2021.07.08
pythonのBytesIOによる標準入出力の再構築とパフォーマンス検証
目次
TL;DR
- 標準入力はsys.stdin系が早い
- 標準出力はprintでいい
- pypyではBytesIOの方が早い
はじめに
Y.Cです。pythonって遅いですよね。インタプリタ言語だから処理が遅いのはそうなんですが、入出力も遅いんです。日本の競技プログラマの間では標準関数の input を sys.stdin.readline で置き換えるのが定番になっています。しかしあるときネットの荒波に揉まれている最中見つけてしまったんです、なんか凄そうな入出力を。
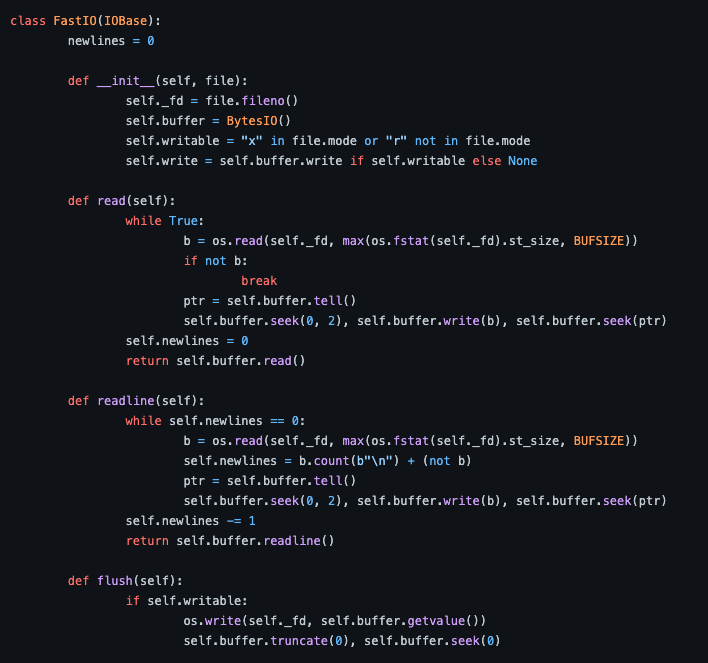
(https://gist.github.com/ShubhamKJha/f16f5eb7e6da41da5f4b95d004b55d6e等)
なんだこれ凄く早そうだな?バイト列として読み込んでるっぽい?多くの人が最も日常的に使うであろう標準入出力が、このコードで書き換えられてしまうかもしれない!それはまさしく、異世界からの転生者を憧れの眼差しで見る村の少年Aの気持ちでした。
さらにググってみると、BytesIOなるものを使った高速化がいくつかヒットします。
https://codeforces.com/blog/entry/83441
https://www.geeksforgeeks.org/fast-i-o-for-competitive-programming-in-python/
日本語記事では全く見聞きしたことがなかったのでかなり期待でいっぱいです。これらのコードを読み解いて簡易的に再実装し、通常の関数とパフォーマンスを比較してみたいと思います!
BytesIOとは
まずコア要素であるBytesIOとそのメソッドを紹介します。BytesIOは一言で言うとバイト列のストリームです。ストリームとか言われてもよくわかりませんが、ひとまずバイト列を格納するバッファと、バッファのどこを見ているかを表す位置をもっていることだけ把握すれば先に進めます。位置を自由にずらしてバッファのどこにバイト列を書き込むのか、どこから読み込むのかを指定できます。

BytesIOのメソッド
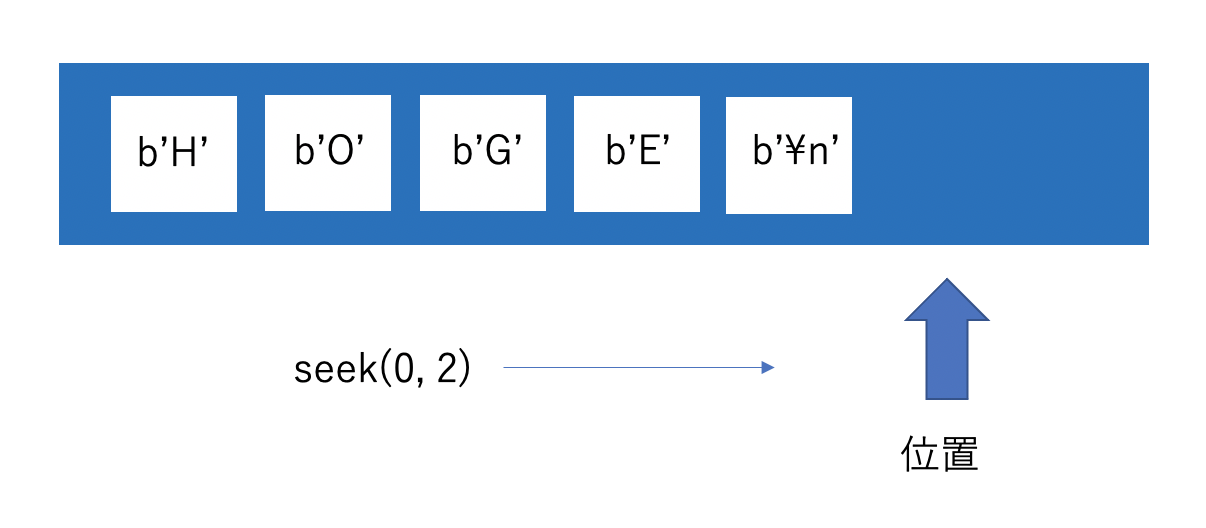
tell()
現在の位置がストリームの先頭から数えて何バイト目かを返します。
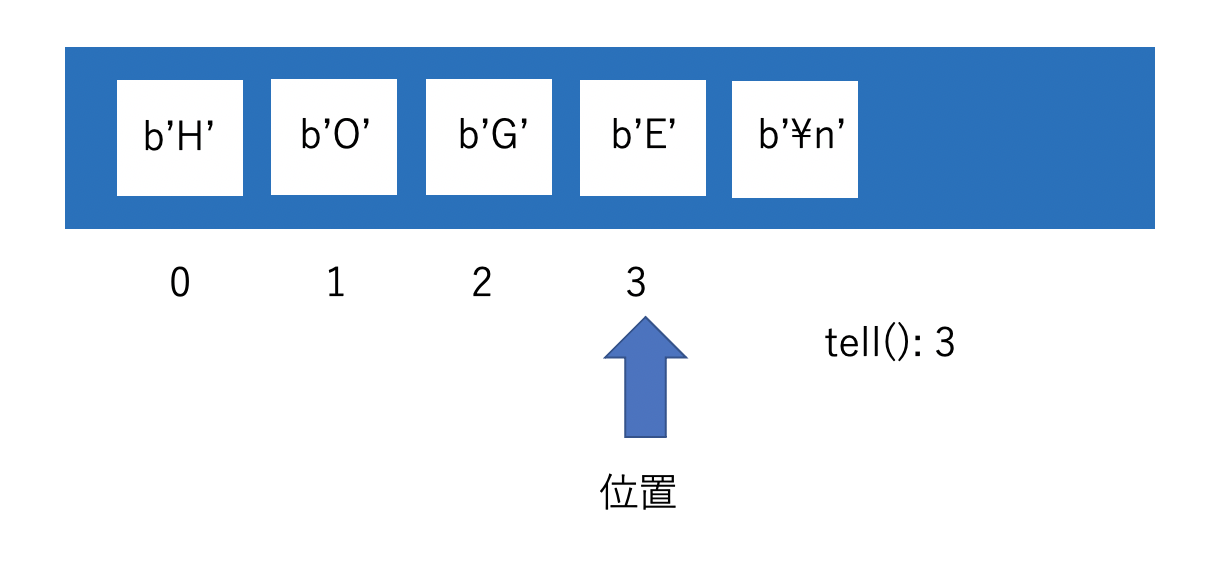
seek(offset)
ストリームの先頭から数えてoffsetバイト目に位置をずらします。0だと先頭です。
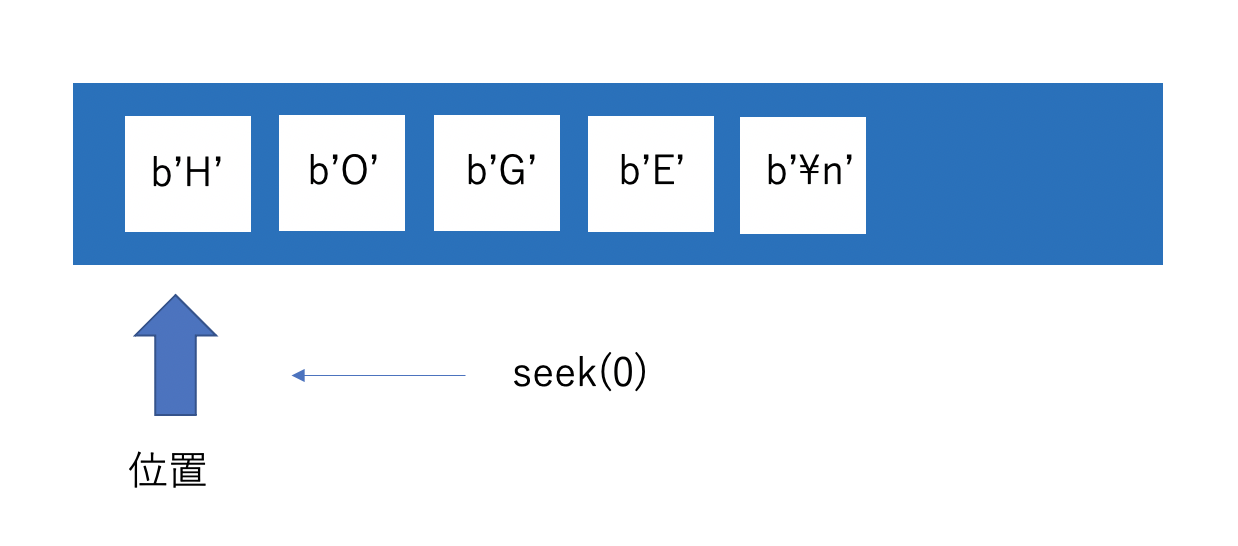
seek(0, 2)
seekの引数に0, 2を指定することで、ストリームの終わりに移動します。
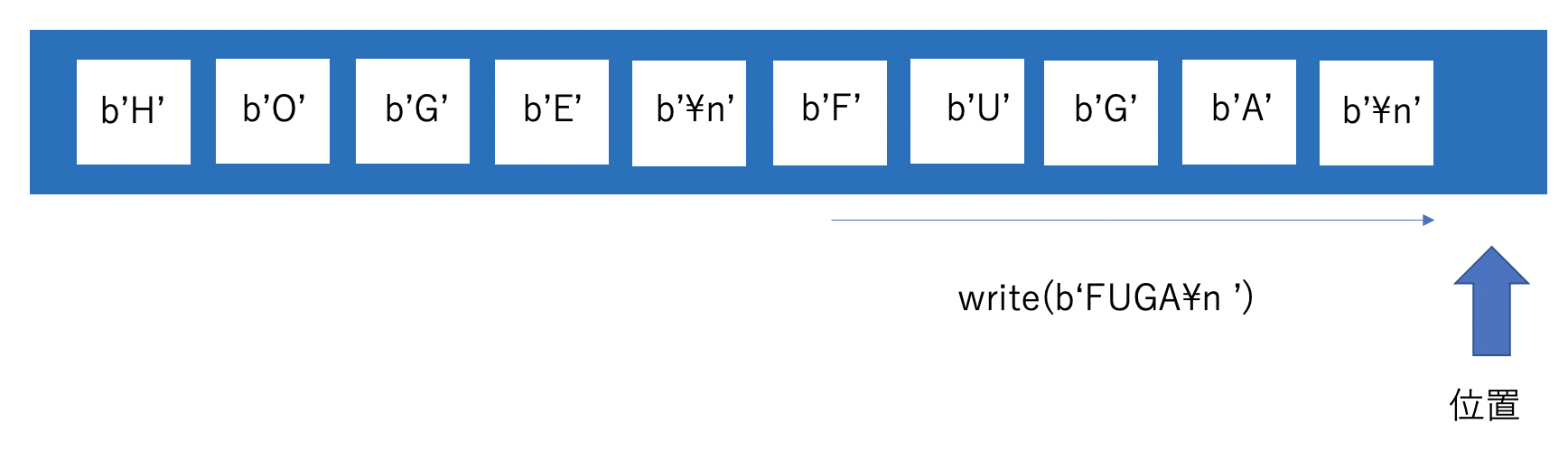
write(x)
現在の位置からバイト列xを書き込みます。書き込んだ分だけ位置も後ろにずれます。
read()
現在の位置から終わり(EOF)までのバイト列を読み取って返します。読み取った分だけ位置もずれます。

readline()
現在の位置から改行または終わり(EOF)までのバイト列を読み取って返します。読み取った分だけ位置もずれます。
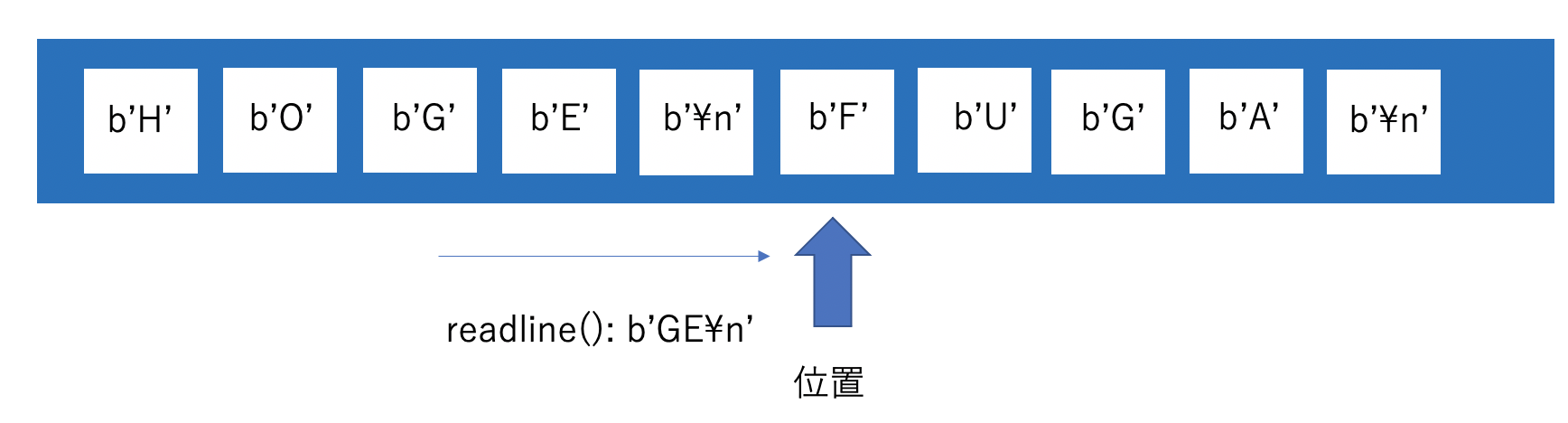
getvalue()
現在の位置に関係なく、バッファのすべてのバイト列を返します。
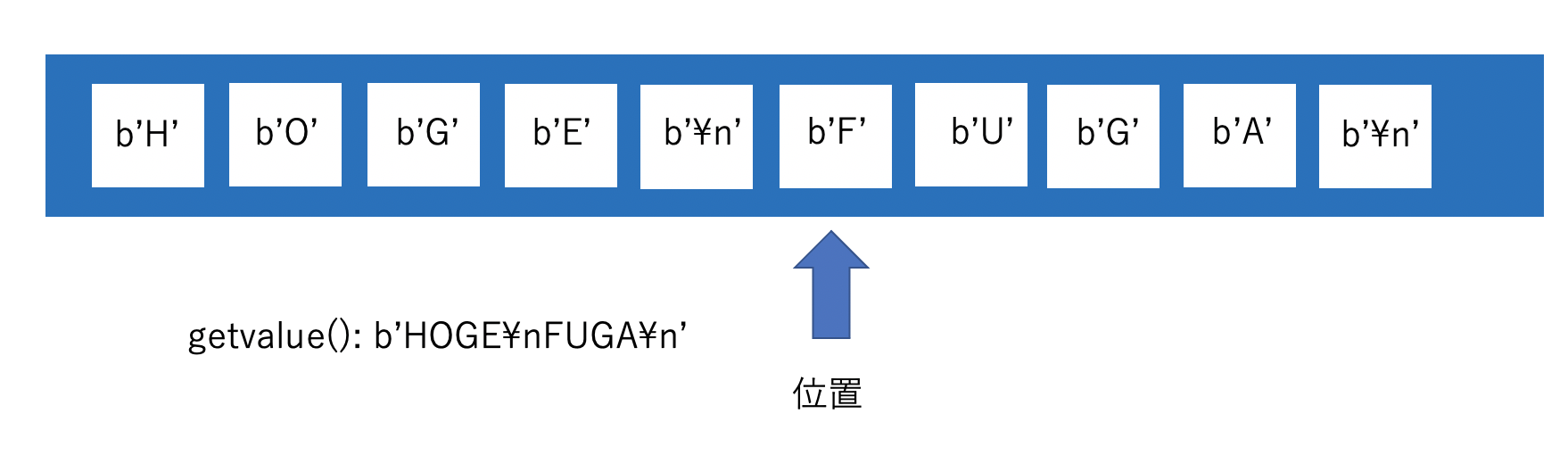
truncate(size)
バッファの長さをsizeで指定したバイト数に変更します。現在の長さより大きくする場合は0埋めです。位置は変わりません。
実装
ここから実際に動くコードを紹介していきます。コンセプトは”生の標準入出力”。os.read やos.write といった低レベルI/Oメソッドに対してバイト列のまま読み書きを行うことで高速化を図ります。
全行読み込み
まずはEOFまでの全行を読み込む関数readです。イメージとしては、生の標準入力から読み込んだバイト列をBytesIOオブジェクトであるbufにどんどん投入していき、最後にまとめて取り出す感じです。ここで重要なのは一度にどれくらいの量のバイト列を標準入力から読み込むかと言う点です。ここを大きくするほど取り出す回数を減らせます。今回は設定できる最大である2**63-1バイトにしています。
注意点ですが、bufはずっと単一のオブジェクトに追記しているので読み込めば読み込むほど肥大化します。常時稼働するプログラムやあまりにも巨大なデータを読み込む場合はそのままでは使用しないほうがよいです。
import io, os
# バイト列のストリーム
buf = io.BytesIO()
# 一度に読み取るバイト列の最大の長さ
BUFSIZE = 2**63-1
def read():
# 現在の位置を退避しておく
pointer = buf.tell()
while True:
# 生の標準入力(=0)から最大BUFSIZE分のバイト列を読み取る
byte_data = os.read(0, BUFSIZE)
# 読み取れなかったら終了
if not byte_data:
break
# 位置をbufの終わりにずらす
buf.seek(0, 2)
# 読み取ったバイト列を書き込む
buf.write(byte_data)
# 退避しておいた位置を復元する
buf.seek(pointer)
# 現在位置から終わりまでのバイト列を読み取り、通常の文字列にデコードして、末尾の空白文字を削除する
return buf.read().decode().rstrip()
一行読み込み
inputを置き換える関数です。先ほどのread関数に、複数行bufに溜まっている場合は全行返すまで生の標準入力から読み込みしない、返す際は一行ずつ返す、という処理を追加しています。
import io, os
# バイト列のストリーム
buf = io.BytesIO()
# 生の標準入力から取得してまだreturnしていない行数
num_line = 0
# 一度に読み取るバイト列の最大の長さ
BUFSIZE = 2**63-1
def input():
# グローバル変数を使う
global num_line
# 現在の位置を退避しておく
pointer = buf.tell()
# 現在1行も生の標準入力から読み取っていない場合
while num_line == 0:
# 生の標準入力(=0)から最大BUFSIZE分のバイト列を読み取る
byte_data = os.read(0, BUFSIZE)
# バイト列の行数を数える 空の場合も1行として数える
num_line = byte_data.count(b"\n") + (not byte_data)
# 位置をbufの終わりにずらす
buf.seek(0, 2)
# 読み取ったバイト列を書き込む
buf.write(byte_data)
# 退避しておいた位置を復元する
buf.seek(pointer)
# 1行返すので、デクリメントする
num_line -= 1
# 現在位置から改行までバイト列を読み取り、文字列にデコードして末尾の空白文字を削除する
return buf.readline().decode().rstrip()
書き込み
printを置き換える関数です。readの逆で、書き込みたい文字列をどんどんbufに追加しておき、最後に生の標準出力にまとめて流し込みます。ちなみに冒頭で貼ったgithubのコードのようにIOWrapperクラスなるものをきちんと継承していると適度なタイミングで流し込みが行われるようですが、今回は簡略化と高速化を狙って最後の一回のみにしています。
import io, os
# バイト列のストリーム
buf = io.BytesIO()
def print(*args):
# 最初の引数かどうか
at_start = True
# 複数の引数に対してforを回す
for x in args:
# 最初の引数でない場合、区切り文字をbufに書き込む
if not at_start:
buf.write(b' ')
# 引数を文字列型に変換しバイト列にエンコードしてbufに書き込む
buf.write(str(x).encode())
# 以降の引数は最初の引数でなくなる
at_start = False
# bufに改行を書き込む
buf.write(b'\n')
"""
print処理
"""
# 生の標準出力(=1)に、bufのすべての値を書き込む
os.write(1, buf.getvalue())
# bufの容量をサイズをゼロにして全削除する
buf.truncate(0)
# bufの位置を先頭に戻す
buf.seek(0)
パフォーマンス検証
それではBytesIOのお手並み拝見です。競技プログラミングサイトAtCoderで使用可能な CPython3.8.2 (ふつうのpython)と pypy3.6-7.3.0(使用できるモジュールは限定的だが動作は早い処理系) で比較を行いました。
条件
以下の文字列を100万行読み込んだり書き込んだりすることを100回行った平均時間(秒)を算出しています。データ量は68MBです。
'123,abc,def,ghi,jkl,mno,pqr,stu,vwx,yz,あいうえお,かきくけこ\n'
全行読み込み
標準ライブラリのsys.stdin.readと、組み込み関数のopen、今回作成したBytesIOのreadです。
| CPython3.8.2 | pypy3.6-7.3.0 | |
|
sys.stdin.read
|
0.19108555821
|
0.4013039637997281
|
|
open(0).read
|
0.20407318835000002
|
0.49515167964971624
|
| BytesIO版read |
0.30032334169999997
|
0.10400186788989231
|
CPythonの中ではsys.stdin.readが最速ですが、openもほぼ互角ですね。
pypyではBytesIO版readがぶっちぎりで早いです!!他がCPythonと比べて遅いのが気になりますが。
一行読み込み
組み込みのinput、大正義sys.stdin.readline、そして今回BytesIOで作成したinputです。
sys.stdin.readlineはそのままだと末尾に改行が含まれるので、以下の形で使用しています。
input = lambda: sys.stdin.readline().rstrip()
| CPython3.8.2 | pypy3.6-7.3.0 | |
| 組み込みinput |
2.03149133454
|
1.0996865939290728
|
| sys.stdin.readline |
0.47355414158000003
|
0.46799130230909214
|
| BytesIO版input |
0.9584284128599999
|
0.10368410232942551
|
CPythonではsys.stdin.readlineの早さは流石と言うほかありません。
しかし見てください、pypyのBytesIO版input、これ凄くないですか??sys.stdin.readlineと比べて4.6倍もの高速化に成功しています。BUFSIZEを巨大にした成果が如実に現れていますね!!!!!
書き込み
組み込みのprint、標準ライブラリのsys.stdout.write、今回作成したBytesIOのprintです。
sys.stdout.writeは改行が自動で入らないので、以下の形で使用しています。本当は複数引数対応させる方がフェアですが、まあハンデということで
print = lambda s: sys.stdout.write(str(s) + '\n')
| CPython3.8.2 | pypy3.6-7.3.0 | |
| 組み込みprint |
0.45517901238
|
0.5227527245495003
|
|
sys.stdout.write
|
0.53868568571
|
0.4219960145000368 |
| BytesIO版print | 0.66131080798 |
0.2480331877397839
|
CPythonではなんと組み込みのprintが最速。pypyだとまたしてもBytesIO版printの勝利で、sys.stdout.writeに2倍近い差をつけています。pypyはI/Oの最適化は甘いんですかね?
まとめると、
- CPythonの標準入力はsys.stdin系を使う、標準出力はprintでよい
- pypyの標準入出力はBytesIOを活用しよう
という結果になりました!
考察とお気持ち
- 日本語unicodeは1バイトずれるとデコードできなくなる。位置合わせ重要
- そもそも処理系によってこんなに結果が変わるのは大きな収穫
- pypy使いは一般的なpython論を鵜呑みにできない。比較するとpypyの苦手分野を炙りだせる。検証大事!
- pythonの古いバージョン・今後出るバージョンだと違う結果になるかもしれない(2系は実装が全然違う模様 参考)
- 今回試したのは100万行だったが、もっと少ないと余計なオーバーヘッドが少なそうな組み込み関数・標準ライブラリが有利になっていくかもしれない。逆に多いと今回の傾向はより顕著になっていく、かもしれない
- CPythonにおいてsys.stdin.readline はやはり偉大だった。内部実装も気になるが膨大なC言語のソースを把握するのは…
感想
BytesIOは通常のpythonでは高速化しなかったので大抵の人にとっては異世界からの来訪者にはなり得なかったわけですが、pypyを使う人にとっては目から鱗だったのではないでしょうか。実際に構築してみることで、組み込み関数でも裏側の処理でバッファリングを行ったりしているんだろうなというイメージができて面白かったです。あと単純に低レベルI/Oをいじるの楽しい。
次世代システム研究室では、 Web アプリケーション開発を行うアーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD