2017.10.04
QRNNでLSTM(深層学習を用いた時系列分析)をスピードアップ
[mathjax]
序文
お疲れ様です、次世代システム研究室のYTです。
普段からミッションとして金融データとにらめっこの毎日を過ごしています。
金融データの分析では、時間の経過に伴う変化に手がかりが含まれることが多いです。
深層学習で時系列を分析するときには、LSTM(Long Short Term Memory)をはじめとしたリカレントネットワークを使うと便利です。
深層学習は優れた学習能力がある一方、学習に結構時間がかかります。数時間などザラ、腰をすえた学習となると数日、数週間になることもあります。
この学習時間が短縮できれば、トライ&エラーを通してよりスピーディーに有益なルールを発見できるようになります。
資金力を頼りに強力なGPUマシンを揃えるのが基本ですが、もっと懐にやさしいアプローチがほしいところです。
そこで今回は、LSTMを高速化するアルゴリズム QRNN(Quasi-Recurrent-Neural-Network) を紹介したいと思います。
QRNNとは
QRNNは、擬似的にリカレントニューラルネットワークを実現するアルゴリズムです。
2016年11月にSales Force研究所のJames Bradburyらによって発表されました。
QRNNの最大の特徴は、CNN(畳み込みニューラルネットワーク)を活用して、計算処理の並列化を進め、LSTMよりも高速な学習を実現したことにあります。
なぜ、計算処理の並列化がQRNN最大の特徴となったのでしょうか?
LSTMと比較しながら見ていきましょう。
LSTMの課題
LSTMは、時系列データの学習を得意とするニューラルネットワーク構造です。
単語の連続で表現される文章や、波形の連続である音声のなど、連続性を持つデータを学習することができます。
長い時系列の推移を踏まえて学習・認識可能なことが、LSTMの大きな特徴です。
LSTMを構成する隠れ層というネットワークでは、過去から未来に向けて計算結果を順番に伝えていきます。
以下の図は、LSTMの隠れ層の仕組みを表したものです。
隠れ層の出力h(t) は、入力x(t)、一つ前の時間(t-1) の隠れ層の出力 h(t-1)、媒介変数C(t-1) を使って計算していることが分かります。

このように過去の状態の計算結果をバトンを渡すように引き継ぐことで、長い時系列パターンを学習できるわけです。
その一方、バトンを渡しで過去から順番に計算するため、並列計算ができません。
隠れ層の出力が過去の値に依存しているためです。過去の値を無視して、一斉にヨーイ・ドン!で計算するわけにはいきませんからね。
よって学習する時系列パターンが長くなるほど、並列計算ができない性質がボトルネックになります。
QRNNの特徴:CNNの並列計算を取り入れる
ボトルネックとなっているLSTMにおける計算処理の直列性を、QRNNはどのように解決したのでしょうか?
ポイントは計算の並列性です。
並列計算を特徴としている深層学習ネットワーク構造にCNN(畳み込みニューラルネットワーク)があります。
画像認識や映像認識でもはやお馴染みのネットワーク構造です。
QRNNは、CNNの並列計算性を部分的に取り入れ、時系列パターンの学習処理を高速化したのです。
LSTM、CNNの特徴とQRNNの特徴を簡易にまとめたものは下記です。
(原図は、QRNNの論文より引用)

QRNNの論文は、以下のURLからアクセスすることができます。
https://arxiv.org/pdf/1611.01576.pdf
QRNNにおける畳み込み処理
QRNNの内部でどのような計算処理が行われているのでしょうか?
論文を元に解説を試みたいと思います。
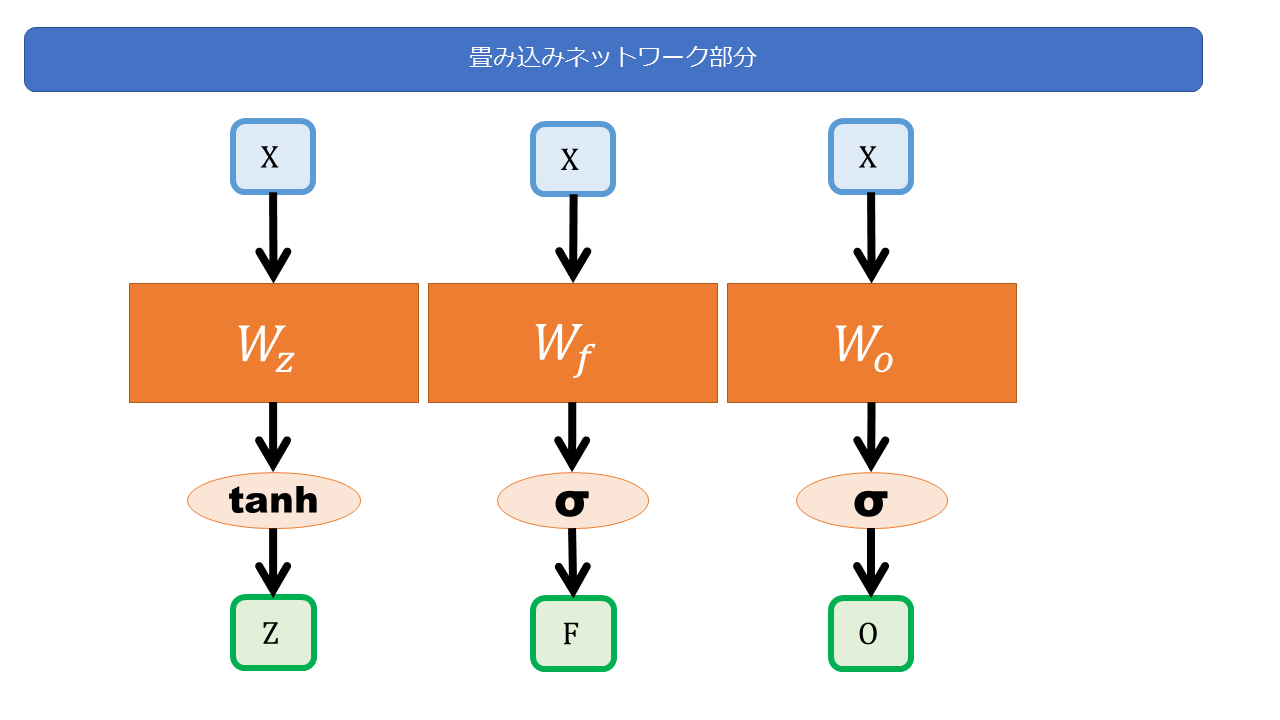
まず、畳み込み処理についてです。
入力 X が、n次元のベクトル x(1),x(2), .. X(T) で構成されているとします。
畳み込み処理で、入力X を、それぞれ m次元のベクトル z(1),z(2),…z(T)に変換します。
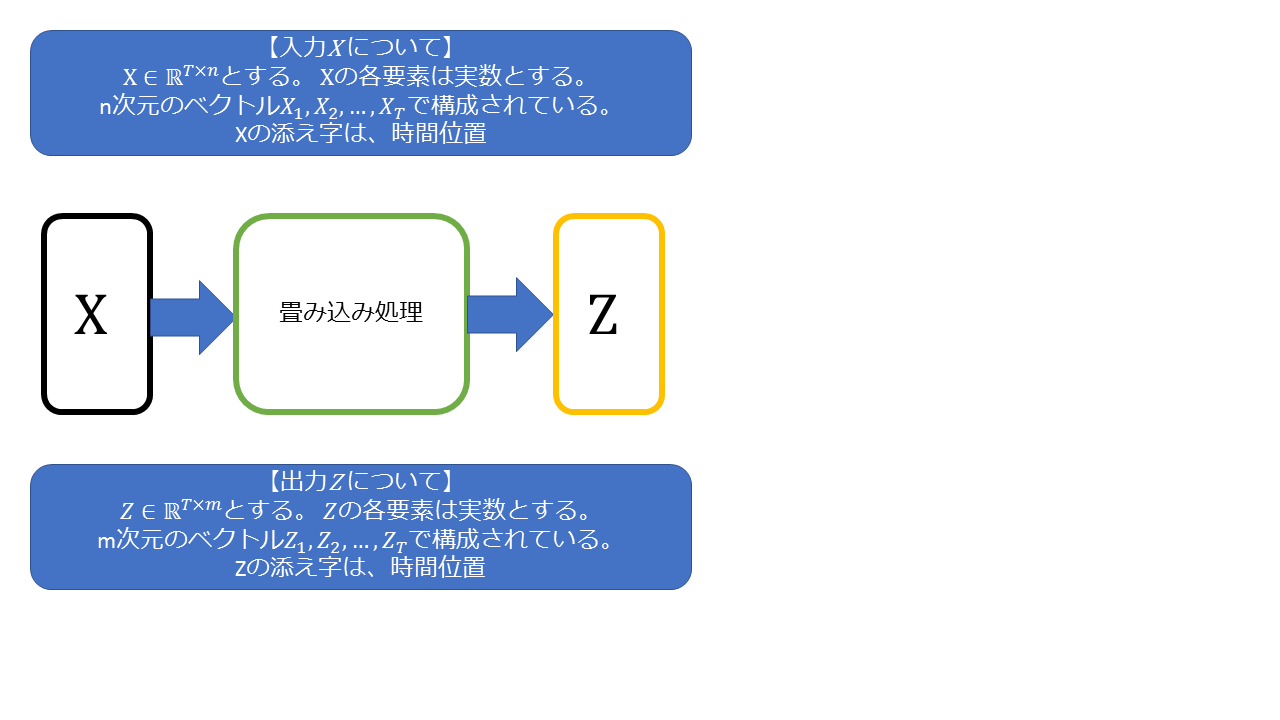
QRNNでは、m は状態空間のサイズ(=隠れ層で使用するz,f,o の次元数)を表します。大きいほど複雑な対象を学習できるようになります(=表現能力が上がる)。
この畳み込み処理を用いることで、QRNNは隠れ層へ入力する変数 Z(入力)、F(忘却率)、O(出力率) を以下のように計算します。
→ z は隠れ層への入力、f は忘却率、oは出力率を表しています。(LSTMのz,f,oと同じ対応関係です)
入力Xに対して、W_z,W_f,W_o の重み行列をかけます(=並列計算)。
そして、tanh,sigmoid の活性化関数を通してZ,F,O を求めます。
このZ,F,Oの計算がLSTMと大きく違っており、高速化のポイントになっています。過去の状態に依存しないので、同時並行で計算できるわけです。
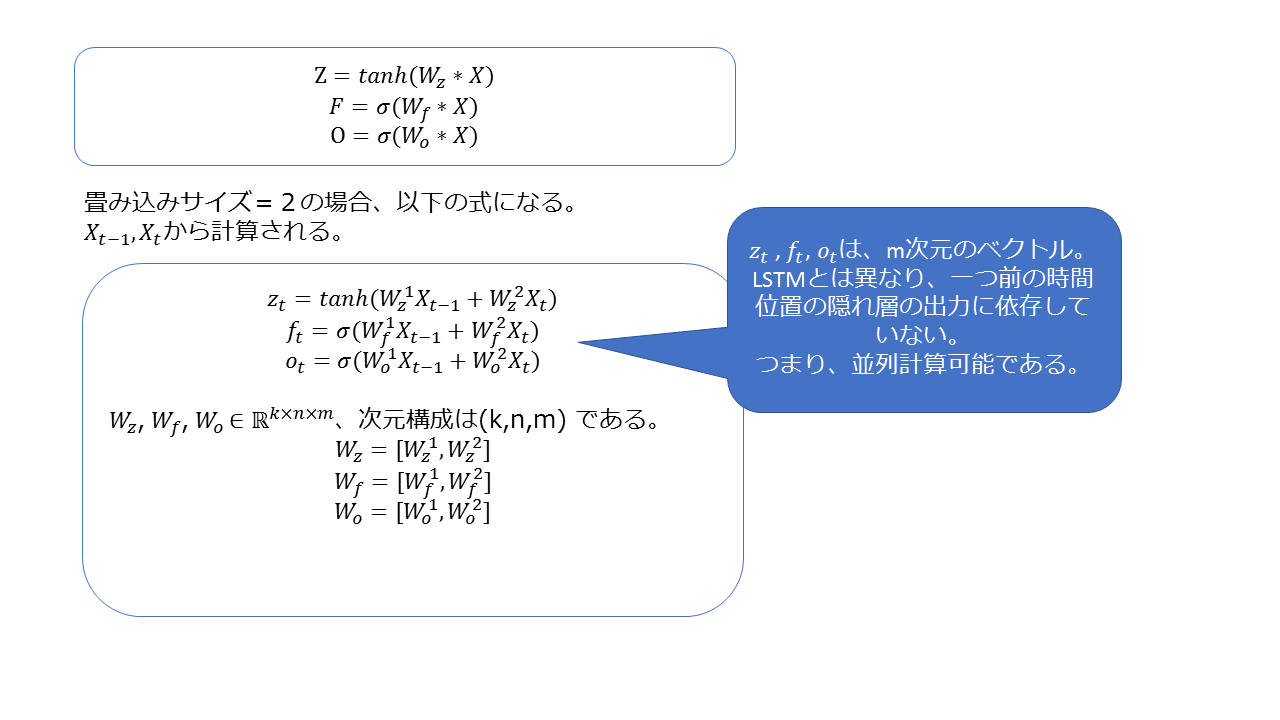
視覚的に構造を把握したところで、上の図に対応する方程式を見てみましょう。
隠れ層の畳み込み処理ですが、畳み込みサイズを指定します。この畳み込みサイズを増やすほど、より過去の範囲を考慮した計算をします。
たとえば畳み込みサイズが2であれば、過去の2ステップの状態を踏まえて、隠れ層の計算を行います。
QRNNの隠れ層の伝播の仕組み
隠れ層に入る Z,F,O が、畳み込み処理を使って並列計算できることが分かりました。
Z,F,Oが揃ったら、時系列順に隠れ層の計算を進めてゆくわけですが、QRNNは得られた Z,F,O をどのように使って、過去から未来へ状態を伝播しているのでしょうか?
QRNNの論文に基づいて図式化したものは次のようになります。
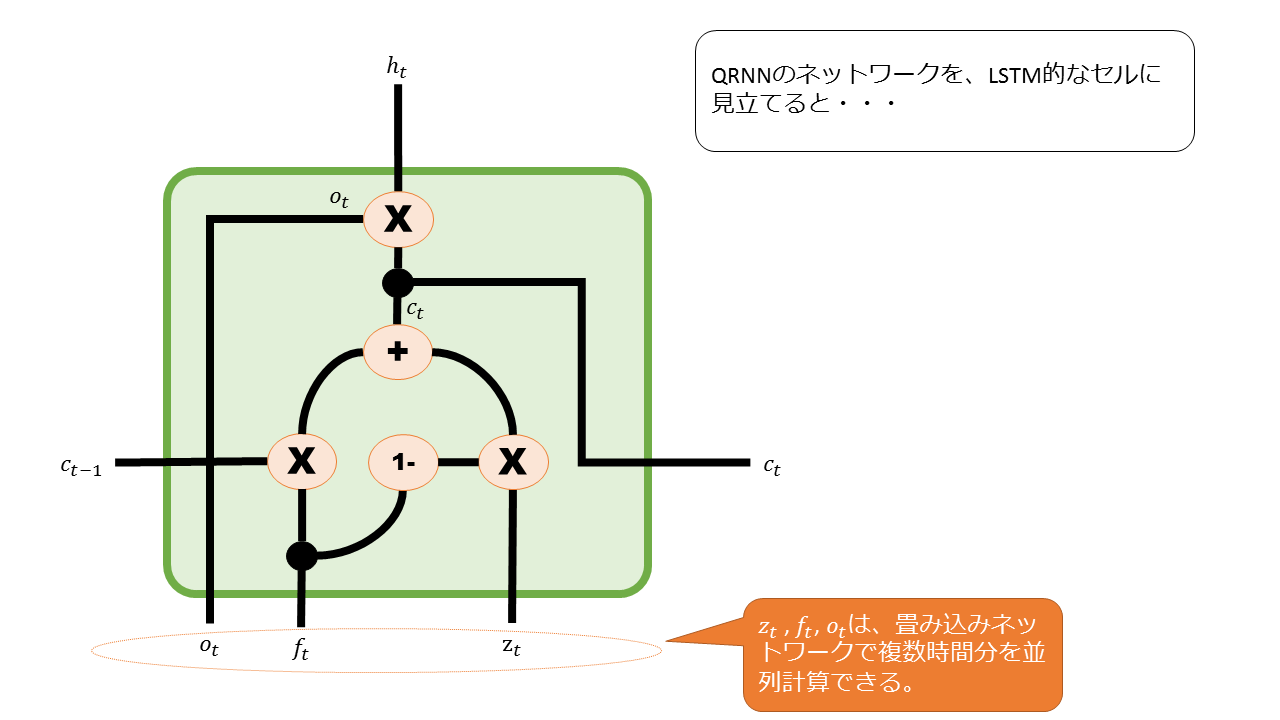
一つ前の時間(t-1)から、媒介変数c(t-1)を受け取っていることが分かります。
c(t-1)は、過去から未来へ受け渡される情報です。
QRNNの隠れ層のセルでは、このc(t-1)を用いて隠れ層の出力 h(t) を計算します。
一方、LSTMでは、過去の隠れ層の出力h(t-1)と、媒介変数 C(t-1) の二つを伝播させています。
すなわち、QRNNは伝播する変数の個数がLSTMの半分なので、計算が高速化されているのです。
さらに、隠れ層の出力の計算では、行列計算はなく、ベクトルの要素積(=アダマール積)だけで結果が出すことができます。
行列積より計算回数が少なくて済みます。
–> LSTMは重み行列と入力変数の行列積を用いてh(t)を計算している。
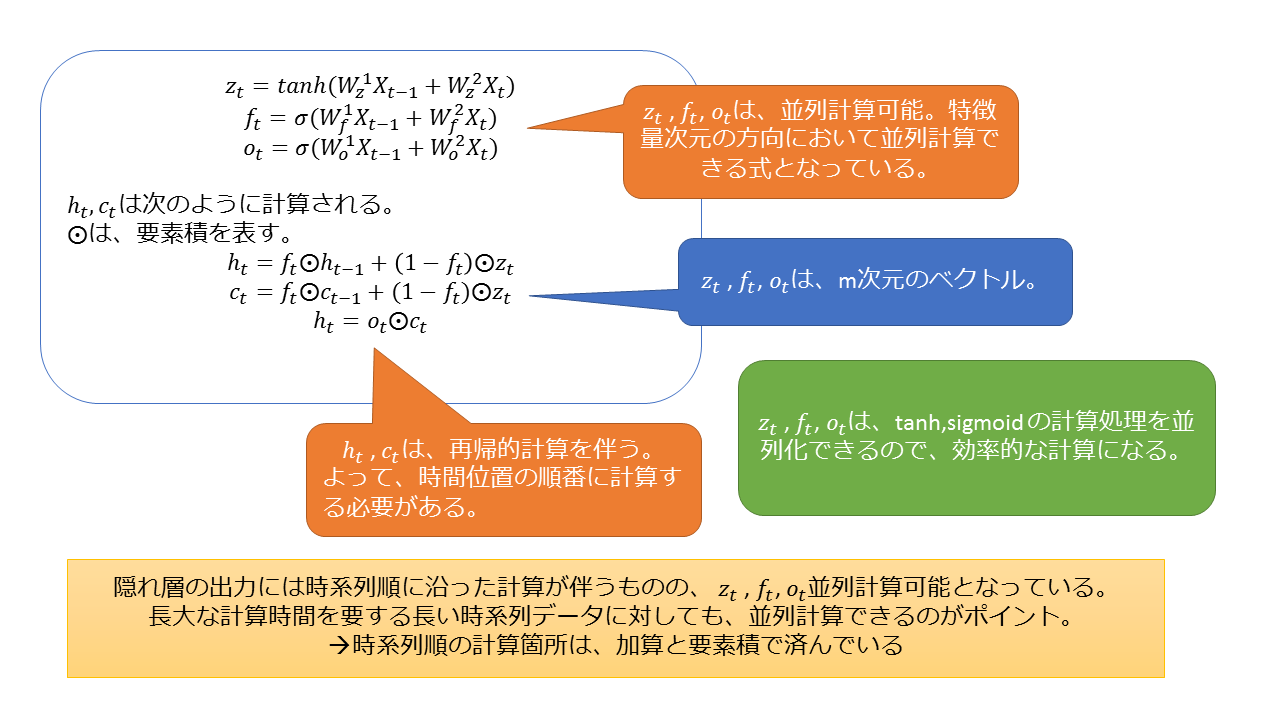
隠れ層の出力h(t)の計算方法の種類
前節の図で示している隠れ層の出力h(t)を求める式は、fo-pooling方式という計算式です。
f と o を使って、h(t) を計算しているので、fo-pooling と呼びます。
h(t) の計算方法には、他にも2種類あり、以下のようになっています。

おさらい
これまでの内容をまとめ、QRNNの仕組みを図式化すると次のようになります。
隠れ層の出力h(t)の計算方法は、fo-pooling法としています。
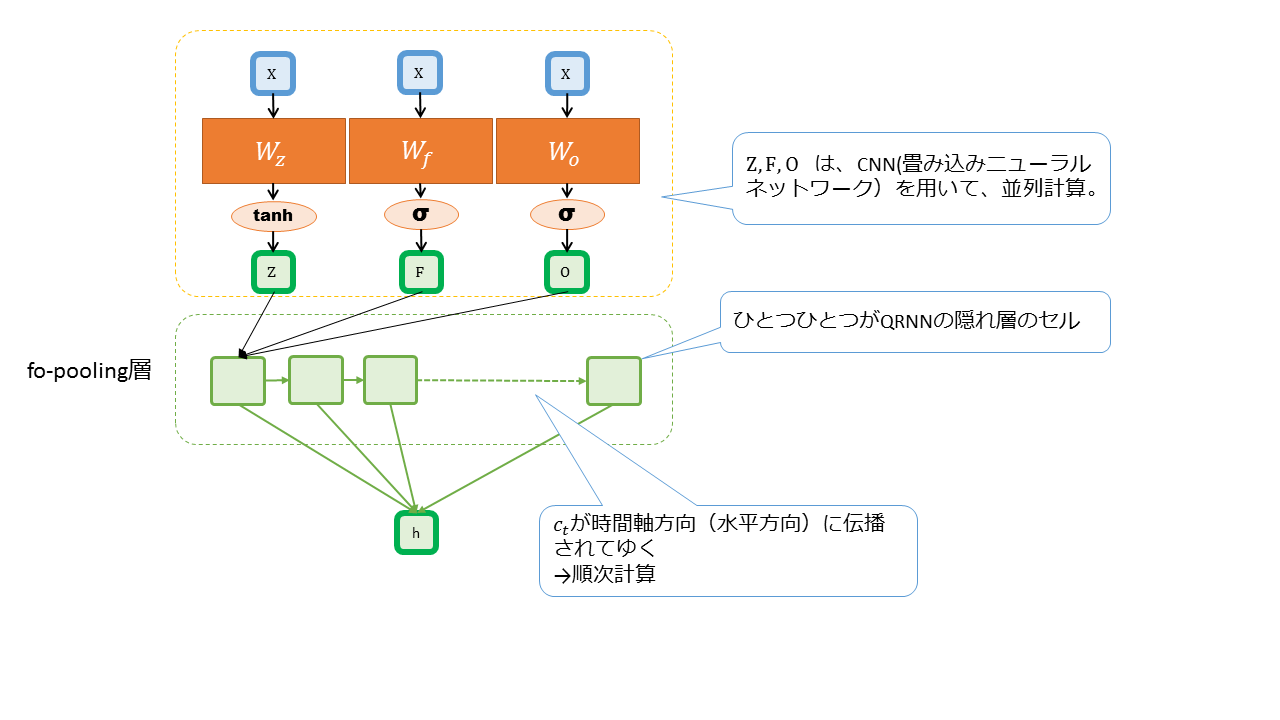
高速化のポイントは次のようになります。
1.隠れ層への入力Z,F,Oを並列計算できる。
2.時系列順に隠れ層の出力h(t)を求める際に、要素積だけで計算を済ませている。
手書き数字データセットを使って性能実験
QRNNの仕組みの解説が終わったので、実際に動かして性能を比較します。
使用するデータは、scikit-learn のデータセットに同梱されている手書き数字画像のサンプルです。機械学習の hello world! のようなもので、最も基本的なテストデータの一つとして有名です
手書き数字のデータ構造
scikit-learn の手書き数字データセットはは、8×8 のモノクロ画像と、手書き画像が表す数字(=答え)がセットになっているデータです。
そののデータの構造は簡潔に表すと次のようになります。
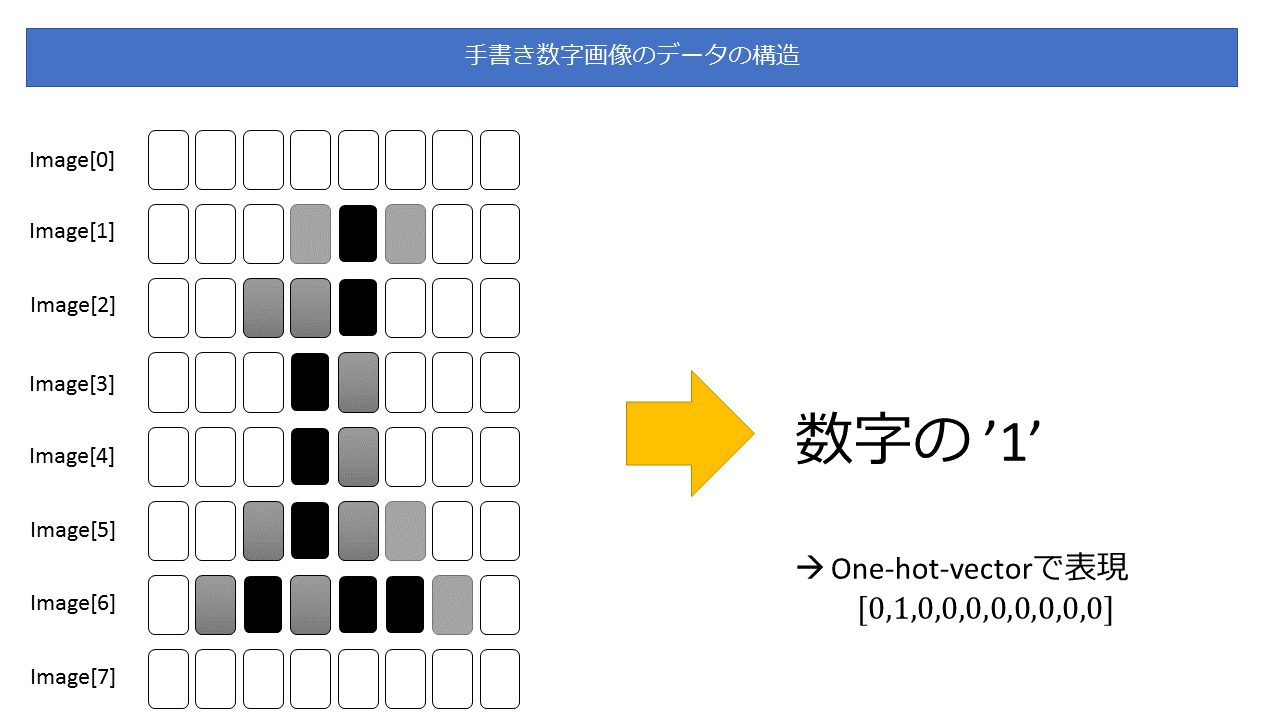
画像データを時系列データとして扱う
これを加工して、時系列データとして使うとしましょう。
具体的には、縦1ピクセルの画像を入力データデータとし、Y=0 から順番にモデルに投入していきます。
Y=0,1,2,3,4,… と順番に入力することで時系列データとみなすわけです。
図式化すると次のようになります。
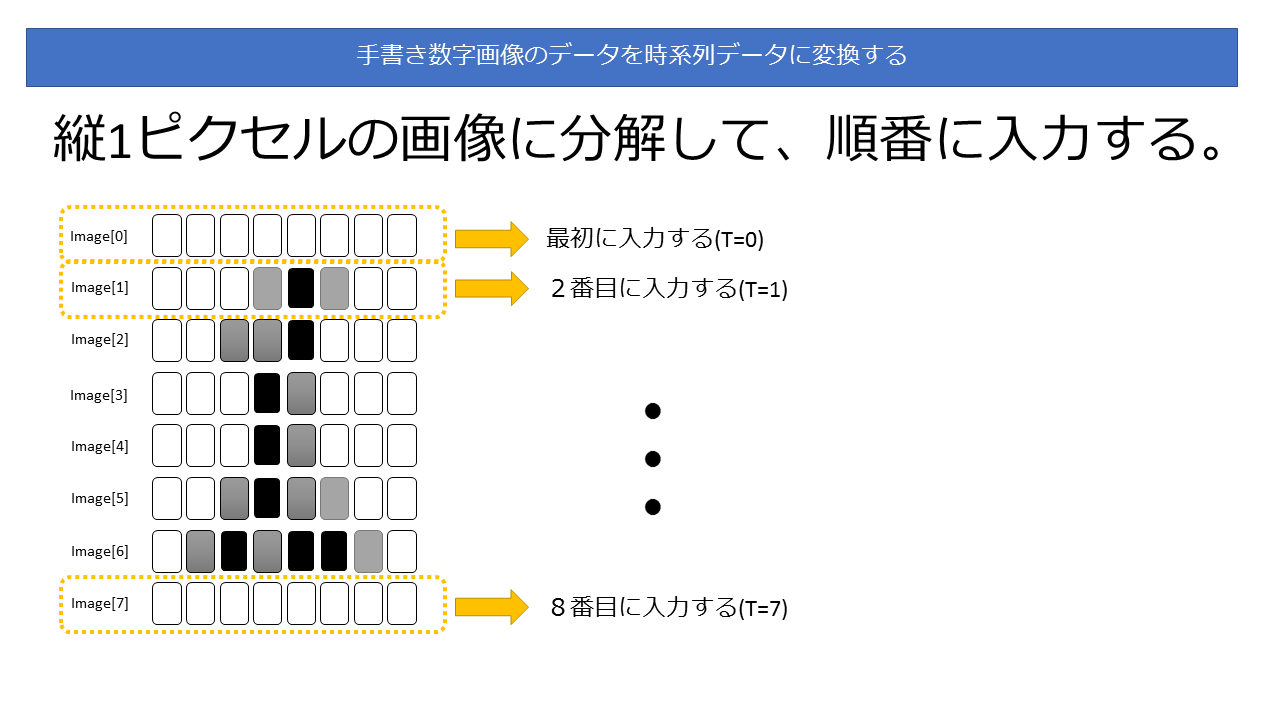
性能比較(GPU使用)
それでは、LSTMとQRNNの性能を比較したいと思います。
以下の環境で性能比較実験を行いました。
実験プログラムの動作環境
GPU : GeForce GTX 1070
Nvidia Driver Version : 375.66
OS : Ubuntsu Linux 16.04
Language : Python 3.5
Library : Tensorflow 1.0
内容
具体的な実験内容ですが、手書き数字画像を学習する工程を10000回、速度を比較します。
入力される画像のデータは、次のような構造になっています。
# 2次元配列で表された数字の0 [input][images] [[ 0. 0. 0.3125 0.8125 0.5625 0.0625 0. 0. ] [ 0. 0. 0.8125 0.9375 0.625 0.9375 0.3125 0. ] [ 0. 0.1875 0.9375 0.125 0. 0.6875 0.5 0. ] [ 0. 0.25 0.75 0. 0. 0.5 0.5 0. ] [ 0. 0.3125 0.5 0. 0. 0.5625 0.5 0. ] [ 0. 0.25 0.6875 0. 0.0625 0.75 0.4375 0. ] [ 0. 0.125 0.875 0.3125 0.625 0.75 0. 0. ] [ 0. 0. 0.375 0.8125 0.625 0. 0. 0. ]] # 数字の0 であることを one-hot-vector 形式で表す [input][target] [1 0 0 0 0 0 0 0 0 0]
結果
QRNN の方がLSTMの約2倍の速度で学習処理を終えました。
実験プログラムの出力から抜粋して紹介します。
(1) LSTM : 所要時間 約35秒
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1070, pci bus id: 0000:01:00.0) Iter 0: loss=2.486823081970215, accuracy=0.0625 Iter 100: loss=0.4927566647529602, accuracy=0.9375 Iter 200: loss=0.43519002199172974, accuracy=0.875 Iter 300: loss=0.21895098686218262, accuracy=0.9375 ・・・中略・・・ Iter 9600: loss=4.604360583471134e-06, accuracy=1.0 Iter 9700: loss=2.2186375645105727e-05, accuracy=1.0 Iter 9800: loss=2.794499960145913e-05, accuracy=1.0 Iter 9900: loss=2.2611315216636285e-05, accuracy=1.0 Testset Accuracy=1.0 takes 34.65536189079285 seconds.
(2) QRNN : 約17秒
Tensor("QRNN/Forward/split:0", shape=(8, 16, 128), dtype=float32)
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1070, pci bus id: 0000:01:00.0)
Iter 0: loss=2.5450267791748047, accuracy=0.0625
Iter 100: loss=0.5936621427536011, accuracy=0.75
Iter 200: loss=0.1960119754076004, accuracy=1.0
Iter 300: loss=0.19385947287082672, accuracy=0.9375
・・・中略・・・
Iter 9600: loss=0.0009646115358918905, accuracy=1.0
Iter 9700: loss=0.0004399011086206883, accuracy=1.0
Iter 9800: loss=0.0009853598894551396, accuracy=1.0
Iter 9900: loss=4.269053079042351e-06, accuracy=1.0
Testset Accuracy=1.0
takes 17.004825115203857 seconds.
まとめ
今回は、時系列パターンの学習においてLSTMより高速で処理をするQRNNというアルゴリズムを紹介しました。
論文内容を追跡し、どのような工夫をして処理の高速化に成功しているのか解説しました。
そして最後に比較実験結果からサマリを抜粋して紹介しました。
本当にLSTMより高速で、精度も同等でした。
並列処理は偉大でした。
【重要】最後に
次世代システム研究室では、機械学習や統計処理に関心を持つ開発者、アーキテクト、データサイエンティストを求めています。
自由闊達にのびのびと働きながら学べる環境が、コーヒー片手にアカデミックとビジネスの融合したディスカッションをしながら、知的好奇心を満たすことができる環境があなたを待っています。
次世代システム研究室にご興味を持たれたらすぐに 募集職種一覧 からご応募してください。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD