2020.04.08
DBクラスタをCentOS8にPostgreSQL12+Patroniで構築してみた
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。 最近はずっとHadoopの検証を行っていましたが、今回はデータベースのテーマに戻ろうと思います。
前に書いた以下のブログ
- 「MySQLの冗長化を試す!~Percona XtraDB Cluster & ProxySQL & Replication~」
- 「Hadoop (Hive, Ambari など) が使う DB を Percona XtraDB Cluster & ProxySQL で冗長化してみた」
でも検証しましたが、システムのアーキテクチャーを考える上でデータベースの高可用性を求められることは多いです。
特に更新対象のデータベースを単一障害点にしないことが大事になりますが、ただ単に複数のデータベースを立てれば良いわけではなく、データベース間の同期や死活監視およびフェイルオーバーなどを何でも簡単に完璧に(しかも低コストで)満たすソリューションというのはありません。
それで前々から色々試していますが、以前の検証ではMySQL系を試したので、PostgreSQL系でも何かないものかと思って探したところ、Patroniというのを見つけました。
Patroniはロードバランサーの一つのHAproxyと組み合わせて比較的簡単に自動フェイルオーバーを実現でき、恐らく日本ではまだあまり使われてなさそうで面白そうだったので、今回はPostgreSQLとPatroniを使ったDBクラスタ構築を検証することにしました。
目次
1. システム構成
1. 概要と構成図
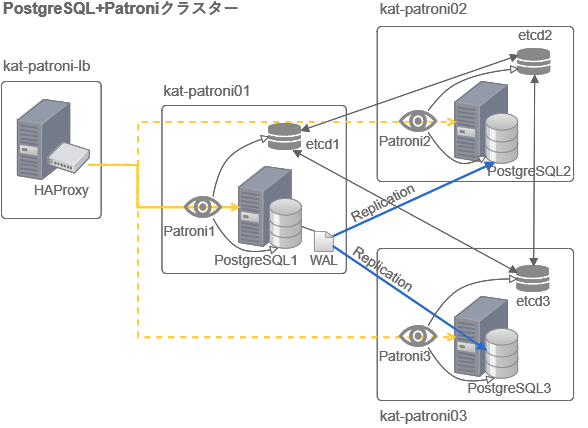
Patroniはetcdという信頼性の高い分散キーバリューストア(KVS)を使い、どのノードのPostgreSQLサーバーが利用可能なマスタかを状態監視して、マスタが故障した際に自動フェイルオーバーをしてくれるものです。Pythonで作られているのも良いですね。
PostgreSQLサーバーを複数台立てて、Patroniのサービスも1ノードに1つずつ起動します。各Patroniは同じノードにあるPostgreSQLを監視、etcdを介して状態を伝えます。マスタが故障するとそれがetcdを介して他のPatroniに伝わりマスタ昇格に適したスタンバイをマスタに昇格(フェイルオーバー)させます。
アプリケーション側はどのように切り替わったマスタに追随するか(どのノードのPostgreSQLがマスタかを知るか)というと、ロードバランサーのHAproxyを使います。HAproxyに接続して各ノードのPostgreSQLに振り分けてもらうのですが、その際Patroniをチェックして200のステータスを返したノードのみに接続します。Patroniは正常なマスタのノードのみ200を返します。
この仕組みでアプリケーション側は作り込むことなくマスタのみ接続することができるのでとても楽ちんですね。
それからPostgreSQL間はどのようにデータ同期するかと言うと、PostgreSQLが持っているストリーミングレプリケーションの機能を使います。昔使っていたPostgreSQL8系の頃は標準機能としてレプリケーションがなく、Slony-Iというトリガーベースのツールを使ってテーブルごとに同期を取っていたりしましたが、9系の頃からストリーミングレプリケーションが標準機能となりだいぶ進化してきました。今回PostgreSQLを使ってみようと思ったきっかけの一つでもあります。
システム構成図
2. 環境準備
1. 利用技術
今回利用するミドルウェアは、以下のものでCentOS8.1で試しました。
- PostgreSQL 12.2 ⇒現時点の最新の12系!
- Python 3.6.8
- python3-psycopg2 2.8.3
- Patroni 1.6.4 ⇒現時点の最新!
- etcd 2.3.8 ⇒実は最初はこの時点で最新の3.4.5で試しました。でも諸事情で結局etcd2系に
- HAProxy 1.8.15
2. サーバースペック
検証に当たりお馴染みの GMO アプリクラウドのサーバーを使いました。スペックは以下です。
- PostgreSQL+Patroni用のサーバー
- OS : CentOS 8.1
- 仮想 CPU : 2
- メモリ容量 : 8GB
- ディスク容量 : 160GB
- HAProxy用のサーバー
- OS : CentOS 8.1
- 仮想 CPU : 1
- メモリ容量 : 4GB
- ディスク容量 : 80GB
参考までに、GMOアプリクラウドの同じ技術を使ったより汎用的な Z.com クラウドもあるので興味のある方はぜひ。
3. インストール
1. 参考:CentOS7から8にアップデート
今回の検証の本筋からは外れますが、自分の勉強も兼ねてCentOS7から8にアップデートしてみたので、そのときの記録を参考までに書いてみました。
CentOS7から8もだいぶ変わっていて、大きな違いとしてはパッケージをインストールする仕組みがyumからdnfに替わります。
dnfをインストールしてCentOS7系の最新に
yum -y install epel-release /etc/yum.repos.d/epel.repoを編集 #-------------------- # baseurlのコメントを外し、 # metalinkをコメント # -------------------- yum -y install yum-utils rpmconf -a package-cleanup --leaves package-cleanup --orphans yum -y install dnf --enablerepo=epel yum -y update
dnfからCentOS8.1にアップデート
dnf -y remove yum yum-metadata-parser
rm -Rf /etc/yum
dnf upgrade
dnf makecache
dnf upgrade -y http://mirror.centos.org/centos/8/BaseOS/x86_64/os/Packages/{centos-release-8.1-1.1911.0.8.el8.x86_64.rpm,centos-gpg-keys-8.1-1.1911.0.8.el8.noarch.rpm,centos-repos-8.1-1.1911.0.8.el8.x86_64.rpm}
dnf upgrade -y epel-release
dnf makecache
rpm -e `rpm -q kernel`
rpm -e --nodeps sysvinit-tools
dnf -y --releasever=8 --allowerasing --setopt=deltarpm=false distro-sync
dnf -y install kernel-core
dnf -y groupupdate "Core" "Minimal Install"
systemctl reboot
Python3.6をインストールして、pythonコマンドとpipコマンドで呼び出すのを3系に切り替える
dnf -y install python36 alternatives --config python # python3を選択してEnter update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 1
2. 前準備
systemdに登録された各種サービスのログを永続化できるようにします。それと今回はDNSを使わずホストファイルの設定を行います。
# systemdのログはjournaldが管理しますがデフォルト状態だと再起動するとログが消えてしまうので、永続化するために/var/log/journalディレクトリを作成します。 mkdir /var/log/journal systemctl restart systemd-journald # IPアドレスはマスクしてますがもちろん実際は違います xx.xx.xx.97 kat-patroni-lb xx.xx.xx.99 kat-patroni01 xx.xx.xx.100 kat-patroni02 xx.xx.xx.101 kat-patroni03 ' >> /etc/hosts
3. PostgreSQL12をインストール
PostgreSQLの最新の12系を入れるため、そのためのレポジトリをダウンロードしてきてインストールします。
dnf -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm # レポジトリ確認 rpm -qi pgdg-redhat-repo dnf -qy module disable postgresql dnf -y install postgresql12 postgresql12-server # HAproxyを入れるサーバーは接続するだけなので、クライアントだけインストールでもOK dnf -y install postgresql12
4. etcdをインストール
最初dnfでインストールしようとしたものの、どうもレポジトリがないようで上手くいかず、結局etcdのバイナリーを落として展開しました。 バージョン2.3.8にしているのは2系の最新がこれだったためです。
mkdir /var/tmp/etcd
cd /var/tmp/etcd
ETCD_VER=v2.3.8
curl -L https://github.com/etcd-io/etcd/releases/download/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf etcd-${ETCD_VER}-linux-amd64.tar.gz --strip-components=1
rm -f etcd-${ETCD_VER}-linux-amd64.tar.gz
chown -R root:root /var/tmp/etcd
cd ..
# etcdを今回は/usr配下に以下の名前で配置
mv /var/tmp/etcd /usr/etcd-2.3.8
dnfでインストールしない場合、etcd用のユーザー作成や、サービス起動スクリプト作成とsystemdへの登録は自分で行わないといけなので、それを行います。
GitHubのドキュメントとこちらのサイトを参考にしました。
後述していますが、etcdのクラスタ構築のための設定は環境変数で行うので、[Service]のセクションにEnvironmentFile=/etc/sysconfig/etcdと指定し、サービス起動時にその環境変数を書いたファイルを読み込ませるようにしました。
# etcdユーザーとグループを作成 groupadd --system etcd useradd -s /sbin/nologin --system -g etcd etcd # etcd用のディレクトリ作成 mkdir -p /var/lib/etcd mkdir /etc/etcd chown -R etcd:etcd /var/lib/etcd # etcdのサービス起動スクリプトを作成 cat <<_EOF_ |tee /etc/systemd/system/etcd.service [Unit] Description=etcd service Documentation=https://github.com/etcd-io/etcd [Service] EnvironmentFile=/etc/sysconfig/etcd Type=notify User=etcd ExecStart=/usr/etcd-2.3.8/etcd [Install] WantedBy=multi-user.target _EOF_ chmod 644 /etc/systemd/system/etcd.service
5. Patroniをインストール
もっとも手こずったのがPatroniのインストールです。公式ドキュメントを参考にpipでインストールするやり方を選んだんですが、怒られ続けて一つずつ足りないものがわかって試行錯誤した結果、以下のようにインストールと積み重ねればできました。
dnf -y install gcc dnf -y install python36-devel pip install --upgrade setuptools pip install python-etcd dnf -y install python3-psycopg2 # etcdを使うので[]でetcdを指定してインストール pip install patroni[etcd]
4. DBクラスタ構築&設定
インストールが終わったらいよいよクラスタを構築するために各種設定を行います。
クラスタ構築&設定には、以下の記事を色々と参考にしました。
- Design A Highly Available PostgreSQL Cluster With Patroni In GCP — Part 2
- Create a Highly Available PostgreSQL Cluster Using Patroni and HAProxy
- GETTING STARTED WITH PATRONI
クラスタを組むサーバー同士は外部から直接見えないこともあり、今回の検証では先にSELinuxをFirawalldを無効化しておきます。また、今回は省いていますが、本番運用のときはクラスターを組む各ノード間で時刻がズレないように時刻同期の仕組みを入れておきます。CentOS8からはntpではなくchronyを使うようになりました。
1. etcdクラスタ設定
etcdの2系では各種設定を環境変数で行います。インストールのところで前述したように、サービス起動時に読み込ませる環境変数を書いたファイルを用意します。クラスタを組むノードごとに少し設定が違うのでそれぞれ設定を分けます。
1. etcdの設定とサービス起動
クラスタ1:kat-patroni01
cat <<_EOF_ |tee /etc/sysconfig/etcd ETCD_NAME='etcd01' ETCD_DATA_DIR='/var/lib/etcd' ETCD_INITIAL_ADVERTISE_PEER_URLS='http://xx.xx.xx.99:2380' ETCD_LISTEN_PEER_URLS='http://xx.xx.xx.99:2380' ETCD_LISTEN_CLIENT_URLS='http://xx.xx.xx.99:2379,http://127.0.0.1:2379' ETCD_ADVERTISE_CLIENT_URLS='http://xx.xx.xx.99:2379' ETCD_INITIAL_CLUSTER_TOKEN='etcd-cluster-01' ETCD_INITIAL_CLUSTER='etcd01=http://xx.xx.xx.99:2380,etcd02=http://xx.xx.xx.100:2380,etcd03=http://xx.xx.xx.101:2380' ETCD_INITIAL_CLUSTER_STATE='new' _EOF_
クラスタ2:kat-patroni02
cat <<_EOF_ |tee /etc/sysconfig/etcd ETCD_NAME='etcd02' ETCD_DATA_DIR='/var/lib/etcd' ETCD_INITIAL_ADVERTISE_PEER_URLS='http://xx.xx.xx.100:2380' ETCD_LISTEN_PEER_URLS='http://xx.xx.xx.100:2380' ETCD_LISTEN_CLIENT_URLS='http://xx.xx.xx.100:2379,http://127.0.0.1:2379' ETCD_ADVERTISE_CLIENT_URLS='http://xx.xx.xx.100:2379' ETCD_INITIAL_CLUSTER_TOKEN='etcd-cluster-01' ETCD_INITIAL_CLUSTER='etcd01=http://xx.xx.xx.99:2380,etcd02=http://xx.xx.xx.100:2380,etcd03=http://xx.xx.xx.101:2380' ETCD_INITIAL_CLUSTER_STATE='new' _EOF_
クラスタ3:kat-patroni03
cat <<_EOF_ |tee /etc/sysconfig/etcd ETCD_NAME='etcd03' ETCD_DATA_DIR='/var/lib/etcd' ETCD_INITIAL_ADVERTISE_PEER_URLS='http://xx.xx.xx.101:2380' ETCD_LISTEN_PEER_URLS='http://xx.xx.xx.101:2380' ETCD_LISTEN_CLIENT_URLS='http://xx.xx.xx.101:2379,http://127.0.0.1:2379' ETCD_ADVERTISE_CLIENT_URLS='http://xx.xx.xx.101:2379' ETCD_INITIAL_CLUSTER_TOKEN='etcd-cluster-01' ETCD_INITIAL_CLUSTER='etcd01=http://xx.xx.xx.99:2380,etcd02=http://xx.xx.xx.100:2380,etcd03=http://xx.xx.xx.101:2380' ETCD_INITIAL_CLUSTER_STATE='new' _EOF_
クラスタ1-3:kat-patroni01-03
設定準備が整ったら、etcdのサービスを有効化して起動します。クラスタ1のノードでetcdを起動したら他のクラスタのetcdが起動するまで待ち状態になるので、続けてクラスタ2と3でも起動します。
systemctl daemon-reload systemctl enable etcd systemctl start etcd
2. etcdのクラスタの挙動確認
クラスタが正しく組めているか確認します。クラスタ1のetcdに書き込んだ内容が他のクラスタのetcdで参照できるかをみてみます。
クラスタ1:kat-patroni01
# "Hellow World"という文字を/messageに書き込む /usr/etcd-2.3.8/etcdctl set /message "Hello World"
クラスタ2-3:kat-patroni02-03
/usr/etcd-2.3.8/etcdctl get /message
“Hello World”が返ってきたらクラスタがきちんと組めていることがわかるので、これでetcdクラスタ構築は完了です!
2. PostgreSQL設定
etcdの次にPostgreSQLを設定します。データベースはインストールしてまずやることは初期化ですね。しかし、一番ハマったところなんですが、結論から言うとPostgreSQLの初期化や設定はPatroniの設定でまとめて行う方が良いです。
参考までに、PostgreSQLのレポジトリからdnfでインストールすると、postgresユーザーとグループが自動で作成され、postgresユーザーのホームディレクトリが/var/lib/pgsqlになります。PostgreSQLのデータディレクトリ(PGDATA)も/var/lib/pgsql/12/dataに決められて、.bash_profileも作られます。PostgreSQL起動スクリプトも作られてsystemdにサービス登録もされます。
とても便利なんですが、色々決め打ちされるのでデータディレクトリを変更すると思わぬ影響を受けるところもありました。。それもあり今回はデータディレクトリはそのままにしています。
この時点ではPostgreSQLの更新ログであるWALをアーカイブする先のディレクトリだけ作っておきます。WALアーカイブは必須ではないですが、本番運用のときにポイントタイムリカバリをする際には必要なので今回の検証ではアーカイブモードを有効にしました。場所はどこでも良いですが、データディレクトリと同じところにarchiveというディレクトリを作りました。
mkdir /var/lib/pgsql/12/archive chown postgres:postgres /var/lib/pgsql/12/archive chmod 700 /var/lib/pgsql/12/archive
3. Patroni設定
いよいよPatroniの設定です。まずサービス起動スクリプトを作成します。
クラスタ1-3:kat-patroni01-03
cat <<_EOF_ |tee /etc/systemd/system/patroni.service [Unit] Description=Runners to orchestrate a high-availability PostgreSQL After=syslog.target network.target [Service] Type=simple User=postgres Group=postgres ExecStart=/usr/local/bin/patroni /etc/patroni.yml KillMode=process TimeoutSec=30 Restart=no [Install] WantedBy=multi-user.target _EOF_ chmod 644 /etc/systemd/system/patroni.service systemctl enable patroni
サービス起動スクリプトが準備できたら、その中にで指定されているPatroniの設定ファイル(yaml)を準備します。
クラスタ1:kat-patroni01
cat <<_EOF_ |tee /etc/patroni.yml
scope: postgres-cluster
namespace: /db/
name: postgresql-patroni01
restapi:
listen: 0.0.0.0:8008
connect_address: xx.xx.xx.99:8008
etcd:
hosts: 'xx.xx.xx.99:2379,xx.xx.xx.100:2379,xx.xx.xx.101:2379'
bootstrap: #Patroniが最初に行う諸々の設定
dcs: #クラスタ構築関連の設定
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
synchronous_mode: on #同期モードの設定
synchronous_mode_strict: true #同期モードの設定
postgresql:
use_pg_rewind: true #レプリケーションの設定
use_slots: true #レプリケーションの設定
parameters:
wal_level: replica #レプリケーションの設定
hot_standby: on #レプリケーションの設定
wal_keep_segments: 8 #レプリケーションの設定
max_wal_senders: 5 #レプリケーションの設定
max_replication_slots: 5 #レプリケーションの設定
checkpoint_timeout: 30 #レプリケーションの設定
synchronous_commit: on #同期モードの設定
synchronous_standby_names: '*' #同期モードの設定
archive_mode: on #アーカイブモードの設定
archive_command: 'test ! -f /var/lib/pgsql/12/archive/%f && cp %p /var/lib/pgsql/12/archive/%f' #アーカイブモードの設定
archive_timeout: 300 #アーカイブモードの設定
initdb: #PostgreSQLの初期化
- encoding: UTF8
- data-checksums
pg_hba: #PostgreSQLへのアクセス権限設定
- host replication replicator 127.0.0.1/32 md5
- host replication replicator xx.xx.xx.99/32 md5
- host replication replicator xx.xx.xx.100/32 md5
- host replication replicator xx.xx.xx.101/32 md5
- local all all md5
- host all all xx.xx.xx.0/24 md5
users: #PostgreSQLユーザーの作成
admin:
password: adm-xxxxx
options:
- createrole
- createdb
replicator:
password: rep-xxxxx
options:
- replication
postgresql: #PostgreSQlの追加設定(主に接続/動的パラメータ)
listen: xx.xx.xx.99:5432
connect_address: xx.xx.xx.99:5432
data_dir: /var/lib/pgsql/12/data
config_dir: /var/lib/pgsql/12/data
bin_dir: /usr/pgsql-12/bin
pgpass: /var/lib/pgsql/pgpass
authentication: #PostgreSQLユーザーへの接続情報
replication:
username: replicator
password: rep-xxxxx
superuser:
username: postgres
password: pos-xxxxx
parameters:
unix_socket_directories: /var/run/postgresql
shared_buffers: 2GB
work_mem: 8MB
effective_cache_size: 4GB
autovacuum: on
track_counts: on
tags: #Patroniのクラスタ操作の設定
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
log:
level: INFO
_EOF_
ポイント
Patroniの設定は項目が多くて全部をしっかり理解するのは簡単ではないですが、少なくともどのセクションが何のための設定かは理解しないとなかなかうまくいきませんでした。上記のサンプルにセクションごとに何のための設定か簡単にコメントを付けましたが、少しずつ理解しながら設定した感じです。まだ全部の項目を理解できているわけでないのと、恐らく不要な記述もありそうなので、実際使うことになったらもっと深く見てみようと思います。
今回はPostgreSQLのレプリケーションを同期モードにする設定にしました。これは、PostgreSQL+Patroniのクラスタを利用したいケースが、大量トランザクションを捌くような性能を求めているのではなく、更新先データベースの高可用性を比較的容易に担保できるケースを想定しているためです。例えば、Hadoopクラスタを組むとき幾つかのサービスは実はデータベースを利用するのですが、そのデータベースを単一障害点(スタンドアロン構成)にしないようなケースです。
クラスタ2:kat-patroni02
クラスタ2の/etc/patroni.ymlの内容はクラスタ1の設定ファイルから以下の項目だけを変更して他は同じにしたまま準備します。
name: postgresql-patroni02
restapi:
connect_address: xx.xx.xx.100:8008
etcd:
hosts: xx.xx.xx.100:2379,xx.xx.xx.101:2379,xx.xx.xx.99:2379
postgresql:
listen: xx.xx.xx.100:5432
connect_address: xx.xx.xx.100:5432
クラスタ3:kat-patroni03
クラスタ3の/etc/patroni.ymlの内容もクラスタ2と同様に以下の項目だけを変更します。
name: postgresql-patroni03
restapi:
connect_address: xx.xx.xx.101:8008
etcd:
hosts: xx.xx.xx.101:2379,xx.xx.xx.99:2379,xx.xx.xx.100:2379
postgresql:
listen: xx.xx.xx.101:5432
connect_address: xx.xx.xx.101:5432
クラスタ1-3:kat-patroni01-03
Patroniの設定ファイルまで準備できたら、クラスタ1から順にPatroniを起動します。
# Patroni&PostgreSQL起動 systemctl start patroni # Patroniの状況確認 systemctl status --no-pager patroni # Patroniのクラスタ状況確認 patronictl -c /etc/patroni.yml list
状況確認して問題なければ、これでようやくPatroniを使ったPostgreSQLクラスタの構築が完了です!
4. おまけ:設定でハマったところ
etcd、Patroni、PostgreSQLとそれぞれ設定項目が多く、理解して上手くいくまで手こずりました・・。それでも特にハマったことは、etcdのバージョン問題とPostgreSQLの初期化&ユーザー作成のところです。
今回はなるべく最新のものを組み合わせることを念頭に置いていたので、当初はetcdの最新版の3.4.5をインストールしていました。順調に構築を進めて最後にPatroniの設定をしてさあ起動というときにエラーで怒られてしまい、原因を詳しく調査したらPatroniの最新版の1.6.4は実はetcdの2系のAPIまでしか対応していなかったことがわかりました。2系のAPIが使えるようなオプションを探して試してみましたが上手くいかず、結局etcdを2系の最新の2.3.8に入れ替えることで解決しました。
もう一つ、PostgreSQLの初期化&ユーザー作成については、初めはPostgreSQLの初期化コマンド(/usr/pgsql-12/bin/postgresql-12-setup initdb)を使って初期化してからPatroniの設定をしていたんですが、どうしてもPatroniが上手く起動しませんでした。詳しく原因を調査すると、PostgreSQLのデータディレクトリがあるとどうやら、Patroniのbootstrapで行うPostgreSQLの処理がこちらの想定通りには行われないようでそれで上手くいっていませんでした。そこで一度PostgreSQLのデータディレクトリを削除し、今度はPostgreSQLの初期化をPatroniで行うようにしました。
これはこれで上手くいったんですがまた別のエラーが出てしまい、これも原因を調査していくと、Patroniの設定ファイルに、PostgreSQLのレプリケーション用のユーザーを作成する設定がなかったことに気が付いて、この設定を追記することで上手く行きました!
bootstrapセクションにあるusersの次の項目ですね。postgresqlセクションにあるauthenticationの項目と紛らわしいので要注意です。
users: #PostgreSQLユーザーの作成
replicator:
password: rep-xxxxx
options:
- replication
上手く行くと、Patroniのサービスを起動したときに同時にPostgreSQLのデータベースも起動します。Patroniを使うときは、PostgreSQLの制御は全てPatroniに行わせた方が良さそうです。
5. データ同期および自動フェイルオーバー検証
クラスタ構築が終わったら、そのクラスタへの接続を制御できるようにHAProxyのインストールと設定を行って、一番の目的である自動フェイルオーバーを検証してみます。
1. HAproxyインストール&設定
クライアント:kat-patroni-lb
クラスタに接続するため用意したサーバーにHAProxyをインストールして、設定ファイルを作成します。
# HAProxyのインストール
dnf -y install haproxy
# HAProxyの設定
cat <<_EOF_ |tee /etc/haproxy/haproxy.cfg
global
maxconn 100
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen postgres
bind *:5000
option httpchk
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server patroni01_5432 xx.xx.xx.99:5432 maxconn 100 check port 8008
server patroni02_5432 xx.xx.xx.100:5432 maxconn 100 check port 8008
server patroni03_5432 xx.xx.xx.101:5432 maxconn 100 check port 8008
_EOF_
上記設定の意味は、ローカルホストの5000番ポートに接続すると、クラスタの中で利用可能なPostgreSQL1台(マスタ)にだけ繋いでくれるというものです。check port 8008と書かれている箇所がありますが、これはPatroniのAPIのポートにステータスをチェックしている箇所です。マスタになっているPostgreSQLがあるサーバーだけ200ステータスを返すので、このような振り分けができる仕組みとなっています。
設定ができたらHAProxyのサービスを有効化して起動します。
systemctl enable haproxy systemctl start haproxy
2. データ同期の検証
フェイルオーバーの検証を行う前に、先ずはそもそもPostgreSQL同士がちゃんとデータ同期されるかを検証します。
HAProxyが起動しているサーバーで、PostgreSQLに接続します。
クライアント:kat-patroni-lb
psql -h localhost -p 5000 -U postgres
postgresユーザーのパスワードを聞かれるので、Patroniの設定ファイルでpostgresqlセクションのauthenticationのところに書いたパスワード(pos-xxxxx)を入力します。
HAProxy経由でPostgreSQLのマスタに繋がったら以下のCREATE文を実行、作成したhauserユーザーとhadbデータベースに全てのPostgreSQLから接続できるかを確認しました。
CREATE ROLE hauser WITH LOGIN PASSWORD 'xyz-xxxxx'; CREATE DATABASE hadb OWNER hauser;
クラスタ1-3:kat-patroni01-03
HAProxyを使わずクラスタ1-3のサーバーに直接入ってから、それぞれのサーバーで起動しているPostgreSQLへhauserユーザーとしてhadbデータベースに接続してみます。
# クラスタ1で接続するとき psql -h xx.xx.xx.99 -p 5432 -U hauser -d hadb # クラスタ2で接続するとき psql -h xx.xx.xx.100 -p 5432 -U hauser -d hadb # クラスタ3で接続するとき psql -h xx.xx.xx.101 -p 5432 -U hauser -d hadb
いずれも成功したので、PostgreSQL間でデータ同期が取れていることが確認できました!
3. 自動フェイルオーバーの検証
それではいよいよ肝心のフェイルオーバーを検証します。
先ずどのPostgreSQLがマスタなのかを確認します。HAProxyを経由してどこに接続されたかがわかればそれがマスタということになります。
クライアント:kat-patroni-lb、クラスタ1-3:kat-patroni01-03
HAProxyを経由して接続している間、クラスタ1-3のサーバーに直接入ってPostgreSQLに繋ぎ、以下のSQLを実行してHAProxyのあるIPアドレスからのセッションが返ってきたらそこがマスタです。
SELECT pid, usename, client_addr, client_port, state, query FROM pg_stat_activity WHERE state != '' AND pid != pg_backend_pid();
今回の構築手順を行えば大抵はクラスタ1のPostgreSQLがマスタとなっていると思いますので、クラスタ1をサーバーごと停止し、自動フェイルオーバーが行われてクラスタ2か3のPostgreSQLがマスタに昇格され、HAProxyを経由して接続した際に新しいマスタに繋がるかを検証します。
- 上記のSQLでクラスタ1のPostgreSQL(マスタ)に接続できていることを確認
- GMOアプリクラウドのコンパネから、クラスタ1のサーバー(kat-patroni01)を停止
- HAProxy経由で再度PostgreSQLに接続し、クラスタ2か3のサーバーに接続できていることを上記SQLで確認
この手順で行った結果、クラスタ2のPostgreSQLがマスタに昇格されて、HAProxy経由で新しいマスタに接続できていることが確認できました!
マスタのPostgreSQLしかWALのアーカイブログは吐かないんですが、クラスタ2のサーバーの/var/lib/pgsql/12/archiveを見るとアーカイブログができていました。
最後に、この状態で新しいマスタに繋いでCREATE TABLE文を実行し、クラスタ3のPostgreSQLに同期されているかも確認してみます。
クライアント:kat-patroni-lb
HAProxy経由でPostgreSQL(新しいマスタ:クラスタ2)に接続し、以下のCREATE TABLE文を実行
CREATE TABLE films (
code char(5),
title varchar(40),
did integer,
date_prod date,
kind varchar(10),
len interval hour to minute,
CONSTRAINT code_title PRIMARY KEY(code,title)
);
クラスタ2-3:kat-patroni02-03
クラスタ2-3のサーバーに直接入ってPostgreSQLに繋ぎ、作成したfilmsテーブルができていることを確認します。
\d films;
無事にfilmsテーブルをクラスタ3でも確認することができました。
これで最初マスタだったクラスタ1のPostgreSQLが倒れても、クラスタ2のPostgreSQLが自動フェイルオーバーでマスタに昇格し、クラスタ2とクラスタ3の間でレプリケーションが継続されていることも検証できました!
最後にもう一つ、停止したクラスタ1のサーバーを起動し直して、クラスタ1のPostgreSQLをPatroniのクラスタに戻すフェイルバックをやってみます。
実はとても簡単で、今回の構築手順を行っていればサーバーを起動するとPatroniも自動的に立ち上がってフェイルバックを自動的にやってくれました!
マスタはクラスタ2のPostgreSQLのままで、復帰したクラスタ1のPostgreSQLはスレーブとしてレプリケーションされていて、クラスタ1が停止しているときに作成したfilmsテーブルもクラスタ1のPostgreSQLで確認することができました。
クラスタ1:kat-patroni01
参考までにPatroniのクラスタ状態を確認すると以下のようになります。クラスタ2のPostgreSQLがマスタで、クラスタ1のPostgreSQLもクラスタに復帰できていることがわかります。
patronictl -c /etc/patroni.yml list # 結果 +------------------+----------------------+---------------+--------------+---------+----+-----------+ | Cluster | Member | Host | Role | State | TL | Lag in MB | +------------------+----------------------+---------------+--------------+---------+----+-----------+ | postgres-cluster | postgresql-patroni01 | xx.xx.xx.99 | | running | 2 | 0 | | postgres-cluster | postgresql-patroni02 | xx.xx.xx.100 | Leader | running | 2 | | | postgres-cluster | postgresql-patroni03 | xx.xx.xx.101 | Sync Standby | running | 2 | 0 | +------------------+----------------------+---------------+--------------+---------+----+-----------+
注意点としては、etcdは今回の構築手順ではサーバーを起動しても自動的には立ち上がりませんでした。etcdも3台でクラスタを構成しているため1台落ちていたも問題なかったです。 以下のコマンドで起動したらフェイルバックは完了です。
フェイルバックもとても簡単ですね。本番運用のときにはetcdも自動起動するようにしておくと良いと思いました。
# etcd起動 systemctl start etcd # etcdのクラスタを確認 /usr/etcd-2.3.8/etcdctl member list # 結果 b125cb142c522b4: name=etcd03 peerURLs=http://xx.xx.xx.101:2380 clientURLs=http://xx.xx.xx.101:2379 isLeader=true 91c55248feceb0b6: name=etcd02 peerURLs=http://xx.xx.xx.100:2380 clientURLs=http://xx.xx.xx.100:2379 isLeader=false ab52793fbec2ca29: name=etcd01 peerURLs=http://xx.xx.xx.99:2380 clientURLs=http://xx.xx.xx.99:2379 isLeader=false
6. まとめ
1. Patroniの感想
正直に言ってPatroniは結構使える気がします。Patroniの設定を覚えるのはちょっと大変ですが、PatroniだけでPostgreSQL同士のレプリケーションや自動フェイルオーバーを制御できるのはかなり強力です。
今後新たにHadoopクラスタを組むことがあったら、Hiveが使うデータベースなどにPostgreSQL+Patroniのクラスターを利用してみようと思います。
2. 今後の課題
今回やれなかったこととして、
- Patroniの設定項目をもっと深追いする
- PostgreSQLが2台倒れたらどうなるか
- 同期モードのレプリケーションについてもっと検証(特に性能面)
といった検証課題が残っています。
本番運用を見据えると、これらの課題はクリアしないといけないので、いつかどこかで試そうと思います。
最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD