました。
[hdfs@vps-m01 ~]$ hdfs dfs -du -s -h /apps/spark/warehouse/deltalake_db_ec.db/iowa_liquor_sales_large 3.6 G 10.8 G /apps/spark/warehouse/deltalake_db_ec.db/iowa_liquor_sales_large [hdfs@vps-m01 ~]$ hdfs dfs -du -s -h /apps/spark/warehouse/deltalake_db.db/iowa_liquor_sales_large 6.8 G 20.3 G /apps/spark/warehouse/deltalake_db.db/iowa_liquor_sales_large
HDFSの通常のReplicationではReplica数が3なので、一つ目と二つ目の数字が3倍の差になっているのですが、どちらもErasure Codingを有効化したディレクトリと比べて2倍くらいのディスク使用量の差があることがわかります(Erasure Codingの方の一つ目と二つ目の数値も3倍差になっているのはちょっと謎)。
今回試したErasure CodingのRS-3-2-1024kというポリシーはReplica数3のReplicationに比べて期待どおり半分のストレージ効率となりました。Erasure Codingのポリシーごとのストレージ率についてはClouderaのドキュメントによくまとめられています。
5.まとめ
今回ConoHaでHadoopクラスタを作り直してErasure Coding機能を使ってみましたが、Hive連携したSparkSQLからデータベースごとにErasure Codingを有効にして使い分けられることがわかったので、思ったより使い勝手がよさそうです。
たまにしか参照しないけど大量データを日々書き込むようなデータがあれば、Erasure Codingを有効にしたデータベースの方にテーブルを作って格納すれば、いつでもSparkSQLで操作できて便利そうです。
それと、今回の全部盛り構成(Hadoop+Delta Lake+Spark+Patroni)は最新のHadoopとSparkを自前で試すにはいい選択肢ではないでしょうか。特にHiveメタ情報テーブルの格納先をZooKeeperを使ったPatroni+PostgreSQLのクラスタにするのは、手軽にRDBも冗長化できるのでおすすめです。
今後の課題
今回試したHadoopクラスタ構成やErasure Coding機能を本番環境で利用するなら、どれくらい安定して稼働できるかはしっかり検証する必要があります。想定する利用にあわせたワークロードを検証したり、本番向けのHadoopの設定を深堀したり、というのがやっぱり今後の課題です。
6.最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




