2020.07.10
情報検索に応用したDeep Learningについて「論文紹介」
こんにちは、次世代システム研究室のA.Zです。
今回は自然言語処理の一つのサブ分野と言える情報検索にdeep learningの応用する論文を紹介したいと思います。
みんなさんはすでにご存知だと思います。情報検索とは簡単にいうと膨大な非構造な情報コレクション目的情報を見つけ出すことです。
情報検索の主にやっていることはある目的情報(query) に対して、情報のコレクション(Corpus)の中から、マッチした情報(relevance)を見つけ出す。
情報検索で、重要なポイントはquery, corpus,とrelevance scoreです。
情報検索分野で一番いっぱん的なのはAd-Hoc情報検索というものです。
Adhoc情報検索とはユーザーは自由に自分の目的に合わせて、queryを設定し、情報検索システムはそのクエリに対して、マッチした情報を見つけ出す。つまり、今の検索エンジン(Google, Bingなど)ということです。
今回紹介したい論文はdeep learningの技術を利用した情報検索モデル(Deep Relevance Matching Model)。
https://arxiv.org/pdf/1711.08611.pdf
はじめに
まずは問題定義と情報検索の特徴について紹介したいと思います。
情報検索では基本的な目的は、queryとマッチするドキュメントを見つけ出すこと。
どれぐらいqueryとドキュメントがマッチするか以下の式で表現できます
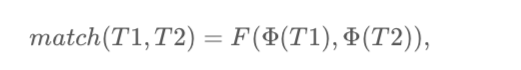
T1とT2はそれぞれのクエリーとドキュメントを表しています。
Φ はテキストをベクターを変換するための関数です。
Fはマッチングスクアーを計算するための関数です。
上記のかFの関数によって、 情報検索のDeep Learningのアルゴリズムは2つに分かれています
- 表現中心 アルゴリズム
こちらのカテゴリのアルゴリズムはどうやってテキスト(文書、単語など)を正確にベクターを表現できるかをフォカスします。このカテゴリのアルゴリズムはΦの関数でDeep Learningを利用することが一般的です。 - インタラクション中心アルゴリズム
こちらのカテゴリのアルゴリズムはマッチングスコアーの計算方法(Fの関数)にフォーカスし、Deep Learningを応用します。
また、こちらの論文の中に、なぜadhoc検索と似たようなNLPタスクマッチング(質問応答、対話システムなど)のモデルはadhoc検索のパフォーマンスは期待通りならないか議論されています。
理由は対話、質問応答システムなどは基本的に以下の要因にフォーカスしています。
- テキストの意味
同じ単語やテキストのマッチするより、テキスト全体意味を重視します。 - 文法
マッチ対象のテキストは基本的に文法が存在し、文法を考慮し、マッチを行います。 - グローバルマッチング条件
マッチ対象のテキストは基本的に一つの大きな文章やドキュメントとしてまとめて、意味的にマッチするどうかが行います。例えば、質問応答の場合は、質問と回答は一致したら、基本的に、質問と回答は同じトピックまた意味的に関連するになっています。
一方、adhoc情報検索は、意味のマッチというより、関連性マッチ(relevance match)のほうが重視します。そのために、フォーカスした要因は以下にです。
- 単語のマッチは最も重要
意味のマッチするより、単語のマッチのほうがもっとも重要。 - queryの重要さ
query自体は基本的に短く、文法が持っていないため、queryに含まれた単語の重要度が大事です。例えば、 “coronavirus news”というqueryの場合は、newsにマッチしたどドキュメントより、coronavirusにマッチしたドキュメントのほうがユーザーの目的に一致している。 - 多様なマッチング条件
ad-hoc情報検索もうひとつの特徴はドキュメントが長く、一つのドキュメントの中に、複数トピックや内容が含まれていることです。ドキュメントの全体がマッチしなくても、一部だけqueryとマッチすれば、そのドキュメントはqueryとマッチすることもあります。
上記の様々な要因や特徴に基づき、Deep Relevance Matching Model for Ad-hoc Retrievalのモデルが提案されました。
Deep Relevance Matching Model について
さて、ようやく本題に入ります。今回の紹介するDeep Relevance Matching Modelは上記に紹介したカテゴリの中に、インタラクションの中心のアルゴリズムになります。
モデルの全体の構造は以下です。
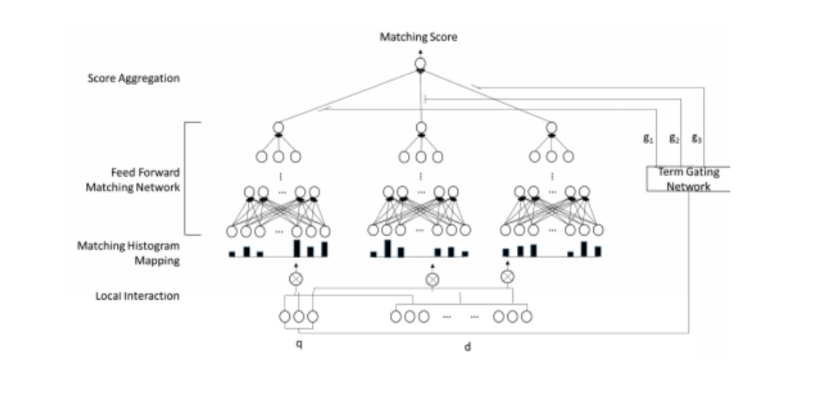
こちらのモデルのinputはドキュメントとqueryのペアー、outputは関連性スコアー(relevancy score)。
今回のモデルは大きく以下のコンポネントで構成されます。
Term Vector Embedding
こちらのステップではまず、各単語をベクターに変換する処理が行います。論文ではこちらの部分が学習済のword2vecモデルを利用されています。
Matching Histogram Mapping
こちらのステップはdeep modelのinputデータの作成行います。前のパートで紹介した通り、ad-hoc情報検索では単語マッチングが重視しているため、queryの単語とドキュメントの単語のマッチング関数が適用されます。しかし、各ドキュメントとの長さ(単語の数)が違いため、適用したマッチ関数の結果の次元が異なります。Neural Networkのinputが固定の次元のため、こちらのモデルではヒストグラムに変換するというアプローチを利用します。具体的に処理は
- 例えば、queryは “car”という単語があって、ドキュメントは[“car”,”truck”,”rent”,”highway”,”passenger”]があります
- carという単語と各ドキュメントの単語すべてベクターに変換し、carとそれそれのドキュメントの単語のマッチ関数(例:cosine similarity)スコアーを計算します。
- 例えば cosine similarityが[1, 0.2, 0.7, 0.3, −0.1]という結果出て、その結果は5 bins{[−1, −0.5), [−0.5, −0), [0, 0.5), [0.5, 1), [1, 1]}に変換し、ヒストグラムの値は[0, 1, 2, 1, 1]が出ました。
- 出た結果のヒストグラムの値はneural networkのinputとして使われています。
- 1単語以上のqueryだったら、それぞれqueryの単語に対して、上記の処理を適用します。
また、ヒストグラム作成方法に関して、本論文は以下の方法が紹介されます。
- Count-based histogram(CH)
一番簡単な方法で、ただのbinのカウントだけで表現します - Normalized Histogram(NH)
binのカウントが更にトータルのカウントでnormalizeします - LogCount-based Histogram(LCH)
カウントの値にlog関数を適用し、全体の値のrangeを小さくするための目的です。
個人的に、この論文の面白い部分はこちらの部分です。同じアイデアで、別の場面でも利用できるではないかと思います。
Feed Forward Matching Network
こちらの部分は今回のモデルが Multi Layer Perceptron(MLP)を利用しています。理由はMLPがポジションに依存しないかつシグナルの強さ中心(今回はヒストグラム)に学習できるため、今回のモデルに適切になります。
Term Gating Network
この部分はqueryの中に、複数単語があった場合は、それぞれの単語はどの程度最終のスコアーに貢献するか学習するためです。
各queryの単語に対して、以下の softmax関数が適用されます。
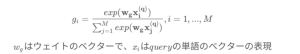
queryの単語のベクター表現は以下の2つ方法が紹介されました。
- Term Vector(TV)
各queryの単語のベクターをそのままinputとして利用します - Inverse Document Frequency(IDF)
ある特定な単語がよく利用されたら、その単語の重要度が下がるというコンセプトです。
Score aggregation
最後に、Feed Forward Matching Networkの結果とTerm Gatingの結果は以下の式で結合し、ファイナルのマッチングscoreを学習します。
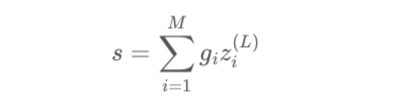
上記はすべてのDeep Relevance Matching Modelになります。
次はこちらのモデルはどれぐらいパフォーマンスが出している紹介いたします。
モデルの結果
今回のモデルのパフォーマンスが以下ののモデルで比較されました。
- 伝統情報検索モデル
- QL(Query Likelihood) Model
- BM25 Model
- 表現中心 Deep Neural Networkアルゴリズム
- DSMM(Deep Structured Semantic Model)
- C-DSMM(Deep Structured Semantic Model with CNN)
- ARC-I
- インタラクション中心Deep Neural Networkアルゴリズム
- ARC-II
- Match Pyramid(MP)
評価するデータセットは以下です
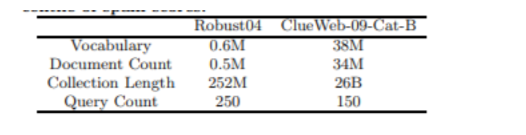
Robust04とClue Web-09は情報検索システムを評価するために、よく使われているデータセットの一部です。
実際に評価結果は以下になります。
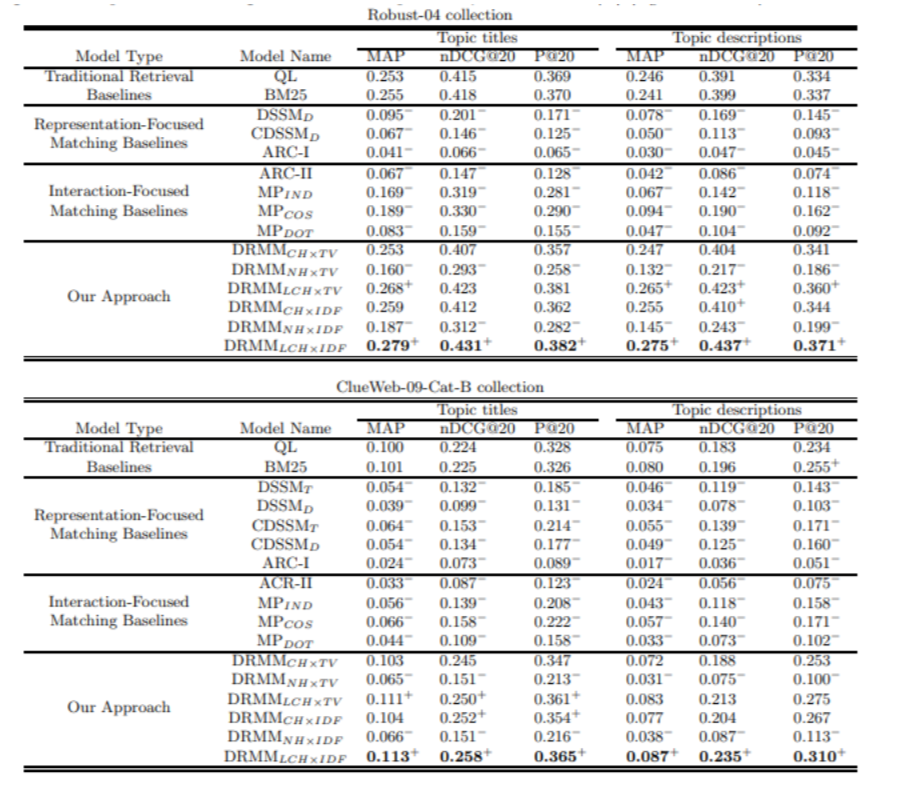
上記の結果は[Topic Titles]と[Topic Description]とはそれぞれのqueryはtopicsというような構造で表現されます。
例としては以下になります。

例えば、上記のtopicから、queryとしてtitleだけ使うとか、descriptionとかという実験です。
利用した評価指標としては以下で簡単に説明いたします。
- MAP(Mean Average Precision)
- すべてのqueryに対して、平均のAverage Precision
- nDCAG@20(normalized Discounted Cumulative Gain)
- 抽出の最上位20件のnormalized Discounted Cumulative Gain
- 検索システムの効率化するため一つの指標です。高いスコアーのドキュメントがどれだけ上位に入っているかつに全体的に高いスコアードキュメントが抽出数がどれぐらいなのかと視点を評価するための指標です。
- P@20(Precision@20)
- 抽出の最上位20件のPrecision
さて、上記の結果からみると、DRMM LCHxIDFは他のベースラインモデルより、良い結果が達成できました。LCHはヒストグラムを作成するときに、log関数を適用されるという意味です。やはり期待した通りで、log関数を適用することで、値のレンジが小さくなりかつ非線形でマッピングできるため、neural networkにとっては学習しやすくなります。IDFというのはterm gattingのネットワークのinputで、IDFスコアーを使うという意味です。IDFに比べて、TV(Term Vector)は単語の重要度がうまく表現できないという原因だと思います。
また、他のDeep Neural networkは伝統的な手法に比べて、精度があまり良くないのは驚きました。他のモデルは意味のマッチにこだわりすぎやqueryの単語の重要度考慮していないなどはお主な理由と思われます。具体的な理由と仮説について、興味がある方は元の論文にご参考いただければとおもいます。
まとめ
今回、Deep Relevance Matching Modelについて紹介いたしました。この論文では情報検索に対して、もっとも重視すべきなポイントはわかりやすく紹介されました。今後の新しい情報検索モデルを作るときに、役に立つではないと思います。また実際に、情報検索と似たようなケースもビジネス面でもたくさんあると思います。例えば、推薦 (recommendation)のケースはadhoc検索の考え方応用できるという議論もあります。今後はなにかの課題を解決するために、情報検索アプローチは一つアプローチとして、応用できるかと思います。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD