2020.07.10
論文紹介:「常識」を使って強化学習してみた(意訳)
こんにちは。次世代システム研究室のJK(男)です。今回は表題の通り論文紹介をします。紹介する論文は、今年の5月に投稿された「Enhancing Text-based Reinforcement Learning Agents with Commonsense Knowledge」(以下、Murugesan+20)です。直訳すると、「常識を用いることで、テキストベースの強化学習のレベルを上げることができたよ」といったところでしょうか。1章でハイライト、2-4章で論文をざっくり紹介して最後に感想を書いています。ちなみに自分が面白いと思ったところだけ紹介しますので、気になった方は元論文にあたってください。
1.論文の背景とハイライト
この論文のポイントは「常識」の部分です。強化学習は人の脳内での学習系に似ており、未知の環境でのエージェントの学習などに向いています(強化学習の説明は以前のブログ等を参照してください)。しかしAtariなどのゲーム環境で成果を出してきたモデルフリーの強化学習の場合、総当たり的に行動を起こして学習していくため人と比べると学習は非効率的です。
たとえば人は初めて橋を渡るときでも、落ちないように渡りますよね。でもエージェントは橋から落ちたら危険ということを事前には知らないので、まず落ちてみます。落ちて報酬が低いことを学習して、初めて橋から落ちずに渡ることができます。当たり前ですが、全ての環境でこんなことをやっていたら命がいくつあっても足りないので、そんな種族はとっくの昔に絶滅しているでしょう。人とエージェントの違いは「常識」を使ったかどうかです。人は橋を渡る以前に、高い所から落ちたら危ないということを学び「常識」として持っています。初めて橋を渡るときもその「常識」を使うので、落ちることなく渡りきれます。
この論文の目的は、人が持つこの「常識」を活用してエージェントの学習効率を上げることです。この論文ではグラフ情報として常識を抜き出し、かつ観測情報(エージェントの情報)もグラフ情報として保持し、両者のグラフを結合して学習用の情報として使っています。常識をグラフ情報として扱うのは脳の構造を考えても適切な方法のように思えます。その常識をうまく扱えるように、観測情報もグラフ情報化したのが面白ポイントですね。結果、「常識」ありのエージェントは「常識」なしエージェントより良い学習結果を得られました。しかし単純に「常識」を入れるだけではダメで、「適切に」常識を入れてあげる必要があったようです。この「常識」を学習に入れ込む方法については、まだまだ研究の余地がありそうな印象を受けました。
2.学習環境
この論文では、TextWorldというテキストしか使わない環境で強化学習を行っており、よく使われる画像を観測情報とする強化学習とは異なります(下図;Murugesan+20)。
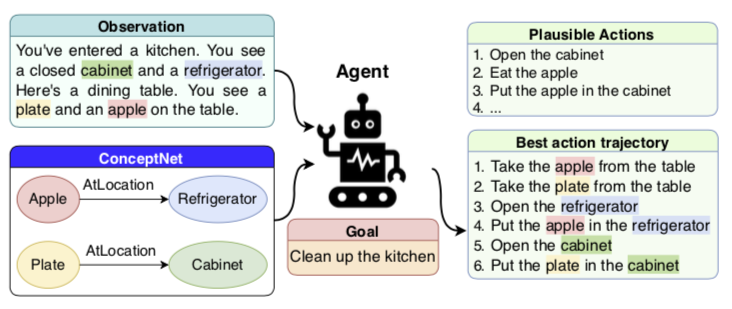
図1では、「台所の片付け」という目標(報酬)を与えられたエージェントがいます。面白いのは、観測情報もテキストで与えられているところです。ここでは「あなたは台所におり、食器棚と冷蔵庫が見えます。テーブルがあり、テーブルの上にお皿とりんごあります」という観測値が、テキストとしてエージェントに与えられます。もう一つインプットとして与えられている「ConceptNet」が「常識」情報です。この例では「りんごは冷蔵庫にある(のが普通だ)」「お皿は食器棚にある(のが普通だ)」となってますね。エージェントがとり得る行動は無限に考えられますが、この環境では有限個のリストになっています。正しい行動だけでなく不正解の行動も入れ、その中から正しい行動を選び取れるように学習します。図の「Plausible Actions」を見ると、「りんごを食べる」とか「りんごを食器棚に入れる」とか明らかに不正解な行動がありますね。この中から報酬が最大化するような「Best action trajectory」の行動を選択できるよう強化学習していきます。
なぜこのようなテキストベースの環境を使っているかですが、「常識」をテキストベースで紐付けているため、環境もテキストにした方が効率的だからだと思います。もし画像を観測情報にすると、画像→テキストの変換をしてから観測情報と「常識」を組み合わせて学習する必要があり、画像→テキストの学習が余計に必要になります。いまこの論文でフォーカスしたいのは、常識を取り込んで強化学習することなので、余計な学習でノイズにならないようにテキストベースにしたのだと思います。
3.モデル
学習モデルは下図(Murugesan+20)の通りで、大きく分けて3つのコンポーネントで構成されています。
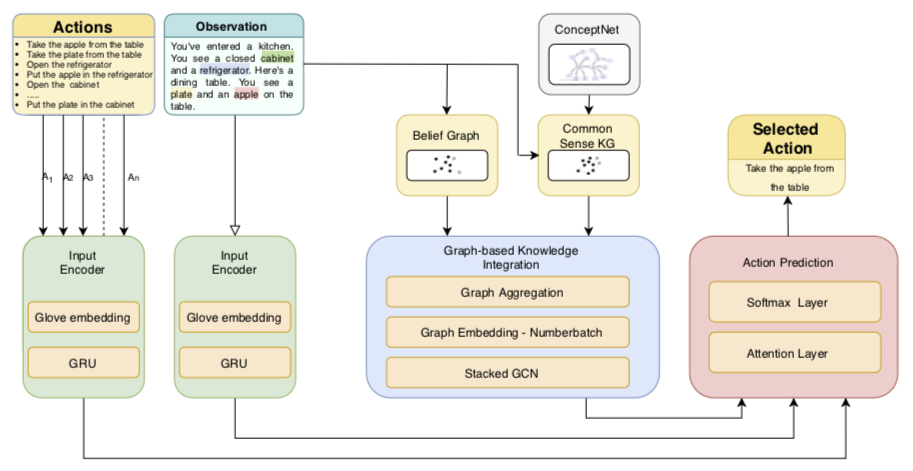
①緑色の「Input Encoder」は、文章をembeddingしています。文章の各単語をGloveで単語毎にembedしてテンソルをつくり、それをインプットにGRUで文章をベクトル化しています。1章の通り、観測値は文章で与えられています。選択できる行動は有限個の文章リストで構成されているようで、これもインプットとして使います。
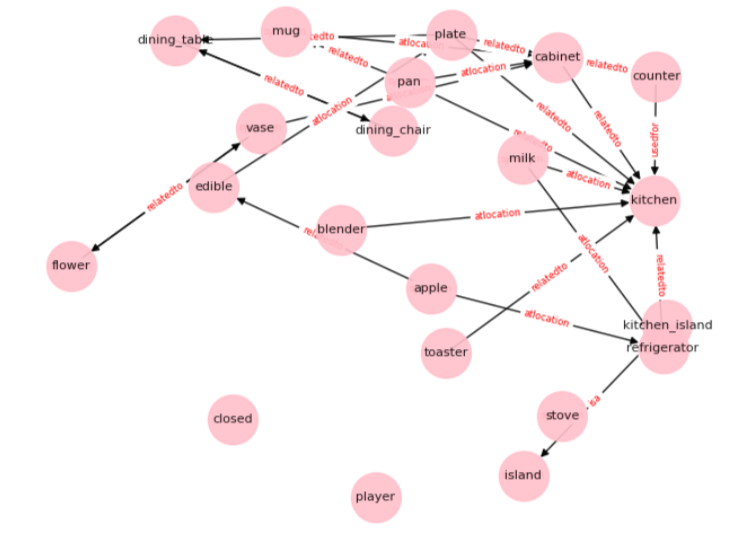
②青色の「Graph-based Knowledge Integration」が最も大事な部分で、インプットは(i) 観測から作られるBelief Graph、(ii)「常識」部分を構成するConceptNetの2つからなります。Belief Graphは、これまでの観測情報からエージェントが自身の状態を情報化したものです。環境が持っている真の「状態」ではなく、エージェントが観測したものから推測した(信じている)「状態」なのでBelief(信念)という言葉が使われています。状態をグラフ情報に落とし込んだのが面白いですね(オリジナルはこの論文)。観測されるごとにBelief Graphは更新されていきます。「常識」も文章リストで箇条書きに書くより関係性で書く方が自然ですね。この論文では「常識」としてConceptNetを採用しています。ConceptNetには多くのモノや概念のつながりがグラフ情報として記述されています。試しに”apple”で検索すると、”apple”と「関係」するのはfruit, red, macなどと出てきます。客観的な「常識」情報として使うにはよさそうです。もちろんこのままだと膨大な情報量になるので、観測情報から関係のあるentityだけを抜き出して「常識グラフ」を作成します(図のCommon Sense KG)。たとえば今回の実験では以下のような常識グラフが使われました(Murugesan+20)。この(i) Belief graphと(ii) 常識グラフを、グラフ情報として組み合わせてGCN(Graph Convolution Network)でベクトル化して、Agentの行動予測のインプットとしています。
③赤色の「Action Prediction」ですが、図の説明だとAttention Layerが入ってますが、論文の文章によるとInput EncoderとGraph-based Knowledge Integrationのアウトプットをガッチャンコして、(行動リストをアウトプットユニットとした)softmaxに入れて、最も確率が高い行動を選択するようです。強化学習のアルゴリズムにはA2Cを使っています。
モデル全体の構成は、「常識」に存在する「”りんご”は冷蔵庫にあるものだ」という関係性を使うことで、観測値にある「テーブルの上にあるりんご」と「冷蔵庫」と結びつけ、「りんごを冷蔵庫にしまう」につながる行動を行動リストから選択していくといった学習になります。「常識」がなければ、あらゆる行動を試すので、たとえば「りんごを床に置く」「りんごを食べる」なども試すことになりますが、こういった無断な試行錯誤を減らせる効果が期待できます。強化学習なので、正しい行動をしたとき(りんごを冷蔵庫に入れた時)は報酬がもらえるので、その行動に結びついた行動シーケンスを取るように学習します。非常に「人間が理解しやすい」モデル構成になっていますね。
4.結果と課題
最初の図の例にもあった「台所の片付け」を報酬とした強化学習をしたときの結果が以下となります(Murugesan+20)。
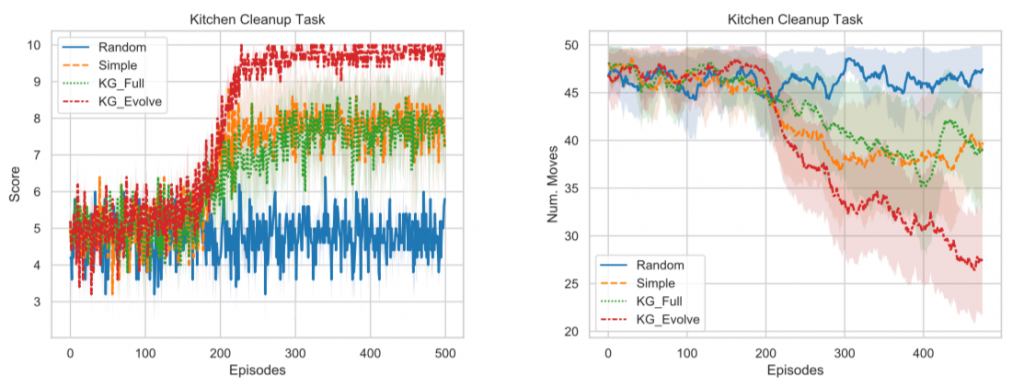
左図が学習エピソード毎の最終報酬です。「台所環境」には10個の片付けるべきモノがあり、1つ正しい場所に片付ける毎に報酬が1点もらえるので10点が最高になります。右図は各エピソードでエージェントが片付けを終えるまでに要した行動ステップ数です。ステップ数が少ないほど無駄な行動をせずに片付けられるのでより優秀なエージェントと言えるでしょう。このタスクでは4つのモデルが比較されています。①Random(ランダムに行動を選択)、②Simple(「常識」なしで学習)、③KG_Full(「常識」ありで学習;関係する全ての「常識」を最初からインプット。KGはKnowledge Graphの略)、④KG_Evolve(「常識」ありで学習;エピソード毎にエージェントの観測と関連する「常識」のみインプット)。最も良いのは④でスコアは満点でステップ数も少ないです。最も悪いのは①ですが、ランダムに行動したら学習できないのは当たり前ですね(なんで図に入れたんだろう。。)。
常識を入れ込んだら結果が良くなった、というのはモデル構成を見ればそこまで驚くべき結果ではないと思います。「常識」と「観測」をグラフ情報として扱い、学習できたというのが一つの成果でしょう(この論文のオリジナルではないですが)。もう一つ大事な点は「常識」最初から全部入れたらうまく学習できなかった(「常識」を入れなかったSimpleケースとほぼ同等の学習効率)という点です。論文では、コンテキストと関係ないデータを入れるとノイズとなってしまい探索空間が増えてしまいうまくいかないのではないかと推測していました。全部入れているといっても、台所タスクに関連する「常識」の関係性を入れただけなので、そこまで情報量としては多くないと思うのですが学習が難しくなるようです。単純に「常識」の情報を全部入れればよいわけではなく、コンテキストに合った情報だけを抜き出す技術が大事というのはAttentionを連想させます。この辺りはまだまだ工夫の余地がありそうですね。
感想とまとめ
今年の5月に投稿された論文「Enhancing Text-based Reinforcement Learning Agents with Commonsense Knowledge」を紹介しました。モデル構成を見ると、人間のメタ認識上での行動をトレースした形になっています。つまり、「台所を片付けて」というタスクを頼まれた時の人の行動をメタ的にラベル付けすれば、このような観測・行動になりそうというものをモデル化しています。個人的には「概念化した行動をモデル化」すると人間がボトルネックになるので、ちょっと微妙だと思っていたりします(実際の人間の行動は、上記モデルのような単純なものではないでしょう)。もちろん著者らもそれは十分わかった上で、「常識」と「観測」を組み合わせた効率的な学習の研究にフォーカスするため、論文のようなシンプルな形にしたのだと思います。
個人的に前提知識のないモデルフリーの強化学習のみでの応用は限定的かなとも感じており、常識なりワールドモデルなりと組み合わせが重要になると思っています。もちろんそういった「常識」をもゼロから学んでいくと、より生物らしいし何よりカッコイイんですがちょっとアカデミック寄りな気がします。まず現実世界への応用を考えるとき、ある程度の常識やフレームワークと組み合わせ、柔軟に学習すべき所を強化学習に任せるというのが良い気がしています。柔軟性と学習効率のバランス、機械の自動化と人間の前提知識のバランスが大事で、そういった意味で今回の論文のコンセプトは面白いです。今後、この分野がどのように発展していくか楽しみです。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD