2018.04.10
Hadoop (Hive, Ambari など) が使う DB を Percona XtraDB Cluster & ProxySQL で冗長化してみた
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
最近 MySQL 系のデータベース (Percona Server / PXC) に関するブログを立て続けに書いていましたが、今回は Hadoop と MySQL 両方に関する内容について書きました。
- 前々回のブログ:InnoDB だけじゃない!MyRocks (MySQL + RocksDB) ストレージエンジンを試してみた
- 前回のブログ:MySQLの冗長化を試す!~Percona XtraDB Cluster & ProxySQL & Replication~
Hadoop を構築すると毎回頭を悩ますこととして、Hadoop エコシステムの各サービス自体は冗長化が強化されているのに、Hive などがバックエンドで使うデータベースだけは蚊帳の外で、ここが単一障害点になってしまっていることでした。
データベースは Hadoop 利用者が自分たちで好きなものを使って冗長化してね、というスタンスなんだと思いますが、せっかく分散&冗長化に特徴がある Hadoop を使っていていつも微妙に思うところだったりします。。
さらに微妙なのは、Hadoop のサービスって結構データベースを利用しているんですが、デフォルトではどれも別々の種類を使っていたりして、Hadoop を構築運用しているのに、データベース構築運用まで見ないといけないところです。
(せめて Hive くらいは自分たちが今から構築する Hadoop クラスタで HBase とかうまく利用してくれないか、とずっと密かに思ってたりします)
そんなこんなで今回は、前回のブログで検証した、PXC & ProxySQL を使って Hadoop を構築してみるのを試してみました。
今回の検証内容
Hadoop クラスタには Hortonworks の HDP (バージョン2.6.4) を利用し、Ambari (Hadoop クラスタを管理するツール) を使って構築します。
Ambari と Hive の使うデータベースを PXC にして、ProxySQL 経由で見にいかせます。
そして、Hive を冗長化して片系の Hive と PXC のプライマリノード (単独の書き込み可能ノード) を落として問題なく Hive が使えるかを検証します。
前回のおさらいになりますが、PXC は同じレコードを別々のノードから更新をかけると先勝ちで、後からの更新はエラー (PXC ではデッドロックエラー) になるため、アプリケーション側で制御が必要になります。
Hive が PXC のデッドロックエラーにうまく対応しているわけもないので、今回の検証ではシングルプライマリモードのまま利用します。
今回のサーバー構成
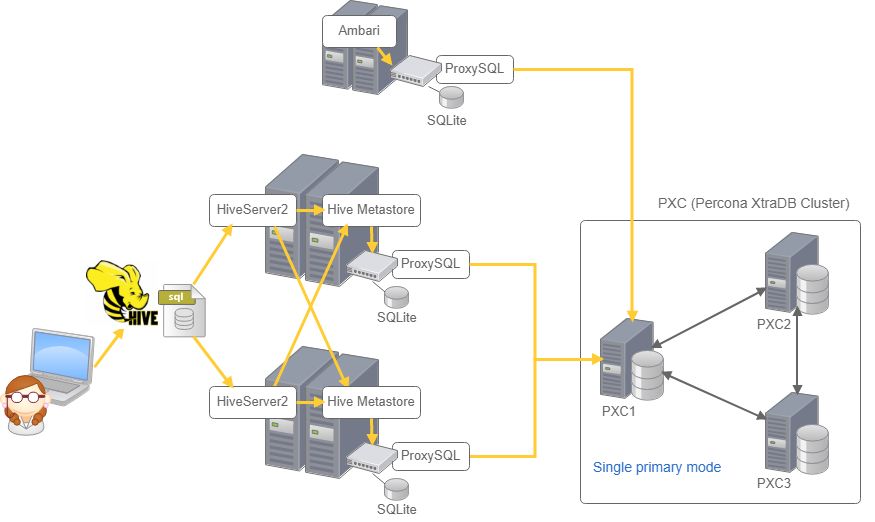
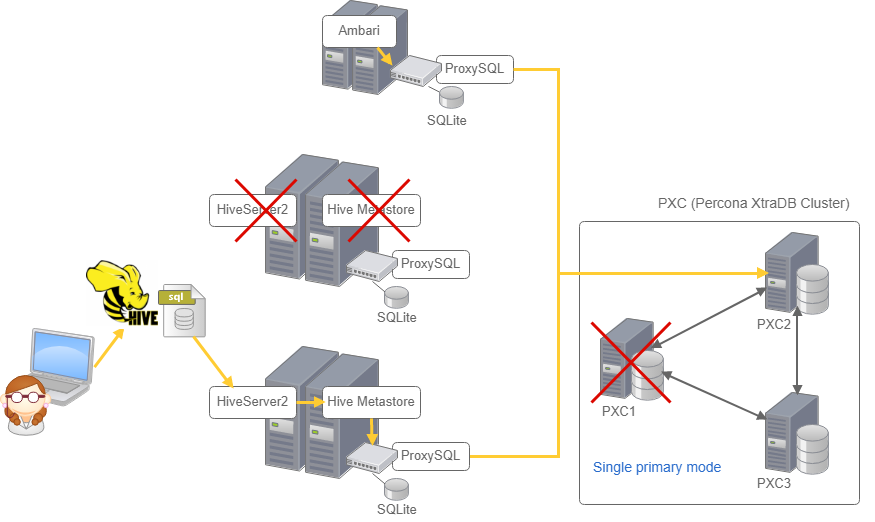
上記構成から片系の Hive と PXC のプライマリノード を落として検証します。
Hadoop 構築前の準備
まず、Hadoop 構築前の環境を準備します。
サーバースペック
検証環境は毎度お馴染みの GMO アプリクラウドのサーバーを使いました。スペックは以下です。
- OS : CentOS 7
- 仮想 CPU : 4
- メモリ容量 : 16GB
- ディスク容量 : 320GB
参考までに、GMOアプリクラウドの技術を応用した Z.com クラウドもあります
hosts ファイルの設定
Hadoop の構築といったら兎にも角にもまず host の設定です。
今回は DNS は使わずに /etc/hosts ファイルを使って設定します。
すべての サーバー で実施します。Hadoop クラスタ を構成するホストには 必ず FQDN のホスト名も入れてください。
echo ' xx.xx.xx.99 tst-hdp-am.tst.hdptest.com tst-hdp-am xx.xx.xx.51 tst-hdp-m1.tst.hdptest.com tst-hdp-m1 xx.xx.xx.52 tst-hdp-m2.tst.hdptest.com tst-hdp-m2 xx.xx.xx.53 tst-hdp-m3.tst.hdptest.com tst-hdp-m3 xx.xx.xx.61 tst-hdp-s1.tst.hdptest.com tst-hdp-s1 xx.xx.xx.62 tst-hdp-s2.tst.hdptest.com tst-hdp-s2 xx.xx.xx.63 tst-hdp-s3.tst.hdptest.com tst-hdp-s3 xx.xx.xx.10 tst-pxc1 xx.xx.xx.20 tst-pxc2 xx.xx.xx.30 tst-pxc3 ' >> /etc/hosts
今回は、Ambari を立てるサーバーを tst-hdp-am、Hadoop クラスタのマスターノードとして利用するホストを tst-hdp-m1, m2, m3 、スレーブノードとして利用するホストを tst-hdp-s1, s2, s3 としました。
PXC を構成するノードは、tst-pxc1, pxc2, pxc3 です。
一般的には Hadoop クラスタのマスターノードには HDFS の NameNode や YARN の ResouceManager、ZooZookeeper の Server、そして Hive の HiveServer2 や Hive Metastore などを割り当てたりします。
対になるスレーブノードには HDFS の DataNode と YARN の NodeManager を割り当てます。
(スレーブノードは分散処理が行われるメインになるので他のサービスはあまり割り当てません)
hosts ファイルの設定が終わったら、Hadoop クラスタ を構成するホストに一つずつログインし、以下のように hostnamectl コマンドで自分自身の FQDN を設定します。
hostnamectl set-hostname tst-hdp-am.tst.hdptest.com
ntp サーバーの構築
Hadoop クラスタの構築では、各ホストの時間がずれていないことがとても大事になります。
PXC と Hadoop クラスタのすべてのホストで時間が同期されるように、ntp サーバーを構築してセットアップします。
(詳細は割愛)
パスワードなしの SSH 認証
HDP の Hadoop クラスタを Ambari を使って構築するので、Ambari を立てるホストの root 権限相当の OS ユーザーが、Hadoop クラスタの全ノードにパスワードなしで SSH 認証できるようにします。
これをしておかないと、Ambari から Hadoop クラスタを構築することができません。
tst-hdp-am で root ユーザーになり ssh-keygen を実施、作成された公開鍵の内容を Hadoop クラスタを構成する全ホストの .ssh/authorized_keys にコピーします。
自分自身のサーバー (Ambari を立てるサーバー) の authorized_keys にも必ずコピーします。
今回は root ユーザーで実施しましたが、本番環境の場合はセキュリティ統制のこともあり、別のユーザー (ambari ユーザーなど) を作成して、sudo 権限を与えるのが良いです。
curl と wget のインストール
すべてのホストで、curl と wget がなければインストールしておきます。
yum install -y curl yum install -y wget
実践的な OS 周りのセットアップ
ここは必要がなければ読み飛ばしてもらっても構いません。本番運用するのにやることが多いであろうセットアップです。
Hadoop 環境に適した設定を行います。
CentOS 7 では tuned という Linux の代表的なカーネルパラメータをチューニングしてくれるデーモンが立ち上がります。
tuned が有効になっていると sysctl で設定したはずのパラメータを上書きするので要注意です。今回は tuned で設定しました。
Hadoop クラスタを構成するすべてのホストで実施します。
tuned での設定
まず新しい tuned の設定を作成します。そのために、HDP 向けの conf ファイルを作成します。
設定内容は以下です。こちらの記事を参考にしました。
- スワップ無効化
- ページキャッシュ(ダーティページ)の書き出し設定変更
- transparent_hugepage 無効化
mkdir /etc/tuned/hdp cp /usr/lib/tuned/throughput-performance/tuned.conf /etc/tuned/hdp/tuned.conf
/etc/tuned/hdp/tuned.conf ファイルを開き、各セクションで以下のように値を修正します。
[vm] transparent_hugepages=never [sysctl] vm.dirty_ratio = 50 vm.dirty_background_ratio = 20 vm.swappiness = 0
また、以下のセクションを追記します。
[script] script=desable-thp-defrag.sh
desable-thp-defrag.sh スクリプトを作成します。
echo '#!/bin/sh
. /usr/lib/tuned/functions
start() {
echo never > /sys/kernel/mm/transparent_hugepage/defrag
return 0
}
stop() {
return 0
}
process $@' > /etc/tuned/hdp/desable-thp-defrag.sh
chmod 755 /etc/tuned/hdp/desable-thp-defrag.sh
準備が整ったので、tuned を今回の HDP 設定に切り替えます。
tuned-adm profile hdp
これで設定が反映されているはずです。
オープンファイル制限数とプロセス・スレッド制限数の増加
オープンファイル制限数とプロセス・スレッド制限数も増やしておきます。
/etc/security/limits.conf を開き、以下の設定に修正します。
* soft nofile 1006500 * hard nofile 1006500 * soft nproc 1006500 * hard nproc 1006500
Percona XtraDB Cluster (PXC) の構築
PXC 構築には、前回のブログの環境を再利用しました。
キャラクタセットの変更
PXC ノード全台で、キャラクタセットの設定を変更します。
MySQL 5.7 系ではキャラクタセットのデフォルトが utf8mb4 になりますが、今回の環境では対応していないため、utf8 にします。
/etc/percona-xtradb-cluster.conf.d/pxc.cnf を開き、以下のように値に変更と、skip-character-set-client-handshake をコメントアウトします。
character-set-server=utf8 collation-server=utf8_general_ci # skip-character-set-client-handshake
※データベースの構築は、Hadoop 環境を構築する前を強くオススメします。Hadoop 環境を作った後で各サービスのデータベースを変更するのは大変でいろんな問題でハマりやすいです。
ProxySQL 構築とセットアップ
Ambari を立てるホストと、Hadoop クラスタのマスターノードとして利用するホスト全台に ProxySQL を構築します。
マスターノードに立てる予定の Hive Metastore が ProxySQL 経由で PXC を見にいくようにすることで、PXC のプライマリノードが1台倒れても ProxySQL がフェイルオーバーを行ってくれます。
ProxySQL を1ホストだけに構築しないのは、ProxySQL が今度は単一障害点になってしまうからです。
ProxySQL を幾つも構築した場合に、フェイルオーバーしたら ProxySQL ごとにプライマリになるノードが変わってしまうことが課題でした。
シングルプライマリの状態になっていないと、冗長化した Hive には適しません。
いろいろ調べた結果、host_priority.conf にプライマリに昇格する順番を記述できることがわかりました。
この設定をすべての ProxySQL で同じにしておけば、フェイルオーバーしたときのプライマリ昇格するノードを同じにできます。
ProxySQL のインストール
まず、/etc/my.cnf がサーバーにあれば、それを消します。
rm -f /etc/my.cnf rm -rf /etc/my.cnf.d/mysql-clients.cnf
必要なものをインストールして、ProxySQLを起動します。
yum install -y libaio yum install -y http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm yum install -y proxysql yum install -y Percona-Server-client-57
PXC に Ambari と Hive 用のユーザーを作成
PXC のいずれかのノードに接続、以下を実施
mysql> CREATE USER ambari@'xx.xx.xx.%' IDENTIFIED BY '*****'; GRANT ALL ON *.* TO ambari@'xx.xx.xx.%'; CREATE USER hive@'xx.xx.xx.%' IDENTIFIED BY '*****'; GRANT ALL ON hive.* TO hive@'xx.xx.xx.%'; FLUSH PRIVILEGES;
ProxySQLの設定
今回は proxysql-admin ツールは使わずに設定します。
Hadoop クラスタのマスターノードの全ホストで同じように行います。
監視やフェイルオーバーを行うスクリプト /usr/bin/proxysql_galera_checker を使う設定をしますが、実はこの proxysql_galera_checker は proxysql-admin の設定ファイル /etc/proxysql-admin.cnf を見ていました。
ですので、proxysql-admin ツールは使わなくても、proxysql-admin.cnf を以下のように編集します。
cp -p /etc/proxysql-admin.cnf /etc/proxysql-admin-conf.bak echo '# proxysql admin interface credentials. export PROXYSQL_DATADIR='/var/lib/proxysql' export PROXYSQL_USERNAME='admin' export PROXYSQL_PASSWORD='admin' export PROXYSQL_HOSTNAME='localhost' export PROXYSQL_PORT='6032' # ProxySQL read/write configuration mode. export MODE="singlewrite" # ProxySQL Cluster Node Priority File export HOST_PRIORITY_FILE=$PROXYSQL_DATADIR/host_priority.conf' > /etc/proxysql-admin.cnf
ProxySQL はインストールしたばかりでは admin ユーザーにパスワード「admin」で接続できます。本番構築時は NG ですが、今回は手間を省くためそのまま使います。PROXYSQL_PASSWORD に「admin」と記述します。
※ProxySQL の admin ユーザーのパスワードを変える場合は、/etc/proxysql.cnf をエディターで開き、admin_credentials を修正するなどします。
また、フェイルオーバー時のプライマリ昇格順を決めるため、HOST_PRIORITY_FILE に指定している host_priority.conf を編集します。
昇格順に「ホスト名:ポート番号」の形で記述します。
echo 'xx.xx.xx.10:3306 xx.xx.xx.20:3306 xx.xx.xx.30:3306' > /var/lib/proxysql/host_priority.conf
※今回 PXC の各ノードは、MySQL お馴染みの 3306 ポートで立ち上げているので、ポート番号のところは 3306 です。
設定ファイルの準備が済んだら、ProxySQL を起動&接続して設定を登録してきます。
ProxySQL へは mysql クライアント (厳密には Percona Server クライアント) を使って、接続します。
systemctl start proxysql mysql -u admin -padmin -h'localhost' -P6032 --protocol=tcp --prompt='ProxySQL> '
ProxySQL にノードの登録をします。ProxySQL の mysql_servers というテーブルにレコードを挿入します。
INSERT 文の hostname の値は適切なものに変えてください。
今回 hostgroup_idは書き込みノード (つまりシングルプライマリノード) は 10、読み込みノードは 11 としました。
weight は フェイルオーバーのための監視スクリプトに、書き込み 1000000、読み込み 1000 とハードコーディングっぽく書かれていたのでそのまま踏襲します。
ProxySQL> INSERT INTO mysql_servers (hostgroup_id, hostname, port, status, weight, comment) VALUES (10, 'xx.xx.xx.10', 3306, 'ONLINE', 1000000, 'WRITE'), (11, 'xx.xx.xx.20', 3306, 'ONLINE', 1000, 'READ'), (11, 'xx.xx.xx.30', 3306, 'ONLINE', 1000, 'READ') ; LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK;
※なお、LOAD と SAVE を行わないと、メモリ上の現設定への反映と永続化がされないので忘れないこと。
次に PXC に接続するユーザーの情報を登録します。mysql_users というテーブルにレコードを挿入します。
ambari ユーザーも hive ユーザーも当然書き込みをするので、default_hostgroup を 書き込みノードの hostgroup_id の 10 にします。
パスワードは先ほど PXC にユーザーを作った際のパスワードと同じでないといけません。
ProxySQL> INSERT INTO mysql_users (username, password, default_hostgroup) VALUES
('ambari', '*****', 10),
('hive', '*****', 10)
;
LOAD MYSQL USERS TO RUNTIME;
SAVE MYSQL USERS TO DISK;
続いて ProxySQL が PXC を監視するユーザーの登録をします。global_variables というテーブルの該当レコードを更新します。
今回、前回の検証で既に作ってある pxc_monitor ユーザーで登録しましたが、新たに作るときは、PXC ノードで ambari と hive ユーザーの他に、監視用ユーザーも作成しておきます。
監視用ユーザーは USAGE 権限のみで OK です。
ProxySQL> SELECT * FROM global_variables WHERE variable_name LIKE 'mysql-monitor_%'; UPDATE global_variables SET variable_value='pxc_monitor' WHERE variable_name = 'mysql-monitor_username'; UPDATE global_variables SET variable_value='*****' WHERE variable_name = 'mysql-monitor_password'; LOAD MYSQL VARIABLES TO RUNTIME; SAVE MYSQL VARIABLES TO DISK;
監視ユーザーが監視を定期的に実行するための登録をします。scheduler というテーブルにレコードを挿入します。
各項目の意味はこちらのドキュメントを参考にしてください。
filename に指定しているのが、フェイルオーバーのための監視スクリプトです。
ProxySQL> INSERT INTO scheduler (id, active, interval_ms, filename, arg1, arg2, arg3, arg4, arg5) VALUES (10, 1, 3000, '/usr/bin/proxysql_galera_checker', 10, 11, 1, 1, '/var/lib/proxysql/proxysql_galera_checker.log') ; LOAD SCHEDULER TO RUNTIME; SAVE SCHEDULER TO DISK;
上記設定後、暫くして下記のクエリで結果が返ってきたら監視できていることがわかります。
SELECT * FROM monitor.mysql_server_connect_log ORDER BY time_start_us DESC LIMIT 12;
Amabari の構築とセットアップ
MySQL Connector/J のインストール
Ambari を立てるサーバーに、まず MySQL Connector/J をインストールします。
MySQL のサイトからダウンロードして配置するだけで完了です。
配置場所は必ず /usr/share/java にします。
今回は現時点で最新の mysql-connector-java-5.1.46 を利用しました。
tar zxvf mysql-connector-java-5.1.46.tar.gz cd mysql-connector-java-5.1.46 mkdir -p /usr/share/java mv mysql-connector-java-5.1.46.jar /usr/share/java/ chmod 644 /usr/share/java/mysql-connector-java-5.1.46.jar
Ambari のインストール
Ambari を立てるサーバーに、CentOS 7 用の最新の Ambari をインストールします。
cd /var/tmp wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.1.0/ambari.repo -O /etc/yum.repos.d/ambari.repo yum repolist yum install ambari-server
Ambari と Hive 用のデータベース(スキーマ)構築
Ambariをインストールしたサーバーから、Ambari と Hive 用のデータベースを作成し、Ambari 用のテーブルを予め作成します。
ProxySQL を経由して、PXC に ambari ユーザーで接続します。
mysql -hlocalhost -P6033 -uambari -p --protocol=tcp
※ protocol に tcp を指定しないと、socket を見にいって怒られますので要注意。
mysql> CREATE DATABASE ambari; mysql> CREATE DATABASE hive; mysql> use ambari; mysql> source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
ambari-server の JDBC 設定
続けて、ambari-server の JDBC 設定を行います。
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java-5.1.46.jar
以下のように返ってきて、プロンプトが戻ってきたら成功です。
----------------------------------------- Using python /usr/bin/python Setup ambari-server Copying /usr/share/java/mysql-connector-java-5.1.46.jar to /var/lib/ambari-server/resources If you are updating existing jdbc driver jar for mysql with mysql-connector-java-5.1.46.jar. Please remove the old driver jar, from all hosts. Restarting services that need the driver, will automatically copy the new jar to the hosts. JDBC driver was successfully initialized. Ambari Server 'setup' completed successfully. -----------------------------------------
ambari-server のセットアップ
いよいよ Ambari をセットアップします。
ambari-server setup
ところどころ、YES か NO (y/n) か、どの番号を選ぶか、名前・パスワードを聞かれるので、以下のように選択しています。
Using python /usr/bin/python Setup ambari-server Checking SELinux... SELinux status is 'disabled' Customize user account for ambari-server daemon [y/n] (n)? n Adjusting ambari-server permissions and ownership... Checking firewall status... Checking JDK... [1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8 [2] Oracle JDK 1.7 + Java Cryptography Extension (JCE) Policy Files 7 [3] Custom JDK ============================================================================== Enter choice (1): 1 To download the Oracle JDK and the Java Cryptography Extension (JCE) Policy Files you must accept the license terms found at http://www.oracle.com/technetwork/java/javase/terms/license/index.html and not accepting will cancel the Ambari Server setup and you must install the JDK and JCE files manually. Do you accept the Oracle Binary Code License Agreement [y/n] (y)? y Downloading JDK from http://public-repo-1.hortonworks.com/ARTIFACTS/jdk-8u112-linux-x64.tar.gz to /var/lib/ambari-server/resources/jdk-8u112-linux-x64.tar.gz jdk-8u112-linux-x64.tar.gz... 100% (174.7 MB of 174.7 MB) Successfully downloaded JDK distribution to /var/lib/ambari-server/resources/jdk-8u112-linux-x64.tar.gz Installing JDK to /usr/jdk64/ Successfully installed JDK to /usr/jdk64/ Downloading JCE Policy archive from http://public-repo-1.hortonworks.com/ARTIFACTS/jce_policy-8.zip to /var/lib/ambari-server/resources/jce_policy-8.zip Successfully downloaded JCE Policy archive to /var/lib/ambari-server/resources/jce_policy-8.zip Installing JCE policy... Checking GPL software agreement... GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? y Completing setup... Configuring database... Enter advanced database configuration [y/n] (n)? y Configuring database... ============================================================================== Choose one of the following options: [1] - PostgreSQL (Embedded) [2] - Oracle [3] - MySQL / MariaDB [4] - PostgreSQL [5] - Microsoft SQL Server (Tech Preview) [6] - SQL Anywhere [7] - BDB ============================================================================== Enter choice (1): 3 Hostname (localhost): 127.0.0.1 Port (3306): 6033 Database name (ambari): ambari Username (ambari): ambari Enter Database Password (bigdata):***** Re-enter password: Configuring ambari database... Configuring remote database connection properties... WARNING: Before starting Ambari Server, you must run the following DDL against the database to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql Proceed with configuring remote database connection properties [y/n] (y)? y Extracting system views... ambari-admin-2.6.1.0.143.jar ........... Adjusting ambari-server permissions and ownership... Ambari Server 'setup' completed successfully.
JDK を Hadoop クラスタを構成するすべてのホストに配布
root ユーザーのパスワードなし SSH 認証を行った kat-hdp-am で行うと楽ちんです。
cd /usr scp -pr jdk64 tst-hdp-m1:/usr/ scp -pr jdk64 tst-hdp-m2:/usr/ scp -pr jdk64 tst-hdp-m3:/usr/ scp -pr jdk64 tst-hdp-s1:/usr/ scp -pr jdk64 tst-hdp-s2:/usr/ scp -pr jdk64 tst-hdp-s3:/usr/
ambari.properties を編集
/etc/ambari-server/conf/ambari.properties の JDBC ドライバーのフルパスを変更しておきます。
server.jdbc.driver.path=/usr/share/java/mysql-connector-java-5.1.46.jar
ambari-server 起動
ambari-server を起動します。
ambari-server start
以下のようにエラー無く返ってきたら完了です。
Using python /usr/bin/python Starting ambari-server Ambari Server running with administrator privileges. Organizing resource files at /var/lib/ambari-server/resources... Ambari database consistency check started... Server PID at: /var/run/ambari-server/ambari-server.pid Server out at: /var/log/ambari-server/ambari-server.out Server log at: /var/log/ambari-server/ambari-server.log Waiting for server start........................................ Server started listening on 8080 DB configs consistency check: no errors and warnings were found. Ambari Server 'start' completed successfully.
Ambari の管理画面から Hadoop クラスタ構築
ここからは Ambari 管理画面にブラウザでログインして操作します。
必要に応じて tst-hdp-am ホスト の 8080 ポートを SSH トンネリングするなどして、ambari管理画面にブラウザでログインします。
初期状態では、Ambari 管理画面に admin ユーザーでパスワード「admin」でログインします。
Install Wizard に従って構築
Ambari 管理画面に初めてログインすると、Launch Install Wizard ボタンが出てくるので、それを押します。
Wizard に従って構築を進めます。
Get Started
クラスタ名を記入します。今回は「HDPWITHPXC」としました。
Select Version
HDP-2.6.4.0を選択します。
「Use Public Repository」をチェックし、今回 OS には一応 redhat-ppc7 と redhat7 だけ残して Remove しました。
Install Options
「Target Hosts」に Hadoop クラスタを構成する全ホストの FQDN をコピペします。
必ず FQDN にしてください。
tst-hdp-am.tst.hdptest.com tst-hdp-m1.tst.hdptest.com tst-hdp-m2.tst.hdptest.com tst-hdp-m3.tst.hdptest.com tst-hdp-s1.tst.hdptest.com tst-hdp-s2.tst.hdptest.com tst-hdp-s3.tst.hdptest.com
Host Registration Information では、
「Provide your SSH Private Key to automatically register hosts」にチェック、
「ssh private key」には kat-hdp-am ホストの root ユーザー が ssh-keygen で作成した秘密鍵 (.ssh/id_rsa) の内容をコピペ、
「SSH User Account」は rootのまま、
「SSH Port Number」は 22 のまま、
「Register and Confirm」ボタンを押します。
※本番運用を見据えて、パスワードなし SSH 認証 の対象ユーザーを root にしないときは、「ssh private key」と「SSH User Account」の内容は適切なものに変えてください。
Confirm Hosts
全ホストともに Status が Success、All host checks passed on 7 registered hosts. の結果に。
Choose Services
稼働させる Hadoop サービスを選択します。今回は Hive を使って検証するので以下を必須としてください。
それ以外は任意で選びます。
- HDFS
- YARN + MapReduce2
- Tez
- Hive
- ZooKeeper
- SmartSence ※チェック外せない
Assign Masters
Hadoop クラスタのマスターノードのホスト1つに、Hive Metastore と HiveServer2 を割り当てます。
今回は tst-hdp-m2 ホストにしました。
後で Hive を冗長化するときには、もう1セットの Hive Metastore と HiveServer2 を別のホスト (tst-hdp-m3) に割り当てます。
Assign Slaves and Clients
「DataNode」には Hadoop クラスタのスレーブノードのホスト3台をチェック、
「NodeManager」にはHadoop クラスタのスレーブノードのホスト3台をチェック、
「Client」には Hadoop クラスタの全ホストをチェックします。
Customize Services
「HDFS」のディレクトリを環境に合わせて変更します。今回の GMO アプリクラウドは /var 配下にディスクがたくさん割り当てられているため、/var 配下にします。
NameNode: NameNode directories = /var/hadoop/hdfs/namenode DataNode: DataNode directories = /var/hadoop/hdfs/data
上記以外はとりあえずデフォルトにします。
「Hive」が使うデータベースの接続設定を変更します。ProxySQL 経由で PXC に作成した hive データベースを見にいくようにします。
Advanced: Hive Metastore: Hive Database -> Existing MySQL / MariaDB Databaseにチェック Database Name = hive Database Username = hive Database Password = ***** Database URL = jdbc:mysql://localhost:6033/hive ※変更前 jdbc:mysql://kat-hdp-m2.kat.hdptest.com/hive
「SmartSence」の admin ユーザーのパスワードを設定します。今回は検証なので「admin」としました。
Activity Analysis: Password for user 'admin' = admin
Review、Install, Start and Test、Summary
あとは状態の確認を進めるだけなんですが、Hive のサービスが起動に失敗。。
構築でどハマりしたこと
ここまでの作業でも幾つもハマったりしたんですが、どハマりしたのは、Hive Metastore がどうにもこうにも起動しなかったことです。
いろいろと調べたり試したりして、何度も試行錯誤するうち、最終的には一応の解決をみました。
Hive Metastore が起動しない主な原因は、Hive Metastore のテーブル作成がイケてないのと、トランザクション分離レベルに実は SERIALIZABLE を指定してたことでした。
Hive Metastore のテーブル作成がイケてない
エラーの内容を追っかけて、Hive Metastore のテーブル定義を確認すると、なんと Primary Key (PK) が定義されてないテーブルがありました・・。
PXC は PK がないテーブルは強く非推奨となっています。
PXC の pxc_strict_mode パラメータを ENFORCING にしていると、PK がないテーブルを作ることができません。
ENFORCING を止めることも考えましたが、PXC の運用上何が起きるかわからず、本質的には PK のないテーブルを作っている方が良くないので、やむを得ず Hive Metastore のテーブル定義を修正することにしました。
Hive Metastore 用のテーブル作成文は、HDP 2.6.4 では、/usr/hdp/2.6.4.0-91/hive2/scripts/metastore/upgrade/mysql/hive-schema-2.1.2000.mysql.sql です。
hive-schema-2.1.2000.mysql.sqlは、その中で同じディレクトリにある hive-txn-schema-2.1.0.mysql.sql も読み込んでいました。
PK がないテーブルを定義しているのは、hive-txn-schema-2.1.0.mysql.sql の方でした。
Hive Metastore のテーブル定義を修正
Hive Metastore が立ち上がるホストで実施する必要があります。今回は Hive 冗長化も見据えて Hadoop クラスタのマスターノードの全ホストで実施しました。
cd /usr/hdp/2.6.4.0-91/hive2/scripts/metastore/upgrade/mysql cp hive-txn-schema-2.1.0.mysql.sql hive-txn-schema-2.1.0.mysql.modified.sql
hive-schema-2.1.2000.mysql.sql を開き、読み込むファイルを変更しておきます。
-- SOURCE hive-txn-schema-2.1.0.mysql.sql; SOURCE hive-txn-schema-2.1.0.mysql.modified.sql;
次に hive-txn-schema-2.1.0.mysql.modified.sql を開き、以下のようにテーブル定義を変更しました。
Hive のソースコードを少し見て、PK がない該当のテーブルについて、PK にできるカラムがあるものはそのカラムに PK を張り、PK にできるカラムがないときは AUTO_INCREMENT カラムを追加してそこに PK を張る形でいけそうだったので、そのようにしています。
-- 全部のカラムでPKになりそうだが、varchar(767)が混じっていてダメなので、dummyのPKを張る CREATE TABLE TXN_COMPONENTS ( DUMMY_ID bigint NOT NULL AUTO_INCREMENT, TC_TXNID bigint NOT NULL, TC_DATABASE varchar(128) NOT NULL, TC_TABLE varchar(128) NOT NULL, TC_PARTITION varchar(767), TC_OPERATION_TYPE char(1) NOT NULL, PRIMARY KEY (DUMMY_ID), FOREIGN KEY (TC_TXNID) REFERENCES TXNS (TXN_ID) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; CREATE TABLE COMPLETED_TXN_COMPONENTS ( DUMMY_ID bigint NOT NULL AUTO_INCREMENT, CTC_TXNID bigint NOT NULL, CTC_DATABASE varchar(128) NOT NULL, CTC_TABLE varchar(128), CTC_PARTITION varchar(767), PRIMARY KEY (DUMMY_ID) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; CREATE TABLE WRITE_SET ( DUMMY_ID bigint NOT NULL AUTO_INCREMENT, WS_DATABASE varchar(128) NOT NULL, WS_TABLE varchar(128) NOT NULL, WS_PARTITION varchar(767), WS_TXNID bigint NOT NULL, WS_COMMIT_ID bigint NOT NULL, WS_OPERATION_TYPE char(1) NOT NULL, PRIMARY KEY (DUMMY_ID) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; --- Hive のソースコード見る限り、1行のUPDATEしかなさそうなので、そのままPKをはる CREATE TABLE NEXT_TXN_ID ( NTXN_NEXT bigint NOT NULL, PRIMARY KEY (NTXN_NEXT) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; INSERT INTO NEXT_TXN_ID VALUES(1); CREATE TABLE NEXT_LOCK_ID ( NL_NEXT bigint NOT NULL, PRIMARY KEY (NL_NEXT) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; INSERT INTO NEXT_LOCK_ID VALUES(1); CREATE TABLE NEXT_COMPACTION_QUEUE_ID ( NCQ_NEXT bigint NOT NULL, PRIMARY KEY (NCQ_NEXT) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; INSERT INTO NEXT_COMPACTION_QUEUE_ID VALUES(1); -- 何故か同じカラムに2つKEY(インデックス)を貼ろうとしているので、以下のCREATE INDEX 文をコメントアウト -- CREATE INDEX HL_TXNID_IDX ON HIVE_LOCKS (HL_TXNID);
注意すること
この修正した Hive Metastore のテーブル作成文を先に手動で実施すると、そのあとで Ambari 管理画面から Hive Metastore を立ち上げようとすると以下のエラーで怒られます。。
CREATE INDEX PCS_STATS_IDX ON PART_COL_STAT S (DB_NAME,TABLE_NAME,COLUMN_NAME,PARTITION_NAME) USING BTREE Error: Duplicate key name 'PCS_STATS_IDX' (state=42000,code=1061)
原因は推定ですが、先にテーブルを作っていても、Hive Metastore を最初に立ち上げるときにはテーブルを作ろうとして、IF EXISTS オプションがついている CREATE 文は問題なく、ついていないところで怒られたためと思われます。
この回避策として、hive.metastore.schema.verification を有効にしないようにしたら上手くいきました。
Ambari 管理画面で、Hive > Configs > Advanced > Custom hive-siteに以下を追加します。
hive.metastore.schema.verification=false
Hive Metastore はトランザクション分離レベルに実は SERIALIZABLE を指定してた
テーブル定義を修正したら OK かと思ったら、今度はまた別のエラーで Hive Metastore が立ち上がらず困りました。。
Percona-XtraDB-Cluster doesn't recommend using SERIALIZABLE isolation with pxc_strict_mode = ENFORCING
あれ、SERIALIZABLE isolation ?と思って、PXC 側で general log を仕掛けるなど調査した結果、Hive Metastore はまさかの毎回以下のコマンドを発行しておりました・・。今更知って驚愕とする事実・・。
SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE
そして、PXC はトランザクション分離レベルの SERIALIZABLE は強く非推奨で、PXC の pxc_strict_mode パラメータを ENFORCING にしていると、操作が一切できません。。
Hive Metastore が 上記の SERIALIZABLE にする SET SESSION 文を発行しないようにできないか、いろいろ試しましたがダメで、PXC を利用するのはもう諦めかけましたが、一つやり方を見つけました。
PXC の pxc_strict_mode を ENFORCING から MASTER に変更するというものです。
PXC の pxc_strict_mode を MASTER に変更
Percona のこちらの記事を参考にしました。
この記事によると、pxc_strict_mode を MASTER にするとトランザクション分離レベルが SERIALIZABLE でも、書き込み可能なノードが一つなら利用できると書いてあります。
PK がないテーブルは ENFORCING と同様に許可されません。
PXC ノードすべてで以下を実施します。再起動しても設定が戻らないように、PXC の設定ファイル (今回の環境では /etc/percona-xtradb-cluster.conf.d/pxc.conf) にも忘れずに反映しておきます。
mysql> SET GLOBAL pxc_strict_mode=MASTER;
これで、ようやく Hive Metastore が立ち上がることができました!
Hive の冗長化
Hive の冗長化を行います。Ambari 管理画面から設定するだけで簡単にできました。
まず Hive Metastore を冗長化します。もう一つの Hive Metastore と HiveServer2 のセットは tst-hdp-m3 に立てる予定なので、そのように設定します。
Ambari 管理画面で、Hive > Service Actions > +Add Hive Metastore を選び、
「Select the host to add Hive Metastore component」に tst-hdp-m3.tst.hdptest.com を選びます。
後は Ambari がやってくれるので、終わったら再起動します。
次に HiveServer2 を冗長化します。
Ambari 管理画面で、Hive > Service Actions > +Add HiveServer2 を選び、
「Select the host to add HiveServer2 component」に tst-hdp-m3.tst.hdptest.com を選びます。
後は Ambari がやってくれるので、終わったら再起動します。
これで無事に立ち上がったら完了です。
フェイルオーバー検証
Hive まで冗長化できたので、ついに本題の検証に入ります。
Hive の片系のサービス (Hive Metastore、HiveServer2) と PXC のプライマリノード (単独の書き込み可能ノード) を落として Hive がちゃんと使えるか4つのシナリオで検証しました。
- シナリオ1)片系 (tst-hdp-m2) の HiveServer2 を落として Hive がうまく動くか
- シナリオ2)片系 (tst-hdp-m2) の HiveMetastore を落として Hive がうまく動くか
- シナリオ3)PXC1 を落として Hive がうまく動くか
- シナリオ4)PXC1 と片系 (tst-hdp-m2) の HiveMetastore と HiveServer2 を落としてHiveがうまく動くか
検証方法
まず検証用にテストテーブルを作り、そこにテストデータを20件ほど入れておきます。
シナリオごとに beeline (Hive のクライアント) で Hive に接続、CREATE TABLE AS SELECT 文を使ってテストテーブルからデータとテーブル定義を新たに作成するという簡単なものです。
テーブル定義はこちらを使いました。
CREATE TABLE test_tbl ( test_id int, test_txt string, test_time timestamp ) STORED AS ORC;
INSERT INTO 文などでデータを格納し、
このような CREATE TABLE AS SELECT 文を使って検証しました。
CREATE TABLE test_tbl_1 STORED AS ORC AS SELECT test_id, test_txt, CURRENT_TIMESTAMP FROM test_tbl;
beeline での Hive への接続方法は、Hive のあるホストを直接指定すると冗長化にならないため、Zookeeper を使って冗長化に対応する以下の接続方法を使います。
beeline -n hive -u "jdbc:hive2://kat-hdp-m1.kat.hdptest.com:2181,kat-hdp-m2.kat.hdptest.com:2181,kat-hdp-m3.kat.hdptest.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"
検証結果
検証方法を決めたらあとは粛々とやるだけです。
そして、シナリオ1、シナリオ2、シナリオ3、シナリオ4すべてで問題なく CREATE TABLE AS SELECT 文が動作しました!
ちなみに、シナリオ3、シナリオ4で PXC のプライマリノードを落としたときに、Hadoop クラスタのマスターノード全ホストの ProxySQL のフェイルオーバー状態をみると、
ProxySQL> select * from mysql_servers; +--------------+--------------+------+--------------+---------+-------------+-----------------+---------------------+---------+----------------+---------+ | hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment | +--------------+--------------+------+--------------+---------+-------------+-----------------+---------------------+---------+----------------+---------+ | 11 | xx.xx.xx.10 | 3306 | OFFLINE_HARD | 1000 | 0 | 1000 | 0 | 0 | 0 | READ | | 10 | xx.xx.xx.20 | 3306 | ONLINE | 1000000 | 0 | 1000 | 0 | 0 | 0 | WRITE | | 11 | xx.xx.xx.30 | 3306 | ONLINE | 1000 | 0 | 1000 | 0 | 0 | 0 | READ | +--------------+--------------+------+--------------+---------+-------------+-----------------+---------------------+---------+----------------+---------+
host_priority.conf に書いた通りの順番でプライマリ昇格していました。
検証後、落としていた PXC1 ノード (xx.xx.xx.10) を再起動させると、
ProxySQL> select * from mysql_servers; +--------------+--------------+------+--------+---------+-------------+-----------------+---------------------+---------+----------------+---------+ | hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment | +--------------+--------------+------+--------+---------+-------------+-----------------+---------------------+---------+----------------+---------+ | 10 | xx.xx.xx.10 | 3306 | ONLINE | 1000000 | 0 | 1000 | 0 | 0 | 0 | WRITE | | 11 | xx.xx.xx.20 | 3306 | ONLINE | 1000 | 0 | 1000 | 0 | 0 | 0 | READ | | 11 | xx.xx.xx.30 | 3306 | ONLINE | 1000 | 0 | 1000 | 0 | 0 | 0 | READ | +--------------+--------------+------+--------+---------+-------------+-----------------+---------------------+---------+----------------+---------+
一番優先度を高くした PXC1ノード にプライマリが戻っていました。
まとめ
今回だいぶ変則的な方法を使った感じですが、簡単な検証をした限りでは目的の冗長化を達成することができました。
わかったこととしては、
- Hive の データベース (RDB) の使い方はかなりイケてない
- PK がないテーブルは Hive のトランザクション対応のためのものに見えるのですが、そこの開発をしている人が PK のないテーブルを作ったり SERIALIZABLE だけを使っているように見えたり、RDB のトランザクションのことをあんまりわかっていないかも知れない・・・
- PK がないテーブルだと、PXC とは別のソリューションとして 最近出てきた InnoDB Cluster も非対応なので、今回の対応みたいに PK を作って下さいと言いたい
- 本番の Hadoop クラスタに PXC (pxc_strict_mode = Master) & ProxySQL を使うには、もっと検証したほうが良さそう
- ProxySQL のフェイルオーバーについて、複数の ProxySQL で同じプライマリ昇格順を設定できたのは良かったものの、タイミングは完全に同期しないと思われるので、より詳細な設定や使いどころの見極めが大事
- 今回みたいにテーブル定義を修正して本当に大丈夫かはもっと検証が必要
- 現段階では PXC を Hadoop クラスタに使うのはオススメの構成とは言い難い
- やっぱりリスクを取らないのであれば、MHA for MySQL あたりを検討することになりそうです
などです。
今後も Hadoop クラスタで使うデータベースの冗長化については追っかけて行こうと思います。
最後に
次世代システム研究室では、データ分析エンジニアやアーキテクトを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD