2020.04.03
Reformer : 小説を一冊丸ごと読み込める Transformer を改良した自然言語処理モデル
導入
こんにちは、次世代システム研究室のT.I.です。
さて、前回、最近の自然言語処理の潮流としてTransformer、そしてBERTについて紹介しました。AttentionというNeural Networkの構造に基づいた自然言語処理モデルの進化は止まることがなく、先日にGoogleからReformer という新たなモデルが発表されました。
このReformerはTransformerよりも効率的にメモリーを使用し、従来では不可能であった長い文章、例えば小説一冊を一度に読み込むことすら可能となりました。100万wordをたったの 16GB のメモリーで処理できるというので驚きです。今回は、このReformerで何が新しいのかについて解説をしたいと思います。
TransformerとAttention
前回のBlogでも解説しましたが、2017年に発表された Transformer という自然言語処理モデルは、Attention というNeural Networkの構造を採用し、非常に高い性能を発揮しました。それ以来というもの、Transformerを応用したBERT, RoBERTa, ALBERT, GPT-2、T5など様々なモデルが提唱され次々に言語処理の各種ベンチマークの記録を更新し続けています。
Attention
Attentionについては前回や他のブログで紹介されてますので、簡単に触れるのみにします。Attentionでは、Query (Q), Key (K), Value (V)を入力し、以下の量を出力します(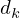 はQ,Kの深さ)。
はQ,Kの深さ)。
%0A%3D%20%5Cmathrm%7Bsoftmax%7D%5Cleft(%5Cfrac%7BQK%5ET%7D%7B%5Csqrt%7Bd_k%7D%7D%5Cright)V%0A%5Cend%7Balign*%7D&f=c&r=150&m=p&b=f&k=f)
これはquery(入力)とkey(K)との類似度の重み(Attention weight)をvalue(V)に掛け合わせて取り出す操作に対応します。
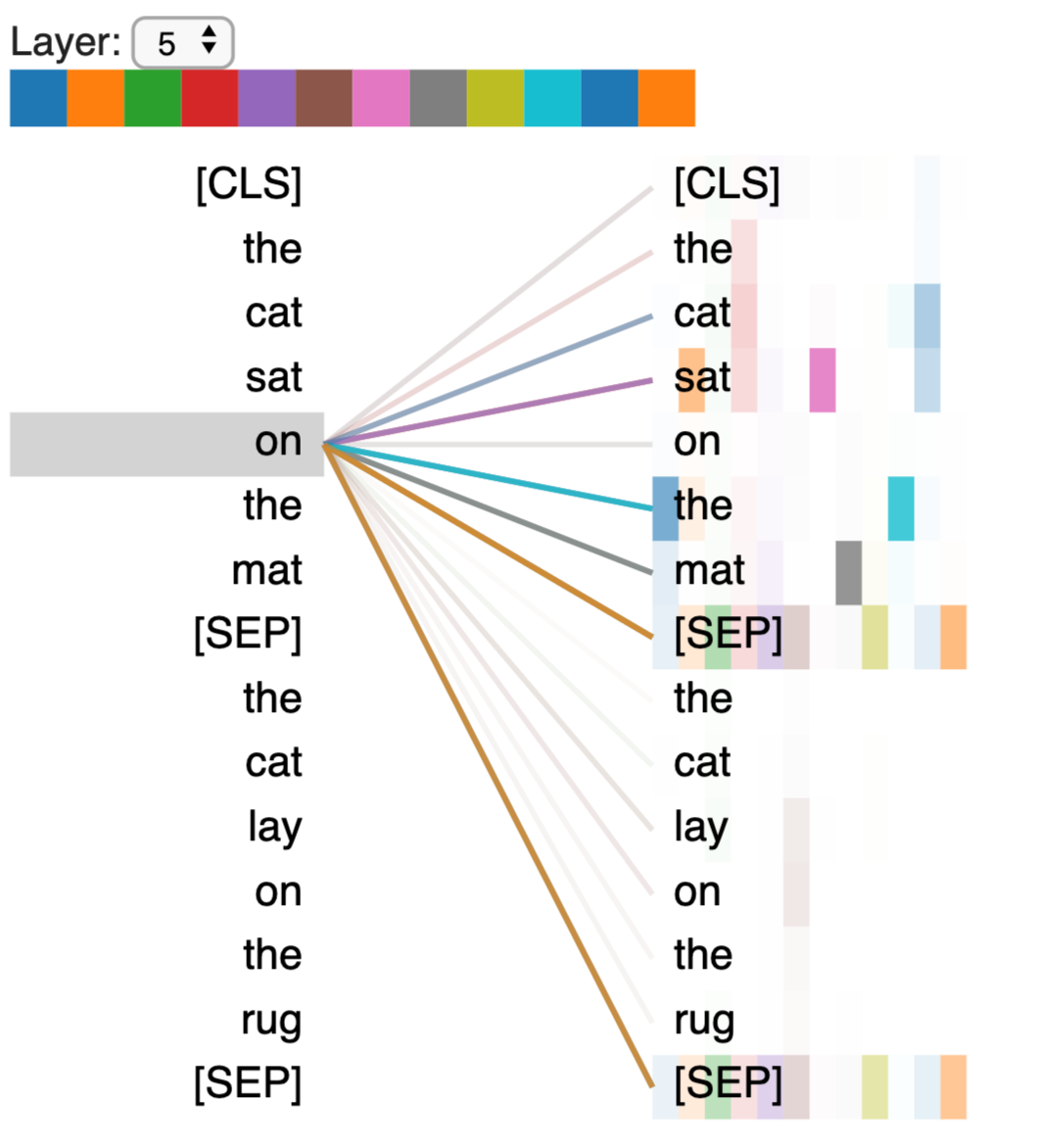
BERT base model(12層)のAttention layer (5層目)の可視化例 (https://github.com/jessevig/bertviz)
上図はこのAttentionの強度を可視化した結果です。Attention layer では、このように単語間の関係を抽出・学習します。このAttention layerとFeed Forward layerを組み合わせたものがTransformerであります。
Transformer の概略図(Transformerの発表論文より引用)
上図は Transformer の概略です。Attentionを複数束ねた Multi-Head Attention layer + Feed Forward layer が基本構成要素で、それを更に幾重にも重ねます。また、左側のブロックはEncoder、右側のブロックはDecoderと呼ばれます。例えば、言語翻訳のタスクではEncoderに元の文章、Decoderに翻訳後の文章を入力して、モデルのパラメーターを調整することで学習します。
Transformerの発表後、Attention layer を応用して、様々なモデルが作られていました。例えば、BERTではTransformer-Encoderを最大24層、GPT-2ではTransformer-Decoderを最大48層など重ねた巨大なモデルで、自然言語処理の各種タスクで高い性能を発揮しました。しかし、性能の反面、数億〜十数億ものパラメーターが必要となり計算コストはどんどん増えていきます。
そこで、層を単純に増やして性能を向上させる方向とは別にモデルをより効率化するための研究も盛んに進められています。Transformer を改良した ALBERTでは、Attention layer のメモリーを減らすため、単語の分散表現をより小さい層に更に埋め込み圧縮、またパラメーターを共有するなどし効率化を図っています。また、同様の観点で、DistilBERTでは複雑なモデルを簡単なモデルで近似するというknowledge distillationを採用しています。
Reformer
さて、上記で紹介したように、Transformer layer を重ねることは、モデルの性能を高めますが、メモリーの枯渇や学習効率の悪化などの問題があります。また、Attention layer を伸ばして入力を長くすることにも限界があります。それらの問題を解決するために、Reformer ではLocal-Sensitive-HashingとReversible Residual layerという2つのアイデアを採用し、少ないメモリで長い入力を処理することを可能にしました。
Local-Sensitive-Hashing (LSH)
まず、Attentionの改良を考えます。
この softmax 関数の引数![]() は[batch size, length, length]の形状を持ちます。そのために、長い入力を受け取るには膨大なメモリーが必要です。そもそも、softmax 関数は query に近い key の要素を抽出することが目的であるため、重なりが殆ど無い要素間の計算は無駄になっています。Reformerではこの計算を効率化するために、長い入力をクラス分けすることでAttentionへの入力を圧縮します。
は[batch size, length, length]の形状を持ちます。そのために、長い入力を受け取るには膨大なメモリーが必要です。そもそも、softmax 関数は query に近い key の要素を抽出することが目的であるため、重なりが殆ど無い要素間の計算は無駄になっています。Reformerではこの計算を効率化するために、長い入力をクラス分けすることでAttentionへの入力を圧縮します。
Reformerでは、類似した要素には同じhash値を与える Local-Sensitive-Hashing (LSH) を用いて入力を分類します。LSH には様々なアルゴリズムがありますが、ReformerではRandom projection を使用します。
Random projection について簡単な例で説明すると以下のような操作となります。まず、2次元面に散らばった点をランダムな角度で原点を中心に回転させます。そして、その点がどの区画に移動するかを調べます。近い点同士は同じ色になる確率が高くなり、遠い点は異なる色に分かれます。以下の例では(x, y, z, w) の4つの点は(x, y), (z), (w) と3つのグループに分類できそうです。
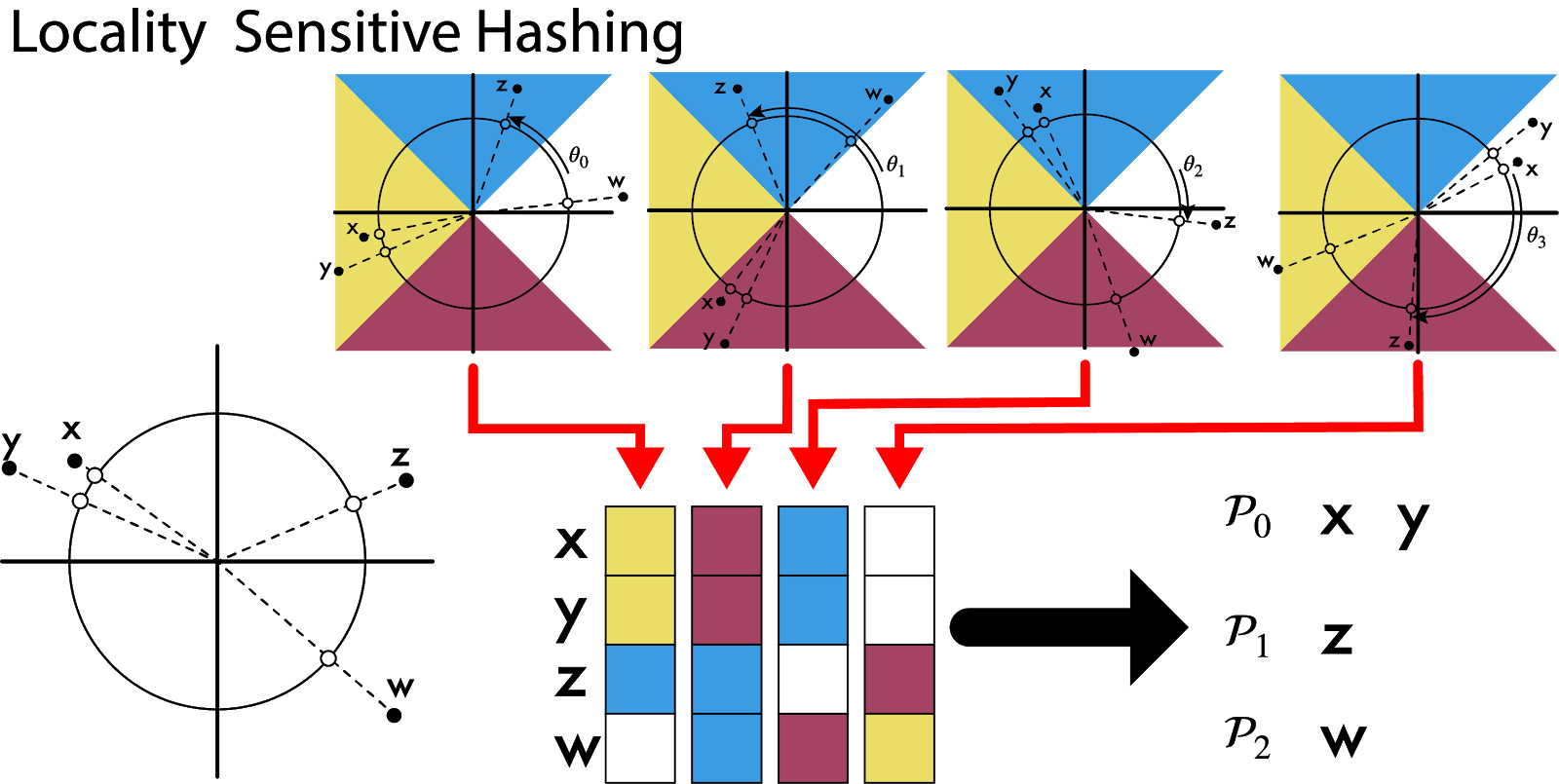
Random projection による Locality Sensitive Hashing の概略
具体的にReformer が、LSHを用いて入力を処理している概略図が以下になります。長い入力 sequence を LSH によりクラス分けします。そのLSH bucket 毎に入力をソートし、一定長の chunk にデータを振り分けます。この chunk 毎(と1つ前のchunkの要素)に対して、Attention の計算を行います。これらの工夫により、計算コストは入力長さ(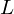 )に対して、
)に対して、%20%5Crightarrow%20%5Cmathcal%7BO%7D(L%5Clog%20L)%0A%5Cend%7Balign*%7D&f=c&r=150&m=p&b=f&k=f) と飛躍的に削減されます。
と飛躍的に削減されます。
Reformerの入力データの前処理(図は論文より引用)
Reversible Residual layers
Reformerで、もう一つ重要なアイデアが、Reversible Residual layersです。これにより Attention layer の学習に必要なメモリーを大幅に削減できます。
上で紹介したTransformerの模式図を見ると、各々の layer の出力結果に、元の入力が加えられていること
%0A%5Cend%7Balign*%7D&f=c&r=150&m=p&b=f&k=f)
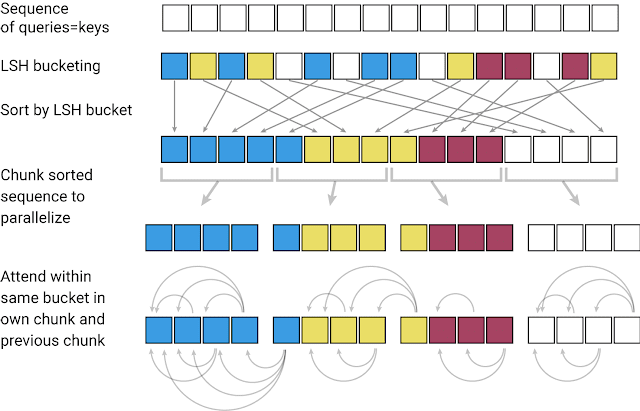
が判ります。これは、画像認識モデルの改善のため ResNet で利用された構造です。Deep Neural Network では層を深くすると、深い層まで入力の情報が伝わらないという問題があります。この情報消失を回避するために ResNet は入力のデータをそのまま出力層に加えます。これにより、層を深くしても効率のよい学習を重ねることができます。
ResNet と RevNet の構造の比較
この ResNet 構造の改良案が、Reversible residual network です。これは、入力・出力を2系統に分割し、2つの層(F, G)に交互に入力します。
%2C%20%5Cquad%20z_2%20%3D%20x_2%20%2B%20G(z_1)%0A%5Cend%7Balign*%7D&f=c&r=150&m=p&b=f&k=f)
このネットワークの特徴は、下流の結果(z)から上流(x)へと可逆に計算できる点にあります。
%2C%20%5Cquad%20x_1%20%3D%20z_1%20-%20F(x_2)%0A%5Cend%7Balign*%7D&f=c&r=150&m=p&b=f&k=f)
これだけでは、モデルを複雑化しただけに思われるかもしれませんが、この構造は学習の際に大きな利点となります。モデルの学習では出力結果をネットワークの下流から上流へと順々に逆伝搬を計算します。通常、その計算には途中の状態を保存する必要があります。しかし、RevNet の場合、可逆ですので、概略図のように最後の出力結果さえあれば、下流から上流へと再計算できます。そのため、途中の状態を保存する必要がなく、メモリーを節約できます。
そして、RevNet の考え方をTransformerに応用したものが、Reformerとなります。Transformerの基本構造がAttention + FeedForward の繰り返しですから、それぞれのゲートを以下のように分割して、交互に作用させます。
%20%5C%5C%0AY_2%20%26%3D%20X_2%20%2B%20%5Cmathrm%7BFeedForward%7D(Y_1)%0A%5Cend%7Balign*%7D&f=c&r=150&m=p&b=f&k=f)
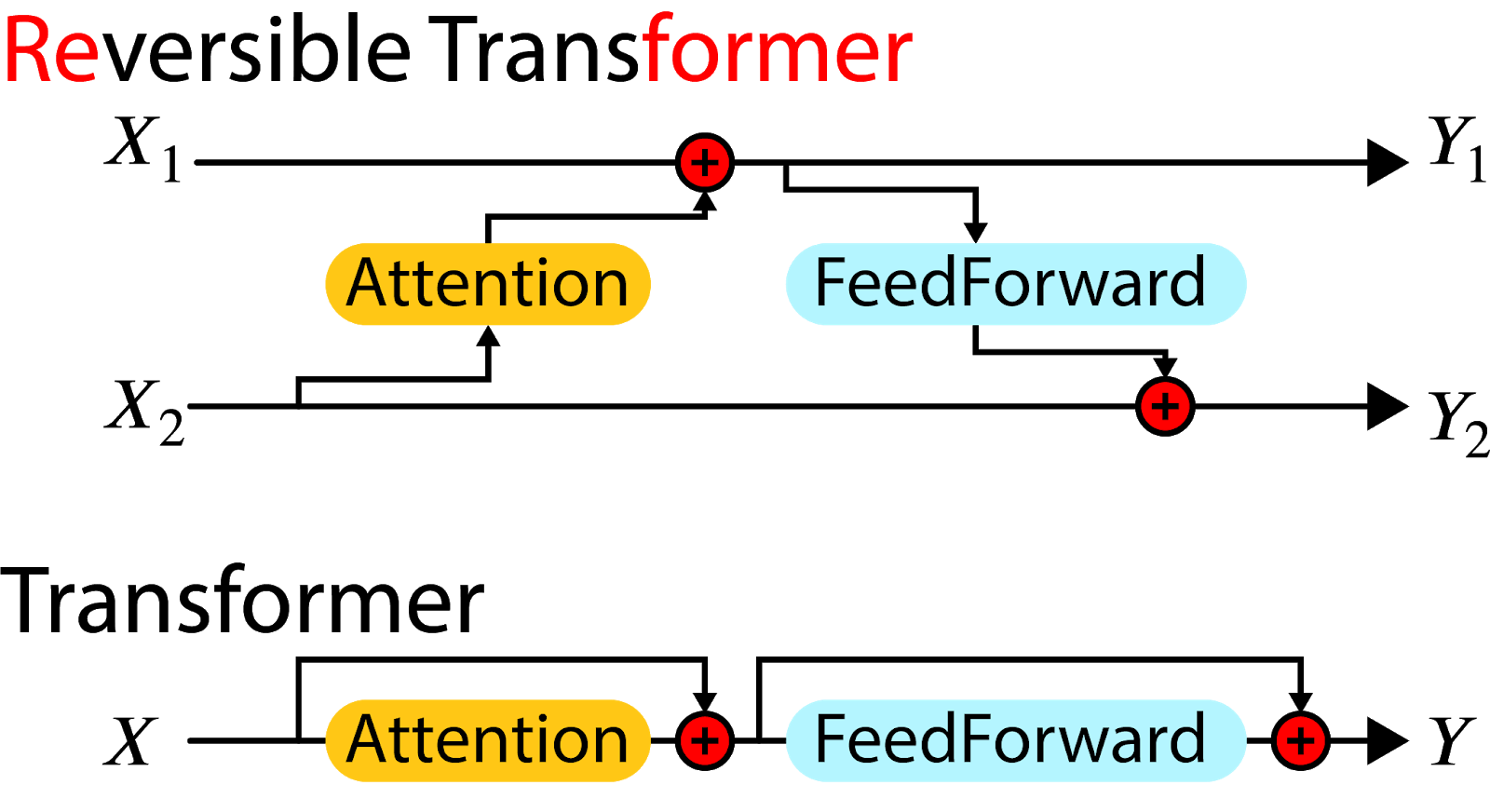
Reversible Transformer と Transformer の基本構造の比較
Transformerを多層化するとそれだけの途中の状態を保存する必用がありますが、Reformerでしたら多層化してもそれぞれの層で状態を再計算できるため、メモリに保持する必用がなく、層の数だけメモリを削減できます。
Reformerを動かしてみる
さて、この Reformer ですが、論文での実装が既に公開されており、Reformerによる”罪と罰”の全文約50万トークン(英文)による文章生成や imagenet64 の画像生成を簡単に動かすことができます。せっかくなので日本語の文章を読み込ませて動かしてみました。
まずは、青空文庫で公開されている少し長めの小説をダウンロードしてデータを加工しておきます。
import re
import urllib
import zipfile
url = 'https://www.aozora.gr.jp/cards/000096/files/2093_ruby_28087.zip'
zip_file = re.split(r'/', url)[-1]
urllib.request.urlretrieve(url, zip_file)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall('.')
with open('dogura_magura.txt', 'rb') as f:
full_text = ''
for i, f in enumerate(f.readlines()):
text = f.decode('Shift_JIS')
text = re.split(r'\r', text)[0]
text = re.split(r'底本', text)[0]
text = text.replace('|', '')
text = re.sub(r'《.+?》', '', text)
text = re.sub(r'[#.+?]', '' , text)
full_text += text
full_text = full_text.replace('\u3000', '')
text_length = len(full_text)
sample_text = full_text[317:len(full_text)-391] # remove header & footer
print('length of sample text : {:,}'.format(len(sample_text))) # 422,261
合計で約42万語なので、それなりな分量ですね、文庫本2冊程度といったところでしょうか。Reformerに入力するためには、日本語の文章を分割し、トークン化し、文章長を調整する必要がありますが、今回は簡単のために前回利用したBERTに含まれていたmoduleを再利用します。
!pip install transformers
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
from transformers import BertJapaneseTokenizer
TOKENIZER = BertJapaneseTokenizer.from_pretrained('bert-base-japanese-char')
tokens = TOKENIZER.tokenize(sample_text)
IDS = TOKENIZER.convert_tokens_to_ids(tokens)
IDS = onp.asarray(IDS, dtype=onp.int32)
PAD_AMOUNT = 512 * 1024 - len(IDS)
あとは公開されているデモ・コード(https://github.com/google/trax/tree/master/trax/models/reformer)を少々修正して、適当な単語から開始して、文章を生成してみた結果が以下のようになります。
夢 よ う に し た 。 「 こ こ は こ う で 、 お よ り も 一 つ の で あ れ ま す 。 実 在 り ま す 。 そ う す る 一 人 は 、 お か よ り で 、 夢 以 で く.... 」 「 そ う だ わ か ら い ま に な っ て は 、 つ の 理 を ス バ イ の 動 さ れ て お り 、 こ と 、 [UNK] を そ う し た 夢.. ブ ウ と い ま っ て い る よ う と 、 そ の 力 の 中 世 も あ ら わ ら い の 人 間 を し た 。........ そ の 人 間 、 夢 し た 。 「 こ の 『 人 』 と を 政 治 、 お か そ ま し ま し た 、 そ の 治 治 さ ま で 、 外 か ら 、 外 れ ま 一 人 で あ り に 、 外 で 夢 よ う に グ ン コ リ と 立 て て て み 。 前 に な っ て 、 よ く 。 そ と し よ り 、 自 ず に 、 ハ ン と 合 っ た せ て 、 中 を 作 っ た 夢 間 地 上 、 大 学 、 行 、 あ な 国 大 学 、 学 部 を 以 て 、 そ の 学 に 自 分 と し て 、 ど こ を し て 、 そ の 中 で あ え ら 作 っ た 夢 よ.............. ン ン ン........ と 、 大 な 力 一 分 の 関 の 行 の 一 分 一 つ 取 り で あ る 夢 で し た が 、 そ の 事 は 、 実 を 社 会 と 大 な 関 す る ば か り に な り ま し た 、 行 し て は ト の で 、 こ の 実 が 、 す 」 に 大
1つの小説を読み込ませて簡単に学習させただけなので、流石に意味のある文章の生成は期待できませんが、やはり一度にこれほどの文章を入力し学習できることは非常にインパクトのあることですね。
まとめ
最近の自然言語処理モデルの研究成果として今回はReformerというモデルを紹介しました。Transformerにあった問題を既存のLSHとRevNetで用いられた技術を上手く組み合わせることで少ないメモリーで非常に長い文章を処理できます。これは機械学習で大量の計算資源がなくとも、高性能のモデルがより手軽に利用できる画期的なものです。 なお、自然言語処理を主に解説しましたが、Reformerは画像生成など他のタスクにも応用することは可能です。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
参考資料
- Attention Is All You Need [https://arxiv.org/abs/1706.03762]
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [https://arxiv.org/abs/1810.04805]
- RoBERTa: A Robustly Optimized BERT Pretraining Approach [https://arxiv.org/abs/1907.11692]
- (GPT-2) Better Language Models and Their Implications [https://openai.com/blog/better-language-models/]
- (T5) Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer [https://arxiv.org/abs/1910.10683]
- 「Reformer: The Efficient Transformer」[https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html]
- 「Transformer大規模化へのブレークスルーとなるか!? 高効率化したReformer登場」https://ai-scholar.tech/treatise/reformer-ai-364/
- ALBERT: A Lite BERT for Self-supervised Learning Representations [https://arxiv.org/abs/1909.11942]
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter [https://arxiv.org/abs/1910.01108]
- Deep Residual Learning for Image Recognition [https://arxiv.org/abs/1512.03385]
- The Reversible Residual Network: Backpropagation Without Storing Activations [https://arxiv.org/abs/1707.04585]
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD