Stable Cascade: Stability AIの新型画像生成AI (Stable Diffusion 3の解説ではありません)
TL;DR
- Stability AIが2024/02/12に「Stable Cascade」を発表しました。これは既存のStable Diffusion XLを上回る高画質・高速な次世代画像生成AIです。
- Stable Cascadeは、画像生成プロセスを3段階に分けるWürstchenというモデルを採用しています。Stable Diffusion では1024×1024の画像を128×128のlatent space(潜在空間)に圧縮し処理していましたが、Stable Cascadeは僅か24×24のlatent spaceに圧縮します。この高い圧縮率にも関わらず生成プロセスを3段階に分けることで、高品質の画像を効率的に生成・学習できます。
- 効率化した反面、Stable Cascadeの実行には高性能なGPUが必要です。公開された最大級のモデルでの画像生成にはGeForce RTX 4090級のGPUが必要となります。
- 今後のStability AIの旗艦モデルとして、Stable Cascadeは、Stable Diffusion XLを置き換えることが期待されます。
- と思っておりましたが、その発表から僅か10日後の2024/02/22に、新たにStability AIは「Stable Diffusion 3」のリリースを報じました。OpenAI Soraにも使われているというTransformerを応用したDiffusion model with Transformers(拡散トランスフォーマー)を採用したモデルで、文字の表現などが改善されている模様です。Stable Diffusion 3はearly preview版でまだ利用できませんが、一体これからどうなってしまうのでしょうか?Stability AIの動向からは目が離せません。
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。また、お前かという思われるかもしれませんが、AI関連の新ニュースは途切れることなく流れ去っていきます。AI技術を適切に評価をするためにも、新技術のキャッチアップとその理解が避けられない急務となっており、もう心休まる暇がありません。さて、Stability AI が “Stable Cascade” という画像生成AIを先日、2024/02/12にリリースしました(Introducing Stable Cascade)。これは、Stable Diffusionの改良版であるStable Diffusion XL(SDXL)の更に後継モデルです(多分、そうなるはずだったのですが)。Stable Cascadeは、Würstchenというモデルをもとにしており、Stage A、B、Cの3つのステップを経て画像を生成します。(注) Würstchen(ヴルストヒェン)とは、ドイツ語のソーセージ(Wurst: ヴルスト)の細いやつという意味だそうです。

以前のBlogで紹介したようにDiffusion Modelは、Denoising Stepで画像からノイズを取り除くことで画像を生成します。その際に通常のピクセルの画像ではなくlatent space(潜在空間)で処理して、Decoderを使って通常の画像へと変換します。例えば、Stable Diffusionの場合では、1024×1024の画像生成に128×128と1/8に圧縮された空間で処理します。Stable Cascadeは、24×24という更に約1/42まで圧縮された空間で処理します。この高い圧縮率によりStable Cascadeは、より高速なモデル学習と推論が可能となります。
Stable Cascadeの画像圧縮のイメージは以下の通りです。1024×1024の画像を24×24のlatent space(厳密には16 channel)に変換し、それを元に通常の画像を生成します。24×24と1024×1024を並べると以下の図のようなイメージとなります、小さすぎて何がなんだかわかりませんが、これほど小さく圧縮された“画像”から高品質な通常の画像を生成されるのは驚きです。

Stable Cascadeの概要
最初に、Stable Cascadeの性能を紹介します。以下の図は、Stable Cascadeと他のモデルの比較を示しています。上段はプロンプトに対しての忠実度、下段は画像の品質の比較です。Stable CascadeとPlayground v2、SDXL Turbo、Stable Diffusion XL(SDXL)、Würstchen v2の比較を示しています。Playground v2とは、PlaygroundがSDXLをチューニングして改良したモデル(https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic)で、SDXL TurboはAdversarial Diffusion Distillationで高速化したSDXLです(StreamDiffusionの解説の際に紹介しました)。Stable Cascade は、Playground v2とほぼ同等の性能で、他のモデルに関してはより優れた性能を発揮しています。
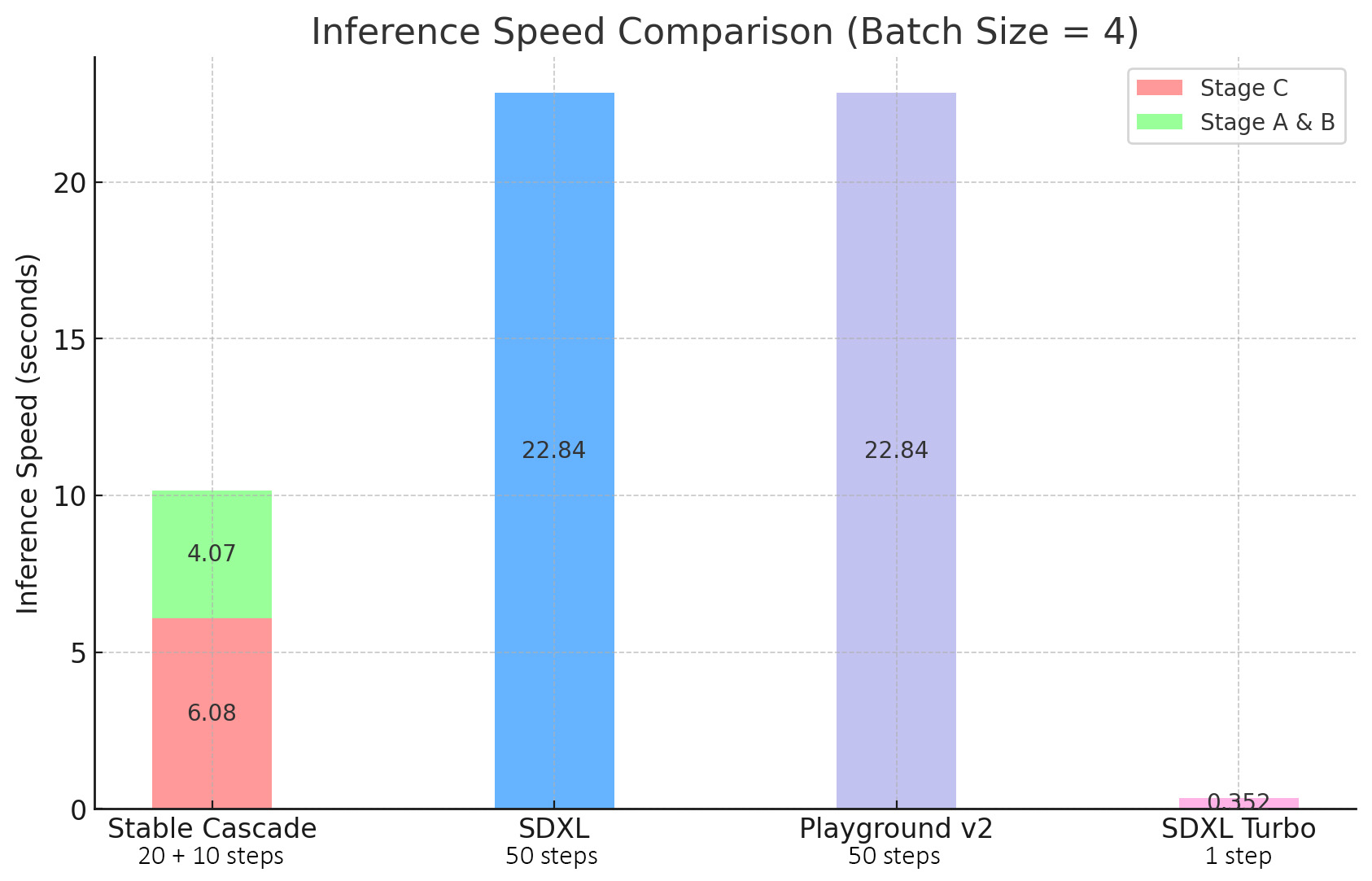
Stable Cascadeの利点は推論速度です。以下の図は、Stable Cascadeと他のモデルの推論速度の比較を示しています。
さて、そのStable Cascadeのモデルの構造は、以下のような3段階構成となっています。
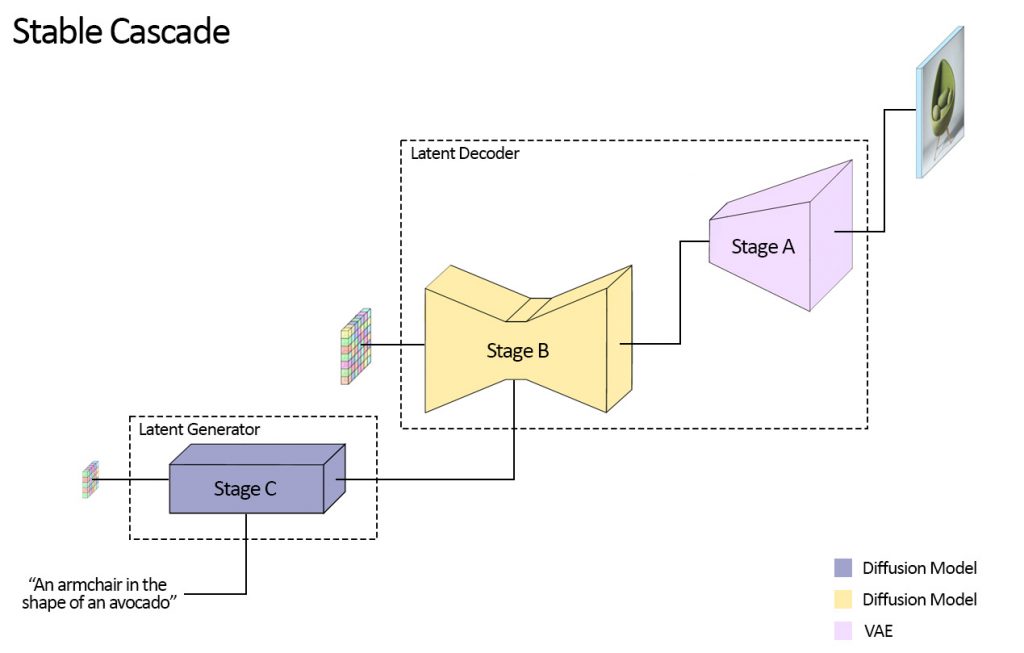
Stable Cascade(Würstchen)は、Vector-quantized Generative Adversarial Network (VQGAN)のDecoderであるStage AとDiffusion ModelであるStage B、Stage Cの3つのステップで画像を生成します。画像生成時の処理としてはlatent spaceのnoiseから逆拡散過程で生成するStage C、B、そしてそれを拡大しピクセルの画像に変換するDecoderのStage Aの順番で処理されます。各ステップの処理は以下の通りです。
- Stage C: 16x24x24のlatent spaceのノイズからプロンプトの情報を与えて逆拡散過程でlatent spaceで高度に圧縮された画像(24×24)を生成
- Stage B: 4x256x256のlatent spaceのノイズにStage Cの出力、プロンプトの情報を与えて逆拡散過程でVQGANのlatent space の情報(256×256)を生成
- Stage A: Stage Bの出力を元に通常の画像(1024×1024)を生成
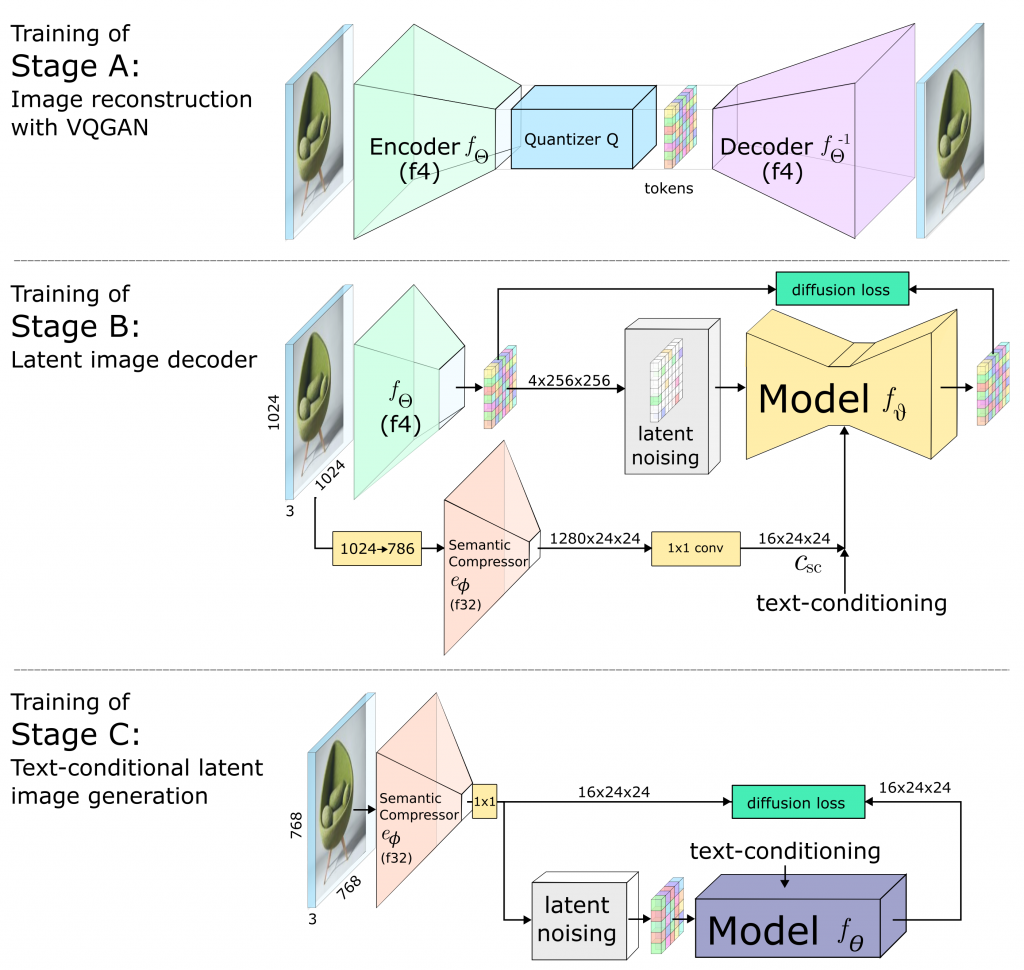
Stable Cascadeの学習済みのモデルが公開されていますが、Stage CとBではそれぞれSmall/Bigの2種類あります。それぞれのパラメーターのサイズは以下の通りです。
- Stage C: 1B & 3.6B
- Stage B: 700M & 1.5B
実践:Stable Cascadeを動かしてみる
では、実践としてStable Cascadeで画像を生成してみます。Hugging Face で、Stable Cascadeが公開されています。以下のコマンドでインストールできると書いてあります。$ pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3ただ、注意点として、その説明の上に
⚠️ Important: For the code below to work, you have to install diffusers from this branch while the PR is WIP.
とあり、時すでに遅くpipでインストールしてもその後のデモがエラーとなり実行できません。無理やりにインストールする方法もあるようですが、そのうちにdiffusersで安定して利用できるようになると思います。(追記) 3/15にリリースされた v0.27.0で、Stable Cascadeが追加されました https://github.com/huggingface/diffusers/releases/tag/v0.27.0。Diffuserを利用する場合は、以下の様に実行すればよいです。
from diffusers import StableCascadePriorPipeline, StableCascadeDecoderPipeline
import torch
prior = StableCascadePriorPipeline.from_pretrained(
"stabilityai/stable-cascade-prior",
torch_dtype=torch.bfloat16,
).to("cuda")
decoder = StableCascadeDecoderPipeline.from_pretrained(
"stabilityai/stable-cascade",
torch_dtype=torch.bfloat16,
).to("cuda")
prompt = "an abstrct painting of a cat"
negative_prompt = "low quality, low resolution, bad quality"
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
negative_prompt=negative_prompt,
guidance_scale=4.0,
num_images_per_prompt=1,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.to(torch.bfloat16),
prompt=prompt,
negative_prompt=negative_prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images[0]
decoder_output.save('output.png')
今回は、GitHubのリポジトリ(https://github.com/Stability-AI/StableCascade)のコードから実行してみます。$ conda create -n stablecascade python=3.10 $ conda activate stablecascade $ git clone [email protected]:Stability-AI/StableCascade.git $ cd StableCascade $ pip install -r requirements.txt $ cd models $ bash download_models.sh essential big-big bfloat16 $ cd ..モデルとしては、Stage CとBのそれぞれでBigとLiteが選択できます。Stage BをLite、Stage CをBigの場合以下のようにすれば良いです。
$ bash download_models.sh essential small-big bfloat16Stage Bのモデルの性能はBigとLiteによる画質の差は僅かですが、Stage CについてはLiteにすると大きく品質が変わります。なお、すでに述べたようにStable Cascadeの場合、Big-Bigのモデルを利用する場合は、VRAMが20GB以上必要となります。今回の検証では、VRAMが24GBあるGeForce RTX 4090を利用しましたが、ほぼ全てのメモリーを使い切ってギリギリでの実行となりました。以下のイラストは、それぞれの組み合わせで同一のプロンプトから山間の風景を生成した比較です。左の列がStage CでLarge、右がLite(Small)を使ったもの、上段がStage BでLarge、下段がLite(Small)となっています。Stage CのモデルではBigとLite差が顕著で、Largeなら湖への映り込みや雲の表現が非常に細かく描かれていますが、Liteを使うとイラストがぼやけた感じで細部の書き込みも荒い印象となります。一方で、Stage Bの場合、BigとLiteで非常に細かい部分の書き込みが違う程度で殆ど差はありません。

さて、具体的な生成コードの説明に移ります。まずはStage BとCのモデルを読み込みます。以下のコードはGitHubで公開されているコードをもとにしています。
import os
import yaml
import torch
from tqdm import tqdm
from inference.utils import *
from core.utils import load_or_fail
from train import WurstCoreC, WurstCoreB
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# SETUP STAGE C
config_file = 'configs/inference/stage_c_3b.yaml'
with open(config_file, "r", encoding="utf-8") as file:
loaded_config = yaml.safe_load(file)
core = WurstCoreC(config_dict=loaded_config, device=device, training=False)
# SETUP STAGE B
config_file_b = 'configs/inference/stage_b_3b.yaml'
with open(config_file_b, "r", encoding="utf-8") as file:
config_file_b = yaml.safe_load(file)
core_b = WurstCoreB(config_dict=config_file_b, device=device, training=False)
# SETUP MODELS & DATA
extras = core.setup_extras_pre()
models = core.setup_models(extras)
models.generator.eval().requires_grad_(False)
print("STAGE C READY")
extras_b = core_b.setup_extras_pre()
models_b = core_b.setup_models(extras_b, skip_clip=True)
models_b = WurstCoreB.Models(
**{**models_b.to_dict(), 'tokenizer': models.tokenizer, 'text_model': models.text_model}
)
models_b.generator.bfloat16().eval().requires_grad_(False)
print("STAGE B READY")
なお、BigではなくLiteを利用する場合は、それぞれのyaml fileで、generator_checkpoint_pathを該当のモデルに変更する必要があります。Text-to-Image
通常のText-to-Imageの場合、以下のようなコードで画像を生成することができます。captionを変更することで、指示する画像を生成することができます。batch_size = 4
caption = "an abstract painting of a cat"
height, width = 1024, 1024
stage_c_latent_shape, stage_b_latent_shape = calculate_latent_sizes(height, width, batch_size=batch_size)
# Stage C Parameters
extras.sampling_configs['cfg'] = 4
extras.sampling_configs['shift'] = 2
extras.sampling_configs['timesteps'] = 20
extras.sampling_configs['t_start'] = 1.0
# Stage B Parameters
extras_b.sampling_configs['cfg'] = 1.1
extras_b.sampling_configs['shift'] = 1
extras_b.sampling_configs['timesteps'] = 10
extras_b.sampling_configs['t_start'] = 1.0
# PREPARE CONDITIONS
batch = {'captions': * batch_size}
conditions = core.get_conditions(batch, models, extras, is_eval=True, is_unconditional=False, eval_image_embeds=False)
unconditions = core.get_conditions(batch, models, extras, is_eval=True, is_unconditional=True, eval_image_embeds=False)
conditions_b = core_b.get_conditions(batch, models_b, extras_b, is_eval=True, is_unconditional=False)
unconditions_b = core_b.get_conditions(batch, models_b, extras_b, is_eval=True, is_unconditional=True)
with torch.no_grad(), torch.cuda.amp.autocast(dtype=torch.bfloat16):
# torch.manual_seed(42)
sampling_c = extras.gdf.sample(
models.generator, conditions, stage_c_latent_shape,
unconditions, device=device, **extras.sampling_configs,
)
for (sampled_c, _, _) in tqdm(sampling_c, total=extras.sampling_configs['timesteps']):
sampled_c = sampled_c
conditions_b['effnet'] = sampled_c
unconditions_b['effnet'] = torch.zeros_like(sampled_c)
sampling_b = extras_b.gdf.sample(
models_b.generator, conditions_b, stage_b_latent_shape,
unconditions_b, device=device, **extras_b.sampling_configs
)
for (sampled_b, _, _) in tqdm(sampling_b, total=extras_b.sampling_configs['timesteps']):
sampled_b = sampled_b
sampled = models_b.stage_a.decode(sampled_b).float()
show_images(sampled)
生成された画像の例は以下の通りです。特に高速化などの工夫をしていない状況では、RTX 4090では、20秒と少しで4枚の画像が生成されました。
Image-to-Image
Image-to-Imageの場合は、画像を入力して、それを元に画像を生成します。noise levelとtimestepsを調整して、入力画像の特徴をどの程度残すかを調整することができます。Text-to-Imageとの変更点は以下のようになります。元にする画像をbatchに追加し、Stage Cの段階でnoise levelを調整しながら画像を生成します。batch_size = 4
base_image_file = 'base image file...'
base_image = PIL.Image.open(base_image_file).convert("RGB")
images = resize_image(base_image).unsqueeze(0).expand(batch_size, -1, -1, -1).to(device)
batch = {'images': images}
caption = "a girl rides a bike in the park"
noise_level = 0.8
height, width = 1024, 1024
stage_c_latent_shape, stage_b_latent_shape = calculate_latent_sizes(height, width, batch_size=batch_size)
effnet_latents = core.encode_latents(batch, models, extras)
t = torch.ones(effnet_latents.size(0), device=device) * noise_level
noised = extras.gdf.diffuse(effnet_latents, t=t)[0]
# Stage C Parameters
extras.sampling_configs['cfg'] = 4
extras.sampling_configs['shift'] = 2
extras.sampling_configs['timesteps'] = int(20 * noise_level)
extras.sampling_configs['t_start'] = noise_level
extras.sampling_configs['x_init'] = noised
# Stage B Parameters
extras_b.sampling_configs['cfg'] = 1.1
extras_b.sampling_configs['shift'] = 1
extras_b.sampling_configs['timesteps'] = 10
extras_b.sampling_configs['t_start'] = 1.0
# PREPARE CONDITIONS
batch['captions'] = * batch_size

Image Variation
Image Variationでは、入力画像からその埋め込みのみを抽出して、それを元に新たに画像を生成するというものです(プロンプトで更に調整することも可)。Image-to-Imageとは異なり類似した雰囲気の画像を生成することができます。Stage BとCのモデルの初期化に関しては、Text-to-Imageの場合と同じです。Stage Cのモデルの処理の際にeval_image_embeds=Trueとすることで、画像の埋め込みを抽出することができます。プロンプトの指定は不要なので、空の文字列を指定します。base_image_file = 'base image file...'
base_image = PIL.Image.open(base_image_file).convert("RGB")
images = resize_image(base_image).unsqueeze(0).expand(batch_size, -1, -1, -1).to(device)
caption = ""
batch = {'images': images, 'captions': * batch_size}
conditions = core.get_conditions(batch, models, extras, is_eval=True, is_unconditional=False, eval_image_embeds=True) # txt2imgとの違いはここ
unconditions = core.get_conditions(batch, models, extras, is_eval=True, is_unconditional=True, eval_image_embeds=False)
conditions_b = core_b.get_conditions(batch, models_b, extras_b, is_eval=True, is_unconditional=False)
unconditions_b = core_b.get_conditions(batch, models_b, extras_b, is_eval=True, is_unconditional=True)
Variationの例は以下の通りです。通常のImage-to-imageでは、入力画像を元に新しい画像が生成されますが、Variationの場合は、入力画像の埋め込みを利用して生成することで、様々な変化のある画像が生成されます。(悪用注意ですが、実在する人の写真を入力すると、その人に似た画像を簡単に生成できてしまいます。)
まとめ、そして、Stable Diffusion 3の発表へ
さて今回は、Stability AIが新たに発表したStable Cascadeについて紹介しました。つい半年ほど前に、Stable Diffusion XLが発表されたばかりですが、Stable Cascadeは更に高速・高品質の画像生成が可能です。Stable Cascadeは、3段階の生成ステップにより高品質のイラストを効率的に生成・学習することができるモデルです。生成の各ステップで異なる大きさのモデルが公開されていますが、最も高品質のモデルとなるとVRAMが20GB以上必要となります。使用するメモリーが大きいという懸念点がありますが、近いうちにより効率化したモデルがリリースされることが期待されます。と、これからStable CascadeがStability AIのベースモデルとなると思っていましたが、なんと、2024/02/22にStable Diffusion 3が発表されました(Stability AI “Stable Diffusion 3” https://stability.ai/news/stable-diffusion-3)。

Stable Diffusion 3はearly preview版でまだモデル自体は未公開ですが、技術としては“diffusion transformer architecture” (Scalable Diffusion Model with Transformers https://arxiv.org/abs/2212.09748)と“flow matching” (Flow Matching for Generative Modeling https://arxiv.org/abs/2210.02747)というものを利用しているようです。前者のDiffusion model with Transformers (DiTs, 拡散トランスフォーマー)とは、一般的にU-Net(CNN)を採用している逆拡散プロセスの計算をTransformerで置き換えるものです。LLMと同様にDiTsは、巨大化させるほど性能が向上するという性質が報告されております。先日、OpenAIが公開したSoraも、このDiTsを利用しているとあります(https://openai.com/research/video-generation-models-as-world-simulators)。
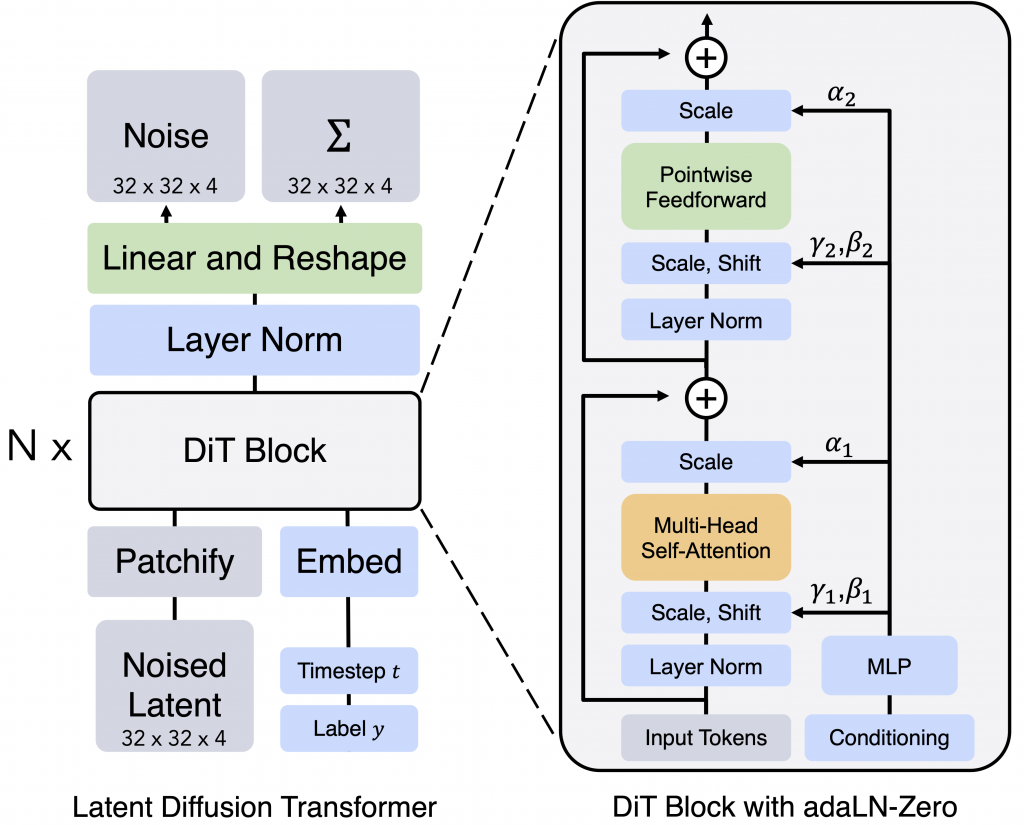
Stable Diffusion 3のテクニカル・レポートはこれから公開予定なので、これ以上の詳細は不明ですが、Stable Cascadeとは全く異なる技術を採用しています。Stable Diffusion 3のモデルサイズとしては、800Mから8B(Stable CascadeのBig-Bigよりも大規模です)までのものがあるそうです。半年ほど前にリリースされたばかりのStable Diffusion XLからの大幅にモデル構造を変えたStable Cascadeの発表、そして僅か2週間あまりでのStable Diffusion 3の発表。Stability AIでは何が起こっているのでしょうか?状況の変化に正直追いつけません。

グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- Stable Cascade
- Stability AI “Introducing Stable Cascade” https://stability.ai/news/introducing-stable-cascade Released 2024/02/12
- Hugging Face https://huggingface.co/stabilityai/stable-cascade
- GitHub https://github.com/Stability-AI/StableCascade
- Würstchen
- Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models https://arxiv.org/abs/2306.00637
- Hugging Face https://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen
- Stability AI “Announcing SDXL 1.0”
Blog: https://stability.ai/news/stable-diffusion-sdxl-1-announcement Released 2023/07/26 - Stability AI “Stable Diffusion 3” https://stability.ai/news/stable-diffusion-3 Released 2024/02/22
- Scalable Diffusion Model with Transformers https://arxiv.org/abs/2212.09748
- Flow Matching for Generative Modeling https://arxiv.org/abs/2210.02747