2017.04.04
Apache HAWQ を最新の Hadoop パッケージ ( HDP 2.5.3 ) で使ってみた(前編)
こんにちは。次世代システム研究室のデータベース・Hadoop (MySQL/MariaDB/PerconaServer, PostgreSQL, Hive, HBase, etc..) 担当のM.K.です。
今回は一連の GreenplumDB の検証の続きで、GreenplumDB を Hadoop とくっつけてしまった変種?の Apache HAWQ を試してみます。
HAWQ のアーキテクチャー理解と、HAWQ クラスタの構築をやってみました。
とりあえず前編です!後編はまたいつか・・
HAWQ は Hadoop で動くものの、GreenplumDB の特徴自体は変わらないので、以前に書いた「CentOS 7 に Greenplum DB クラスタを構築してみた」を見直しながらやりました。
前提知識として参考になると思うので良かったらご覧ください。
HAWQのアーキテクチャー
GreenplumDB は PostgreSQL のフォークで Redshift のようなプロダクトですが、HAWQ はそれをさらにHadoop の HDFS に搭載したようなものです。
HAWQ は “HAdoop With Query” の頭文字から命名されました。
アーキテクチャーについての詳細は
に非常によくまとまっています。

抜粋「Figure 2: Apache HAWQ components」 – Introducing The Newly Redesigned Apache HAWQ
詳細はこれらの資料を見ていただくとして、自分が思う HAWQ の特徴は次の3つ。
HAWQ の3つの特徴
- 1. データの冗長性は HDFS で担保
- 2. YARN と連携が可能
- 3. 各種 Hadoop サービスと直接データをやり取りできない
上記 1 は HDFS を利用しているので当たり前ですね。
上記 2 は YARN のリソース管理に統合してくれる話なので各種 Hadoop サービスと一緒に利用していく場合などにはとても有用です。
Cloudera の CDH や Hortonworks の HDP に HAWQ を組み込んで、各種 Hadoop サービスと連携してこその HAWQ と思うので、YARN との連携は外せないところ。
が、しかし、上記 3 のように実は HDFS 上にあっても肝心の HAWQ のデータと Hive などの他の Hadoop サービスは直接やりとりできません。
そこで PXF (Pivotal Extention Framework) というプロダクトをあわせて利用します。
PXF については後編で試す予定です。詳細はこちらの PXF のスライド資料(英語) をご覧ください。
OSS 版と商用版
HAWQ は 2015 年に Pivotal から Apache Software Foundation に寄贈され Apache HAWQ として OSS 版となりました。
それにともなって商用版プロダクトは Pivotal HDB となっています。
今回試した HAWQ クラスタの構築では、HDB のパッケージは使わず、Apache HAWQ をビルドしてインストールしました。
HAWQ クラスタの構築
クラスタを構築するにあたって、サーバー構成は次のようにしてみました。
Hadoop 環境には素の Hadoop ではなく Hortonworks の HDP を使い、この環境に HAWQ をくっつけます。
- Ambari サーバー x 1
- マスターノード x 3
- スレーブノード x 5
マスターノードには、HDP の NameNode や ResourceManager、HiveServer2、ZooKeeper などに加えて、HAWQ のマスターを2台(アクティブ/スタンバイ)割り当てます。
スレーブノードは HDP の DataNode、NodeManager、そして HAWQ のセグメントサーバー専用にします。
マスターノードとスレーブノードのスペックは「CentOS 7 に Greenplum DB クラスタを構築してみた」のときと同等です。
今回も GMO アプリクラウドのサーバーを使いました。
- OS : CentOS 7
- 仮想 CPU : 4
- メモリ容量 : 16GB
- ディスク容量 : 320GB
HAWQ クラスタの構築は以下の手順で行いました。
- 1. 全ホストの初期セットアップ
- 2. HDP のインストール(with Ambari)
- 3. NameNode HA と ResourceManager HA
- 4. Apache HAWQ のビルド&インストール
- 5. HAWQ クラスタの初期化(各種プロパティ設定)&起動
やってみて思いましたが、HDP の構築をしてから HAWQ をビルド&インストールするので、思ったより手間がかかります。
そして、たいてい初めての構築はどこかでハマるものですが、案の定 HDP と HAWQ それぞれで大きくハマってしまい、だいぶ時間がかかってしまいました。
全ホストの初期セットアップ
まず Hadoop 構築で最も大事なことといえば、ホスト名の設定です。
ホスト名に使って良い記号は「-」ハイフンのみで、FQDN できちんと設定しないと、HDP 構築している際によくハマります。
「_」アンダーバーなどの記号をついうっかり使ってしまうと、HDP 構築時にサービスが起動しなくて途中から進めなくなったりしますので要注意。
/etc/hosts を以下のように全ホストに設定します。
xx.xx.xx.x0 tst-hawq-am.tst.hawq.com tst-hawq-am xx.xx.xx.x1 tst-hawq-m1.tst.hawq.com tst-hawq-m1 xx.xx.xx.x2 tst-hawq-m2.tst.hawq.com tst-hawq-m2 xx.xx.xx.x3 tst-hawq-m3.tst.hawq.com tst-hawq-m3 xx.xx.xx.x4 tst-hawq-s1.tst.hawq.com tst-hawq-s1 xx.xx.xx.x5 tst-hawq-s2.tst.hawq.com tst-hawq-s2 xx.xx.xx.x6 tst-hawq-s3.tst.hawq.com tst-hawq-s3 xx.xx.xx.x7 tst-hawq-s4.tst.hawq.com tst-hawq-s4 xx.xx.xx.x8 tst-hawq-s5.tst.hawq.com tst-hawq-s5
それから、hostnamectl コマンドを利用して、以下のようにそれぞれのホスト名を変えていきます。全ホストで実施します。
hostnamectl set-hostname tst-hawq-am.tst.hawq.com
次に Hadoop 環境ではホスト間の時間のズレを許さないため、ntp サーバーをセットアップします(詳細は割愛)。
Hadoop 構築で必須の設定とされている transparent_hugepage の無効化も実施します(手順は「CentOS 7 に Greenplum DB クラスタを構築してみた」の「transparent_hugepage の無効化」を参照)。
最後に OS パラメータとユーザーリソースの設定です。
設定値は Apache HAWQ の Build and Install の「Rad Hat/CentOS 7.X」タブに書かれた内容に従いました。
OS パラメータの設定
echo ' kernel.shmmax = 1000000000 kernel.shmall = 4000000000 kernel.shmmni = 4096 kernel.sem = 250 512000 100 2048 kernel.sysrq = 1 kernel.core_uses_pid = 1 kernel.msgmnb = 65536 kernel.msgmax = 65536 kernel.msgmni = 2048 net.ipv4.tcp_syncookies = 0 net.ipv4.conf.default.accept_source_route = 0 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_max_syn_backlog = 200000 net.ipv4.conf.all.arp_filter = 1 net.ipv4.ip_local_port_range = 1281 65535 net.core.netdev_max_backlog = 200000 vm.overcommit_memory = 2 fs.nr_open = 3000000 kernel.threads-max = 798720 kernel.pid_max = 798720 # increase network net.core.rmem_max=2097152 net.core.wmem_max=2097152 ' > /etc/sysctl.d/hawq_os_setting.conf sysctl --system
OS ユーザーリソースの設定
echo '* soft nofile 2900000 * hard nofile 2900000 * soft nproc 131072 * hard nproc 131072' >> /etc/security/limits.conf
これで初期セットアップ完了です。
HDP のインストール (with Ambari)
Ambari 2.4.1 を利用して、最新の HDP をインストールします。
CentOS 7 用の Ambari レポジトリを Hortonworks のサイトから選びます。
選んだ Ambari レポジトリの取得に wget を利用するため、wget がない環境であれば先にインストールし、次に ambari-server をインストールして、HDP を構築します。Ambari サーバー用のホストで行います。
yum install wget cd /usr/local/src wget -nv http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.1.0/ambari.repo -O /etc/yum.repos.d/ambari.repo yum repolist yum install ambari-server ambari-server setup
ところどころ y か n を聞かれますが、今回は以下のようにしました。JDK8 を利用し、デフォルトの DB 設定とします。
Customize user account for ambari-server daemon [y/n] (n)? n Do you want to change Oracle JDK [y/n] (n)? y [1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8 [2] Oracle JDK 1.7 + Java Cryptography Extension (JCE) Policy Files 7 [3] Custom JDK ============================================================================== Enter choice (1): 1 Do you accept the Oracle Binary Code License Agreement [y/n] (y)? y Enter advanced database configuration [y/n] (n)? n
Ambari サーバーのセットアップが終わったら、Ambari サーバー用のホストから他の全ホストにパスワードなしで ssh できるための設定を行います。
root ユーザーもしくは root 権限相当のユーザーで ssh-keygen を実施、公開鍵の内容を全ホストの同じユーザーの ~/.ssh/authorized_keys にコピーします。
準備できたら、Ambari サーバーを起動します。
ambari-server start
リモートデスクトップや SSH トンネルを利用して、Ambari サーバーの 8080 ポートにブラウザアクセスします。
ログイン画面になるのでユーザー&パスワードを入力してログインします(今回はデフォルトのままなので、admin / admin)。
あとは CLUSTER INSTALL WIZARD に従って構築します(HDP 構築の詳細は今回は割愛)。
途中、ssh private key の記述を求められるので、前述の ssh-keygen を行ったユーザーと、
その秘密鍵の内容を貼り付けてください。
今の時点で最新の HDP2.5.3 をインストール、目的に応じたサービスを選択します。
- HDFS
- YARN
- ZooKeeper
は必須です。これらに加えて、Hive / Tez / Spark などを入れてみました。
サービスの構成は、上述のようにスレーブノードは DataNode、NodeManager のみにして、マスターノードの3台に他のものを割り当てました。
ハマったところ
構築中、curl を使っているところがありましたが、curl が入っていなかくてコケました。全ホストで curl をインストールしておきましょう。
一番ハマったのは、MapReduce2 の History Server がどうしても起動してくれないという事象で、このためにその他のサービスがうまく構築できませんでした。
結局いろいろ調査した結果、この事象が原因ということがわかり、NameNode の heap size を 1G から 2G にしたらうまくいきました。
NameNode HA と ResourceManager HA
HAWQ が HA 設定で動くか試したいので、NameNode と ResouceManagerの HA 設定を実施します。
以下のドキュメントの通りに実施すればうまく設定できます。
- NameNode HA化の手順
- ネームサービスは、hawqcluster としておきます。後述する HAWQ の各種プロパティ設定で指定します。
- Resource Manager HA化の手順
Apache HAWQ のビルド&インストール
HDP が構築できたら、いよいよ Apache HAWQ のインストールです。
Apache HAWQ の Build and Install の「Rad Hat/CentOS 7.X」タブに書かれた手順を参考に行います。
HAWQ クラスタを構築するマスタノード 2 台とスレーブノード 5 台で実施します。
wget を使ってレポジトリやソースを落とすので、入っていなければインストールしてください。
ビルドに必要なものをインストールします。
wget https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm rpm -ivh epel-release-latest-7.noarch.rpm yum makecache yum install -y man passwd sudo tar which git mlocate links make bzip2 net-tools \ autoconf automake libtool m4 gcc gcc-c++ gdb bison flex gperf maven indent \ libuuid-devel krb5-devel libgsasl-devel expat-devel libxml2-devel \ perl-ExtUtils-Embed pam-devel python-devel libcurl-devel snappy-devel \ thrift-devel libyaml-devel libevent-devel bzip2-devel openssl-devel \ openldap-devel protobuf-devel readline-devel net-snmp-devel apr-devel \ libesmtp-devel python-pip json-c-devel \ java-1.7.0-openjdk-devel lcov cmake\ openssh-clients openssh-server perl-JSON perl-Env pip --retries=50 --timeout=300 install pycrypto
しかしこのまま configure、make、make install をすると怒られます。CentOS では yum で cmake をインストールしてもバージョン 2 系までしか入りません。
cmake3 が要求されるので、面倒ですが cmake3 だけ個別対応します。
cmake2 系を使わないように削除、cmake3 のバイナリを取得し cmake3 のパスを通します。
yum erase -y cmake wget https://cmake.org/files/v3.7/cmake-3.7.2-Linux-x86_64.tar.gz tar zxvf cmake-3.7.2-Linux-x86_64.tar.gz mv cmake-3.7.2-Linux-x86_64 /usr/local/cmake3 sed -i -e '/^PATH=/s/$PATH:/$PATH:\/usr\/local\/cmake3\/bin:/' ~/.bash_profile . ~/.bash_profile
Apache HAWQ のソースを取得します。なるべく最新のものを使うため git 上のものを取ってきます。
PL/Python と GreenplumDB でも利用するクエリオプティマイザの gporca を利用したいので、この 2 つを有効にする configure 設定にしました。
git clone https://git-wip-us.apache.org/repos/asf/incubator-hawq.git CODE_BASE=`pwd`/incubator-hawq cd $CODE_BASE ./configure --prefix=/usr/local/hawq --with-python --enable-orca make -j8 make install
続けて、HAWQ 用のスーパーユーザーを作成します。
名前はなんでも構いませんが、GreenplumDB クラスタを構築したときのように今回は gpadmin ユーザーとしました。
HDP 連携をスムーズに行うため、ユーザーグループは hadoop にします。
useradd -d /home/gpadmin -s /bin/bash -g hadoop -m gpadmin chown -R gpadmin.hadoop /usr/local/hawq
HAWQ マスターから gpadmin ユーザーがパスワードなしで他の HAWQ クラスタのホストに ssh できるように設定します。
自分自身のホストにもパスワードなしで ssh できるようにしておきます。
HAWQ マスターのアクティブとスタンバイ両方で行います。
su - gpadmin cd ~ ssh-keygen cat .ssh/id_rsa.pub > .ssh/authorized_keys chmod 600 .ssh/authorized_keys
~/.ssh/id_rsa.pub の内容を自分以外の全ホストの ~/.ssh/authorized_keys にコピー(gpadmin ユーザー)、パーミッションを 600 にしてください。
~/.ssh がなければ mkdir して 700 のパーミッションにしておきます。
HAWQ が使用する HDFS ディレクトリを事前に作成します。どこかのホスト 1 台から実施。
su - hdfs hdfs dfs -mkdir /hawq hdfs dfs -chown -R gpadmin:hadoop /hawq hdfs dfs -mkdir /user/gpadmin hdfs dfs -chown gpadmin /user/gpadmin
HAWQ 用の環境変数 (greenplum_path.sh) を常に読み込めるように、gpadmin ユーザーの .bash_profile を編集します。
HAWQ マスター 1 台から gpssh を利用すれば 1 回のコマンド実施で済みます。
su - gpadmin echo 'tst-hawq-m1 tst-hawq-m2 tst-hawq-s1 tst-hawq-s2 tst-hawq-s3 tst-hawq-s4 tst-hawq-s5' > hawq_all_hosts source /usr/local/hawq/greenplum_path.sh gpssh -f hawq_all_hosts -e "echo . /usr/local/hawq/greenplum_path.sh >> .bash_profile"
HAWQ マスター用のローカルディレクトリを HAWQ マスターホスト 2 台に作成します。
下記の “/var/hadoop/hdfs/namenode” の箇所は HDP を構築したときの NameNode ディレクトリを指定します。
確認の際は Ambari サーバーにブラウザアクセスし、HDFS >> Configs >> NameNode directories を参照してください。
NameNode ディレクトリ配下は HDP 構築時のパーミッションでは gpadmin ユーザーがディレクトリを作成できないので注意。
mkdir -p /var/hadoop/hdfs/namenode/hawq/master chown -R gpadmin:hadoop /var/hadoop/hdfs/namenode/hawq
それから HAWQ セグメントサーバー用のローカルディレクトリをスレーブノード 5 台に作成します。
下記の “/var/hadoop/hdfs/data” の箇所は HDP を構築したときの DataNode ディレクトリを指定します。
確認の際は Ambari サーバーにブラウザアクセスし、HDFS >> Configs >> DataNode directories を参照してください。
DataNode ディレクトリ配下は HDP 構築時のパーミッションでは gpadmin ユーザーがディレクトリを作成できないので注意。
mkdir -p /var/hadoop/hdfs/data/hawq/segment chown -R gpadmin:hadoop /var/hadoop/hdfs/data/hawq
HAWQ クラスタの初期化(各種プロパティ設定)&起動
次に最も肝心な HAWQ 用の設定ファイルを編集します。HAWQ マスターノード(アクティブ)で実施。
編集する設定ファイルは次の 4 つです。
- slaves
- hdfs-client.xml
- yarn-client.xml
- hawq-site.xml
slaves の編集
/usr/local/hawq/etc/slaves ファイルを以下のように書き換えます。
echo 'tst-hawq-s1.tst.hawq.com tst-hawq-s2.tst.hawq.com tst-hawq-s3.tst.hawq.com tst-hawq-s4.tst.hawq.com tst-hawq-s5.tst.hawq.com' > /usr/local/hawq/etc/slaves
hdfs-client.xml の編集
/usr/local/hawq/etc/hdfs-client.xml の以下のプロパティを編集します。
dfs.nameservices には上述の NameNode HA をした際のネームサービスを指定します。
次のプロパティについては、ネームサービスに合わせてプロパティ名自体も変更してください (phdcluster となっている箇所)。
- dfs.ha.namenodes.phdcluster
- dfs.namenode.rpc-address.phdcluster.nn1
- dfs.namenode.rpc-address.phdcluster.nn2
- dfs.namenode.http-address.phdcluster.nn1
- dfs.namenode.http-address.phdcluster.nn2
設定値に NameNode HA を構成しているホストと、HDP で利用するポートを指定します。
<property>
<name>dfs.nameservices</name>
<value>hawqcluster</value>
</property>
<property>
<name>dfs.ha.namenodes.hawqcluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hawqcluster.nn1</name>
<value>tst-hawq-m1.tst.hawq.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hawqcluster.nn2</name>
<value>tst-hawq-m2.tst.hawq.com:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hawqcluster.nn1</name>
<value>tst-hawq-m1.tst.hawq.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hawqcluster.nn2</name>
<value>tst-hawq-m2.tst.hawq.com:50070</value>
</property>
yarn-client.xml の編集
/usr/local/hawq/etc/yarn-client.xml の以下のプロパティを編集します。
プロパティ名の変更はなく、設定値に ResourceManager HA を構成するホストと、HDP で利用するポートを指定します。
<property>
<name>yarn.resourcemanager.ha</name>
<value>tst-hawq-m1.tst.hawq.com:8050,tst-hawq-m2.tst.hawq.com:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.ha</name>
<value>tst-hawq-m1.tst.hawq.com:8030,tst-hawq-m2.tst.hawq.com:8030</value>
</property>
hawq-site.xmlの編集
/usr/local/hawq/etc/hawq-site.xml の以下のプロパティを編集します。
hawq_dfs_url は hdfs-client.xml でも設定した NameNode HA のネームサービス名 + HAWQ 用に HDFS に作成した /hawq を指定します。
hawq_master_directory には上述の HAWQ マスター用のローカルディレクトリを、
hawq_segment_directory には上述の HAWQ セグメントサーバー用のローカルディレクトリを指定します。
hawq_master_temp_directory、hawq_segment_temp_directory はデフォルトが /tmp ですが、ディスク割り当てが大きいところが別にあればそのパスを指定したほうが良さそうです。
そして、リソース管理に YARN を使うように hawq_global_rm_type の設定値を none から yarn に変更します。
<property>
<name>hawq_master_address_host</name>
<value>tst-hawq-m1.tst.hawq.com</value>
<description>The host name of hawq master.</description>
</property>
<property>
<name>hawq_standby_address_host</name>
<value>tst-hawq-m2.tst.hawq.com</value>
<description>The host name of hawq standby master.</description>
</property>
<property>
<name>hawq_dfs_url</name>
<value>hawqcluster/hawq</value>
<description>URL for accessing HDFS.</description>
</property>
<property>
<name>hawq_master_directory</name>
<value>/var/hadoop/hdfs/namenode/hawq/master</value>
<description>The directory of hawq master.</description>
</property>
<property>
<name>hawq_segment_directory</name>
<value>/var/hadoop/hdfs/data/hawq/segment</value>
<description>The directory of hawq segment.</description>
</property>
<property>
<name>hawq_master_temp_directory</name>
<value>/var/tmp/</value>
<description>The temporary directory reserved for hawq master.</description>
</property>
<property>
<name>hawq_segment_temp_directory</name>
<value>/var/tmp</value>
<description>The temporary directory reserved for hawq segment.</description>
</property>
<property>
<name>hawq_global_rm_type</name>
<value>yarn</value>
<description>The resource manager type to start for allocating resource.
'none' means hawq resource manager exclusively uses whole
cluster; 'yarn' means hawq resource manager contacts YARN
resource manager to negotiate resource.
</description>
</property>
ResourceManager HA を行っている場合、hawq-site.xml の hawq_rm_yarn_address と hawq_rm_yarn_scheduler_address は無視されて、yarn-client.xml の ha 設定が利用されます。
詳細は Pivotal ドキュメントの「Configuring HAWQ in YARN Environments」を参照してください。
ハマったところ
hawq_dfs_url の設定値を、デフォルトで 8020 ポートが書かれていたことから
“hawqcluster:8020/hawq” と書いてしまっていたのに気が付かず、
この後で行う HAWQ の初期化が何度も何度も失敗してドツボにハマりました・・・
NameNode HA の場合、ポート番号の記述は不要です。意外とやりそうなミスなのでご注意を。
HAWQ の初期化
まず編集した設定ファイルを他の全ホストにコピーします。
cd /usr/local/hawq/etc/ hawq scp -h tst-hawq-m2 slaves hdfs-client.xml yarn-client.xml hawq-site.xml =:/usr/local/hawq/etc/ hawq scp -f /usr/local/hawq/etc/slaves slaves hdfs-client.xml yarn-client.xml hawq-site.xml =:/usr/local/hawq/etc/
ここまででようやく HAWQ 初期化と起動の準備が整いました。
HAWQ マスターノード(アクティブ)で以下を実施します。
hawq init cluster
hawq state cluster
yarn application -list | awk '/application_/ {printf ("%s\t%s\t%s\t%s\t%s\n", $1,$2,$3,$4,$5)}' |grep hawq
エラーが出ず、最後の yarn application コマンドで hawq が表示されれば OK です。
HAWQ を操作
これでようやく HAWQ クラスタが構築できました。本当に YARN を利用して SQL クエリが実施できるところを見るため、前回のブログ「GreenplumDB と Hive on tez でデータのロードとクエリを試してみました」と同じデータを準備して試しました(データロードの詳細は後編で)。
hawqdb というデータベースを作り、前回と同じ page_views テーブルを作成しています。
HAWQ には psql コマンドで接続して操作します。
psql -d postgres create database hawqdb; \c hawqdb;
テーブル作成で前回の GreenplumDB と今回の HAWQ で違うところは、ORIENTATION が COLUMN から PARQUET になっていることです。
CREATE TABLE page_views ( uuid varchar(20), document_id int, pv_timestamp bigint, platform smallint, geo_location varchar(20), traffic_source smallint ) WITH ( APPENDONLY=TRUE, ORIENTATION=PARQUET, COMPRESSTYPE=SNAPPY ) DISTRIBUTED BY (uuid) ;
データロード後、簡単な件数取得 SQL を投げてちゃんと件数が返ってくるところと、
select count(*) from page_views;
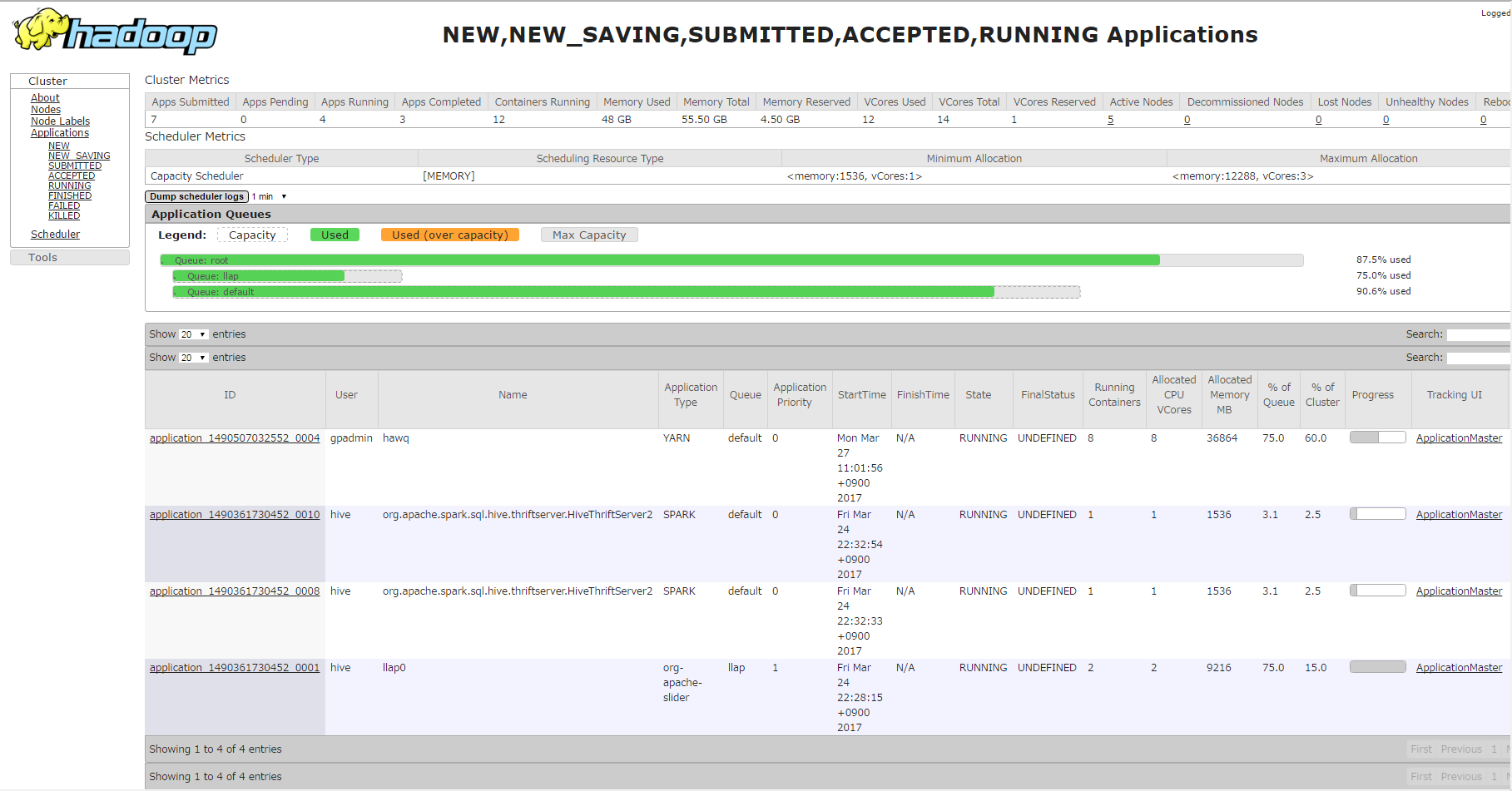
ResourceManager の WebUI を見て、以下の画像のように YARN の default キューを使用していることが確認できました。
前編おわり
構築の作業が多く、設定もたくさんあるので、ちょっと大変ですが、ちゃんと HDP 上で HAWQ が動かせました。
今後試そうと考えているのは、ビッグデータのロード、PXF のビルド&インストール、そして本題ともいうべき Hive や Spark との連携、比較検証です。
このあたりはまた後日、後編で。
最後に
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD