2017.04.11
トピックモデル入門:WikipediaをLDAモデル化してみた
こんにちは。次世代システム研究室のJK(男)です。
これまではDeep Learning系の話をしてきましたが、今回はちょっと目線を変えてトピックモデルの話をしたいと思います。トピックモデルはちょっと前に話題になったモデルで、取得した結果がわかりやすいというところが魅力的かなーと思います。今回の内容は、(1) トピックモデルと(2) LDAについて簡単に説明したあと、(3) python libraryのgensimを用いてWikipediaの文章についてLDAでモデル化します。(4) 最後に得られた結果を考察します。
1. トピックモデルとは
トピックモデルとは、ざっくり言えばある文章をトピックごとの成分に情報圧縮するモデルです。ちゃんと理解したい人は教科書(これとかこれ)を読むことをお薦めします。ただいきなり読むと挫折する可能性があるので、ここでは教科書への架け橋的な説明をしてみます(ちょっとマニアックな話なので、時間がなければ2章から読んでください)。
そもそもモデル化とは何でしょうか?私なりの理解としては、複雑な観測現象を数式という単純な言語で説明しよう、という作業です。つまり「数式Aでモデル化する」とは、観測現象を数式Aで表せるはずだという信念(仮定)が暗黙の内に入っています。たとえば図1左を見ると、この観測現象(観測ポイント)は直線で表せそうです。そこで直線の数式:y = ax + bでモデル化します。このとき暗黙のうちにきっとこの観測現象は直線で説明できるはずだ、という信念が入っているのがわかると思います。当たり前ですが、図1右のようなデータをy=ax+bでモデル化しても、現象をうまく説明できません。この場合はサインカーブでモデル化するのがよさそうです。こういった数式(モデル)は色々な形をとり得るので、y = f(x)といった書き方をよくされます。
図1: 観測データのモデル化

図1左のケースにもどります。バラバラの観測現象(ここでは100観測点)を、モデル化することでたった2つのパラメータ(a, b)で表せました。1観測点につき(x, y)と2つの情報量をもつので、この現象を表すには200個の数字が必要だったのに、それが2つの数字にまで圧縮できました。これは直線で表せることができるという仮定、つまり直線モデルという情報量が入ってるために可能な圧縮といえます。
モデル化の話をまとめると、複雑な観測現象を(数式という言語で)単純に説明しようぜ、ということです。そのとき観測現象がとり得る形状がこういう形であるはずだ!と仮定した数式、これがモデルです。このモデルの決定に、人の主観(信念)が思いっきり入っているんですね。
トピックモデルの話です(やっと)。ここでは観測現象としては、オーソドックスに日本語のニュース記事を考えます。この記事を説明する(生成する)モデルをつくります。つまりモデル化です。トピックモデルはどんな信念でつくるのか?それは文章の各単語が「トピック」という変数から作られる、という大胆な仮定の下に構築されています。トピックとは”分野”や”主題”のようなものと考えればOKです。すごく簡略化して説明すると上記のxをトピック変数として、x = “スポーツ”のとき、y = f(x) = “スポーツ記事”の文章が現象として観測される、といった感じのモデル化を行います。x=”政治”なら、y=”政治記事”です。そんな単純なのでいいんか?という疑いがあると思います。その感覚は正しくて、モデル化は主観が入っているので失敗することもたくさんあり、上手く説明できているか調査することはとても大事です。トピックモデルがかなり有用なモデルであることは先人達によって実証されているので、ここでは彼らに感謝しつつこのまま使います。
脱線話をひとつ。上記のとおり現象を説明する上で、モデルの選択は最重要タスクの一つです。ダメなモデルを使ったら、他をどんなに頑張ってもダメなことがわかると思います。昨今話題のDeep Learningの長所の一つは、モデル化にあまり頭を悩ませなくてよいということです。上記の言葉でいえば、モデル作成者の信念があまり入らないということです。複雑なネットワークによって色々な形状の関数になれるため、とりあえず特徴量(と教師データ)を入れて最適化すると結構いい感じのモデル化がされます。ただこの長所には裏の顔があります。それは最適化されたモデルの解釈が難しいことです。たとえば上記のy=ax+bなら、モデル作成時に既にyとxは直線関係にあるという信念が入っています。このため、最適されたモデル(正確にはモデルパラメータ: a, b)から、現象についての理解が進みます。一方、Deep Learningは複雑なネットワークによって作られたブラックボックス的なモデルなので、最適化モデルのパラメータを見てもなかなか理解が難しいです。これはモデル化の際の、主観の情報量の差ともいえるかもしれません。もちろん予測に使うだけなら、あまり関係ない話ですが。一方で、トピックモデルの基本であるLDAは、結果が解釈しやすいです。これはモデル化のとき「記事とはこのように作られてるはずだ」という信念(仮定)がたっぷり入り込んでいるからだと思います。
2. LDAとは
LDA (Latent Dirichlet Allocation; 潜在的ディレクリ配分法)は、トピックモデルの基本的なモデルです。謎な言葉の羅列ですが、さらっと説明します。LDAは(基本形は)教師なし学習であり、インプット情報は複数の文章(これまでの例で言えば記事の集まり;以下も記事を例に説明します)です。LDAでは、それぞれの記事を単語に分割して情報化して、各記事についてのトピックを推定します。トピックとは”分野”や”主題”のようなものと考えればOKです。1章ではトピックは一つで説明しましたが、例えば「スポーツ振興」の記事ならば、政治とスポーツどちらもトピックになりそうです。つまり一つの記事は複数のトピックを持ちえます。LDAでは各記事の単語ごとにトピックがあると仮定して、各単語はそのトピックからある確率で生成されたと考えます。つまり同一記事に、政治っぽい単語があれば政治トピック、スポーツっぽい単語があればスポーツトピックのウェイトが高くなります。
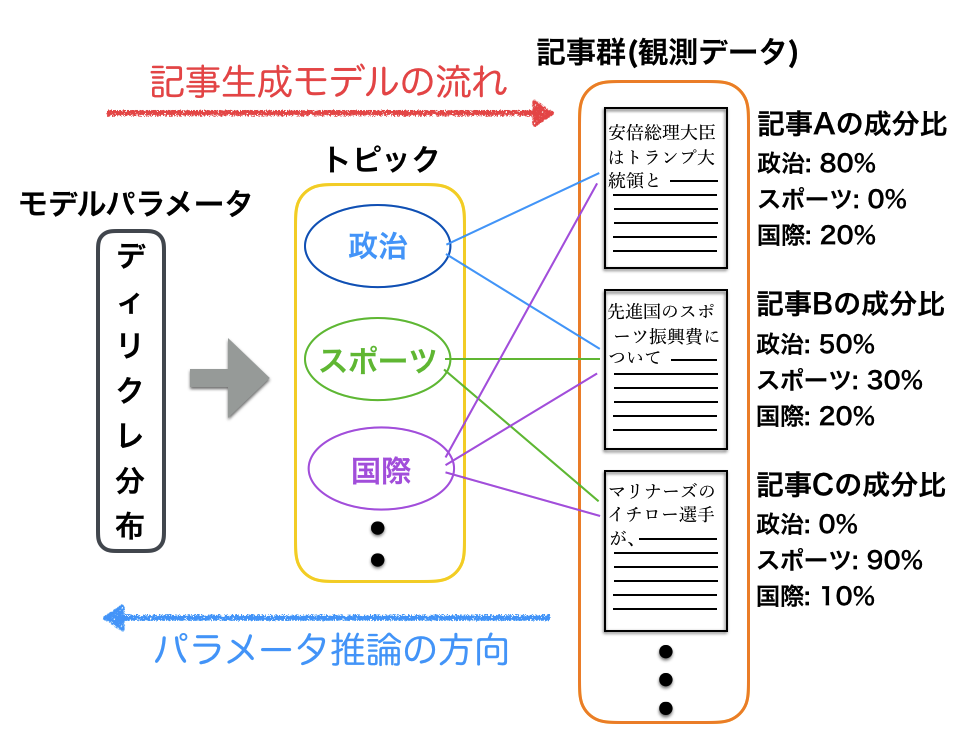
LDAで注意したいのは、観測事実から推定する方向とモデル構築の向きが逆ということです(図2)。LDAはある視点から見ると、記事の単語製造モデルといえます。確率分布(ここではディレクリ分布)からトピックが決まり、トピックから単語が生成され記事ができる。一方、推定する際は観測記事があり、そこから大元のディレクリ分布のパラメータの最適化が必要になります。この方向の違いを理解しないと混乱するかもですね。ちなみに上記のようにトピックはディレクリ分布から作られていて直接観測できない(= 潜在)ので、LDA(潜在的ディレクリ配分法)と呼ばれています。
図2: LDAモデルのスケッチ
(この段落はちょいアドバンス)そもそもトピックはどう決めてんの?人が決めてるの?と疑問に持ったかもしれません。今までは説明を簡単にするために「政治」「スポーツ」トピックというものがある、という様に書いてきましたが、これは正確ではないです。実際には観測された記事のベクトル化された多次元の情報を、別の(より情報量を持つ)軸に射影します。機械学習経験者ならPCA(主成分分析)がイメージ的に近いです。なので人が決めるのはトピックの数だけです。軸は元のベクトル空間のある方向を向いており、0.2 * (サッカー) + 0.1 * (野球) + …. のようになります。このとき、この軸に集まる単語の集団が多くの場合似た文脈で使われることから、似たような意味を持つ集団(= トピック)になる、というわけです。上記の例なら、サッカー、野球があるから「スポーツ」のトピックだな、と人が理解できます。ただしこれはLDAが(最適化によって)決めた軸であり、常に人が理解できるトピックにまとまっているとは限りません。
このブログを読む上で必要な知識を(正確性を若干犠牲にして)ざっくりまとめると以下のようになります。
- LDAは多数の記事群をインプットとすることで、各記事の文章情報を「トピック」というものにまとめる。
- トピックは複数あり、記事の情報はその組み合わせでできている(というモデル化をする)。たとえば記事Bを、「政治トピック」成分50%,「スポーツトピック 」成分30%,「国際トピック」成分20%、のように圧縮する。このとき(topic1,2,3 = 政治、スポーツ、国際として)、記事A = 0.5 * topic1 + 0.3 * topic2 + 0.2 * topic3のようにこのブログでは表示する。
- トピックは(記事の文章中の)複数の単語から構成され、単語によって成分量(〜 重要度)が異なる。2の表示方法に従うと、Topic1 = 0.5 * “野球” + 0.3 * “サッカー” + 0.1 * “試合” + 0.1 * “得点”、のようになる(”野球”、”サッカー”, etcはインプット記事で使われた単語)。
- 各トピックは、インプットされた全ての記事をもとにLDAが自動的に決定する。したがってLDAで最適化された各トピックについて、トピックを構成している重要な(成分の多い)単語群を見ることで(上の3参照)、人が各トピックの分野を推定する。上記3のtopic1であれば、構成単語から「スポーツ」トピックと推測できる。
3. gensimで日本語WikipediaをLDAモデル化
gensimは、自然言語処理系のpython libraryです。LDAの他、ちょっと前に話題になったword2vecもpythonから簡単に使えるようになっているイケメンlibraryです。今回は日本語Wikipediaの記事を、LDAを使いモデル化します。データ処理とLDA最適化についての具体的なコードは、ここのana_wiki1.ipynbにあるので参考にしてください。簡単な流れだけ書くと以下のようになります。
- データの準備
- データ処理
- LDAでモデル化
a. 日本語Wikipediaの記事データをダウンロードして展開
b. xml -> txt化 (wp2txtを使用)
a. (この実験では時間節約のため、全体の30%の記事を使用した)
b. 1記事ずつ形態素解析(Mecabを使用)で単語に分割
c. 辞書化(日本語単語のままでは扱えないので、分割した日本語ごとに数字を割り振る)
d. 記事ごとのコーパスをつくる。コーパスとは、文章を(コンピュータで扱えるように)ベクトル化したもの。ここではWikipediaの1ページを1記事とする。
e. 記事をtfidf化。しなくても良いが、ここでは行う (その方が精度が良い気がするので)。
a. 上記で作成したコーパス、辞書を用いてgensimのLDA modelを最適化する。
4. あそんでみる & 考察
さて日本語Wikipediaの記事の30%(約30万記事)をLDAでトピック情報にモデル化した(圧縮した)ので、これをつかって遊んでみましょう。ちなみにここのana_wiki2.ipynbに実際に実験したコードや結果があります。ここでは一部を紹介しますので、興味のある方は実際のノートも見てください。ここでは以下の3つを実験します。
- 4-1. トピック観察 (取得したトピックの構成単語を観察)
- 4-2. 類似度 (インプット文章と似た記事を探す)
- 4-3. クラスタリング (記事群をクラスタリングして、うまくまとまっているかを観察)
4-1. トピック観察
まずLDAで最適化した記事のトピックがどのような単語群でできているかを見て、各トピックを推測しましょう(2章の最終段落も参照)。今回のモデルでは全部で100トピック(0番-99番)と多いので一部抜粋します。またトピックは非常に多くの単語でできているため、トップ10の重み(〜重要度)をもつ単語のみ表示します。
ケースa. きれいにtopic内容がわかる例
- Topic#3: ‘0.021″属” + 0.017″科” + 0.011″種” + 0.010″分類” + 0.009″綱” + 0.009″亜” + 0.008″植物” + 0.008″目” + 0.008″学名” + 0.006″分布”‘
- Topic#6: ‘0.007″作曲家” + 0.007″演奏” + 0.006″ピアノ” + 0.006″指揮者” + 0.005″語” + 0.005″ドイツ” + 0.005″音楽” + 0.005″楽章” + 0.005″ヴァイオリン” + 0.005″指揮”‘
- Topic#42: ‘0.042″駅” + 0.012″線” + 0.007″ホーム” + 0.007″開業” + 0.007″路線” + 0.005″間” + 0.005″運行” + 0.005″列車” + 0.005″駅名” + 0.005″鉄道”‘
- Topic#81: ‘0.023″古墳” + 0.012″出土” + 0.011″遺跡” + 0.008″史跡” + 0.008″メートル” + 0.008″墳” + 0.007″墳丘” + 0.006″築造” + 0.005″土器” + 0.005″発掘調査”‘
ケースb. 微妙な例
- Topic#5: ‘0.017″恒星” + 0.014″星” + 0.012″料理” + 0.009″NGC” + 0.007″天体” + 0.006″光年” + 0.006″変光星” + 0.005″HD” + 0.005″視る” + 0.005″食べる”‘
- Topic#50: ‘0.006″ウォルト・ディズニー” + 0.005″リーグ・アン” + 0.005″ミニマム級” + 0.005″流通経済大学” + 0.005″ドナルド” + 0.004″ガーナ” + 0.004″ブータン” + 0.004″世界選手権自転車競技大会トラックレース” + 0.004″桃園” + 0.004″矢沢永吉”‘
ケースaのトピックは上から、3:種族系, 6:クラシック音楽系, 42:電車系, 81:考古学系、ときれいにまとまっています。一方ケースbでは、5:宇宙と料理, 50:特にまとまりがない、となっています。トピック5は宇宙や料理系の記事数が少なく、限られたトピック数(100個)しかないためマージされたのかもしれません。トピック50は「その他」枠?記事数があまり多くないニッチな系統のテーマが集まったのかもしれません。
4-2. 類似度
今度は自前で用意した文章に最も近いWikipediaの記事を見つけてみましょう。やることとしてはインプット文章をトピック成分に圧縮して、その情報と記事情報の間の類似度を計算した後、類似度の高い記事を見つけます。具体的なやりかたは上記で紹介したノートを見てもらうとして、ここでは結果だけ見せます。
実験Aでは、前回のブログの1章までをインプット文章としました。内容は機械学習系です。計算された類似記事は、[任意性: 0.999, 概念: 0.999, クリック (ノイズ): 0.999, ウソスコア: 0.999, スーパーfxチップ: 0.999]などになりました(記事タイトルの横にある数字が類似度;0から1まで取り得て、1のとき完全一致)。ちょっと微妙な感じです。記事中の単語の多くが、Wikipediaから作られた辞書に存在せず意味のある単語があまり取得できなかったのかもしれません。実際、類似記事も抽象的な内容に見えます。ただし、Wikipediaの「機械学習」の記事との類似度を計算すると0.95と非常に高い数字になったので、ちゃんとモデル化できている可能性が高いです。
実験Bは、極端に一単語のみ(有名人でパッと思いついた)「明石家さんま」をインプットにしてみました。計算された類似記事はテレビ関係(新やじうまワイド: 1.000, ibcテレビ: 1.000, newsjapan: 1.000, ez!tv: 1.000, 山本厚太郎: 1.000, 脇田寧人: 1.000,)で、たったこれだけの情報でもテレビ系のトピックを引っ張ってこられるのは、さすが明石家さんまといったところです。トピック分布としては、85番が圧倒的な重みを占めています。1章で調査したトピックの単語成分を調査すると、メディア系だったのでいい感じです。
実験Cでは、ニコニコ大百科の「明石家さんま」の項目の文章をインプットにしました。計算された類似記事(山田じん子: 0.995, 森脇和成: 0.991, はなけろ: 0.990, 光の海 (漫画): 0.990, 心はロンリー気持ちは「…」: 0.990, ジミー大西: 0.988, 鬼瓦権造: 0.988)は、(マイナーとはいえ)テレビタレントが多く、なかなか良い感じです。上位に(明石家さんまと関係深い)「ジミー大西」がランクインしているので「すごい!」と一瞬嬉しくなりましたが、インプット記事にジミー大西という単語が入っていたためだと思います。この記事とWikipediaの「明石家さんま」の記事との類似度を計算すると0.92なので良い感じです。
これらの実験から、インプット文章との”類似度”が最も高い記事が最も類似している記事とまではいえないものの、”類似度”がインプット文章と記事群との類似性を評価する上でかなり有用であることがわかりました。
4.3 クラスタリング
最後にLDAでモデル化した記事(約30万件)を、K-means法を用いて200種類のクラスタに分類しました(やり方は上記で紹介したノートを参照)。分類した200個のクラスタごとに、トピック成分(0-99番)のヒストグラムを作ります。ヒストグラムはそれぞれ異なるトピック分布となっているため、期待どおりクラスタごとに異なる記事情報を持っていることが期待できます。計算されたヒストグラムは、図3のように3種類に大別できることがわかりました:(i)一つのトピックだけ大きい, (ii) 2-4コのトピックが大きい, (iii)飛び抜けたトピックがない均一的な分布(1クラスタのみ)。
図3: 各クラスタごとのトピックモデルの分布。(左):グループ(i). (真ん中):グループ(ii). (右):グループ(iii)

上記で分類したクラスタごとの記事の特徴を調査してみます。以下は結果の抜粋です。
グループ(i)
- Cluster0: スペルバウンド,坪田文,佐藤智恵子,富岡志織,平野文子,水沢南紀
- Cluster80: 佐久間勝之,藤堂高則,織田信貞,毛利貞親,牧野城,岩屋城 (淡路国)
グループ(ii)
- Cluster1: その手はないよ,ウィリー・ディクスン,シモーネ・シモンズ,アニー・レノックス,リッキ・リー
- Cluster23: ウィクトル2世 (ローマ教皇), ルィリスク公,オドン (ポズナン公),ペドロ5世 (アラゴン王)
グループ(iii)
- Cluster6: 太田幸司の熱血!タイガーススタジアム,内田ゴシック,ジスプロシウムの同位体,幻獣旅団
思った以上にきれいに分類できています。グループ(i)のCluster0はトピック番号25がドミナントで、4-1で調査した各トピックの単語分布を見ると25番はテレビ番組系に見えます。Cluster0で選択された記事はテレビタレントが多いので良い感じです。Cluster80は戦国時代系クラスタでこれも良い感じ。唯一他と全く異なる形状をしたグループ(iii) (= Cluster6)の記事を実際にWikipediaで調べてみると、リダイレクト用のタイトル/ほとんど情報がない記事であることがわかりました。ほとんど情報がないために、多数のトピックに均等に重みが分配された結果、均一的な形になったと推測されます。つまりCluster6は「ほとんど情報がない」系ですね。グループ(ii)のCluster1は面白いです。トピック番号70と99番の2種類がドミナントで、70番が音楽系、99番は欧米系トピックのように見えます。実際Cluster1で選ばれた記事は洋楽の音楽関係者で、上記2つのトピックが混合されているように見えます。他のClusterでも99番がつくと欧米化する傾向が見えて、たとえばCluster23のドミナントトピックは99と33番ですが、選択された記事はヨーロッパの王族、教皇っぽい人達の記事群(ちなみに33番は、王族、貴族など超セレブ系のトピック)なので、この場合も良い感じに分類されているのがわかります。
まとめ
日本語Wikipediaの記事の30%をLDAでトピック情報にモデル化(圧縮)しました。モデル化したデータを用いて、類似度の計算やクラスタリングをした結果について考察しました。LDAという非常に基本的なモデルにも関わらず、期待していたより正確に類似度や分類ができたので、正直びっくりしています。(個人的な見解ですが)解析結果について理解しやすく、色々と遊べるので、Deep Learning系よりも考察が楽しい気がします。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD