2020.10.07
Spark Streaming + Kudu + Impalaでリアルタイムデータ集積&分析を試す
こんにちは。次世代システム研究室のS.T.です。
前回の続編として,分散データストア「Kudu」を主軸に,SparkとImpalaを使ってリアルタイムにデータ集積・分析を行う環境の検証を行います。前回はローカルのVMでKuduをビルドして環境を構築しましたが,今回はConoHa(VPS)上のサーバでクラスタ環境を構築し,その上で検証を行います。
とりあえず3行で
- DStreamでDataFrameを作ってKuduのinsertRowsに投げたけど動かなかったよ
- 手動でKuduSessionを開いてOperationを取得して操作したら書き込めたよ
- 書き込みながらImpalaからクエリを投げて実用的な時間で返ってくるよ
この記事でやること
Kudu(分散ストレージ)+Spark(分散処理フレームワーク)+Impala(クエリエンジン)を使ったシステムの開発・検証に使えるような環境をVPSサービスConoHa<fn>ConoHa</fn>上に構築し,各コンポーネント間で連携してデータ蓄積・分析を行う環境の検証を行います。
- ローカル上のVMにKudu,Spark,Impalaをセットアップ(自前でビルド):前回の内容
- Spark Streaming(DStream)でデータを継続的に受け取り・加工
- KuduのテーブルへINSERT
- ImpalaからSQLで集計
各コンポーネントの概要
Spark Streaming
Spark Streamingは,KafkaのようなメッセージキューやTCPソケットなどから連続的に発生するデータを小さなバッチに分解し,Spark上で処理を行うことができるものです。DStreamという概念で抽象化されており,コード上ではこれに対して次々と処理を適用していくことになります。
図1に示すように,あるWindowの幅(t=0, 1, 2,… のそれぞれの間)の期間に受信したデータに対して処理を順番に適用し,完了次第次の処理に移る,といった流れで,連続的なデータに対する処理を小さな処理に分解し,分散処理を行うことができます。例えば,t=0から1までに10件のデータを受信した場合,t=1のタイミングでまとめて10件分の処理が行われます。各処理が1つのスレッドとして動作し,Sparkのクラスタ上で毎度起動して処理を行います。
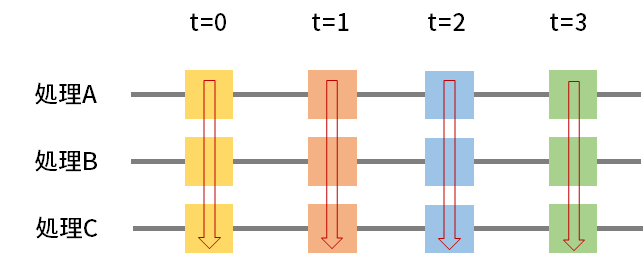
図1:Spark Streamingの処理の流れ
詳細はプログラミングガイドを参照していただくとわかりやすいでしょう。<fn>Spark Streaming Programming Guide</fn>
また,今回は取り上げていませんが,Structured Streamingというストリーム処理エンジンも存在します。Spark StreamingがRDDを用いているのに対してStructured StreamingはDataFrameを用いており,新規に実装する場合はこちらを選ぶことも多いかと思いますので,機会があればこちらも取り上げてみたいと思います。
Kudu・Impala
Kudu・Impalaの詳細については前回の記事<fn>Kudu+Spark+Impalaを手元で試す環境を構築する</fn>や前々回の記事<fn>Apache Impala 3.3をビルドして新機能を試す – S3のファイルハンドルキャッシュ</fn>で触れていますので,そちらを参照してください。
環境セットアップ
今回はVPS ConoHa上のVMを使用します。
- kudu01:2GBプラン CentOS 8.2 Kudu master / Spark master
- kudu02-05:2GBプラン CentOS 8.2 Kudu tablet / Spark slave
- imp01:8GBプラン CentOS 7.8 Impala
ConoHaのローカルネットワーク機能を用いて,各ノードに以下のようにプライベートIPアドレスを割り当てました(hostsファイルに記載して名前解決できるようにしておく)。JDKは各ノード共通でOpen JDK 1.8.0_265を使用しています。
192.168.100.1 kudu01 192.168.100.2 kudu02 192.168.100.3 kudu03 192.168.100.4 kudu04 192.168.100.5 kudu05
Kudu・Impala
これらは前回の記事でビルドしたものをコピーして使用します。ディレクトリ構成やJDKのバージョンをビルド環境と合わせること,起動したことがあるKuduをコピーする場合は
メタデータ類(metaディレクトリなど)を削除する必要があることに注意してください。
Impalaは過去記事のとおり環境変数をexportした後に以下のコマンドで起動します。
export KUDU_MASTER_HOSTS=kudu01 ./bin/impala-shell.sh
Kuduは過去記事と同じコマンド(masterの指定は変更します)で起動します。起動後はノードのグローバルIPアドレス:8051で
# master /opt/kudu/usr/local/sbin/kudu-master --fs_data_dirs /opt/kudu/data/ --fs_metadata_dir /opt/kudu/meta/ --fs_wal_dir /opt/kudu/wal/ --log_dir /opt/kudu/log/ & # tablet /opt/kudu/usr/local/sbin/kudu-tserver --fs_data_dirs /opt/kudu/data/ --fs_metadata_dir /opt/kudu/meta/ --fs_wal_dir /opt/kudu/wal/ --log_dir /opt/kudu/log/ --tserver_master_addrs kudu01 &
Spark
今回はYARNの環境がないので,Sparkのスタンドアロンモードを使用してクラスタを起動します。スタンドアロンモードはSparkのみを使ってマスタノード,スレーブノードを起動しクラスタを作成するモードです。Sparkの詳細なアーキテクチャについては良質な書籍や記事がたくさんありますので,本記事の範囲外とします。
MavenリポジトリにKuduのライブラリはScala 2.11向けのものが最新なので,spark-2.4.7-bin-hadoop2.7を使用します。
スタンドアロンモードで使用するのは非常に簡単で,spark-2.4.7-bin-hadoop2.7のアーカイブをダウンロード,展開した後,以下のコマンドを各ノードで実行するのみです。
# master ~/spark-2.4.7-bin-hadoop2.7/sbin/start-master.sh -h kudu01 # slave ~/spark-2.4.7-bin-hadoop2.7/sbin/start-slave.sh spark://kudu01:7077
masterの起動時にバインドするアドレスを指定する-hオプションでkudu01を指定しないと,slaveがローカルネットワークで接続できないので注意が必要です。
検証
上記のセットアップで5台構成のkuduとSparkクラスタが完成しました。これをつかって
- TCP 12345番で待ち受けて適当なフォーマットのログを模したデータ(後述)を返すアプリケーションを作る
- Spark StreamingでTCP 12345からデータを読み取り,1秒間隔でKuduに書き込む
- Impalaでリアルタイムで集計する
という操作を行い,期待通りの処理が行われているか,書き込んだデータをリアルタイムに取得できるかを検証します。
テストデータ生成アプリケーション
今回は「ある時間にユーザが出したスコア」という設定で
UNIX_TIME,LOG_ID,USER_ID,SCORE
というカンマ区切りのデータを生成します。UNIX_TIMEは現在時刻のUNIX時間,LOG_IDはログ固有の文字列(UUIDを使用),ユーザIDは1~10000までの9999通りの乱数(あとで集計クエリをつかった検証をしやすくするために範囲を狭めている),スコアは0~100までの乱数を入れ,10msに1回TCP 12345番に接続してきたクライアントに対して送信するRubyスクリプトを作成します。
単に生成するだけではつまらないので,1000分の1の確率で同じログを2回同時に出力するような動きを入れておき,書き込む際に重複除去を行ってみます。
Impalaでテーブル作成
上記のログに合わせて下記のようなテーブルを作成します。ハッシュパーティショニングで16個のパーティションに分割します。
CREATE TABLE user_logs (
id STRING,
unix_time INTEGER,
user_id INTEGER,
score INTEGER,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
;
Spark Streamingでデータ取得・書き込み
キモになる部分を以下に示します。ウィンドウサイズを1秒として,ストリームで入ってくるカンマ区切りのデータをパース後,(ID, リスト)のタプルで用いて重複除去を行ったあと,結果をKuduに書き込んでいます。ログは10msおきに出力されるので,1回の処理で100行のログが処理されることになります。
val kc = new KuduContext("kudu01:7051", sc)
val schema = StructType(List(
StructField("id", StringType, nullable = false),
StructField("unix_time", StringType, nullable = true),
StructField("user_id", StringType, nullable = true),
StructField("score", StringType, nullable = true)
))
val lines = ssc.socketTextStream("kudu01", 12345)
lines
.map(x => {
val l = x.split(",")
(l(1), l)
})
.reduceByKey((x, y) => y)
.map(_._2)
.foreachRDD(rdd => rdd.foreach( x => {
val kuduClient = kc.syncClient
val kuduSession = kuduClient.newSession()
kuduSession.setFlushMode(SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND)
val table = kuduClient.openTable("impala::default.user_logs")
val op = table.newInsert()
val row = op.getRow
row.addString("id", x(1))
row.addInt("unix_time", x(0).toInt)
row.addInt("user_id", x(2).toInt)
row.addInt("score", x(3).toInt)
kuduSession.apply(op)
kuduSession.flush()
kuduSession.close()
})
)
書き込みを行う部分はKudu公式のチュートリアル<fn>Developing Applications With Apache Kudu</fn>に記載されている「insertRows(dataFrame, tableName)」よりも冗長ですが,このように少しまわりくどいやり方をしないとうまく書き込みすることができませんでした。そこで(Spark用ラッパではない)KuduのAPIを使用し,直接Sessionを開いて書き込みを行っています。
完全なソースコードはこちら。
Impalaからクエリ実行
しばらく放置してデータがたまるのを待ち,Impalaからクエリを実行してみます。
[localhost.localdomain:21000] default> select count(1) from user_logs; +----------+ | count(1) | +----------+ | 9453971 | +----------+ Fetched 1 row(s) in 0.16s [localhost.localdomain:21000] default> select count(1) from user_logs; +----------+ | count(1) | +----------+ | 9454024 | +----------+ Fetched 1 row(s) in 0.13s [localhost.localdomain:21000] default> select count(1) from user_logs; +----------+ | count(1) | +----------+ | 9454138 | +----------+ Fetched 1 row(s) in 0.13s
このように連続してCOUNTを実行すると,どんどんデータが増えていっているのがわかります。リアルタイムに書き込み・読み込みができているようです。
では次に「累計スコアトップ10のユーザ」を集計して表示してみます。
[localhost.localdomain:21000] default> select user_id, sum(score) as s from user_logs group by user_id order by s desc limit 10; +---------+-------+ | user_id | s | +---------+-------+ | 9982 | 53213 | | 1651 | 53035 | | 7426 | 52895 | | 761 | 52730 | | 5321 | 52680 | | 8347 | 52625 | | 4924 | 52584 | | 4087 | 52548 | | 6090 | 52496 | | 3316 | 52486 | +---------+-------+ Fetched 10 row(s) in 1.27s
データ数は950万件弱でビッグデータとは言えない件数ですが,この程度の規模であれば1秒強で結果を取得することができました。リアルタイムにデータを書き込みながら,実用的な速度でインタラクティブにSQLを実行できそうです。
Stream処理の段階で行っている重複除去の成果を確認します。
[localhost.localdomain:21000] default> select id, count(1) as cnt from user_logs group by id having count(1) > 1; Fetched 0 row(s) in 17.66s
重複データはなく,期待通りに処理されています。こちらは少し重く,20秒弱の時間を要しました。しかし,インタラクティブにクエリを発行しデータを見ていくには十分な性能です。今回Kuduの各ノードのスペックが低い上にImpalaが1ノードなので,スペックアップ&複数ノードで分散することで,より高速な動作が期待できます。
所感
5台構成でノードのスペックも十分とは言えないものでしたが,毎秒100件弱の書き込みを行う程度ではまだ余裕があり,リアルタイムに集計クエリを実行することもできました。蓄積したデータをリアルタイムに使いたい要求が強い場合,十分選択肢に入ると思います(もちろんそれを意図して作られているわけですが)。masterのHA構成にも対応しており,プロダクションでも活躍できそうです。
ImpalaやSpark経由でBIツールやアプリケーションとの連携がとれるのでこういった点でも使いやすそうですが,運用やメンテナンスはHDFSと比べると少し大変そうな雰囲気なので,そのあたりがどうなっているかを調査するのが今後の課題です。
最後に
次世代システム研究室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD