2021.10.07
分散機械学習をゆりかごから墓場までサポート ~Analytics Zoo~
こんにちは。最近金融領域からweb広告領域にクラスチェンジしたY.S.です。
今回はintel-analyticsが開発しているオープンソースビッグデータAIプラットフォームの
Analytics Zooを触ってみました。2018年1月にver0.1.0がリリースされ、2021年9月時点の最新はver0.11.0です。まだまだ不具合や動かない部分もありますが、2~3日毎に更新されていてかなり活発なプロジェクトです。
Analytics Zoo
Analytics Zooのコンセプトとして、「end-to-endな大規模分散AIプラットフォームの実現」というものがあります。ここでいうend-to-endとは、「local環境で試した処理・モデルをそのまま分散環境にスケールできる」ということのようです。
たしかに、手元で前処理やモデル検証を試すまでは良いのですが、いざそれを分散環境・ビッグデータで動かそうとすると、分散機械学習のライブラリで作り直したり、クラスタに接続するための設定をしたり、色々と大変だと思います。ここのスケールを気にせずに作れるのは便利かもしれませんね。
Analytics ZooにはOrcaというライブラリが用意されていて、これを使うことで一般的な機械学習フレームワークで作ったモデルを、変更を加えることなく分散処理クラスタにsubmitすることができます。現段階では機械学習フレームワークはtensorflow, keras, pytorch、クラスタはYARN, kubernetesに対応しているようです。
今回はAnalytics Zooで、どの程度簡単に分散機械学習を実現できるか試していきます。
2.google colabのチュートリアル (実践)
まずはチュートリアルから始めましょう。
analytics-zooには、google colabでいくつかチュートリアルが用意されています。ここではtensorflow1.15を動かすチュートリアルを触りながら、analytics-zooの使い方を学んでいきます。
まず、必要な環境のセットアップを行います。今回はJDK, analytics-zoo, tensorflowがようですね。pysparkやその他分散処理に関係するパッケージはanalytics-zooと一緒に入ってきます。
!apt-get install openjdk-8-jdk-headless -qq > /dev/null import os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" !update-alternatives --set java /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java !pip install --pre --upgrade analytics-zoo !pip install tensorflow==1.15.0 tensorflow-datasets==2.1.0
環境が整ったら、必要なライブラリをimportしてOrcaプログラムを作成しましょう。Orcaプログラムを使う際は、まずorca_contextを作成します。orca_contextは、Orcaプログラムをクラスタにプロビジョニングする際のエントリーポイントです。作成時にcluster_mode、cluster_master、driver_core、driver_memory等を指定し、yarnやkubernetesなどのクラスタに任意のプロビジョニング設定でモデルをデプロイして分散学習を実現できます。ただ、このチュートリアルではlocalを指定します。
import argparse from zoo.orca.learn.tf.estimator import Estimator from zoo.orca import init_orca_context, stop_orca_context from zoo.orca import OrcaContext OrcaContext.log_output = True # recommended to set it to True when running Analytics Zoo in Jupyter notebook (this will display terminal's stdout and stderr in the Jupyter notebook). init_orca_context(cluster_mode="local", cores=4) # run in local mode
Orcaでの分散学習では、機械学習モデル自体は特別な作り方をする必要はなく、tensorflowで普通に作れます。ここでは画像認識のLeNetモデルを作成します。
import tensorflow as tf
def accuracy(logits, labels):
predictions = tf.argmax(logits, axis=1, output_type=labels.dtype)
is_correct = tf.cast(tf.equal(predictions, labels), dtype=tf.float32)
return tf.reduce_mean(is_correct)
def lenet(images):
with tf.variable_scope('LeNet', [images]):
net = tf.layers.conv2d(images, 32, (5, 5), activation=tf.nn.relu, name='conv1')
net = tf.layers.max_pooling2d(net, (2, 2), 2, name='pool1')
net = tf.layers.conv2d(net, 64, (5, 5), activation=tf.nn.relu, name='conv2')
net = tf.layers.max_pooling2d(net, (2, 2), 2, name='pool2')
net = tf.layers.flatten(net)
net = tf.layers.dense(net, 1024, activation=tf.nn.relu, name='fc3')
logits = tf.layers.dense(net, 10)
return logits
# tensorflow inputs
images = tf.placeholder(dtype=tf.float32, shape=(None, 28, 28, 1))
# tensorflow labels
labels = tf.placeholder(dtype=tf.int32, shape=(None,))
logits = lenet(images)
loss = tf.reduce_mean(tf.losses.sparse_softmax_cross_entropy(logits=logits, labels=labels))
acc = accuracy(logits, labels)
データはtensorflowに用意されているmnistデータセットを使用します。
import tensorflow_datasets as tfds def preprocess(data): data['image'] = tf.cast(data["image"], tf.float32) / 255. return data['image'], data['label'] # get DataSet dataset_dir = "~/tensorflow_datasets" mnist_train = tfds.load(name="mnist", split="train", data_dir=dataset_dir) mnist_test = tfds.load(name="mnist", split="test", data_dir=dataset_dir) mnist_train = mnist_train.map(preprocess) mnist_test = mnist_test.map(preprocess)
作成したモデルのlogitやlossを引数として、Orcaのestimatorインスタンスを作成します。このestimatorには他の機械学習ライブラリのようにfitメソッドやevaluateメソッドが用意されていて、直感的にモデルの訓練や評価を実施できます。これらの処理は、init_orca_contextで指定された環境にsubmitされ実行されます。また、学習後にモデルのsaveもできます。
est = Estimator.from_graph(inputs=images,
outputs=logits,
labels=labels,
loss=loss,
optimizer=tf.train.AdamOptimizer(),
metrics={"acc": acc})
est.fit(data=mnist_train,
batch_size=320,
epochs=max_epoch,
validation_data=mnist_test)
result = est.evaluate(mnist_test)
print(result)
est.save_tf_checkpoint("/tmp/lenet/model")
チュートリアルは特にエラーもなくすんなり完遂できました。
3.localでimageから動かす (実践)
Analytics Zooはdockerイメージを提供しています。今度はこのイメージをベースに作成したコンテナ上でjuypterを起動し、用意されているチュートリアル用のnotebookを動かしてみます。
今回は扱うデータサイズが小さい且つlocal modeでOrcaを使用するので、pandasでデータ操作をしています。
一方で、OrcaをYARNやkubernetesのclient modeとして起動し、実際の分散環境に繋いでその上で処理を進めることもできます。その場合はOrcaが提供しているdata loaderを使ってXShardというクラスとしてデータを読み込むことで、分散処理を意識することなくpandasライクにデータ操作が可能です。ただ、XShardはpandasの操作を完全にカバーできてはいないので、足りない部分はRDD等に変換して自前で書く必要があるようです。
提供されているイメージにはnotebookを起動するスクリプトが含まれていますので、コンテナを起動したらこれを使ってjupyterを立ち上げます。
sudo docker pull intelanalytics/analytics-zoo:latest
sudo docker run -it --rm --net=host \
-e NOTEBOOK_PORT=12345 \
-e NOTEBOOK_TOKEN="my-token" \
intelanalytics/analytics-zoo:latest bash
----- ここからコンテナ内 -----
cd /opt/work
./start-notebook.sh
いくつかnotebookが用意されていますが、今回はanomaly-detection-nyx-taxi.ipynbを実行してみます。このnotebookではRNNを用いた異常検知を実践しています。使用するデータはNYCタクシーの乗客データで、中身はtime spot(30分おき)毎の乗客数が10320レコード入っています。
データの中身はこんな感じ
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10320 entries, 0 to 10319 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 timestamp 10320 non-null object 1 value 10320 non-null int64 dtypes: int64(1), object(1) memory usage: 161.4+ KB None
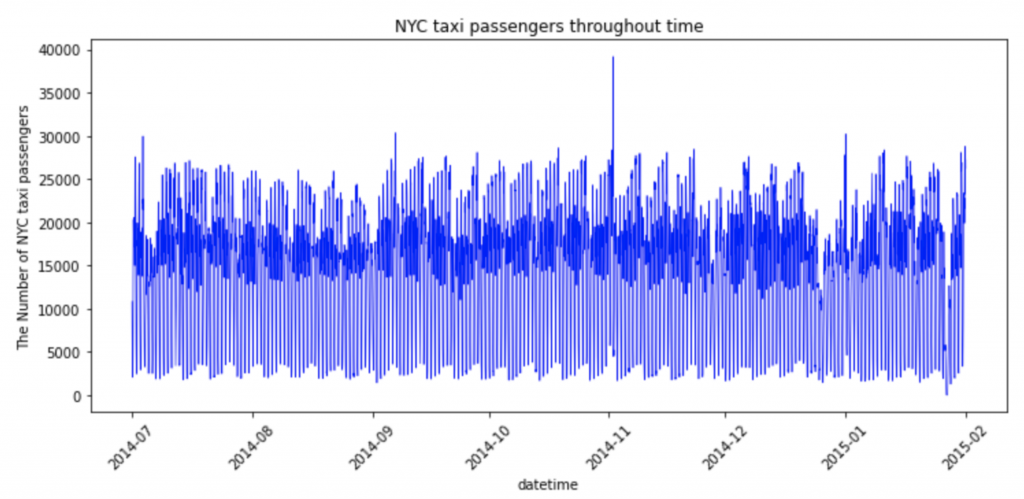
必要なライブラリのインポートです。今回はinit_orca_context()ではなく、init_nncontext()でSparkContextを作成しています。init_orca_context()も内部的にinit_nncontext()を呼んでいるので、init_orca_context(cluster_mode=”local”)としても同じことだと思います。
特にconfを与えていないと、local in-memoryなSparkContextを返します。
import os
from zoo.common.nncontext import *
sc = init_nncontext("Anomaly Detection Example")
import pandas as pd
import numpy as np
import matplotlib
matplotlib.use('Agg')
%pylab inline
import seaborn
import matplotlib.dates as md
from matplotlib import pyplot as plt
from sklearn import preprocessing
EDAとtrain/testデータの作成は本題とは少し外れるので割愛します。pandas DataFrame + matplotlibで、notebook上で可視化しながら使えそうな特徴を探しました。
今回のモデルは、analytics-zooのkerasラッパーで作成します。colabのチュートリアルでやったように通常のtensorflowで定義したモデルをorcaのestimatorに入れるのではなく、orcaを使わずにkerasのラッパーでモデルを作れるのですね。こちらもmodel.fitやmodel.predictで学習・予測をします。
ここでは、直前のN time spotsのデータから直後のtime spotの乗客数を予測するRNNを定義します。このモデルをテストデータに適用した時、予測とかけ離れた部分が異常値ということになります。
from zoo.pipeline.api.keras.layers import Dense, Dropout, LSTM
from zoo.pipeline.api.keras.models import Sequential
# Build the model
model = Sequential()
model.add(LSTM(
input_shape=(x_train.shape[1], x_train.shape[-1]),
output_dim=20,
return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(
10,
return_sequences=False))
model.add(Dropout(0.2))
model.add(Dense(
output_dim=1))
model.compile(loss='mse', optimizer='rmsprop')
# Train the model
print("Training begins.")
model.fit(
x_train,
y_train,
batch_size=1024,
nb_epoch=20)
print("Training completed.")
# create the list of difference between prediction and test data
diff=[]
ratio=[]
predictions = model.predict(x_test)
p = predictions.collect()
for u in range(len(y_test)):
pr = p[u][0]
ratio.append((y_test[u]/pr)-1)
diff.append(abs(y_test[u]- pr))
学習が終わったらテストデータに適用してみて、平均的な予測誤差よりも大きくなっている部分(異常値)を赤くplotして可視化してみましょう。周りに比べて乗客数が減っている期間が赤くプロットされています。
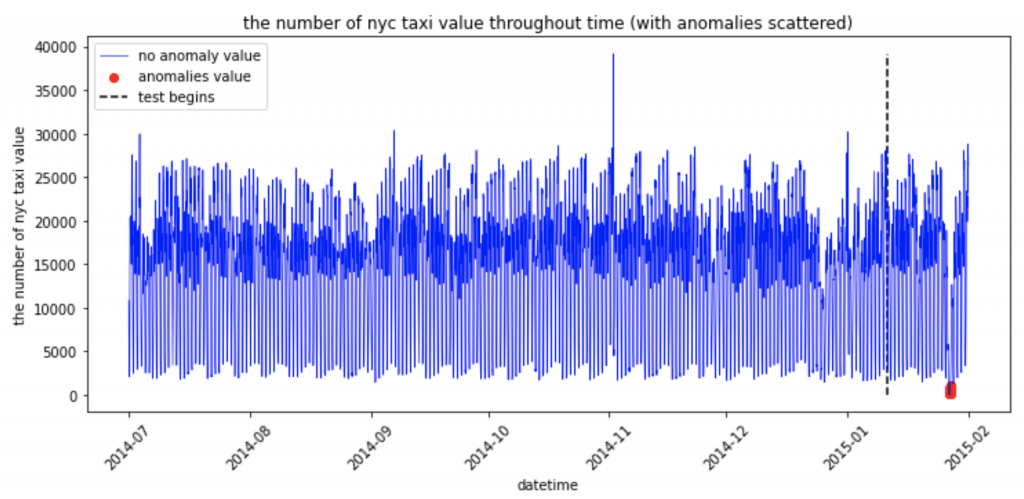
今回はlocal modeで試しましたが、最初に書いたようにorca_contextを各分散クラスタのclient modeとして作成すれば、クラスタに接続した状態で可視化 -> EDA -> モデル作成・検証のフローを行えます。データをXShardとして読み込むことで、分散処理を意識せずにpandasライクなデータ操作も可能なので、機械学習エンジニアリングを大規模データに適用する際のハードルはかなり低いように感じます。
4.YARNクラスタにsubmit (docベースで紹介)
この章では公式Documentを元に、YARNクラスタにanalytics-zooのモデルをデプロイするための準備と手順を紹介します。
client modeとcluster modeの両方に対応しています。どちらのmodeでも、deploy clientとなるノードにanalytics-zooやその他必要なライブラリをインストールした環境を作り、その環境をクラスタにデプロイするので、クラスタの各ノードに何かを新たにインストールする必要はありません。
まずはdeploy clientとなるノードにpython3.7のconda環境を作り、HADOOP_CONF_DIRの設定をします。
conda create -n zoo python=3.7 # "zoo" is conda environment name, you can use any name you like. conda activate zoo export HADOOP_CONF_DIR=the directory of the hadoop and yarn configurations
4-1.client mode
client modeでデプロイする場合は、pipでpythonライブラリとしてanalytics zooをインストールします。
init_orca_context()にcluster_mode=”yarn-client”を指定します。”yarn-client”を指定すると、init_orca_contextはactiveなconda環境を元にpythonランタイム環境を用意し、deploy clientノードに分散処理エンジンを初期化します。
from zoo.orca import init_orca_context sc = init_orca_context(cluster_mode="yarn-client", cores=4, memory="10g", num_nodes=2)
プログラムの実行は、jupyter notebook上で実行するか、通常のpythonスクリプトとして実行します。
jupyter notebook --notebook-dir=./ --ip=* --no-browser or python script.py
4-2.cluster mode
cluster modeでデプロイする場合は、準備としてdeploy clientノードにsparkとanalytics-zooをインストールし、環境変数を設定します。
export SPARK_HOME=the root directory where you extract the downloaded Spark package export ANALYTICS_ZOO_HOME=the root directory where you extract the downloaded Analytics Zoo package
init_orca_context()にはcluster_mode=”spark-submit”を指定します。
submitには、インストールしたanalytics-zooに含まれているspark-submit-python-with-zoo.shを使います。client modeでは、各ノードに実行環境を配布してやる必要がありますが、ここではclient nodeのconda環境を配布します。conda packで現在の環境をパッケージにして、spark-submitスクリプト実行時の引数に与えてやります。
conda pack -o environment.tar.gz
PYSPARK_PYTHON=./environment/bin/python ${ANALYTICS_ZOO_HOME}/bin/spark-submit-python-with-zoo.sh \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./environment/bin/python \
--master yarn-cluster \
--executor-memory 10g \
--driver-memory 10g \
--executor-cores 8 \
--num-executors 2 \
--archives environment.tar.gz#environment \
script.py
5.kebernetesクラスタにsubmit (実践)
T.D.Qさんが以前に作成された検証用のkubernetesクラスタがあるので、実際にそこに機械学習モデルをデプロイしてみます。
kubernetesクラスタへのデプロイは、analytics zooの[intelanalytics/hyper-zoo]イメージをベースに作成したコンテナから行います。
sudo docker pull intelanalytics/hyper-zoo:latest
sudo docker run -itd --net=host \
-v /etc/kubernetes:/etc/kubernetes \
-v /root/.kube:/root/.kube \
-e NOTEBOOK_PORT=12345 \
-e NOTEBOOK_TOKEN="your-token" \
-e http_proxy=http://your-proxy-host:your-proxy-port \
-e https_proxy=https://your-proxy-host:your-proxy-port \
-e RUNTIME_SPARK_MASTER=k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \
-e RUNTIME_K8S_SERVICE_ACCOUNT=account \
-e RUNTIME_K8S_SPARK_IMAGE=intelanalytics/hyper-zoo:latest \
-e RUNTIME_PERSISTENT_VOLUME_CLAIM=myvolumeclaim \
-e RUNTIME_DRIVER_HOST=x.x.x.x \
-e RUNTIME_DRIVER_PORT=54321 \
-e RUNTIME_EXECUTOR_INSTANCES=1 \
-e RUNTIME_EXECUTOR_CORES=4 \
-e RUNTIME_EXECUTOR_MEMORY=20g \
-e RUNTIME_TOTAL_EXECUTOR_CORES=4 \
-e RUNTIME_DRIVER_CORES=4 \
-e RUNTIME_DRIVER_MEMORY=10g \
intelanalytics/hyper-zoo:latest bash
5-1.client mode
hyper-zooのコンテナ上のjupyter notebookからclient modeでkubernetesクラスタに接続してみようとしたのですが、jupyterのkernelへの接続がTimeoutとなってしまいました。どうやら入っているtornadoライブラリのバージョンの問題みたいです。バージョンを変えて再インストールを試してみたりしたのですがどうにも上手くいかず、今回はclient modeの検証は断念しました。
Documentを見ると、init_orca_context()でcluster_mode=”k8s_client”を指定すれば、あとはYARNのclient modeと同様に動きそうでした。
from zoo.orca import init_orca_context
init_orca_context(cluster_mode="k8s", master="k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port>",
container_image="intelanalytics/hyper-zoo:latest",
num_nodes=2, cores=2,
conf={"spark.driver.host": "x.x.x.x",
"spark.driver.port": "x"})
5-2.cluster mode
cluster modeはなんとか動きました。
hyper-zooにはpython3.6.9とtensorflow2がインストールされています。tensorflow2でmnistをanalytics zooを動かすcolabのチュートリアルがあるので、同じコードをkubernetesクラスタにsubmitしてみます。
from zoo.orca import init_orca_context, stop_orca_context
init_orca_context(cluster_mode="spark-submit")
import tensorflow as tf
def model_creator(config):
model = tf.keras.Sequential(
[tf.keras.layers.Conv2D(20, kernel_size=(5, 5), strides=(1, 1), activation='tanh',
input_shape=(28, 28, 1), padding='valid'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'),
tf.keras.layers.Conv2D(50, kernel_size=(5, 5), strides=(1, 1), activation='tanh',
padding='valid'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(500, activation='tanh'),
tf.keras.layers.Dense(10, activation='softmax'),
]
)
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
def preprocess(x, y):
x = tf.cast(tf.reshape(x, (28, 28, 1)), dtype=tf.float32) / 255.0
return x, y
def train_data_creator(config, batch_size):
(train_feature, train_label), _ = tf.keras.datasets.mnist.load_data()
dataset = tf.data.Dataset.from_tensor_slices((train_feature, train_label))
dataset = dataset.repeat()
dataset = dataset.map(preprocess)
dataset = dataset.shuffle(1000)
dataset = dataset.batch(batch_size)
return dataset
def val_data_creator(config, batch_size):
_, (val_feature, val_label) = tf.keras.datasets.mnist.load_data()
dataset = tf.data.Dataset.from_tensor_slices((val_feature, val_label))
dataset = dataset.repeat()
dataset = dataset.map(preprocess)
dataset = dataset.batch(batch_size)
return dataset
from zoo.orca.learn.tf2 import Estimator
est = Estimator.from_keras(model_creator=model_creator, workers_per_node=2)
batch_size = 320
stats = est.fit(train_data_creator,
epochs=5,
batch_size=batch_size,
steps_per_epoch=60000 // batch_size,
validation_data=val_data_creator,
validation_steps=10000 // batch_size)
stats = est.evaluate(val_data_creator, num_steps=10000 // batch_size)
est.shutdown()
print(stats)
stop_orca_context()
submitにはYARNクラスタの時と同様に${ANALYTICS_ZOO_HOME}/bin/spark-submit-python-with-zoo.shを使い、引数でmasterのurlやkubernetesのサービスアカウント 、各ノードに配布するimageファイルを指定します。しかし、hyper-zooのimageを指定してsubmitすると、Estimator作成の部分でエラーが出ました。
RuntimeError: Click will abort further execution because Python 3 was configured to use ASCII as encoding for the environment.
Consult https://click.palletsprojects.com/python3/ for mitigation steps.
This system supports the C.UTF-8 locale which is recommended.
You might be able to resolve your issue by exporting the following environment variables:
export LC_ALL=C.UTF-8
export LANG=C.UTF-8
実行環境にLC_ALLとLANGを設定すると解決するようなので、hyper-zooを拡張したimageを作り、それを指定するようにします。ちなみにpython3.7以上ではこのエラーは出ないようです。
FROM intelanalytics/hyper-zoo:latest ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8
最終的なsubmitコマンドは以下になりました。
${ANALYTICS_ZOO_HOME}/bin/spark-submit-python-with-zoo.sh \
--master k8s://https://192.168.1.14:6443 \
--deploy-mode cluster \
--name analytics-zoo \
--conf spark.kubernetes.container.image="my_custom_hyper-zoo_image" \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=${RUNTIME_K8S_SERVICE_ACCOUNT} \
--conf spark.executor.instances=1 \
--conf spark.cores.max=2 \
--executor-memory 2g \
--driver-memory 2g \
--executor-cores 1 \
--num-executors 2 \
http://192.168.1.14:30001/AnalyticsZoo_k8s_test.py
このコマンドを実行し、kubectl logsでpod内の出力を見てみると、学習が完了してevaluateの結果が表示されていました。
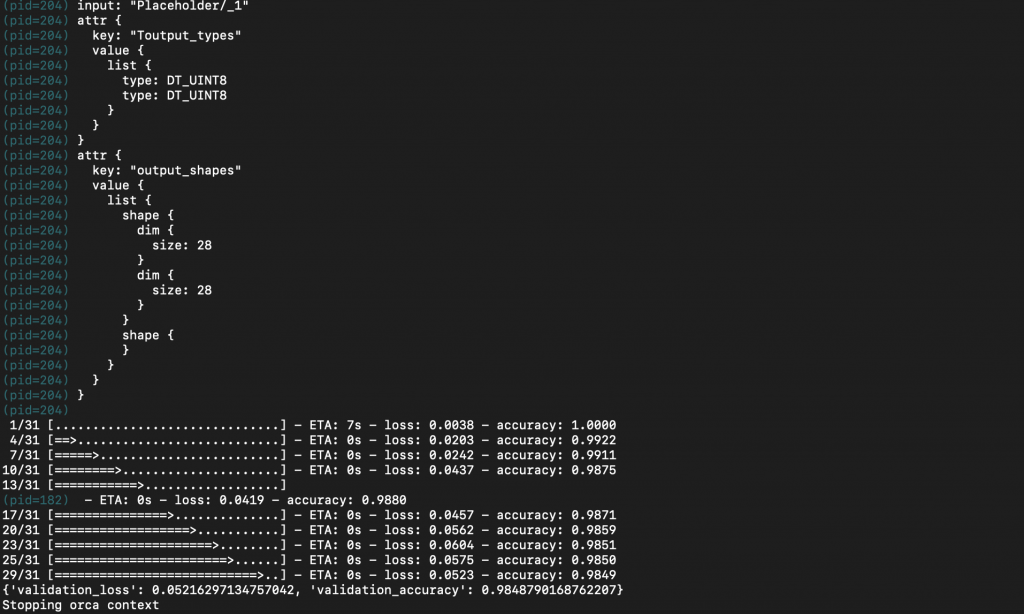
6.まとめ
今回は、「end-to-endな大規模分散AIプラットフォーム」を目指しているAnalytics Zooを触ってみました。各機械学習フレームワークやsubmit先の違いを吸収してくれるorca_contextや、pandasライクに分散DataFrameを操作できるXShardなど、モデル開発者が機械学習フローだけに集中できるように設計されています。
実際にorca_contextを通じて、tensorflowで作成したモデルをkubernetesクラスタにsubmitできました。必要な操作もコンテナ起動+αで、クラスタ環境さえあればお手軽に分散機械学習を導入できます。
一方で、コンテナ内のpythonとフレームワークの親和性が完全でなかったり、XShardが対応していないデータ操作があったりと、伸び代もたくさんあるようです。
ただ冒頭でも紹介したように、Analytics Zooはかなり活発に開発が行われているプロジェクトですので、v.1.0.0がリリースされるのもそう遠くないかも知れません。今から楽しみですね。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティスト、及びグループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD