2021.04.06
Conoha VPS上にKubernetesベースのSparkクラスターを検証するー環境構築編
こんにちは。次世代システム研究室のT.D.Qです。
Spark 2.3からKubernetesのNativeサポートしているようになりましたがその時はまだ色々な制限がありました。Sparkの進化と伴い、Kubernetesのサポートも少しずつ進化して、最新バージョンのSpark3.1.1では複数の機能が改善されました。前回紹介したSpark 3.0の新機能によるFXデータの抽出時間を短縮してみたを続いて、今回の記事でConoha VPS上にContainerベースSparkクラスターを検証する内容を紹介したいと思います。
Spark on Kubernetesについて
依存関係の管理が簡単になる
今までSparkとHadoop YARNを使っていますがクラスター全体に同じグローバルSparkバージョン及び依存するライブラリバージョンを使用する必要があります。Kubernetesで実行している場合は依存関係の管理が簡単になります。Sparkアプリケーションをコンテナとしてパッケージ化することで、アプリケーションと一緒に依存関係を単一のエンティティとしてパッケージ化できるため、コンテナのメリットを享受できます。さらに個別のDockerイメージごとにSparkバージョンを自由に選択できます。
Spark on Kubernetesの仕組み

上記の図のようにKubernetes上にSparkの実行には以下のステップがあります。
※計算が終了したExecutorのPodは自動で削除されます。全てのExecutorのPodが削除された後、最後にSpark DriverのPodが停止(Terminate)されます。計算結果は、Spark DriverのPodのログに出力されます。Spark DriverのPodは自動で削除されないため、計算結果を確認後にkubectlコマンドを使い手動で削除します。
Spark on Kubernetesは最新版を使った方が良い
以下の図のようにSpark2.3の時点でSpark on Kubernetesを使えるようになりましたがかなり制約が大きかった。2.4以降で少しずつ完成度を高めてきていますので、最新版を使った方が良さそうです。

VPSサーバの準備
今回の検証はConoha VPS 6台(メモリ 8GB/CPU 6Core/SSD 100GB)で環境構築しました。
| Master Node | 2台 |
| Worker Node | 3台 |
| Tool Node | 1台 |
| 作業PC | Macbook Pro |
| OS | Ubuntu 20.04 LTS |
| Deployment Tool | Kubespray v2.15.0 |
| Container Runtime | Docker |
| CNI | Calico |
| Monitoring Tool | Lens 4.2.0 |
※クラスターのHA構成のため、Tool Nodeのリソースも使います。
サーバの初期設定
プライベートネットワーク設定
各VPSサーバにログインしてホスト名、プライブネットワークを構築するためEth1の設定を行いました。プライベートネットワーク設定はConohaからの設定手順もありますので参考して設定しました。
Kubernetesクラスター構築アカウント発行
rootアカウントはセキュリティ関係で使わないため、各サーバにKubernetesクラスター構築用のアカウント発行し、公開鍵認証を設定しました。
adduser k8sadmin adduser k8sadmin sudo echo "k8sadmin ALL=(ALL:ALL) NOPASSWD: ALL" >> /etc/sudoers.d/k8sadmin
セキュリティグループの設定
セキュリティを高めるため、通信設定を行います。外部から各ノードにアクセスを制限するため、接続許可の設定しましょう。
Conoha VPS上に接続許可の設定の仕組みとしては、セキュリティグループを作り、これをサーバーのネットワークポートに適用して行いますが、APIでしか操作することができません。そのため、Conoha APIページで事前にAPIユーザ/PWを発行する必要があります。コマンドラインで操作できるConohaーnetというツールを使って簡単に設定できるので、今回使ってみました。というわけで今回は以下の2つのセキュリティグループを作成し、サーバーのインターネット接続用のネットワークポートに適用することとします。
spark8s-inbound:プライベートネットワーク内のサーバ全ポート許可
./conoha-net create-group spark8s-inbound ./conoha-net create-rule -d ingress -e IPv4 -P tcp -i 192.168.10.0/24 spark8s-inbound ./conoha-net attach -n quytd-vps-spark-m1 spark8s-inbound ./conoha-net attach -n quytd-vps-spark-m2 spark8s-inbound ./conoha-net attach -n quytd-vps-spark-s1 spark8s-inbound ./conoha-net attach -n quytd-vps-spark-s2 spark8s-inbound ./conoha-net attach -n quytd-vps-spark-s3 spark8s-inbound ./conoha-net attach -n quytd-vps-spark-tool spark8s-inbound
spark8s-outbound: 外部からKubernetesクラスターに接続するため6443(IPv4)のみ許可
./conoha-net create-group spark8s-outbound ./conoha-net create-rule -d ingress -e IPv4 -p 6443 -P tcp spark8s-outbound ./conoha-net attach -n quytd-vps-spark-tool spark8s-outbound
KubeSprayによるKubernetesクラスターを構築
KubeSprayとはAnsibleベースでKubernetesを構築するツールです。他の構築ツールもありますが、KubeSprayはHAクラスターを容易に構成可能で、パブリッククラウドからベアメタルまで様々な環境にProduction Readyマルチノードクラスターを構築できるということで、今回使ってみたいと思います。
KubeSprayをToolサーバにCloneする
早速インストールしていきましょう。まずは、Kubesprayの公式リポジトリからgit cloneしましょう。
k8sadmin@quytd-spark-tool:~$mkdir /tmp/workspace k8sadmin@quytd-spark-tool:~$cd /tmp/workspace/ k8sadmin@quytd-spark-tool:/tmp/workspace$git clone https://github.com/kubernetes-sigs/kubespray.git k8sadmin@quytd-spark-tool:/tmp/workspace$cd kubespray k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$
Ansible実行環境の準備
Ansibleを実行するために必要なモジュールをインストールするため、Kubesprayリポジトリに含まれるrequirements.txtに書かれたモジュールをインストールします。Pipを使ってKubesprayを利用する際に必要なモジュールをインストールします。
k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ pip -V
pip 21.0.1 from /home/k8sadmin/.local/lib/python3.8/site-packages/pip (python 3.8)
k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ pip install --user -r requirements.txt
Collecting ansible==2.9.18
Downloading ansible-2.9.18.tar.gz (14.3 MB)
|████████████████████████████████| 14.3 MB 16.6 MB/s
Requirement already satisfied: cryptography==2.8 in /usr/lib/python3/dist-packages (from -r requirements.txt (line 2)) (2.8)
Collecting jinja2==2.11.3
Downloading Jinja2-2.11.3-py2.py3-none-any.whl (125 kB)
|████████████████████████████████| 125 kB 62.2 MB/s
Collecting netaddr==0.7.19
Downloading netaddr-0.7.19-py2.py3-none-any.whl (1.6 MB)
|████████████████████████████████| 1.6 MB 57.1 MB/s
Collecting pbr==5.4.4
Downloading pbr-5.4.4-py2.py3-none-any.whl (110 kB)
|████████████████████████████████| 110 kB 72.2 MB/s
Collecting jmespath==0.9.5
Downloading jmespath-0.9.5-py2.py3-none-any.whl (24 kB)
Collecting ruamel.yaml==0.16.10
Downloading ruamel.yaml-0.16.10-py2.py3-none-any.whl (111 kB)
|████████████████████████████████| 111 kB 73.0 MB/s
Requirement already satisfied: PyYAML in /usr/lib/python3/dist-packages (from ansible==2.9.18->-r requirements.txt (line 1)) (5.3.1)
Requirement already satisfied: MarkupSafe>=0.23 in /usr/lib/python3/dist-packages (from jinja2==2.11.3->-r requirements.txt (line 3)) (1.1.0)
Collecting ruamel.yaml.clib>=0.1.2
Downloading ruamel.yaml.clib-0.2.2-cp38-cp38-manylinux1_x86_64.whl (578 kB)
|████████████████████████████████| 578 kB 28.5 MB/s
Building wheels for collected packages: ansible
Building wheel for ansible (setup.py) ... done
Created wheel for ansible: filename=ansible-2.9.18-py3-none-any.whl size=16200792 sha256=ff338d4328c2bb1cf363e1a7471f423d76e27e59d69580882fbe34532bad6ff1
Stored in directory: /home/k8sadmin/.cache/pip/wheels/ed/7b/19/06eda6ee0b619ebe3d45303209e94902e2cc01b4aac9af17fb
Successfully built ansible
Installing collected packages: ruamel.yaml.clib, jinja2, ruamel.yaml, pbr, netaddr, jmespath, ansible
WARNING: The script pbr is installed in '/home/k8sadmin/.local/bin' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed ansible-2.9.18 jinja2-2.11.3 jmespath-0.9.5 netaddr-0.7.19 pbr-5.4.4 ruamel.yaml-0.16.10 ruamel.yaml.clib-0.2.2
k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$
上記でインストールされたAnsibleを確認しましょう。
k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ ansible --version ansible 2.9.18 config file = /tmp/workspace/kubespray/ansible.cfg configured module search path = ['/tmp/workspace/kubespray/library'] ansible python module location = /home/k8sadmin/.local/lib/python3.8/site-packages/ansible executable location = /home/k8sadmin/.local/bin/ansible python version = 3.8.5 (default, Jan 27 2021, 15:41:15) [GCC 9.3.0]
Inventoryファイルの設定
次にクラスターインストール時に利用するInventoryファイルを作ります。KubeSprayのSampleファイルを再利用した方が速いのでコピーして使います。
inventory.iniファイルにcontrolplaneノード、etcdノード、workerノードを定義します。RancherからProduction Ready Cluster Checklistが公開しているのでご参照ください。
k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ cp -rfp inventory/sample inventory/spark8scluster k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ vi inventory/spark8scluster/inventory.ini # ## Configure 'ip' variable to bind kubernetes services on a # ## different ip than the default iface # ## We should set etcd_member_name for etcd cluster. The node that is not a etcd member do not need to set the value, or can set the empty string value. [all] quytd-spark-m1 ansible_host=192.168.10.1 ip=192.168.10.1 etcd_member_name=etcd1 quytd-spark-m2 ansible_host=192.168.10.2 ip=192.168.10.1 etcd_member_name=etcd2 quytd-spark-s1 ansible_host=192.168.10.3 ip=192.168.10.3 etcd_member_name=etcd3 quytd-spark-s2 ansible_host=192.168.10.4 ip=192.168.10.4 etcd_member_name=etcd4 quytd-spark-s3 ansible_host=192.168.10.6 ip=192.168.10.6 etcd_member_name=etcd5 quytd-spark-tool ansible_host=192.168.10.7 ip=192.168.10.7 # ## configure a bastion host if your nodes are not directly reachable # [bastion] # bastion ansible_host=x.x.x.x ansible_user=some_user [kube_control_plane] quytd-spark-m1 quytd-spark-m2 quytd-spark-tool [etcd] quytd-spark-m1 quytd-spark-m2 quytd-spark-s1 quytd-spark-s2 quytd-spark-s3 [kube-node] quytd-spark-m1 quytd-spark-m2 quytd-spark-s1 quytd-spark-s2 quytd-spark-s3 quytd-spark-tool [calico-rr] [k8s-cluster:children] kube_control_plane kube-node calico-rr
Kubernetesクラスターを展開する
k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ ansible-playbook -i inventory/spark8scluster/inventory.ini --become --become-user=root cluster.yml PLAY RECAP ***************************************************************************************************************************************************************************************** localhost : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 quytd-spark-m1 : ok=566 changed=73 unreachable=0 failed=0 skipped=1134 rescued=0 ignored=2 quytd-spark-m2 : ok=498 changed=62 unreachable=0 failed=0 skipped=993 rescued=0 ignored=1 quytd-spark-s1 : ok=421 changed=49 unreachable=0 failed=0 skipped=669 rescued=0 ignored=1 quytd-spark-s2 : ok=421 changed=49 unreachable=0 failed=0 skipped=669 rescued=0 ignored=1 quytd-spark-s3 : ok=422 changed=50 unreachable=0 failed=0 skipped=668 rescued=0 ignored=1 quytd-spark-tool : ok=428 changed=48 unreachable=0 failed=0 skipped=936 rescued=0 ignored=1
構築したクラスターを確認する
構築したクラスターを確認するため、以下のように実行ユーザーに認証情報の設定と環境変数を設定しましょう。
k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ mkdir -p $HOME/.kube k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ ls -al /etc/kubernetes/admin.conf -rw------- 1 root root 5573 Apr 3 20:45 /etc/kubernetes/admin.conf k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ sudo chown $(id -u):$(id -g) $HOME/.kube/config k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ export KUBECONFIG=$HOME/.kube/config k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$ kubectl cluster-info Kubernetes control plane is running at https://127.0.0.1:6443 To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'. k8sadmin@quytd-spark-tool:/tmp/workspace/kubespray$
良さそうですね。ここまではひとまずクラスターを構築することができました!
Lensでクラスターを管理する
LensはKubernetesの管理コマンドラインツールであるkubectlをGUIで使いやすくした管理ツールです。LensにKubernetesクラスター登録した後、クラスターのオブジェクト管理、メトリクス表示、Helm管理をGUIで行うことができます。同僚がLensについての記事を書いているのでよかったらご参照ください。クラスター管理ツールについてはRancherもありますが、Rancherサーバをインストール必要があるし、クラスター全ノードにAgentを展開する必要があるのでクラスターのリソースを食います。デスクトップ環境で気楽に始められることはLensが強みです。
Lensのインストール
今回は自分の作業PC(Macbook Pro)でLensをインストールしますので、Lensの公式ページからMacOS用のインストラーをダウンロードしてダブルクリックするだけでインストールしました。
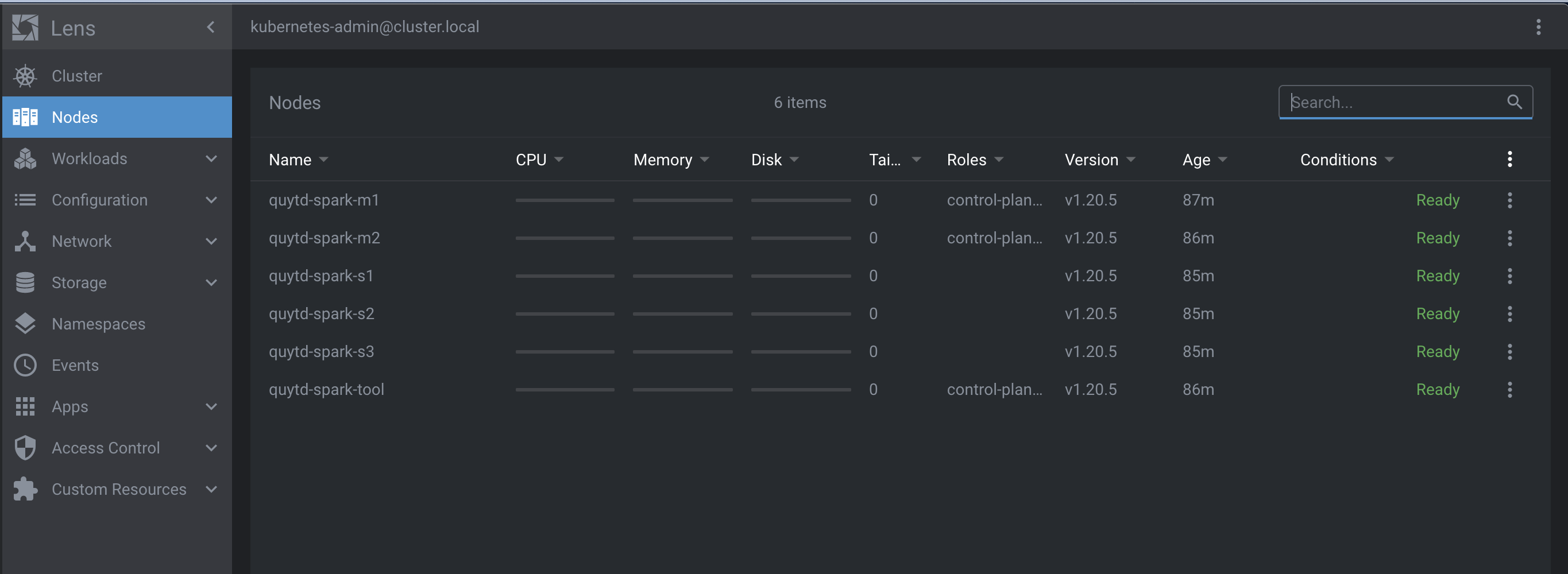
Lensに構築したKubernetesクラスターを登録する
作業PC(Macbook)に構築したクラスターのConfigファイルをcopyした後、configファイル内の127.0.0.1をquytd-spark-toolノードのIPアドレスを書き換える必要がありますが、連携するため残りの作業はLensのクラスター登録画面で指定するだけなので、驚くほど簡単です。
scp conoha-tool:/etc/kubernetes/admin.conf ~/.kube/config
Prometheus stackをインストールする
Defaultの状態はクラスターのノード、各オブジェクトの状態を確認できますが、Prometheusを利用すると、リソースなど色々なメトリックスがグラフで可視化できます。Lens GUIの右上ギアアイコンをクリック、「Settings」を選択すると設定画面が表示されるので、この画面の下にある「Features」の「Metrics Stack」にある「Install」ボタンをクリックします。
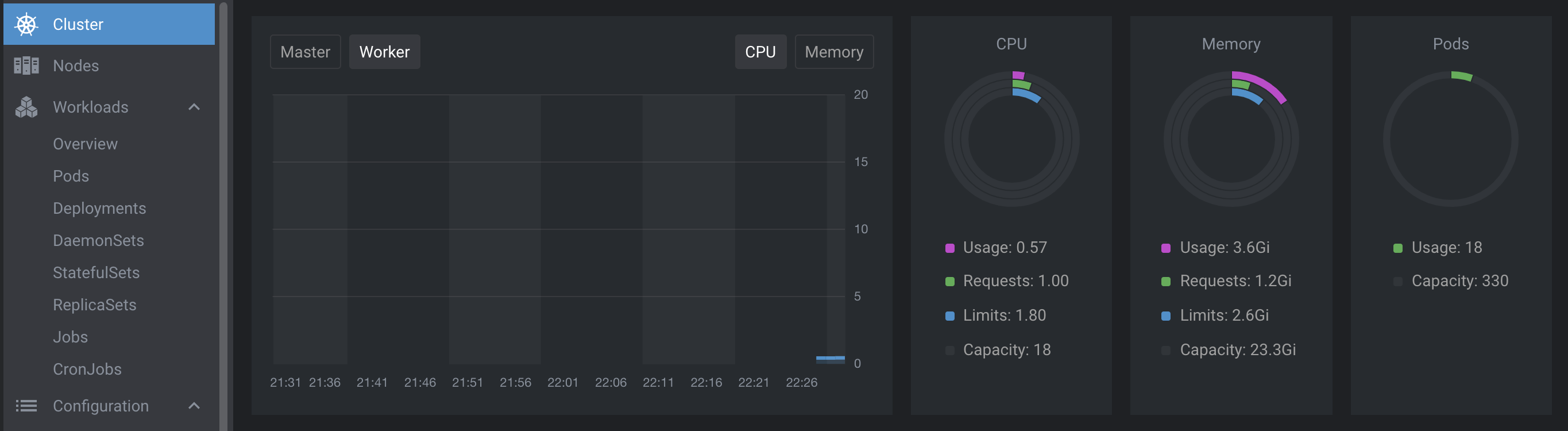
インストール後にリソースをグラフで確認できるようになりました!
Spark3のDocker Imageをビルドする
最初は公式ページからSpark3の最新バージョンをダウンロードする。現時点はspark-3.1.1-bin-hadoop3.2.tgzが最新バージョンなのでこのファイルを使います。
k8sadmin@quytd-spark-tool:/tmp/workspace$ wget https://ftp.kddi-research.jp/infosystems/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz k8sadmin@quytd-spark-tool:/tmp/workspace$ tar -xvzf spark-3.1.1-bin-hadoop3.2.tgz k8sadmin@quytd-spark-tool:/tmp/workspace$ rm -rf spark-3.1.1-bin-hadoop3.2.tgz k8sadmin@quytd-spark-tool:/tmp/workspace$ sudo mv spark-3.1.1-bin-hadoop3.2 /usr/local/ k8sadmin@quytd-spark-tool:/tmp/workspace$ sudo ln -s /usr/local/spark-3.1.1-bin-hadoop3.2/ /usr/local/spark k8sadmin@quytd-spark-tool:/tmp/workspace$ export SPARK_HOME=/usr/local/spark k8sadmin@quytd-spark-tool:/tmp/workspace$ java --version openjdk 11.0.10 2021-01-19 OpenJDK Runtime Environment (build 11.0.10+9-Ubuntu-0ubuntu1.20.04) OpenJDK 64-Bit Server VM (build 11.0.10+9-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
Docker Imageをビルドする
cd /usr/local/spark sudo bin/docker-image-tool.sh -r quytd -t v3.1.1 -p kubernetes/dockerfiles/spark/Dockerfile build Successfully tagged spark8s/spark:v3.1.1 sudo ./bin/docker-image-tool.sh -r quytd -t v3.1.1 -p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile build Successfully tagged spark8s/spark-py:v3.1.1 quytd/spark-py v3.1.1 db6c8c08c41b 6 minutes ago 909MB quytd/spark v3.1.1 f0d1e1f56750 4 hours ago 532MB
Docker RegistryにPush
k8sadmin@quytd-spark-tool:/usr/local/spark$ sudo docker login k8sadmin@quytd-spark-tool:/usr/local/spark$ sudo bin/docker-image-tool.sh -r quytd -t v3.1.1 push The push refers to repository [docker.io/quytd/spark] The push refers to repository [docker.io/quytd/spark-py] k8sadmin@quytd-spark-tool:/usr/local/spark$
KubernetesクラスターにSpark Containerを展開する
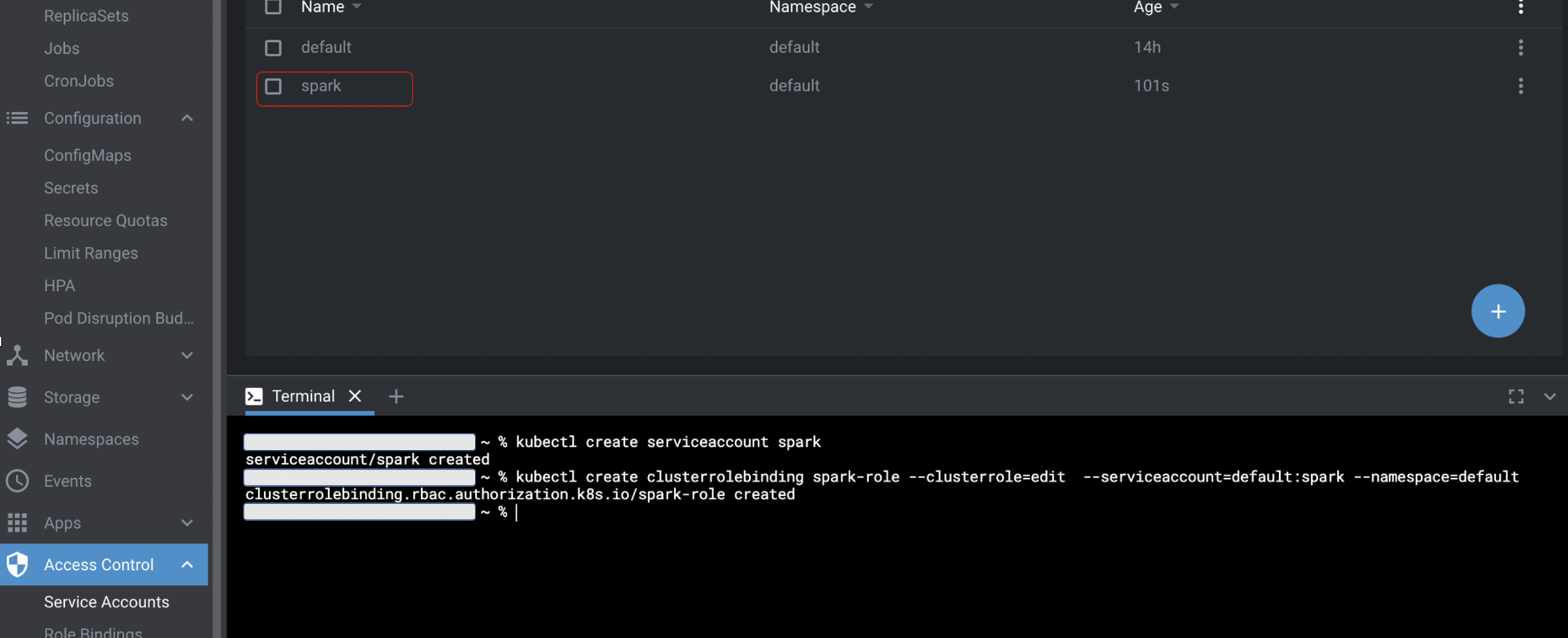
KubernetesのRBACによるSparkユーザー作成、権限付与
ジョブの認証・認可はKubernetesのサービスアカウントで行うため、Sparkジョブで使うサービスアカウントを作成しておきます。
LensのTerminalでKubectlコマンドを実行できるので、以下の図のようにコマンドを実行して作りました。
検証用のPySparkソースコードを準備する
今回は、PySparkで検証したいと思いますので、quytd-spark-toolサーバの「/var/local/www/spark8s/」にword_count.pyファイルを準備しておきました。
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
[
"python",
"scala",
"java",
"hadoop",
"spark",
"dataframe",
"spark",
"pyspark",
"hadoop",
"pyspark",
"big data",
"ETL",
"jupyter"]
)
counts = words.count()
print(counts)
WebサーバーでPySparkスクリプトをホストする
検証用のPySparkスクリプトファイルをネットワーク内全ノードからアクセスできるようにWebサーバーを起動しておきます。
cd /var/local/www/spark8s/ python3 -m http.server 30001
PySparkコマンド実行
実行環境を準備できましたので、早速PySparkスクリプトを実行しましょう。
spark-submitはSparkアプリケーションをKubernetesクラスタにサブミットするために直接使うことができますので、quytd-spark-toolサーバから以下のようにSparkーsubmitを実行しましょう!
./spark-submit \ --master k8s://https://192.168.10.7:6443 \ --deploy-mode cluster \ --conf spark.executor.instances=3 \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.kubernetes.container.image=quytd/spark-py:v3.1.1 \ --name spark-wordcount \ http://192.168.10.7:30001/word_count.py 21/04/04 06:13:10 INFO LoggingPodStatusWatcherImpl: Application status for spark-b486b5e716934964afe0bec4dd3048ae (phase: Succeeded) 21/04/04 06:13:10 INFO LoggingPodStatusWatcherImpl: Container final statuses: container name: spark-kubernetes-driver container image: quytd/spark-py:v3.1.1 container state: terminated container started at: 2021-04-04T06:13:03Z container finished at: 2021-04-04T06:13:09Z exit code: 0 termination reason: Completed 21/04/04 06:13:10 INFO LoggingPodStatusWatcherImpl: Application spark-wordcount with submission ID default:spark-wordcount-6d248a789b835b23-driver finished
Spark-submitコマンドのパラメーターについて以下のように設定されました。
PySparkプログラムが無事に構築したクラスターで実行完了しました!
結果確認
ログは Kubernetes API と kubectl CLI を使ってアクセスすることができます。Sparkアプリケーションが実行中の場合、以下を使ってアプリケーションからログをストリームすることができます
k8sadmin@quytd-spark-tool:/usr/local/spark/bin$ sudo kubectl logs spark-wordcount-6d248a789b835b23-driver 21/04/04 06:13:09 INFO DAGScheduler: Job 0 finished: count at /tmp/spark-3a139d57-f47d-436a-a90b-85b44ab00131/word_count.py:19, took 0.781797 s 13
所感
今回は、Conoha VPS上にマルチノードKubenetesクラスターを構築してSparkの実行環境を構築しました。今までHadoopクラスター上でSparkプログラムの開発・運用している経験から見ると、Kubernetes・Dockerで依存関係の管理が簡単になる点は大きなメリットです。実行環境は基本的にはDocker Imageで構築して、使いたい時はContainerを起動するだけなので、全ノードにインストールする必要があるHadoopに比べると大分楽になると思います。さらに実行終了にPodが削除されるのでノードのリソースが開放されて、次のジョブに調整可能になるので、クラスターのリソース管理面も効率よくなると思います。とはいえ、Kubernetes周りの概念と使いこなすまで少し時間が必要だし、Spark on Kubernetesはまだ成熟していないので、クラスター環境構築、プログラム開発・運用に様々な工夫が必要だと思います。次回は、KubenetesにSpark Operator、Jupyter Notebook/Zeppelineなど他のツールを導入して定期的に実行するバッチ管理やAdhoc分析環境を実現したいと思います。
それではまた!
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD


